
Digital Resilience Pays Off
Download this e-book to learn about the role of Digital Resilience across enterprises.

In the first part of this blog series, we presented a use case on how machine learning can help to improve police operations. The use case demonstrates how operational planning can be optimized by means of machine learning techniques using a crime dataset of Chicago. However, this isn’t the only way to predict and prevent crime. Our next example takes us to London to have a look at what NCCGroup’s Paul McDonough and Shashank Raina have worked on.
For any predictive analytics to work, we first need some data. So let’s assume we have access to data that keeps track of various aspects of recorded crimes. Luckily many governments and public administrations provide access to open data, such as data.police.uk. We load this data into Splunk to get the ball rolling. This is the method Paul and Shashank implemented for their presentation at .conf18.
This is what they had to say at the conference: We wanted to showcase that Splunk’s Machine Learning Toolkit can be used on real world problems and help us get better answers. And by doing this we will also present typical steps on how to use Splunk easily for prediction problems. We performed a few basic tasks which can be used on any ML Toolkit Example:
Build Dataset: we used publicly available data for London from government websites like crime information, census, child poverty, income details, etc.
Pre Process Data: to prevent data variance issues in the model, we can run various commands in Splunk like kmeans, analyzefields, anomalousvalue.
Create Predictive Model: we have 6 different types of model creation available: Numerice, Categorical, Numeric Outliers, Categoric Outliers, Forecast Time Series & Numeric Cluster.
Predict Future Values: The model we created in the previous step will be used to predict the future values.
By following the steps above, we created a Predicting Crime Model using the Splunk ML Toolkit app and it gave us an interesting insight into what factors affect the crime levels in London. Below you find our presentation and a blog article explaining in detail the steps we followed.
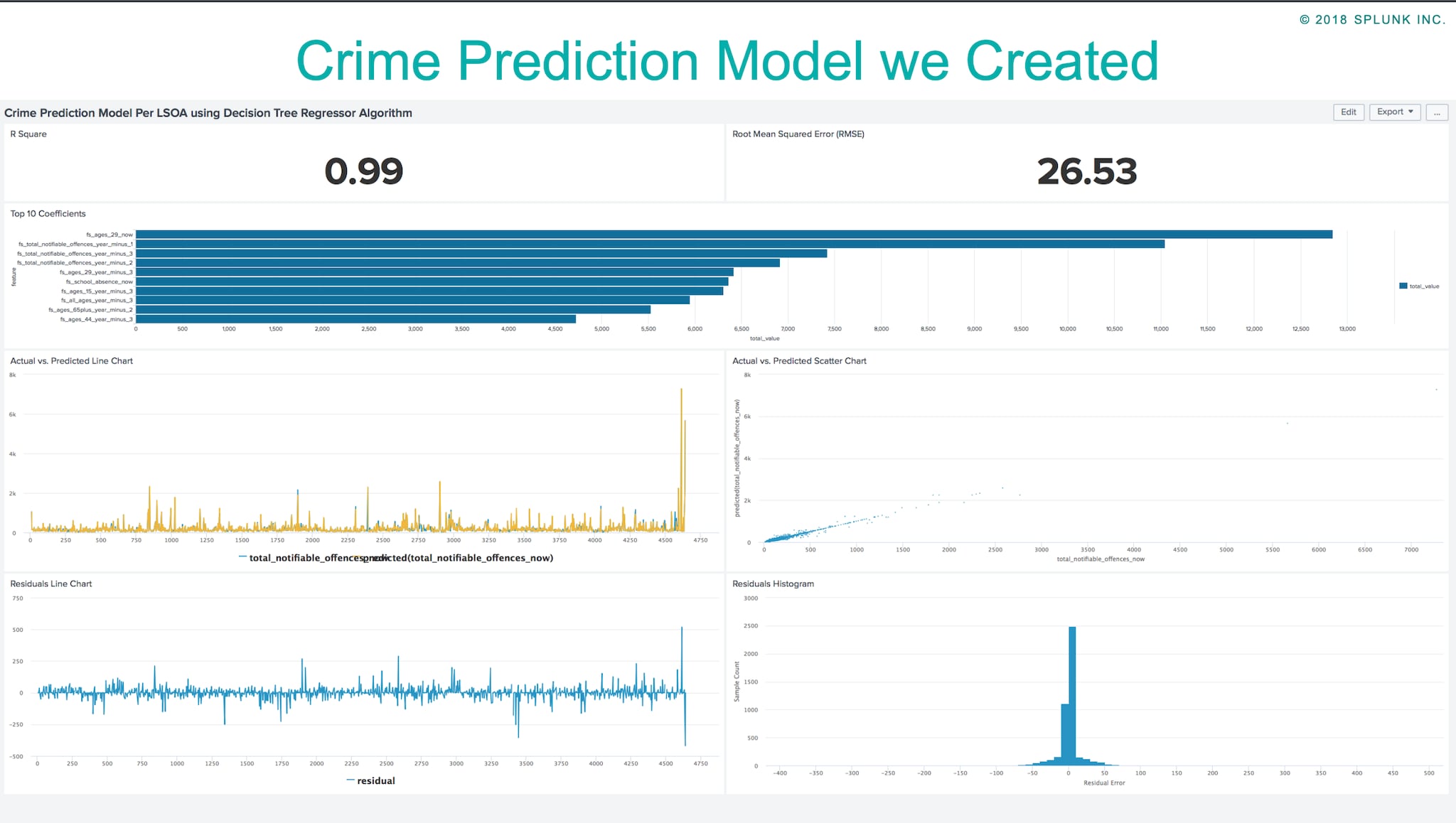
As mentioned before, we presented at Splunk .conf18 and talked about how we can leverage on Splunk ML Toolkit for creating Machine Learning models. As Machine Learning has been a buzzword in the digital world for quite some time, we have taken a step back and to try to understand the effect of the developed models and how they are applied in the real world. Due to ongoing technological advances, we have seen an increased usage of predictive techniques, but we have also observed a large number of reports on machine bias. Examples include:
Amazon shuts down the model to score candidates for employment after realizing that it penalized women.
Predictive policing systems have come under close scrutiny and their use has been curtailed due to discovered biases.
Content personalization systems create filter bubbles and ad ranking systems have been accused of racial and gender profiling.
Bias is defined as prejudice or discrimination against something, someone, or a group. Discriminatory bias is created when data-driven decisions have unbalanced outcomes. The shocking truth is that all big data sets are biased. However, most users creating these models are not aware of it, as ML bias is not a phenomenon that’s being widely discussed. Even if a few are aware of the issue, they wouldn’t know what to do about it anyway. The buzz around the ML has led modelers to focus on creating increasingly complex and big ML models which will help them gain better coverage. Yet few are willing to address the inherent issues of bias in data and the ML models they have developed.
In our presentation at Splunk .conf 2019, we touched on ML Bias and its effects. We also talked about how it can be minimized. Take a closer look here:
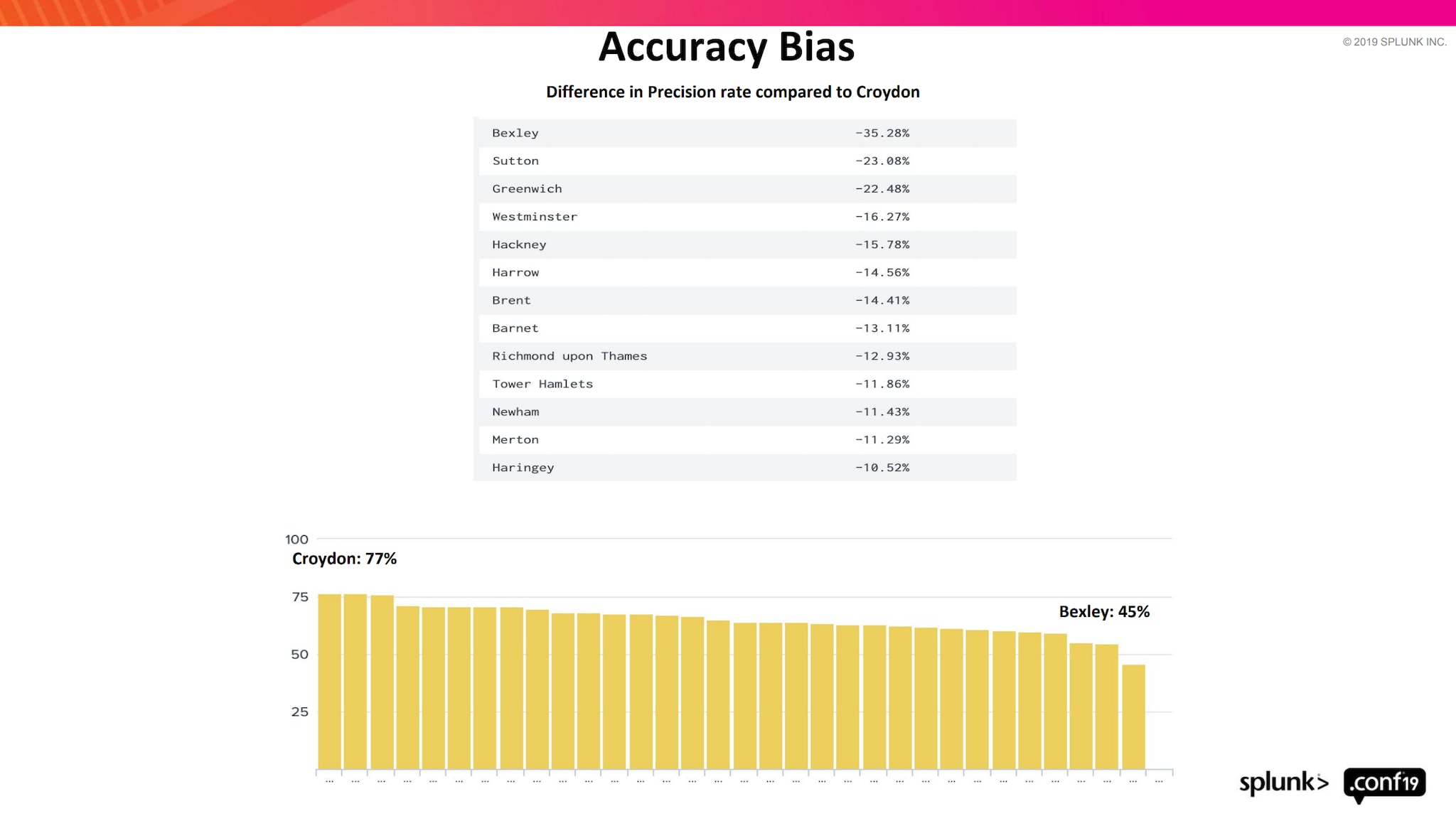
In this blog series, we discussed various aspects related to predicting and preventing crime. The discussion on bias in models tells us just how crucial it is to exercise caution, especially when it comes to models which have direct or indirect effects on people. If you want to delve deeper into this topic please find more bias-related .conf talks and Dipock’s Mind the Gap! for a more in-depth look.
Personally I would like to say a big “THANK YOU” to Shashank from NCC and Paul from 13 Fields who collaborated on the referenced content.
Keep up your great work and happy Splunking,
Philipp

The Splunk platform removes the barriers between data and action, empowering observability, IT and security teams to ensure their organizations are secure, resilient and innovative.
Founded in 2003, Splunk is a global company — with over 7,500 employees, Splunkers have received over 1,020 patents to date and availability in 21 regions around the world — and offers an open, extensible data platform that supports shared data across any environment so that all teams in an organization can get end-to-end visibility, with context, for every interaction and business process. Build a strong data foundation with Splunk.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2024 Splunk Inc. All rights reserved.
