
Digital Resilience Pays Off
Download this e-book to learn about the role of Digital Resilience across enterprises.
The evolution of Splunk and Docker continues! In the early days (2015) of Splunk and Docker we recommended using the native syslog logging driver in Docker Engine. In Feburary of 2016, Docker 1.10 came out and we contributed the first version of Splunk Logging Driver in Docker 1.10. Since that first release we have seen huge adoption. After reviewing feedback and thinking about what is needed for Splunk environments with Docker, we’ve added a bunch of new features!
When I wrote this blog post, Docker 1.13 was still in Release Candidate stage. If you still have a version of Docker less than 1.13, you can try to install it with docker-machine, like this:
$ docker-machine create \
--driver=virtualbox \
--virtualbox-disk-size=200000 \
--virtualbox-memory=4096 \
--virtualbox-cpu-count=4 \
--virtualbox-boot2docker-url=https://github.com/boot2docker/boot2docker/releases/download/v1.13.0-rc2/boot2docker.iso \
docker-1.13.0-rc2To try Splunk latest features you have to install matched or higher version of Docker Client. If you are using docker machine, you can just ssh on just created machine
$ docker-machine ssh docker-1.13.0-rc2
--log-opt splunk-verify-connection=true|false
In the example above and all following examples we will skip all the options we usually specify in the docker command to focus attention on the new parameters, the full command for the Splunk Logging Driver is:
docker run ubuntu --log-driver splunk --log-opt splunk-url=http://localhost:8088 --log-opt splunk-token=E055502A-D35D-45F7
-9457-085A9DB9A49F bash -c 'printf "my message\n{\"foo\": \"bar\"}\n"'
Sometimes a logging endpoint isn’t available/or misconfigured. Docker engineering recommended that the container should fail to start. This topic was an open discussion since opened the very first PR.
Since then we have received a lot of feedback on this issue–especially from the folks who wanted to run Splunk Enterprise on the same Docker host where they wanted to use Splunk Logging Driver. Not being in production environments, they were ok with missing logs before HTTP Event Collector endpoint was available. Our solution had to ensure when using the splunk logging driver, the container will start.
For production environments splunk-verify-connection=false also works nicely with new retry logic and configurable buffer in the Logging Driver.
--log-opt splunk-format=inline|json|raw
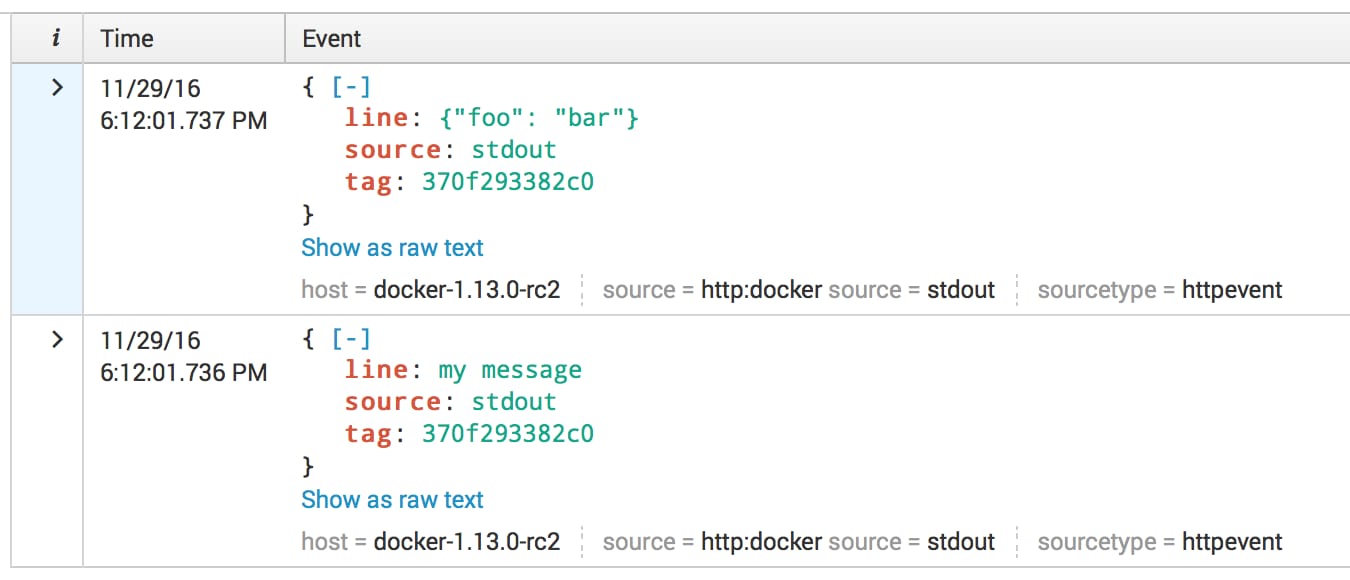
The default format will stay the same as it was originally implemented, now known as inline. For this update, we have two more format options, json and raw. Here’s an example. Let’s prepare a container which will print two messages to standard output, first line just a string,
Here’s an example. Let’s prepare a container which will print two messages to standard output, first line just a string, second line is a valid JSON message
docker run ubuntu bash -c 'printf "my message\n{\"foo\": \"bar\"}\n"'
my message
{"foo": "bar"}
Let’s look on how that will be represented in Splunk using various formats.
--log-opt splunk-format=inline
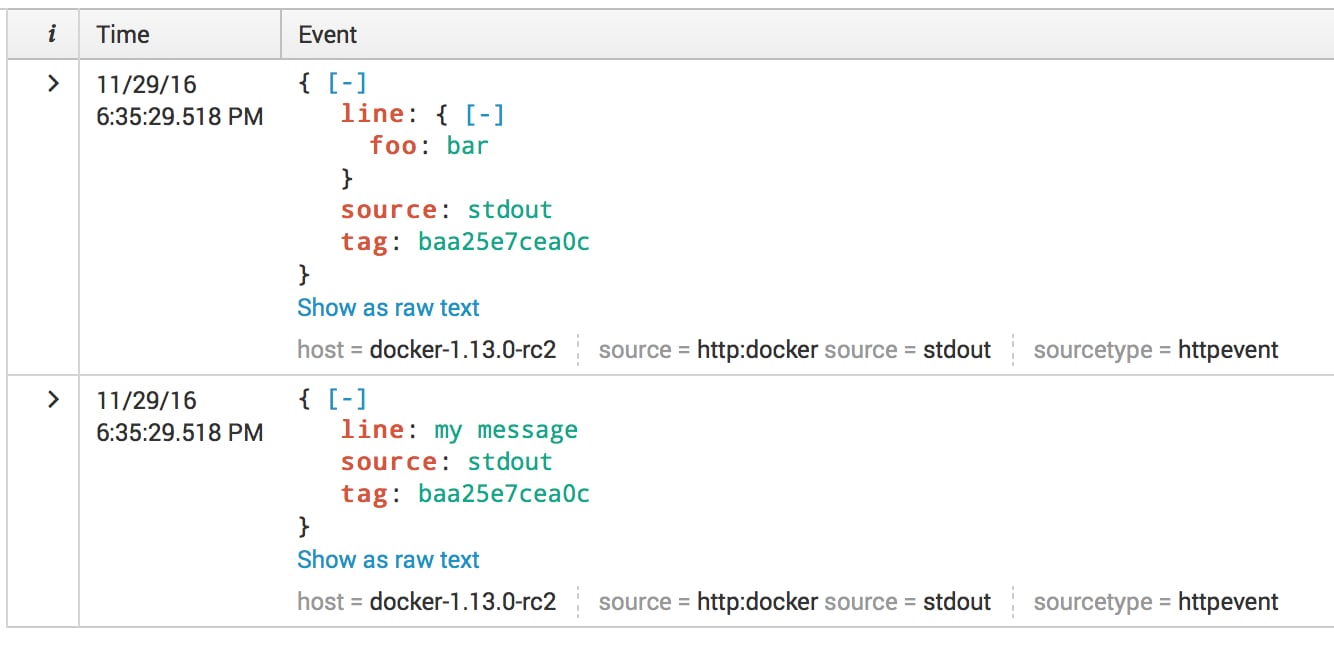
This is the default format used in all versions up to docker 1.13.
--log-opt splunk-format=raw
Note: we are still sending events on services/collector/event/1.0 endpoint (not services/collector/raw/1.0), which means that you can use it with Splunk Enterprise 6.3.x.
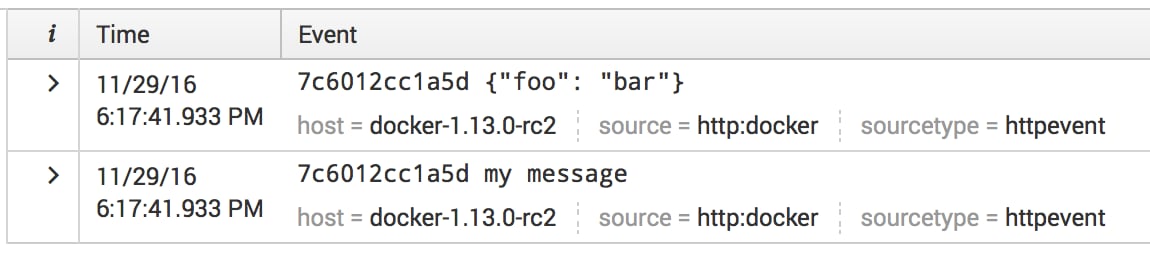
By default all messages are prepended with the value specified in the –log-opt tag, which, by default, has value {{.ID}} (you can read about all other available placeholders in Log tags for logging driver). You can remove tag from the message and for example send container id or name with the –log-opt splunk-source to identify logs from this container in the search
--log-opt splunk-format=raw --log-opt tag="" --log-opt splunk-source=my_container_id
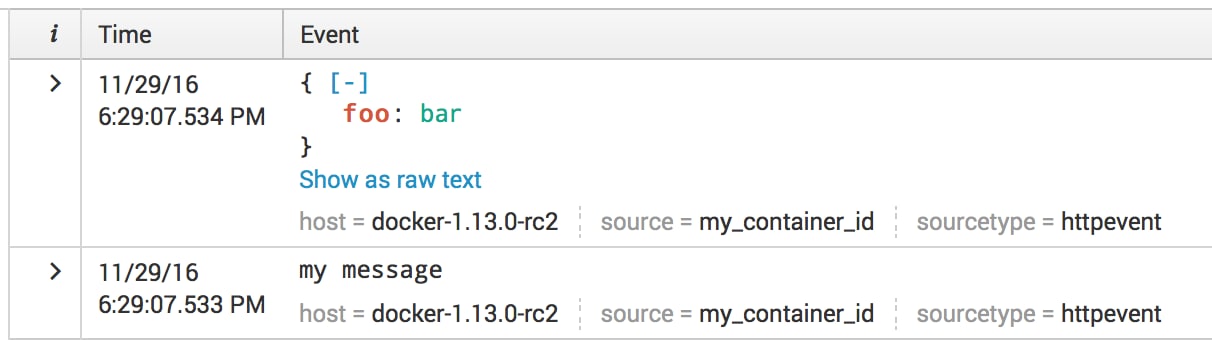
--log-opt splunk-format=json
It is very similar to the inline format, but in JSON format we also trying to parse the message as a valid JSON document, and if we fail we send it as inline string. Because we are parsing every message as JSON – Splunk Logging Driver will have small overhead in the logging pipeline.
The first version of Splunk Logging Driver had very simple implementation. For every line in standard output we were sending one HTTP request to HTTP Event Collector, with one little downside– a huge overhead in the communication protocol. What we have learned from our customers is they might send a lot of messages to standard output. What we have learned from the Docker source code – the buffer between standard output and logging driver is set to 1Mb, in case if the buffer will be full – standard output will be blocked, which might block your application, if you are writing messages to standard output synchronously.
In docker 1.13 we have implemented buffer in the Splunk Logging Driver itself. Which can be configured, but not with the standard –log-opt way, as we did not want to confuse people with these options, because defaults should work in most cases. By default we are batching events in maximum of 1000 per HTTP request and sending them not less often than every 5 seconds. So in case if you are sending just one message in 10 seconds – possible that you will start seeing 5 seconds delay. This can be configured with environment variables, see Advanced options.
In case if you are sending a lot of messages to standard output you will see a huge improvement, for example
time docker run --log-driver=splunk --log-opt splunk-url=http://localhost:8088 --log-opt splunk-token=E055502A-D35D-45F7
-9457-085A9DB9A49F alpine sh -c "seq 1000000" > /dev/null
This simple example generates 1,000,000 lines in standard output. Before our change on my laptop result of time
real 2m52.159s
user 0m0.080s
sys 0m0.110s
After this change
real 0m14.122s
user 0m0.060s
sys 0m0.080s
As you can see the difference is in 12 times.
Because we have implemented our own buffer to improve the performance it was reasonable also to implement a retry logic. By default, we can store in buffer 10,000 events maximum. In case if we will reach this maximum we will start dropping events, one batch in a time. Again, this can be configured with advanced options.
Now that logic works really well with the splunk-verify-connection=false. If you are launching Splunk Enterprise image at the same time as your own application and you have small delay in when HTTP Event Collector will be ready to receive the data.
--log-opt splunk-gzip=false|true
There is slight overhead, as data will need to be compressed. (default is off). Compression is handy in cases where you might be charged a traffic cost between datacenters or clouds. Enabling gzip compression in the Splunk logging driver can help to reduce the cost.
The level of compression can be set with
--log-opt splunk-gzip-level=-1,0,1...9
These numbers comes from gzip package, where -1 is DefaultCompression, 0 is NoCompression and all other numbers are level of compression, where 1 is BestSpeed and 9 is BestCompression.
Unit test code coverage is the most important part of this update. We rewrote almost everything and introduced more complex logic as we wanted to be sure that code will be reliable and manageable. We covered Splunk Logging Driver with the unit tests (80-90% coverage). You can safely try to improve or change Splunk Logging Driver and send PR without worrying that something will be broken.
Enjoy!
----------------------------------------------------
Thanks!
Denis Gladkikh

The Splunk platform removes the barriers between data and action, empowering observability, IT and security teams to ensure their organizations are secure, resilient and innovative.
Founded in 2003, Splunk is a global company — with over 7,500 employees, Splunkers have received over 1,020 patents to date and availability in 21 regions around the world — and offers an open, extensible data platform that supports shared data across any environment so that all teams in an organization can get end-to-end visibility, with context, for every interaction and business process. Build a strong data foundation with Splunk.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2024 Splunk Inc. All rights reserved.
