
Digital Resilience Pays Off
Download this e-book to learn about the role of Digital Resilience across enterprises.
Looking forward to my talk on “Turning Data into Leverage” at Velocity in New York next Thursday, I find that the best discussion of metrics monitoring is often the most straightforward and practical. As monitoring evolves from static checks towards metrics time series, we gain a rich source of data from which we can extract value through some basic analysis. Let’s start with a metric most operations folks are already familiar with: CPU utilization.
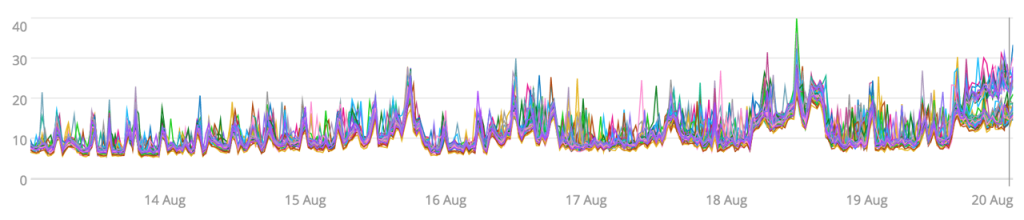
A line graph is one of the most basic ways to visualize a time series and works well if you have a small set of sources (less than 100). Here’s a line graph of the CPU utilization of about 100 servers over the span of a week:
Right away, we get a sense of the range of observed values (hovering between 10% and 20%), direction, and size of trends (pretty flat for most of the week), as well as seasonality, if any exists in the time span (which doesn’t seem to be the case here).
The line graph visualization is fairly busy. There are many sharp peaks across the time series, but it’s not clear if these peaks are representative of the entire cluster or if a few servers are creating noise. A great way to deal with many small deviations is to apply smoothing.
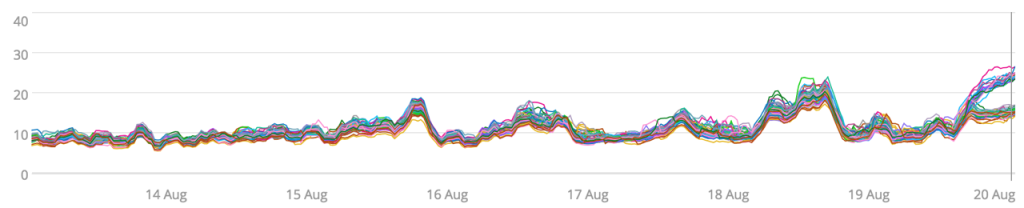
I’ve applied a three-hour moving average on the CPU utilization metric per server. We’ve lost some information (the spikiness) but made the visualization more understandable. We can now easily see some interesting features that were previously hidden in the noise.
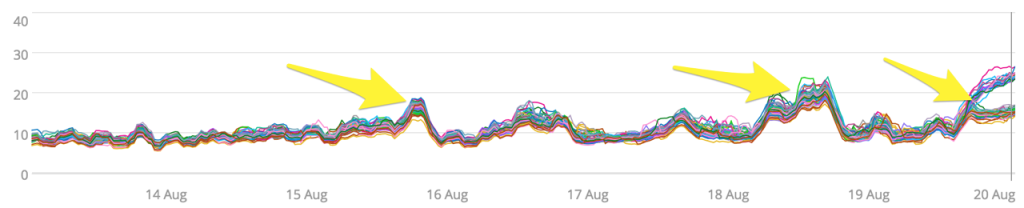
There were two events in which CPU utilization rose across the cluster along with a divergence in CPU load by some of the servers near the end of the week. Let’s walk through some ways of summarizing this data that can be useful in monitoring the cluster.
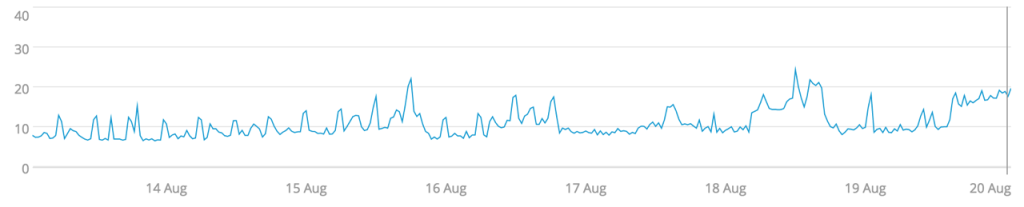
Averages are one of the most familiar ways of summarizing data for many people. We had used averaging across time for smoothing each time series. Now we’re applying the same method across the population to get a single number to represent the cluster over time. The two events where CPU utilization rose is still visible, but the divergence in load is masked. So this could be a good measure of determining when to add or remove capacity from the cluster, but not for load balancing concerns.
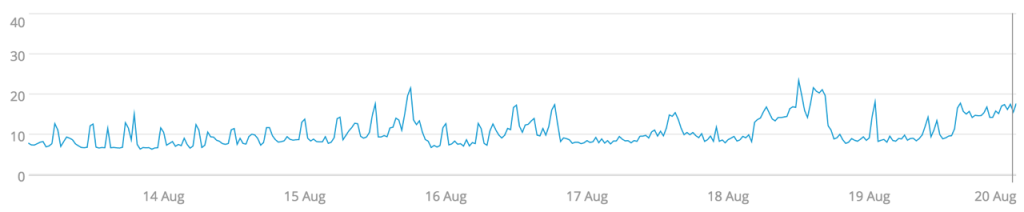
The median for the data set is a summary similar to the average, but it is less prone to outliers skewing the data. Since the median is the value that’s in the middle of the ordered data set, an outlier on the edges of the data has no impact. Skewing is often a common concern with latency timings. If most of your requests complete within 100ms but one comes in at 10 seconds, the average will take the outlier into consideration whereas the median will be 100ms—a better representation of most of the data. For our CPU utilization, this doesn’t matter much because there were no outliers in our data except near the end of the week.
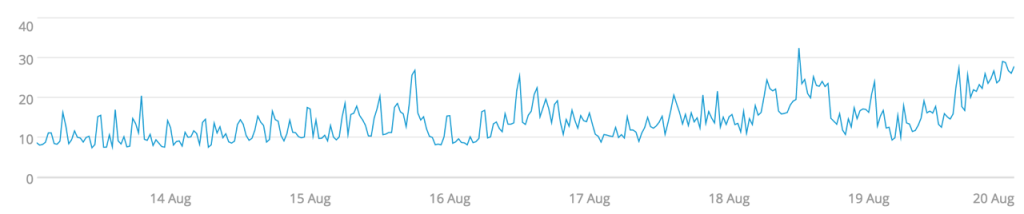
Percentiles are similar to the median in that they refer to a position in an ordered list of values. The 50th percentile is the median—they’re both ways of saying the middle value in an ordered list of values. I’ve often seen percentiles used in application monitoring for selecting the worst latencies, to answer the common question, “What’s the slowest our transaction are taking?” Finding the action maximum is prone to selecting outliers, whereas selecting the 95th or 99th percentile still selects a member that’s representative of that ‘slowest’ group without resorting to the most extreme value.
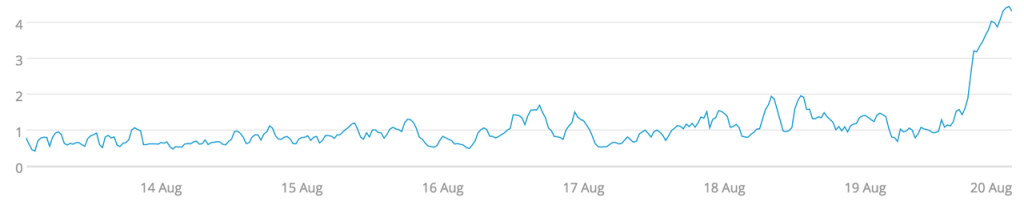
If our servers are meant to share workload, a measure of how ‘alike’ their loads are would be very useful to monitor. This is a measure that standard deviation provides. A low deviation means that we’re well balanced, and a high deviation means a poor balance in our load. Whereas the averaging and percentiles masked our CPU utilization divergence at the end of the week, the standard deviation highlights it. This comes with the expense of some notable data loss. We no longer have a sense of how much CPU load our cluster has, and the two spikes in CPU load aren’t visible, only how balanced that load is.
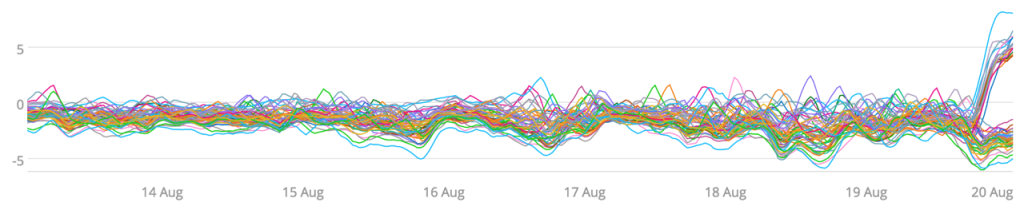
By combining several methods, we can not only see when our load is imbalanced, but also which servers are deviating from the norm. First we need to establish a baseline. In this case we’ll use median absolute deviation (MAD), a similar measure of variance to that of standard deviation, to establish what the norm is. Then we’ll compare each time series against that norm to highlight servers that are outliers. The graph above does this by displaying:
[each server’s CPU utilization] – ([the median of all server’s CPU utilization] + 3 * MAD)
We can now see the servers that have broken away from their peers, which gets us one step closer to resolving the issue of the imbalance. In practice, rather than visualizing this metric, we’ll want automated monitoring to watch for outliers instead, so that we can be immediately notified when servers start displaying anomalous behavior.
Metrics monitoring provides valuable insight into the operations of your systems. Processing these metrics with simple statistical methods can highlight patterns in the noise, or behaviors that you care about. Knowing when to use an average, median, percentile, or standard deviation can help you expose interesting and important behaviors in your system, increasing your overall awareness and catching problems early. Investing in more advanced methods such as outlier detection can help you monitor your systems at granular level by highlighting individual actors that are misbehaving in the context of their peer groups.
Please join me at Velocity Conference in New York on Thursday, September 22 at 9:50am ET to learn more about “Turning Data into Leverage.”
Join our live weekly demo on cloud monitoring »
----------------------------------------------------
Thanks!
Ozan Turgut

The Splunk platform removes the barriers between data and action, empowering observability, IT and security teams to ensure their organizations are secure, resilient and innovative.
Founded in 2003, Splunk is a global company — with over 7,500 employees, Splunkers have received over 1,020 patents to date and availability in 21 regions around the world — and offers an open, extensible data platform that supports shared data across any environment so that all teams in an organization can get end-to-end visibility, with context, for every interaction and business process. Build a strong data foundation with Splunk.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2024 Splunk Inc. All rights reserved.
