
Digital Resilience Pays Off
Download this e-book to learn about the role of Digital Resilience across enterprises.
As cyber-security risks and attacks have surged in recent years, identity fraud has become all too familiar for the common, unsuspecting user. You might wonder, “why don’t we have the capabilities to eliminate these incidents of fraud completely?” The reality is that fraud is difficult to characterize as it often requires much contextual information about what was occurring before, during, and after the event of concern in order to identify if any fraudulent behavior was even occurring at all. Cyber-security analysts therefore require a host of tools to monitor and investigate fraudulent behavior; tools capable of dealing with large amounts of disparate data sets. It would be great for these security analysts to have a platform to be able to automatically monitor logs of data in real-time, to raise red flags in accordance to certain risky behavior patterns, and then to be able to investigate trends in the data for fraudulent conduct. That’s where Splunk and Gephi come in.
Gephi is an open-source graph visualization software developed in Java. One technique to investigate fraud, which has gained popularity in recent years, is link analysis. Link analysis entails visualizing all of the data of concern and the relationships between elements to identify any significant or concerning patterns – hence Gephi. Here at Splunk, we integrated Gephi 0.9.1 with Splunk by modifying some of the Gephi source code and by creating an intermediary web server to handle all of the passing of data and communication with the Splunk instance via the Splunk API. Some key features that we implemented were:
Gephi can populate a workspace or enrich the data already contained in a workspace by pulling in properly formatted data. We implemented this by setting up two servers, one of which would act as an intermediary and determine what kinds of data a node could pull in based on it’s nodetype, and another server which contained all the scripts that interacted with a Splunk instance to run Splunk searches, pull back the results, then format it in a way Gephi could already understand.
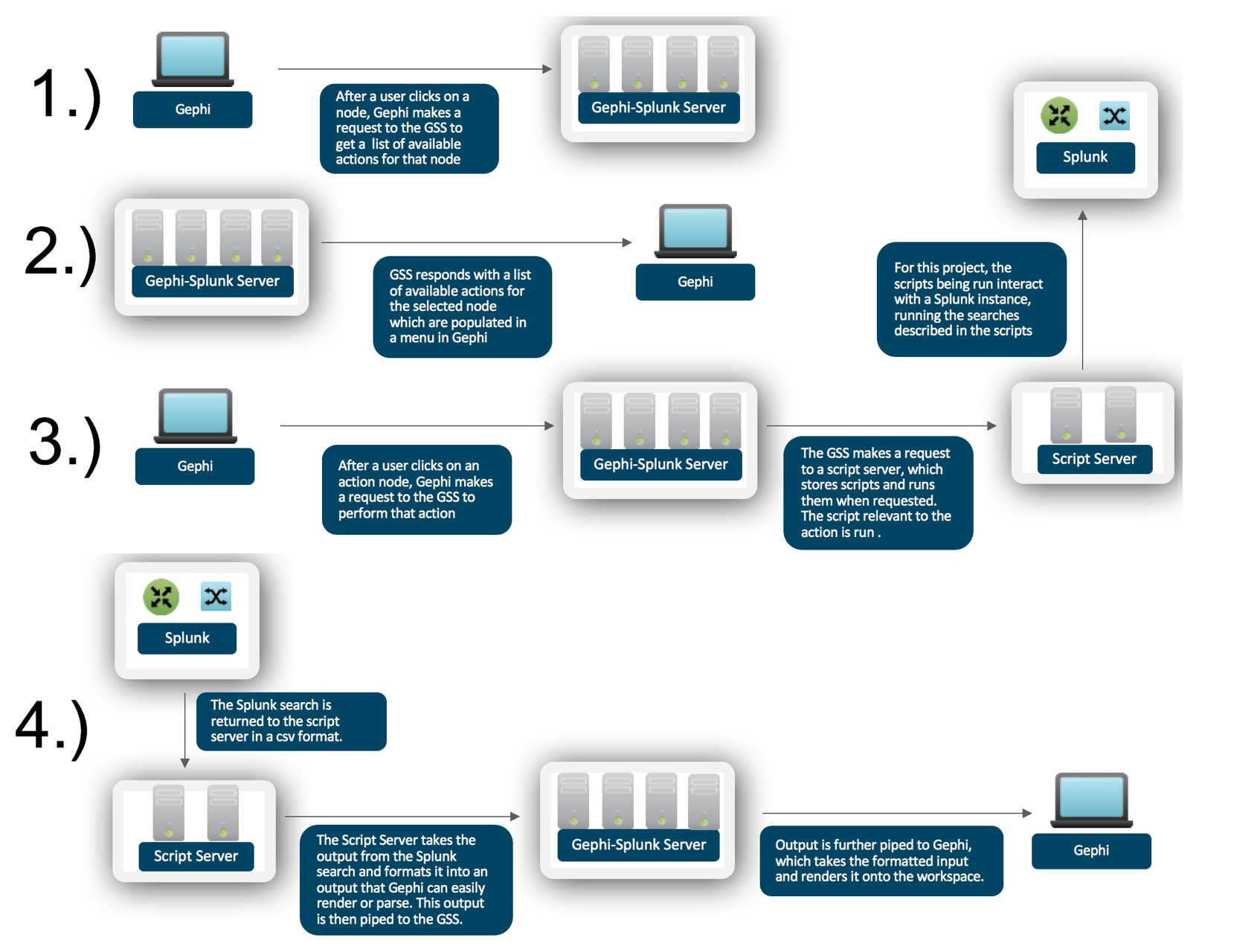
To make all this happen, Gephi makes a GET request to the Gephi-Splunk server (GSS) containing the nodetype, which prompts the GSS to return a list of available actions for that nodetype (Note: The list is statically defined in Gephi to simplify things for the demos). Each of these actions can be used (along with information about the node) to construct another GET request which gets sent again to the GSS then forwarded to a script server to execute that action. The action is completed by running a script held on the script server, actions involving Splunk searches are completed by using Splunk oneshot searches as defined in the Splunk API (http://dev.splunk.com/view/python-sdk/SP-CAAAEE5). The script server takes in the results of the search, formats it, and forwards it to the GSS, which responds to the original request from Gephi with a formatted output that Gephi can render. The architecture is defined visually below.
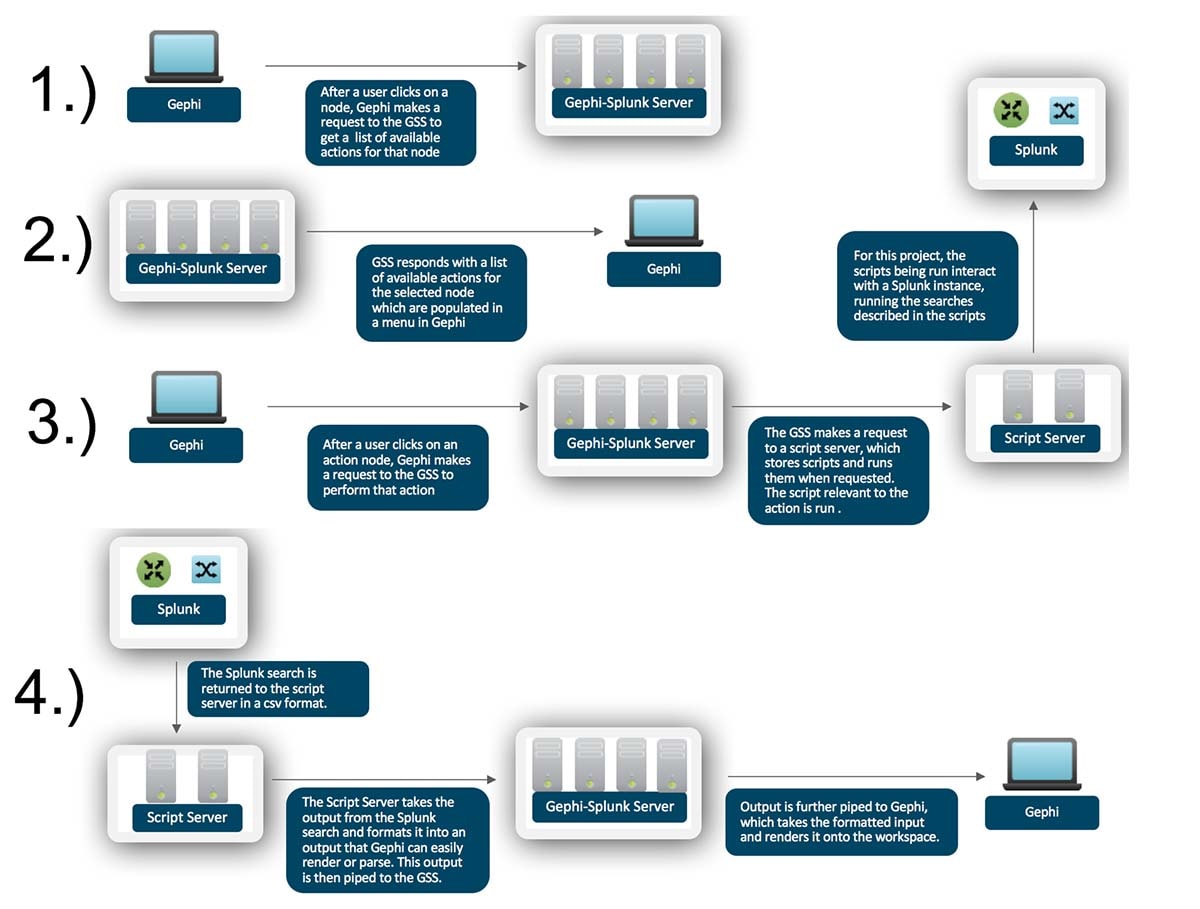
The reason for the separation of servers into a “permissions” server and a script server is to make it easier to expand this project to serve multiple use cases and leverage multiple Splunk instances, while keeping organization simple and limited to a single point. In other words, resources are separated, but management is centralized.
Install by following the instructions here: https://github.com/splunk/gephi-splunk-project/tree/master
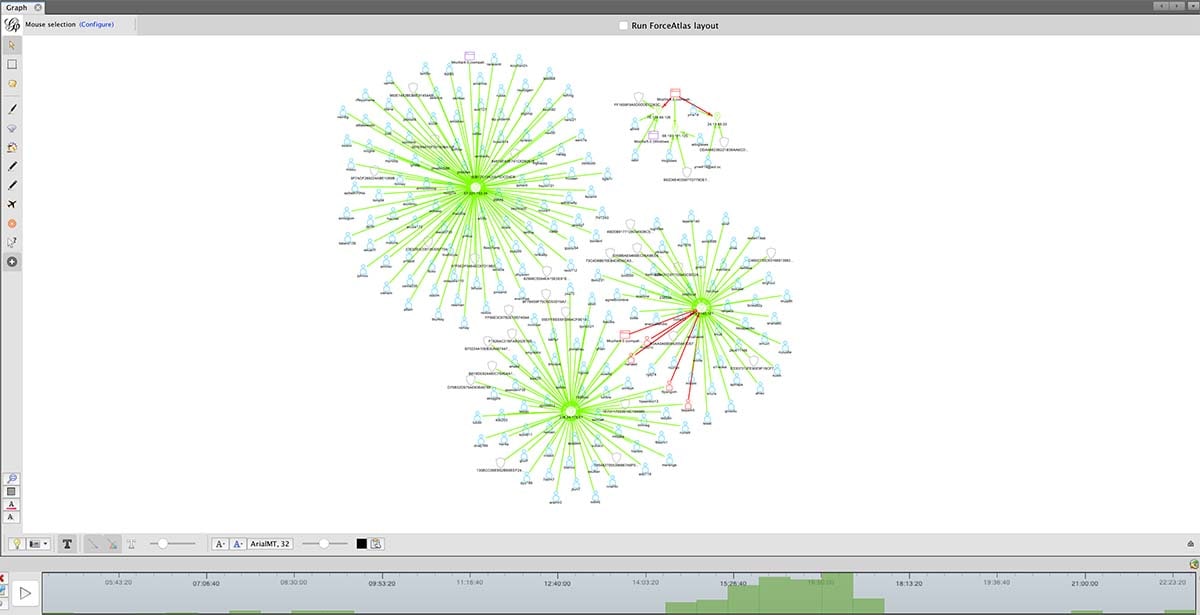
The first screenshot shows a use-case in which an analyst might have six IP addresses to be investigated. The analyst can start out with only the six IP addresses shown on the graph, and then choose to select the “drilldown” menu option to make a call to Splunk for more information. Our Gephi instance will then populate the graph with all of the data received from Splunk, creating nodes with connections if the nodes do not already exist in the visualization, and only adding connections if the nodes do already exist in the visualization. The analyst can also choose to “playback” the data via the timeline to see how events were occurring through time.
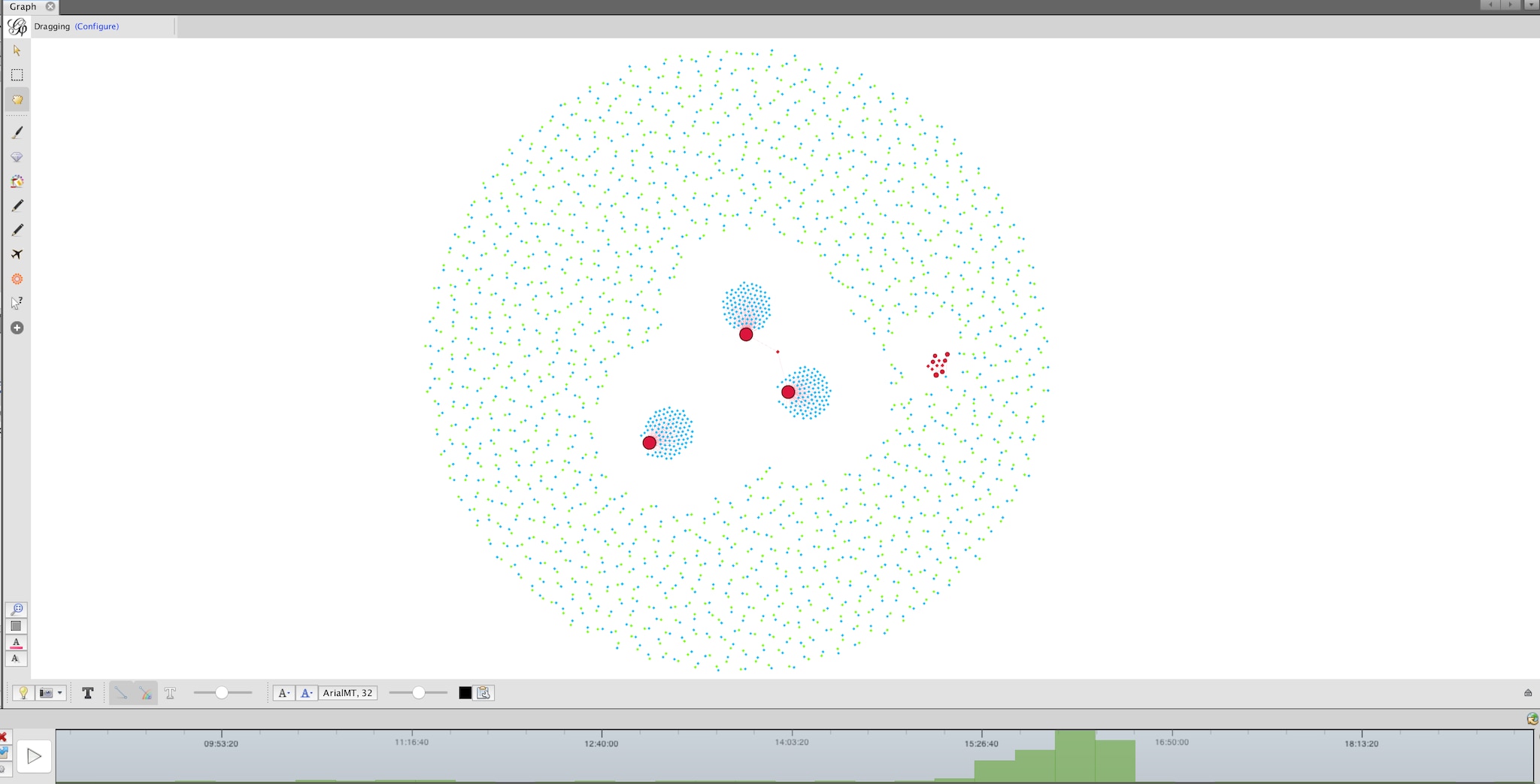
Shown in the second screenshot is a use case in which an analyst might have a large dataset but no clues of where to start investigating. Importing the data into Gephi would allow for recognition of clusters of correlated events (shown as large red nodes in the screenshot). The timeline would also assist in seeing how these resources were being accessed through time.
In addition to anti-fraud use cases, the Gephi + Splunk integration can be applied to any datasets that have cause and effect relationships. The example we provide is of IP address, username, session ID, and user agent data. In order to use other datasets, you will have to change some of the code to display the correct icons and to drilldown into the nodes correctly (see “Altering Data Sources” section of the github docs).
Disclaimer: This integration is provided “as is” and should not be expected to be supported. The application has not been extensively tested with large data sets, so use with caution. Depending on the searches being run in Splunk, and the size of the underlying data set, searches may take a while to complete. The purpose of this application was to provide a proof of concept of using the Splunk API with an open-source graph visualization tool. At the moment, there are no official plans to integrate a graph visualization into the Splunk native web framework. If you intend on adapting this integration for your own uses, please be aware that it will require knowledge and use of Java and Python.
More information about Gephi can be found at their website: https://gephi.org/ and on their github repository: https://github.com/gephi/gephi
If you have any comments, questions, or feedback about this project, please send all inquiries to Joe Goldberg at jgoldberg@splunk.com
Special thanks to the Intern Team (Phillip Tow, Nicolas Stone, and Yue Kang) for making all this possible!
—
Gleb Esman,
Sr. Product Manager, Anti-Fraud

The Splunk platform removes the barriers between data and action, empowering observability, IT and security teams to ensure their organizations are secure, resilient and innovative.
Founded in 2003, Splunk is a global company — with over 7,500 employees, Splunkers have received over 1,020 patents to date and availability in 21 regions around the world — and offers an open, extensible data platform that supports shared data across any environment so that all teams in an organization can get end-to-end visibility, with context, for every interaction and business process. Build a strong data foundation with Splunk.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2024 Splunk Inc. All rights reserved.
