
Digital Resilience Pays Off
Download this e-book to learn about the role of Digital Resilience across enterprises.

In previous blog posts, we provided a deep dive into the messaging model of the Apache Pulsar messaging system, which unifies high-performance streaming and flexible queuing. These posts showed how message consumption, acknowledgment, and retention work in Apache Pulsar and contrasted messaging models implemented by Apache Pulsar and Apache Kafka. In this post, I'll walk you through some architectural details and design philosophy behind Apache Pulsar and make some comparisons with Apache Kafka at the end.
Apache Pulsar has a fundamentally layered architecture. An Apache Pulsar cluster is composed of two layers: a stateless serving layer, comprised of a set of brokers that receive and deliver messages, and a stateful persistence layer, comprised of a set of Apache BookKeeper storage nodes called bookies that durably store messages. Figure 1 illustrates a typical installation of Apache Pulsar.
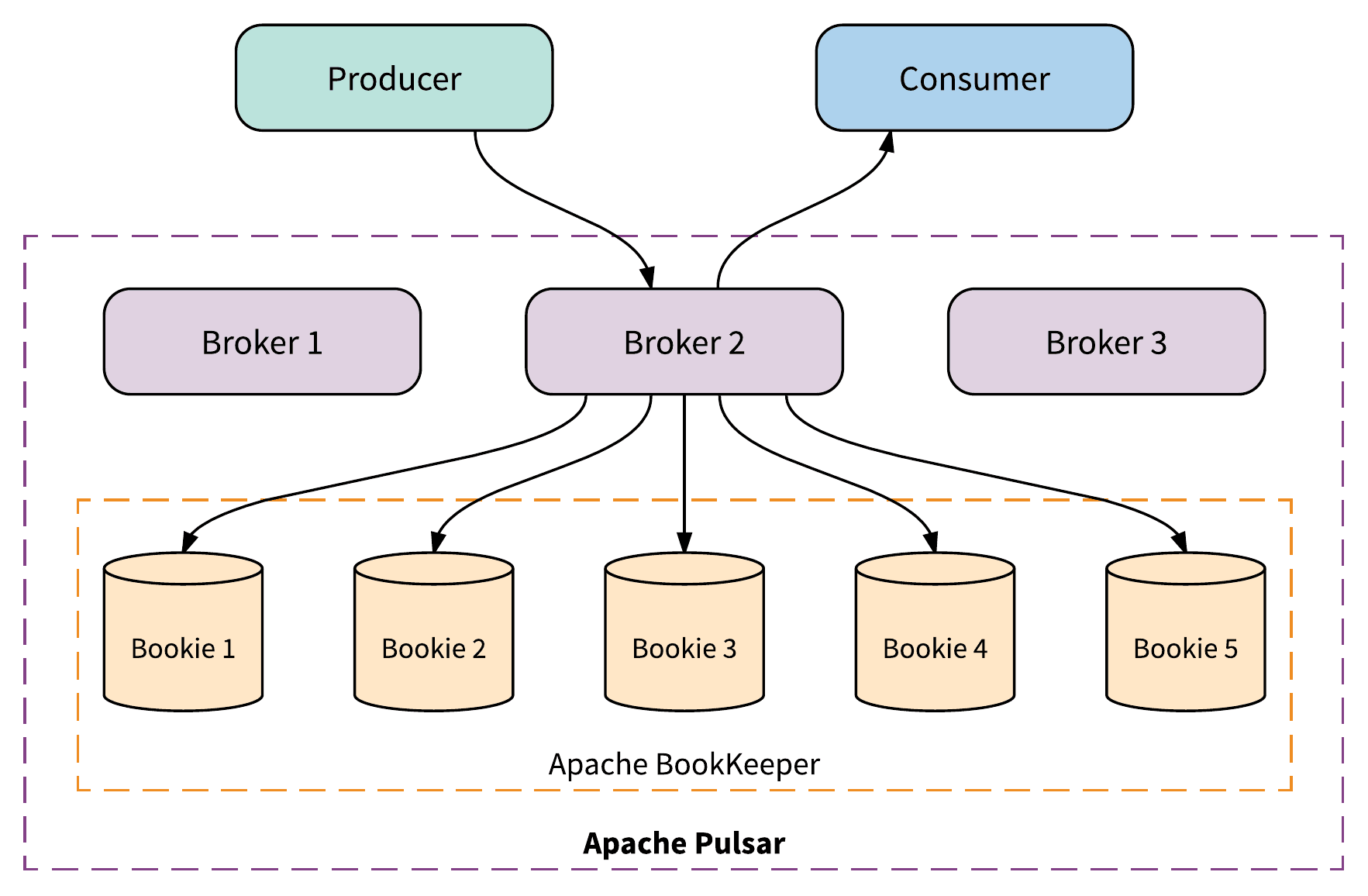 Figure 1. A typical installation of Apache Pulsar
Figure 1. A typical installation of Apache Pulsar
Applications use Pulsar clients to connect to brokers to publish and consume messages. Pulsar clients don't interact with Apache BookKeeper directly. There is also no direct Zookeeper access from clients, providing the isolation needed to implement a single authentication model required for secure multi-tenancy. Apache Pulsar provides multiple language and protocol bindings for clients, including Java, C++, Python, and Websockets. Apache Pulsar also provides a Kafka-compatible API that you can use to migrate existing Kafka applications by simply updating dependencies and pointing the client to a Pulsar cluster. Existing Kafka applications are expected to work with Apache Pulsar immediately and without any code changes.
Brokers form the stateless serving layer in Apache Pulsar. The serving layer is "stateless" because brokers don't actually store any message data locally. Messages on Pulsar topics are instead stored in a distributed log storage system: Apache BookKeeper. We will talk about BookKeeper more in the next section. Each topic partition is assigned by to a broker by Pulsar. The broker that a topic partition is assigned to is called the owner broker of that topic partition. Pulsar producers and consumers connect to the owner broker of a topic partition to produce messages to and consume messages from the owner broker.
If a broker fails, Pulsar automatically moves the topic partitions that were owned by it to the remaining available brokers in the cluster. One thing to call out here: since brokers are “stateless,” Pulsar only transfers ownership from one broker to another when a topic is moved to a different broker. No data is copied during this movement.
Figure 2 illustrates an example 4-broker Pulsar cluster with 4 topic partitions distributed across the brokers. Each broker owns and serves the traffic of one topic partition.
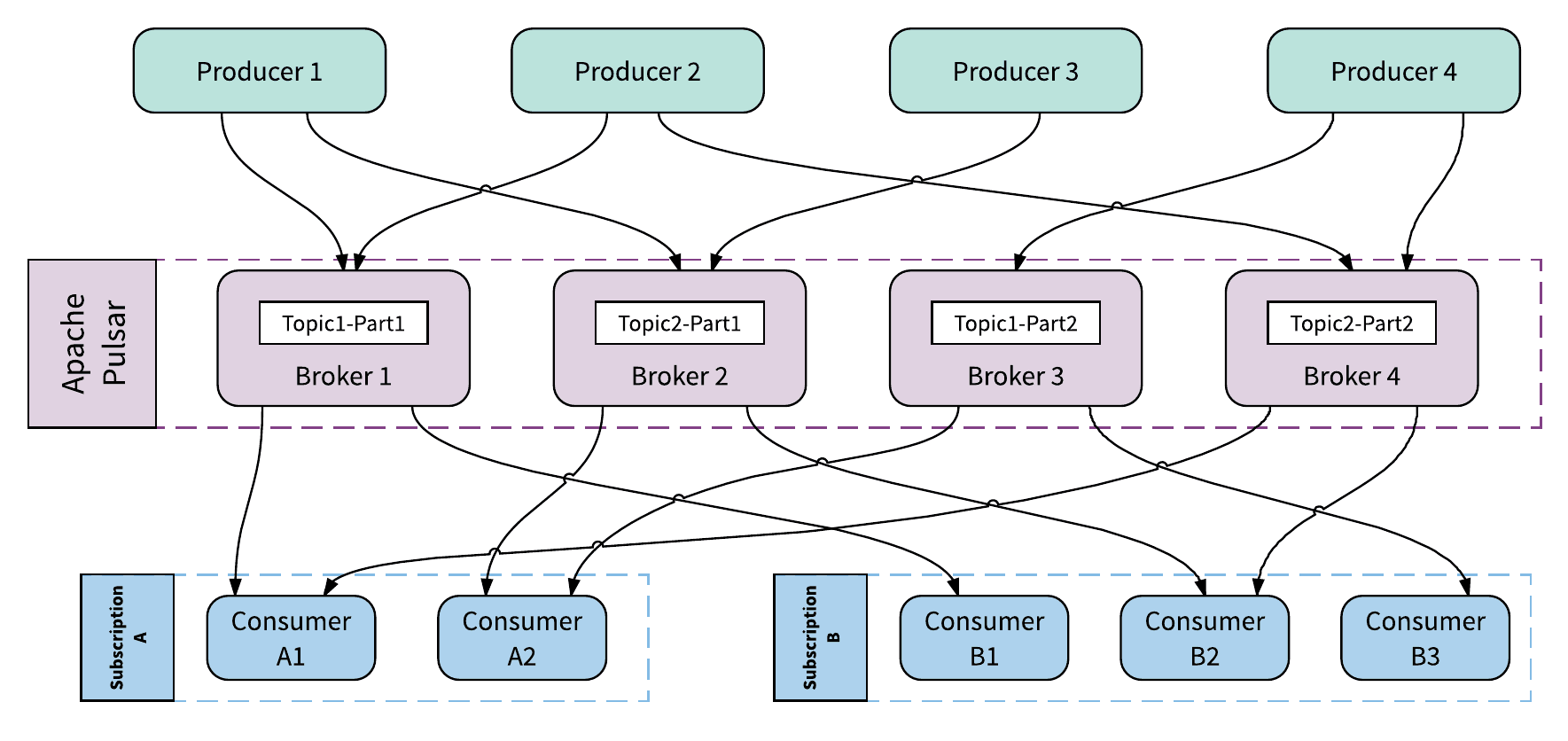 Figure 2. Pulsar brokers
Figure 2. Pulsar brokers
Apache BookKeeper is the persistence layer for Apache Pulsar. Each topic partition in Apache Pulsar is essentially a distributed log stored in Apache BookKeeper.
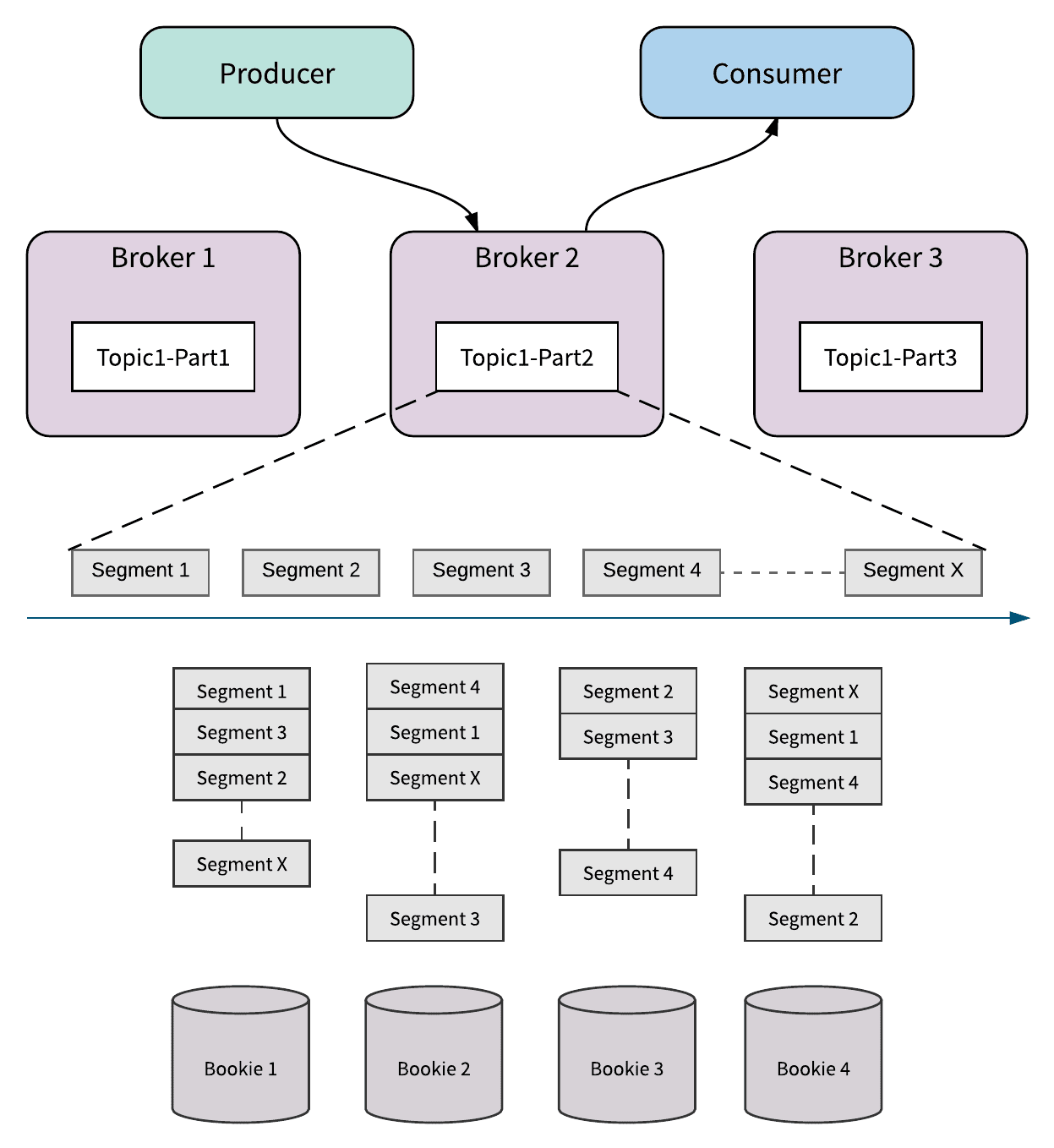 Figure 3. Topic partition, log, and segment
Figure 3. Topic partition, log, and segment
The distributed log is divided into segments. Each segment is stored as an Apache BookKeeper ledger and distributed and stored in multiple bookies (storage nodes of Apache BookKeeper) in the cluster. A new segment is created either after a previous segment has been written for longer than a configured interval (aka time-based rolling), or if the size of the previous segment has reached a configured threshold (aka size-based rolling), or whenever the ownership of topic partition is changed. With segmentation, the messages in a topic partition can be evenly distributed and balanced across all the bookies in the cluster. That means that the capacity of a topic partition is not limited only by the capacity of one node. Instead, it can scale up to the total capacity of the whole BookKeeper cluster.
Figure 3 above illustrates a topic partition that is segmented into x segments. Each segment is stored as 3 replicas. All segments are distributed and stored on 4 bookies.
A fundamentally layered architecture and segment-centric storage are two key design philosophies in Apache Pulsar (with Apache BookKeeper). These two philosophies provide a number of major benefits to Pulsar:
Because topic partitions are broken into segments and stored in a distributed fashion in Apache BookKeeper, the capacity of a topic partition is not limited by the capacity of any smallest node. Instead, topic partitions can scale up to the total capacity of the whole BookKeeper cluster, and scaling up a cluster is achieved by simply adding additional nodes. This is key to using Apache Pulsar to store streaming data for unbounded time periods and to be able to reprocess data in an efficient, distributed fashion. Distributed log storage with Apache BookKeeper is essential to unifying messaging and storage.
Because message serving and storage are separated into two layers, moving a topic partition from one broker to another can happen almost instantly and without any data rebalancing (recopying the data from one node to the other). This characteristic is crucial to many things, such as cluster expansion and fast failure reaction to broker and bookie failures. I will use a few diagrams to explain some of these in more detail below.
Figure 4 illustrates an example of how Pulsar handles broker failure. Broker 2 has gone down for some reason (e.g. a power outage). Pulsar detects that broker 2 is down and immediately transfers the ownership of Topic1-Part2 from Broker 2 to Broker 3. When broker 3 takes over the ownership of Topic1-Part2, it doesn’t need to recopy data from segment 1 to segment 4. The new data is instantly appended and stored as segment x+1 in Topic1-Part2. The segment x+1 is distributed and stored on bookies 1, 2 and 4. Because it doesn't have to recopy the data, the ownership transfer happens instantly without sacrificing the availability of topic partitions.
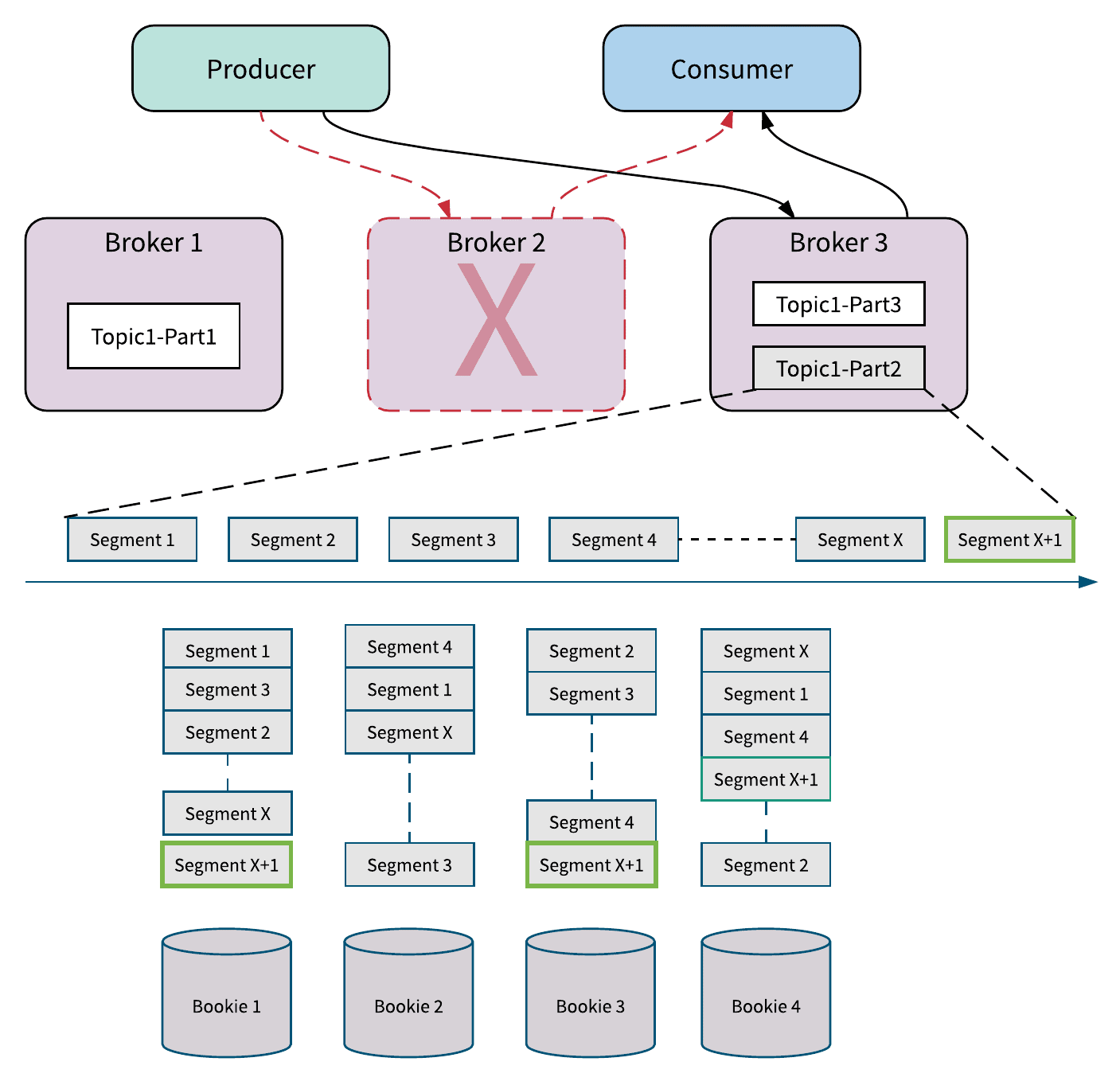
Figure 4. Broker failure
Figure 5 illustrates how Pulsar handles cluster expansion. Bookies X and Y are added to the cluster while broker 2 is writing messages to segment X of Topic1-Part2. Bookies X and Y are instantly discovered by broker 2. Brokers then will try to store the messages of segment X+1 and X+2 to the newly added bookies. The traffic instantly ramps up on the newly added bookies, without recopying any data. Apache BookKeeper offers resource-aware placement policies in addition to rack-aware and region-aware policies to ensure that traffic is balanced across all the storage nodes in the cluster without herding all the newly added empty bookies.
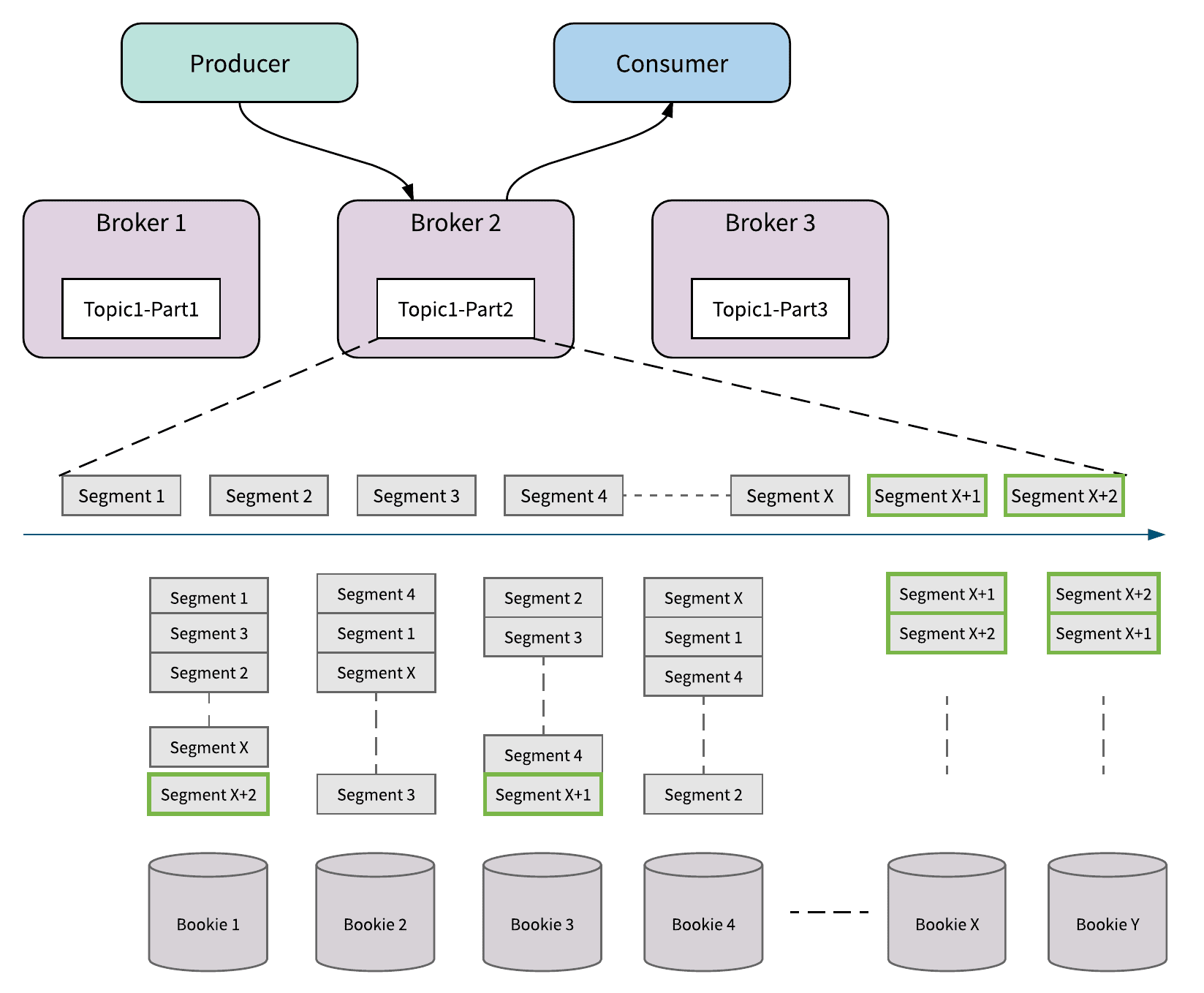
Figure 5. Cluster expansion
Figure 6 illustrates how Pulsar (via Apache BookKeeper) handles bookie or disk failures. Here there's a disk failure causing segment 4 to be broken on bookie 2. Apache BookKeeper will detect this and schedule a replica repair. The replica repair in Apache BookKeeper is a many-to-many fast repair at the segment (even at the entry) level, which is a much finer granularity than recopying the whole topic partition. This means that Apache BookKeeper can read messages from segment 4 from either bookie 3 and bookie 4 and repair segment 4 at bookie 1. All the replica repairs happen in the background. All the brokers can continue accepting writes immediately without sacrificing the availability of topic partitions by swapping in a working bookie to replace the failed bookie for that segment.
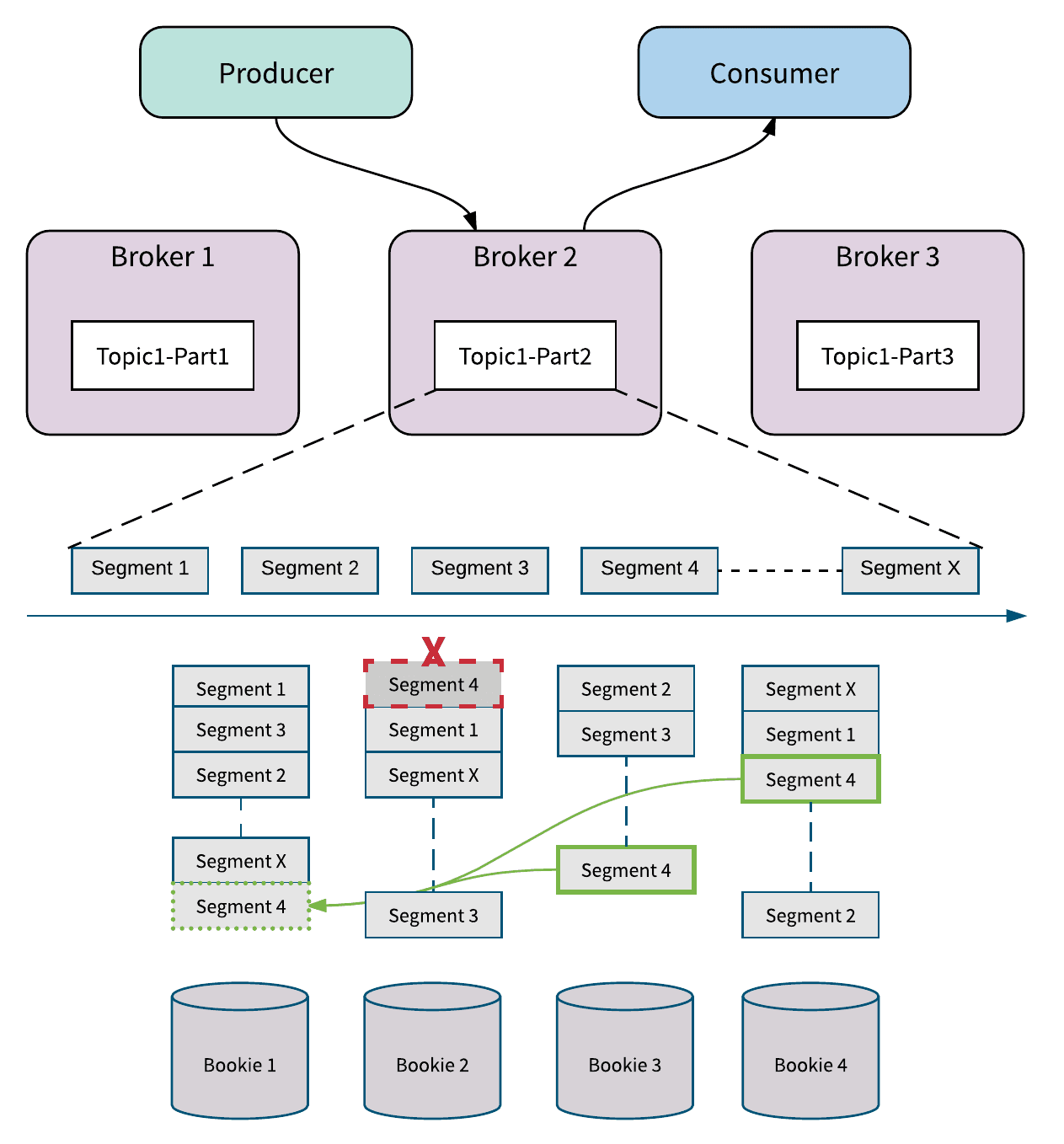
Figure 6. Handling bookie or disk failure
Because the serving and persistence layers are separated, Apache Pulsar can scale serving independently of scaling storage. This provides a much better capacity planning model that can be more cost efficient:
For more details, you can read my previous Why BookKeeper? blog post. We will discuss the replication scheme of BookKeeper in detail in upcoming blog posts and also how it achieves high write and read availability, repeatable read consistency, and low-latency durability.
Both Apache Kafka and Apache Pulsar have similar messaging concepts. Clients interact with both systems via topics. Each topic is partitioned into multiple partitions. However, the fundamental difference between Apache Pulsar and Apache Kafka is that Apache Kafka is a partition-centric pub/sub system while Apache Pulsar is a segment-centric pub/sub system.
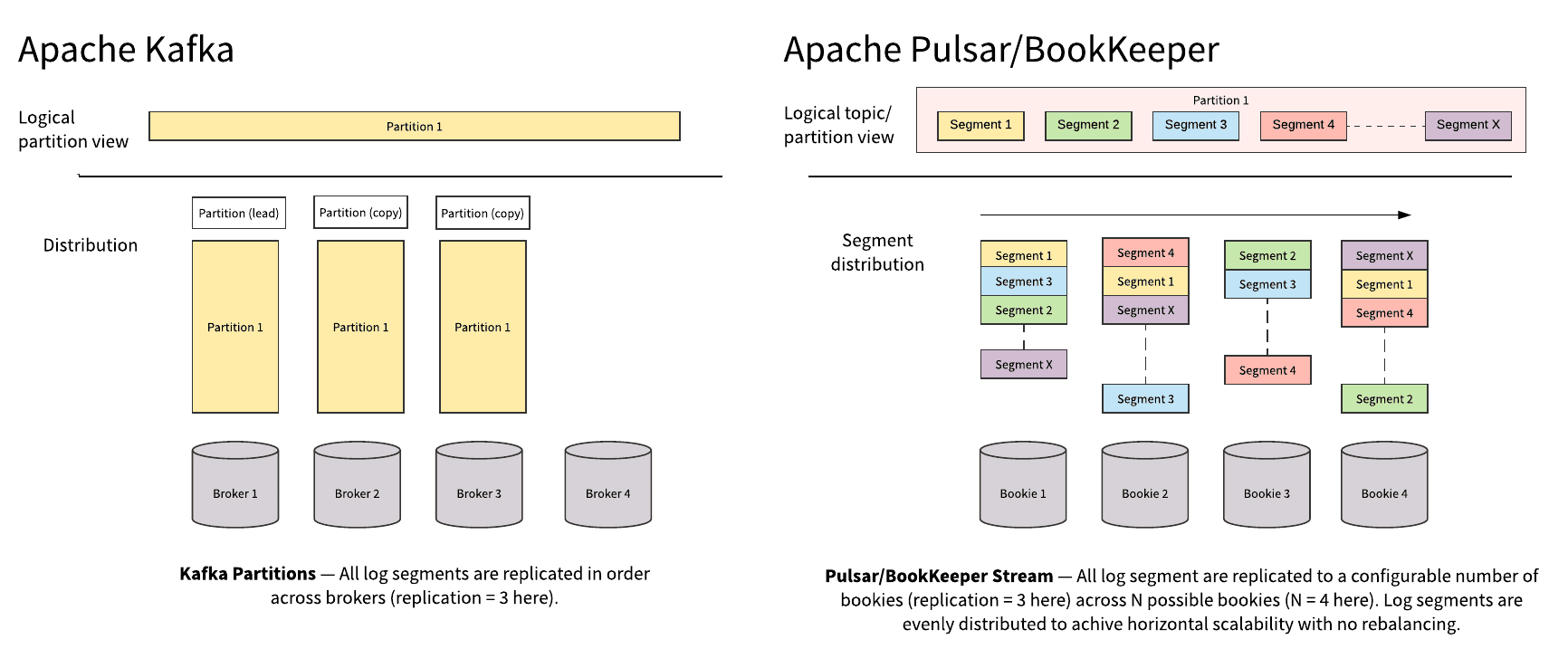
Figure 7. Partition centric versus segment centric
Figure 7 illustrates the difference between a partition-centric and a segment-centric system. In Apache Kafka, a partition can only be stored on a single node and replicated to additional nodes, whose capacity is limited by the capacity of the smallest node. That means that capacity expansion requires partition rebalancing, which in turn requires recopying the whole partition for balancing both data and traffic to the newly added brokers. Recopying data is expensive and error prone and it consumes network bandwidth and I/O. Operators need to be extremely careful when doing this, otherwise it can break production systems easily.
Recopying partition data doesn't only happen on cluster expansion in partition-centric system. Many other things can trigger data recopying, e.g. replica failures, disks failures, or machine failures. During data recopying, partitions are generally unavailable until data recopying is completed. For example, if you have a partition configured to be stored on 3 replicas you have to recopy the whole partition in order to make the partition available again upon losing just one replica. This limitation is often missed until users experience a failure because many use cases are an ingestion-only buffer over a short period. Users will experience inevitable problems more and more often when ingested data accumulates over longer periods.
In Apache Pulsar, in contrast, a partition is segmented over time and distributed across the cluster and designed to efficiently scale. It is segment centric and thus doesn’t require data rebalancing when expanding capacity thanks to using a scalable segment-centric distributed log storage system in Apache BookKeeper. Traffic will instantly and automatically ramp up on new nodes or new partitions, and old data doesn’t have be recopied. By leveraging distributed log storage, Pulsar can maximize segment placement options, achieving high write and read availability. With BookKeeper, for example, with replicas settings equalsto 2, a topic partition is available for write as long as any 2 bookies are up. For read availability, as long as 1 broker is alive in the topic partition’s replica set, you can read it, without having any inconsistencies.
In conclusion, a segment-centric pub/sub messaging system with distributed log storage can provide many advantages as a reliable streaming system including unbounded log storage, Instant scaling without partition rebalancing, fast replica repair,and high write and read availability via maximized data placement options.
In this blog post, I have given an architectural overview of Apache Pulsar. The layered architecture and segment centric design in Apache Pulsar are the two unique design points compared to other streaming messaging systems. Together with previous blog posts, I hope they give you a better idea about Apache Pulsar from an architectural perspective and developer perspective, and you’ve learned the differences between Apache Pulsar and Apache Kafka. In the upcoming blog posts, I will talk about data replication in Apache Pulsar using Apache BookKeeper and how do we achieve low latency durability in Apache Pulsar.
If you are interested in this subject, and want to learn more about Apache Pulsar, please visit the official website at https://pulsar.apache.org. You can also participate in the Pulsar community via:
If you are interested in Apache BookKeeper, you may want to check out the official website at http://bookkeeper.apache.org/. You can also participate in the BookKeeper community via:
For getting the latest updates about Pulsar and BookKeeper, you can follow the projects on Twitter @apache_pulsar and @asfbookkeeper.
Thanks,
Sijie Guo

The Splunk platform removes the barriers between data and action, empowering observability, IT and security teams to ensure their organizations are secure, resilient and innovative.
Founded in 2003, Splunk is a global company — with over 7,500 employees, Splunkers have received over 1,020 patents to date and availability in 21 regions around the world — and offers an open, extensible data platform that supports shared data across any environment so that all teams in an organization can get end-to-end visibility, with context, for every interaction and business process. Build a strong data foundation with Splunk.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2024 Splunk Inc. All rights reserved.
