
Digital Resilience Pays Off
Download this e-book to learn about the role of Digital Resilience across enterprises.
This is the second of a two-part series on US healthcare fraud. In part one, we explored how to discover anomalous and potentially fraudulent providers. In part two, we'll look at using the Splunk Machine Learning Toolkit to predict whether a given provider will be excluded from participation.
You can read "Building a $60 Billion Data Model to Stop US Healthcare Fraud (Part 1)" here.

As noted in part one of this series, the data used in this this research work and demo contains approximately 24 million real records collected from the Centers for Medicare and Medicaid (CMS) datasets related to providers' drug prescriptions billed to Medicare, along with supplementary datasets such as payments from drug manufacturers to providers.
They also made available a public dataset related to "exclusions"—the list of providers who were banned from participating in Medicare due to multiple violations, fraud or crimes.
Having that, we decided to apply Splunk Machine Learning Toolkit capabilities to build a model capable of predicting a provider's future exclusion using data about Medicare claims. The idea is to train the model to use available information to calculate the probability of exclusion.
As features for the model, we've used percentages of each drug claim in relationship to total claims per provider. So say the total claim for the provider is $1000 and the Drug_A claim part is $150, then the Drug_A feature value is 0.15. This also helps normalize input data to the size of the practice and only consider percentages per each drug prescribed and billed to Medicare.
Having too many features—especially many less relevant ones—might make the model perform poorly and be difficult to generalize. The Splunk Machine Learning Toolkit makes two commands available to select the best features for classification tasks.
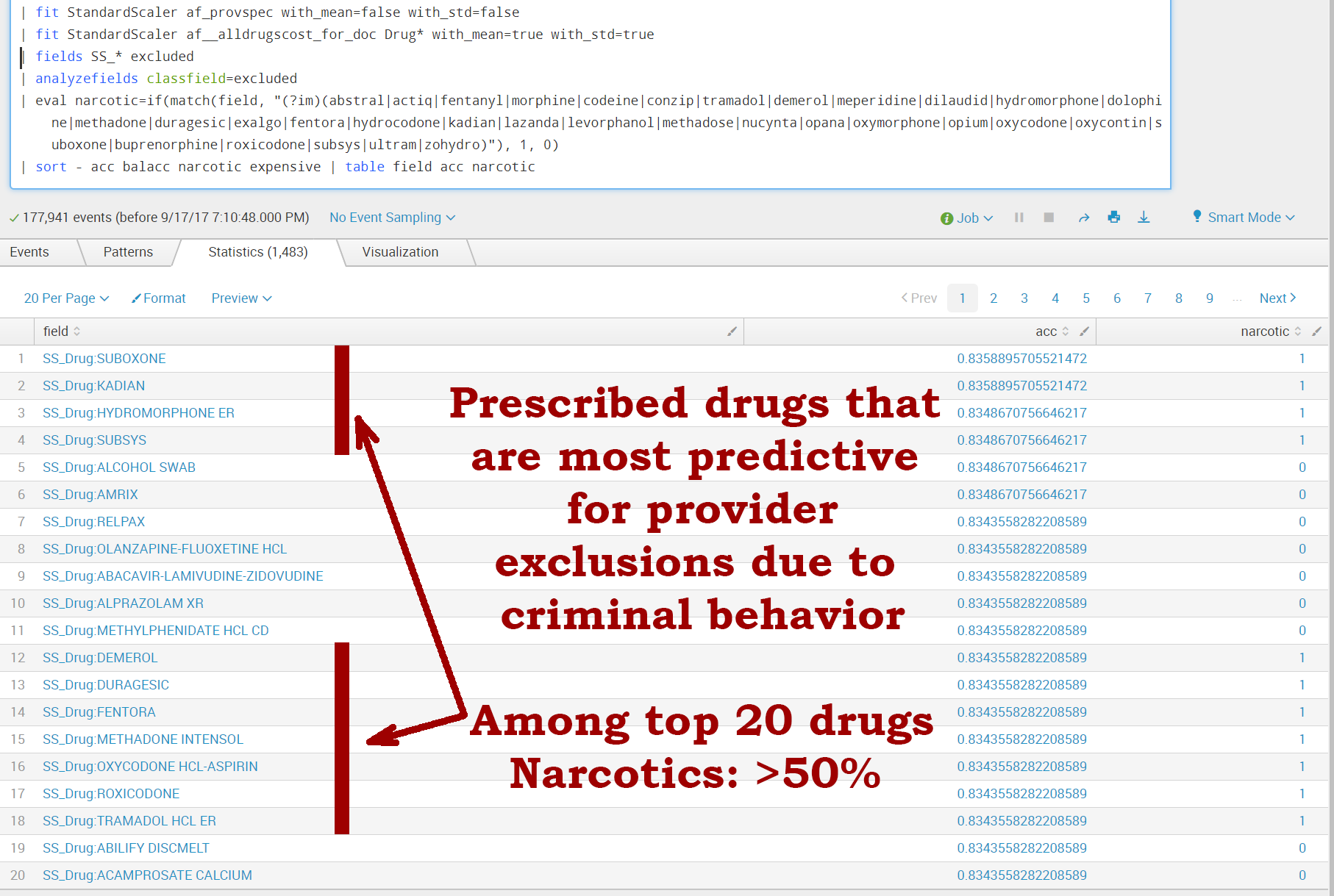
First, the SPL command is 'analyzefields.' This command analyzes all numerical fields to determine the ability of each of those fields to predict the value of the classfield—in our case, "excluded." For each feature, 'analyzefields' creates the accuracy value: 'acc.' This is the ratio of the number of accurate predictions to the total number of events with that field.
Once we run the appropriate SPL query with "... | analyzefields," we notice that more than 50% of drugs in the top 20 are narcotics and opioids. This makes sense due to widespread opioid abuse.
Second, Splunk supports another command to select the features carrying the most predictive powers: 'FieldSelector.' The 'FieldSelector' algorithm selects the best predictor fields based on statistical tests, offering an advantage in that it allows us to automate the process of extracting the most important features and get rid of the "noise."
'FieldSelector' makes copies of the most important features as fs_* fields, and makes it easy to pass them further in the SPL pipeline to fit commands.
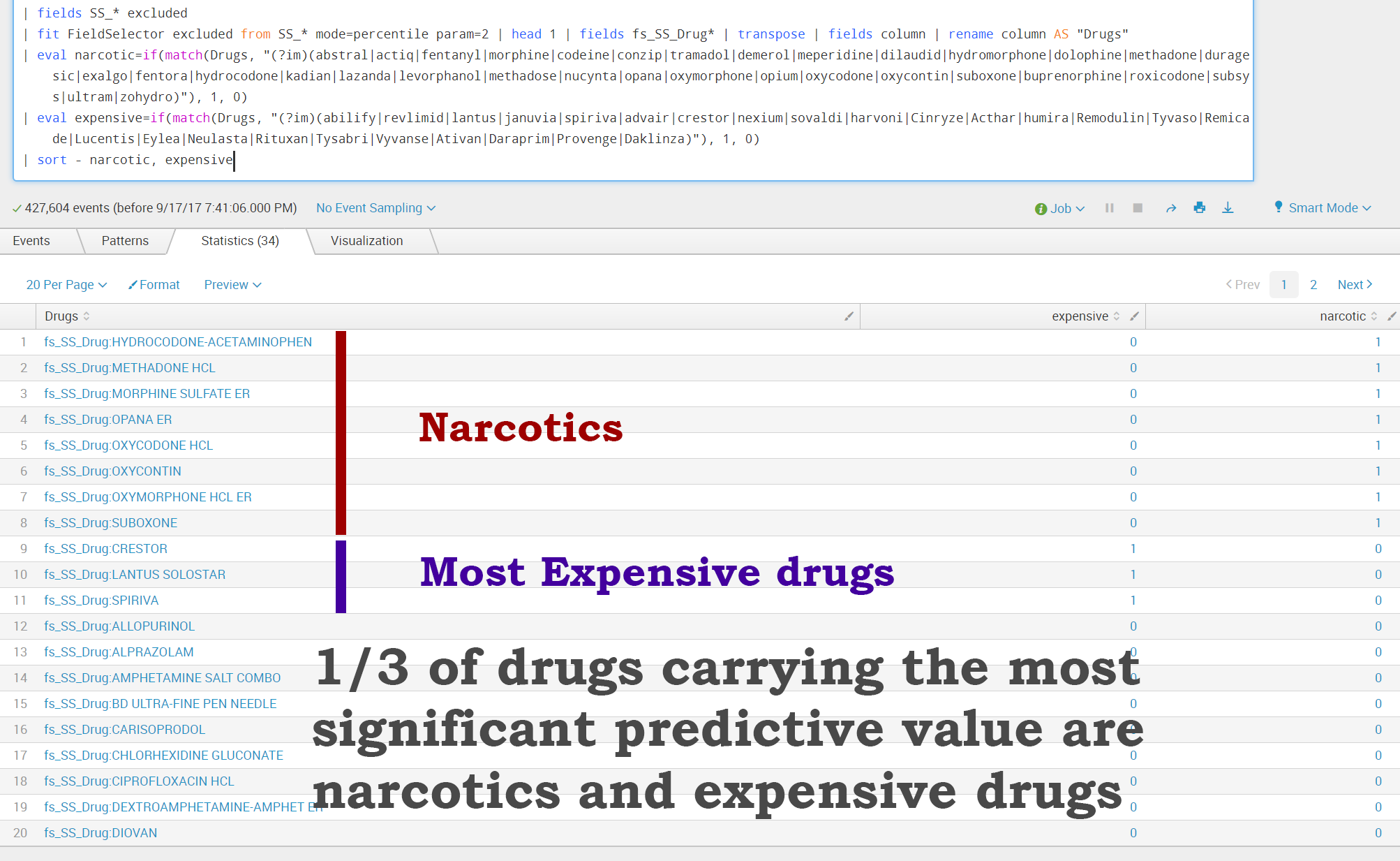
We can see that at least 1/3 of all drugs marked as carrying the highest predictive value are opioids and the most expensive drugs. In order to predict excluded providers, we need to build a model first; this process involves normalizing data (features) into a format that is acceptable by algorithms.
Here's the sequence of SPL that actually trains the model:
... | sample partitions=12 seed=46 | search partition_number<9 | fit StandardScaler Drug* with_mean=true with_std=true into scaler_7b | fit FieldSelector excluded from SS_* mode=percentile param=1.75 into fs_7 | fit SVM excluded from fs_* af_provspec into m_7
'sample' and subsequent 'search' commands are splitting the dataset into training and validation sets—75% and 25%, accordingly.
We want to validate the trained model on the data it hasn't seen before to make sure the prediction estimates are valid.
The '| fit StandardScaler' fragment normalizes data for the actual algorithm. We want to normalize all 'Drug*' fields, which are the percentages of each drug prescribed by each provider.
The '| fit FieldSelector' picks the most valuable fields to predict exclusion. It's interesting to note that the total number of different drugs available within this model-building experiment is more than 1,500.
We call for the 'FieldSelector' algorithm to help pick only the most valuable features (prescribed drugs) that are most predictive for our classification task. Through multiple experiments we determined that it is enough to pick only 1.75% of the total features to get reasonable results.
And the final classification task is based upon the SVM algorithm that's part of the Splunk Machine Learning Toolkit app:
| fit SVM excluded from fs_* af_provspec into m_7
After the training part is done, we want to validate the model.
The validation part is executed by the set of " | apply" SPL commands matching previous 'fit' commands.
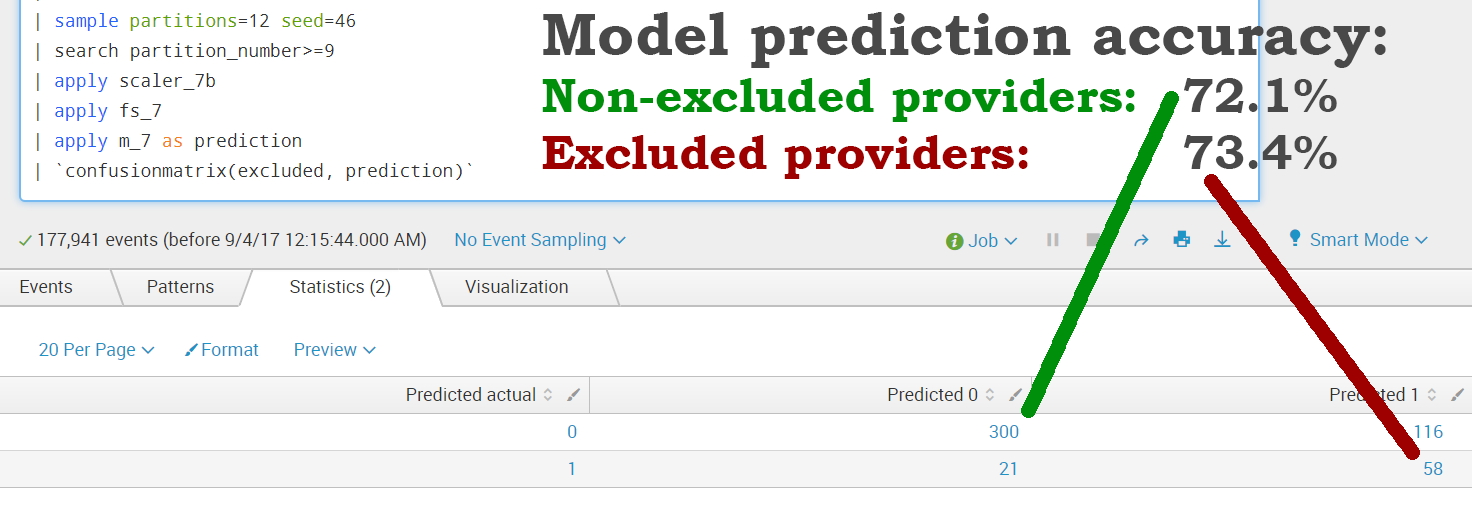
With a rather limited dataset available (we haven't considered any other provider behavior characteristics, only the percentages of drugs billed to Medicare), we were able to achieve a provider exclusion prediction accuracy of 73.4%.
Within the available data, we found 10 providers who were convicted of miscellaneous fraud and violations by the US Justice Department. However, these providers were not listed within the exclusion dataset provided by data.cms.gov. It would be interesting to apply the above trained model to see how it would classify the behavior of these providers.
Here are the results:
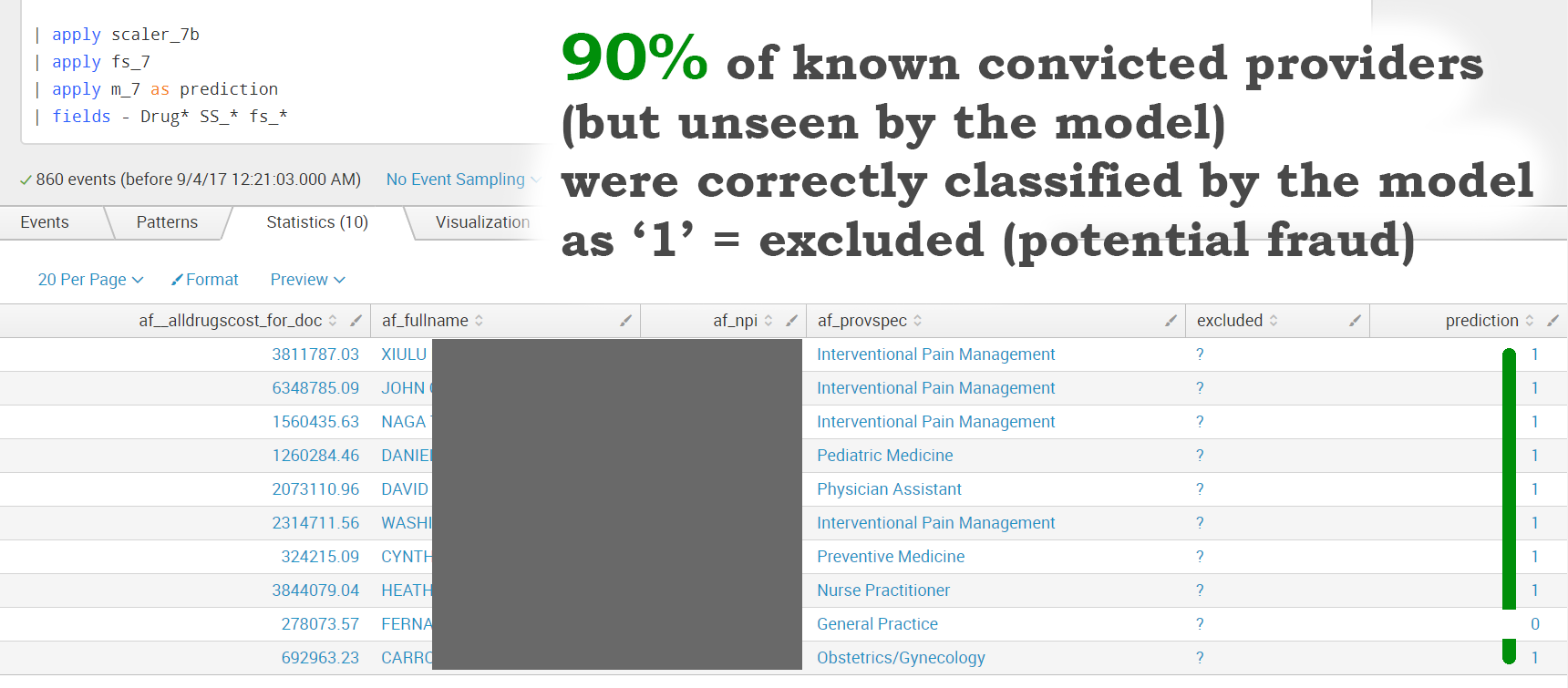
We were able to apply the generated model to previously unseen data (known convicted providers) to correctly predict potentially fraudulent behavior with 90% accuracy!
This shows the value of Splunk combined with the power of machine learning delivered by the Splunk Machine Learning Toolkit to solve a challenging problem and potentially save billions of dollars in losses.
Special thanks to:
Manish Sainani, Director - Product Management, Machine Learning & Advanced Analytics, Splunk
Iman Makaremi, Sr. Data Scientist, Splunk
Alexander Johnson, Sr. Software Engineer, Machine Learning, Splunk

The Splunk platform removes the barriers between data and action, empowering observability, IT and security teams to ensure their organizations are secure, resilient and innovative.
Founded in 2003, Splunk is a global company — with over 7,500 employees, Splunkers have received over 1,020 patents to date and availability in 21 regions around the world — and offers an open, extensible data platform that supports shared data across any environment so that all teams in an organization can get end-to-end visibility, with context, for every interaction and business process. Build a strong data foundation with Splunk.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2024 Splunk Inc. All rights reserved.
