Splunk Connect for Syslog: einsatzfertige, skalierbare Syslog-Datenaufnahme – Teil 3
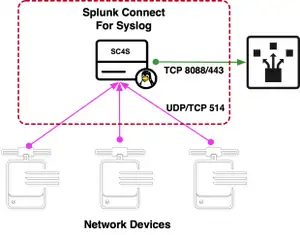
Tips & Tricks SplunkIn Teil 1 und Teil 2 dieser Reihe haben wir die Designphilosophie von Splunk Connect for Syslog (SC4S), die Designziele und die neue HEC-basierte Transportarchitektur sowie die Grundlagen der allgemeinen Konfiguration beschrieben. Wir wenden uns nun den Besonderheiten der SC4S-Konfiguration zu, einschließlich einer Übersicht über das Layout der lokalen (gemounteten) Dateisysteme und der Bereiche, in denen ihr arbeiten werdet.
Konfigurationsebenen und Dateisystemlayout
Die Konfiguration von SC4S erfolgt auf fünf Hauptebenen:
- Erforderliche SC4S-Konfiguration
- Eindeutige Listening-Ports
- Ausweichziele
- Kernel-Einstellungen
- Debug-/Entwicklungseinstellungen
- Festlegen/Überschreiben von Splunk-Metadaten
- Festlegen des Ausgabeformats von Ereignissen
- Festlegen des Log-Pfads auf der Grundlage des eingehenden Hostnamen oder der IP-Adresse
- Hinzufügen von indizierten Kontextfeldern
Compliance-Überschreibungen
Ereignisunterfilter
- Überschreiben von Splunk-Metadaten für eine Teilmenge von Ereignissen
- Hinzufügen indizierter Felder zu einer Teilmenge von Ereignissen
s_<source>.conf
- Hinzufügen einer neuen Datenquelle zu SC4S
- Hinzufügen eines neuen Ziels zu SC4S
- Hinzufügen einer neuen Erfassungsmethode (Quelle) zu SC4S
Wir werden uns all dies der Reihe nach ansehen, aber vorher werfen wir einen genaueren Blick auf die Containerarchitektur und das Konfigurationsverzeichnis von SC4S.

Der Container ist so konfiguriert, dass ein lokaler Satz von Verzeichnissen eingebunden wird, sodass die Konfiguration auch bei einem SC4S-Neustart erhalten bleibt. Dieses Verzeichnis hat die folgende Struktur:

Rot markierte Verzeichnisse und Dateien sind Teil einer SC4S-Standardkonfiguration; sie decken die erforderlichen Komponenten ab, wie die URL und das Token für den Splunk-HEC-Endpunkt (das Standardziel für SC4S-Datenverkehr), ebenso die Konfiguration für Splunk-Metadaten (Index usw.). Die Dateien in den blauen Verzeichnissen enthalten Konfigurationen für lokal konfigurierte Erfassungsmethoden (Quellen), Ausgabeziele und vor allem Log-Pfade (Filter) für Datenquellen, die von SC4S nicht ohne Konfiguration unterstützt werden. Die Erstellung von Log-Pfaden wird in Teil 4 dieser Blog-Reihe behandelt.
In diesem Teil der Serie werden wir uns auf die oben rot gekennzeichneten Dateien und Verzeichnisse konzentrieren. Beginnen wir mit der häufigsten (und erforderlichen) Konfiguration, dem Festlegen von Umgebungsvariablen in der env_file.
Globale und erforderliche Einstellungen (env_file)
Die Konfiguration von SC4S beginnt mit der Festlegung der erforderlichen und der gängigen optionalen Parameter, die für den grundlegenden SC4S-Betrieb erforderlich sind, was mithilfe der env_file erfolgt. Die Datei enthält, wie der Name schon sagt, Umgebungsvariablen, die von der Container-Shell beim Start verwendet werden und auf die sich später der Templating-Prozess bezieht (der in Teil 4 dieser Blog-Serie ausführlich beschrieben wird), um die endgültige syslog-ng-Konfiguration zu erstellen, die SC4S steuert. Hier seht ihr ein Beispiel für eine einfache, aber in vielen Fällen völlig ausreichende env_file:

Ihr seht, dass der Zweck der meisten dieser Variablen bereits aus ihrem Namen ersichtlich ist. Die Variablen hier reichen von den erforderlichen (Splunk-HEC-URL und Token) bis zu den typischen optionalen Variablen, die in der Dokumentation beschrieben sind. Die übrigen optionalen Variablen im Beispiel werden häufig verwendet und haben daher eine Erläuterung verdient:
- SC4S_DEST_SPLUNK_HEC_TLS_VERIFY: Die richtige Festlegung dieser Variable ist kritisch, da die SC4S-Standardeinstellung auf hohe Sicherheit gesetzt ist. Wenn diese Variable nicht angegeben (oder auf „yes“ festgelegt) ist, wird standardmäßig das Serverzertifikat für den HEC-Endpunkt überprüft. In vielen Fällen, insbesondere bei der Erstkonfiguration von SC4S, befindet sich das erforderliche Zertifikat nicht am angegebenen Speicherort (dieser ist hier dokumentiert), und es fließt kein Datenverkehr zum HEC-Endpunkt. In solchen Fällen ist es am besten, wenn ihr mit der auf „no“ festgelegten Variable beginnt und prüft, ob Daten zum HEC-Endpunkt fließen, bevor ihr die Sicherheit für den Produktionsbetrieb verschärft.
- SC4S_USE_REVERSE_DNS: Dies kann sehr nützlich bei Ereignissen sein, für die kein Hostname in der Nutzlast (0der per IP-Adresse) festgelegt ist. Es ist jedoch darauf zu achten, dass der Reverse-DNS-Algorithmus (Nameserver mit Cache) schnell arbeitet, sonst kann es nach der Erfassung Minuten dauern, bis die Ereignisse bei Splunk eingehen.
- SC4S_LISTEN_JUNIPER_NETSCREEN_TCP_PORT: Ihr findet möglicherweise mehrere dieser Listen-Variablen in eurer Datei; sie sind nach Quelle bzw. Technologie dokumentiert. Sie zeigen SC4S an, dass ihr nach einer bestimmten Geräteklasse an einem bestimmten Port (bzw. Ports) lauscht. Achtet unbedingt darauf, dass ihr für mehrere Geräte nicht denselben Port oder sich überschneidende Portbereiche angebt; die Ports müssen für jeden Typ eindeutig sein. Andernfalls gibt es einen Startfehler.
- SC4S_SOURCE_STORE_RAWMSG: Diese Einstellung ist beim Debuggen von Event Flows und/oder beim Entwickeln eines neuen Log-Pfades äußerst hilfreich, wenn ihr eine „nackte“ Syslog-Nachricht benötigt. Achtet jedoch darauf, dass ihr diese Einstellung im Produktionsbetrieb wieder deaktiviert, da sie praktisch den Ressourcenverbrauch in der gesamten Pipeline verdoppelt (bei internem SC4S-Speicher, Datenträger-Warteschlangen und potenziell beim Splunk-Index).
- SC4S_DEST_GLOBAL_ALTERNATES: Diese Variable gibt für den gesamten Datenverkehr eine Liste mit Ausweichzielen an (außer bei HEC). Diese Ausweichziele könnt ihr auch pro Quelle angeben. In der Liste können sowohl von SC4S bereitgestellte (d_hec_debug und d_archive) als auch lokal definierte Ziele angegeben werden.
- SC4S_SOURCE_UDP_SO_RCVBUFF: Diese und die folgende Sockets-Variable sind entscheidend für die Optimierung des UDP-Puffers. Da es sich um ein Send-and-forget-Protokoll handelt, kann der Empfänger dem Sender nicht sagen, dass er „sich mäßigen“ soll. Daher ist eine Anpassung der SC4S-Serverressourcen an die erwartete Datenverkehrslast unbedingt erforderlich, wenn man verworfene Pakete vermeiden will. Oftmals muss diese (in Byte angegebene) Variable auf 32 MB oder mehr festgelegt werden. Der Kernel muss passend abgestimmt sein, sonst wird beim Start eine Warnung ausgegeben.
- SC4S_SOURCE_LISTEN_UDP_SOCKETS: Dies ist eine weitere UDP-Variable, die den Kernel anweist, parallel lauschende Sockets für UDP-Datenverkehr einzurichten. Damit könnt ihr die Skalierbarkeit der zugrunde liegenden Hardware für UDP-Verkehr deutlich verbessern.
Diese Liste ist keineswegs vollständig; sämtliche verfügbaren Variablen, die in dieser Datei festgelegt werden können, findet ihr in der Dokumentation behandelt.
Kontextanpassungen
Die in der env_file enthaltenen Konfigurationen sind für viele Bereitstellungen ausreichend, es gibt aber drei wichtige Bereiche, die darin nicht abgedeckt werden:
- Überschreibungen von Splunk-Metadaten (Index, Host, Quelle und Sourcetyp) sowie
- die Kategorisierung von Daten nach Ursprungshost-Name oder IP-Adresse bzw. CIDR-Block; außerdem die
- Unterkategorisierung von Events (für Compliance-Anforderungen wie PCI).
Das Kontextverzeichnis enthält Lookups und Konfigurationsstubs für syslog-ng, die all diese Anpassungen ermöglichen.
Splunk-Metadaten (splunk_metadata.csv)
Wir vertiefen das in diesem Abschnitt mit ein paar Beispielen. Wir beginnen mit den Dateien, die für die meisten Unternehmen erforderlich sind, wenn sie besondere Indizierungsanforderungen haben: den splunk_metadata.csv*-Dateien, die sich normalerweise im Verzeichnis /opt/sc4s/local/context befinden (siehe das Verzeichnis-Schema oben). Der Zweck dieser Dateien besteht darin, Splunk-Metadaten auf der Grundlage eines Schlüssels (erste Spalte), der im Log-Pfad für die betreffende Datenquelle festgelegt ist, entsprechend zuzuordnen. Diese Dateien funktionieren in Splunk ähnlich wie die Verzeichnisse „default“ und „local“ für Konfigurationsdateien. Die Example-Datei ist so etwas wie die Standardkonfigurationsdatei in Splunk und sollte nicht direkt bearbeitet werden. In der Tat wird die interne Version der Beispielversion dieser Datei nur als Referenz in das lokale Verzeichnis kopiert. Hier seht ihr einen Ausschnitt:

Ihr könnt diese Datei durchsuchen, damit ihr wisst, welcher Index (und andere Metadaten) standardmäßig in SC4S festgelegt ist (diese Einträge sind auch dokumentiert). Die Datei hat dieses Format:
anbieter_produkt,metadaten,wert
Dabei ist anbieter_produkt ein beliebiger Schlüssel, der vom Autor des Log-Pfades gemäß der Konvention mit Anbieter (z. B. Cisco) und Produkt (z. B. ASA) angegeben wird, getrennt durch einen Unterstrich. In den meisten Fällen werden Kleinbuchstaben verwendet, Ausnahmen sind die Quellen CEF und LEEF, bei denen sich diese Werte aus dem Event ableiten und keine freie Wahl des Log-Pfad-Autors sind. Für alle von SC4S unterstützten Datenquellen (und die Standardwerte für Index/Sourcetyp) sind die Schlüssel im Abschnitt „Quelle“ der Dokumentation niedergelegt. Eine vollständige Liste der verfügbaren Überschreibungen ist hier verfügbar; sie umfasst auch Vorlagen für alternative Ausgaben (die steuern, wie ein Ereignis in Splunk dargestellt wird) sowie herkömmliche Metadaten. Pro Zeile kann nur ein Metadatenelement festgelegt werden. Wenn ihr mehr als ein Metadatenelement für dieselbe Quelle festlegen oder überschreiben müsst, könnt ihr denselben Schlüssel in mehreren Zeilen verwenden.
Wenn ihr ein bestimmtes Metadatenelement überschreiben müsst (meistens ist das der Index), könnt ihr die Datei splunk_metadata.csv (ohne die Beispielerweiterung) bearbeiten und einen oder mehrere Einträge überschreiben. Die lokale (Nicht-Beispiel-)Datei könnt ihr auch verwenden, um Standardmetadaten für neue Log-Pfade anzugeben (das werden wir uns in Teil 4 dieser Blog-Reihe genauer ansehen):

Ähnlich wie lokale .conf-Dateien in Splunk ist diese Datei viel kürzer als der Standard. Sie sieht lediglich ein Überschreiben des Cisco-ASA-Index sowie einen neuen Eintrag für das Gerät StealthINTERCEPT vor, der in der Beispieldatei überhaupt nicht vorkommt (da er nicht zum Lieferumfang von SC4S gehört). Dieser letzte Eintrag ist für unseren neuen Log-Pfad, den wir in Teil4 behandeln werden.
Ereignis-Kategorisierung nach Anbieter/Produkt (Kontextfilter)
Wenn Ereignisse bei SC4S eingehen, müssen sie ordentlich kategorisiert werden, damit der richtige Sourcetyp und weitere Splunk-Metadaten angewendet werden können. Wenn ein Ereignis über seinen eigenen, eindeutigen TCP- oder UDP-Port erfasst wird, ist diese Kategorisierung einfach. Häufiger muss das Ereignis jedoch über den UDP-Standardport 514 erfasst werden, der historisch für Syslog-Verkehr reserviert ist und auf jeden Fall Ereignisse von vielen verschiedenen Gerätetypen empfängt. In diesem Fall wird der Inhalt des Ereignisses (die Nutzlast) untersucht, damit das Ereignis an den richtigen Log-Pfad weitergeleitet wird, der das Ereignis weiter analysiert und die richtigen Metadaten zuweist. Dies funktioniert zwar für die meisten Gerätetypen, doch es gibt eine kleine, aber wichtige Menge von Geräten, deren Nutzlast nicht ausreichend eindeutig ist, als dass man sie mit Sicherheit kategorisieren könnte.
Diesem Umstand trägt SC4S mit der Möglichkeit Rechnung, Ereignisse auf der Grundlage des Namens oder der IP-/CIDR-Adresse des sendenden Hosts zu kategorisieren (filtern), bevor überhaupt eine Untersuchung der Nutzdaten erfolgt. Wenn der Filter (die Filterregel) für ein Ereignis mit einem bestimmten Hostnamen und/oder einer bestimmten IP-Quelladresse ausgelöst wird, wird eine Lookup-Datei zurate gezogen und damit eine interne Variable auf eine für den Anbieter und Produkttyp eindeutige Zeichenfolge festgelegt. Diese Variable wird ihrerseits als ein (separater) Filter in einem Log-Pfad verwendet, der für diese bestimmte Anbieter-Produkt-Kombination erstellt wurde, sodass das Ereignis an den richtigen Log-Pfad geroutet wird, unabhängig von seinem Nutzlastinhalt. Wir werden uns die Verbindung von Kontextfilter, Lookup-Datei und Log-Pfad-Filter gleich unten an einem Beispiel ansehen.
Zunächst aber noch eine Mahnung zur Vorsicht: Bei dieser Anpassungsebene ist zum ersten Mal ein zumindest rudimentäres Verständnis der syslog-ng-Syntax erforderlich, da die Regeln selbst ebenso wie die von ihnen berücksichtigten Nachschlagevorgänge „echte“ syslog-ng-Konfigurationen sind, die in der lokalen Verzeichnisstruktur zur Verfügung stehen. Wenn diese Dateien fehlerhaft konfiguriert sind, kennzeichnet der Start-Parser von syslog-ng die Fehler, weist beim Start auf sie hin und bricht den Start ab. Aber keine Sorge, es gibt gut mit Daten bestückte Beispieldateien, die euch als Vorlage für die meisten Anwendungsfälle dienen können, und die gehen wir jetzt durch.
Und los geht’s. Die primären Kontextdateien befinden sich unter /opt/sc4s/local/context. Es sind zwei:
vendor_product_by_source.conf
vendor_product_by_source.csv
Der Umgang mit diesen Dateien unterscheidet sich von der typischen Splunk „default/local“-Konvention, die für splunk_metadata.csv verwendet wird. Die ordnungsgemäße Verwendung setzt voraus, dass die Dateien vollständig sind (mit anderen Worten: dass die Example-Dateien überhaupt nicht abgefragt werden). Daher empfiehlt es sich, die Beispieldateien in die Dateien mit den regulären Endungen zu kopieren, bevor ihr mit der Verwendung/Bearbeitung beginnt.
Hier haben wir die Datei vendor_product_by_source.conf:

Ihr werdet bemerken, dass es sich um eine Reihe von syslog-ng-Filtern handelt, die nach jedem beliebigen syslog-ng-„Makro“ (Feld) filtern können, jedoch werden nur Host und Netzmaske verwendet, weil dies (wie bereits besprochen) die einzigen Felder sind, die man mit Sicherheit verwenden kann, bevor die Nutzlast weiter verarbeitet wird. SC4S prüft diese Filter (Regeln) schon sehr früh im Datenpfad, gleich nachdem die rudimentären Syslog-Parser ausgeführt worden sind und vor jeglicher Nutzdatenfilterung.
In diesem Beispiel ist in Zeile 11 ein Filter für Juniper-NetScreen-Geräte mit dem Hostnamen jpns-* markiert (der Typ „glob“ zeigt an, dass es sich um ein Platzhalterzeichen und nicht um einen regulären Ausdruck handelt). Die Netzmaske ist in diesem Fall auskommentiert, aber wenn sie bekannt ist, kann sie einfach angewendet werden. Ihr seht auch, dass diese Datei keinen Hinweis darauf gibt, welche Kategorisierung angewendet werden soll – hier kommt die zweite (Lookup-)Datei vendor_product_by_source.csv ins Spiel:

Dieser Lookup weist die gleiche dreispaltige Struktur auf wie die für Splunk-Metadaten verwendete splunk_metadata.csv-Datei, allerdings sind die Felder und die festgelegten Werte ganz anders und verweisen nicht direkt auf irgendwelche Splunk-Metadaten. Das Geheimnis dieser Dateien liegt in der Verwendung des Lookup-Schlüssels: Ihr werdet feststellen, dass der Filtername in der confDatei (Zeile 11) mit einem oder mehreren Schlüsseln im CSV-Lookup (Zeile 7) übereinstimmt. Wenn der Filter in der conf-Datei ausgelöst wird, legt dieser Link ein internes Feld namens fields.sc4s_vendor_product fest. Diese Variable wird ihrerseits in einem einfachen Filter verwendet, der nach dem Wert dieser Variable in einem Log-Pfad sucht, der für diese spezielle Kombination von Anbieter und Produkt erstellt worden ist, in diesem Fall für Juniper NetScreen:

Ihr fragt euch vielleicht, warum wir statt dieses indirekten Ansatzes mit einem internen Feld nicht den ursprünglichen Filter im Log-Hauptpfad verwenden (der direkt darüber zu sehen ist). Der Grund dafür ist, dass Administratoren auf diese Weise Hostnamen-/CIDR-Filter mit einer minimalen Menge an (wiederholbarem) syslog-ng-Code festlegen können und – was noch wichtiger ist – dass sie keinen Zugriff auf den Log-Hauptpfad benötigen, der innerhalb des Containers unzugänglich ist. In vorliegenden Fall muss sich die Zeile 43 im Log-Hauptpfad (der innerhalb des Containers verborgen ist) niemals ändern, sondern wird stattdessen von den Filtern und Lookups in den vendor_product_by_source.*-Dateien gesteuert.
Compliance-Überschreibungen (Ereignisunterfilter)
Es gibt noch einen zweiten Satz von Kontextdateien, die ähnlich wie die oben beschriebenen primären Kontextfilter konfiguriert sind. Der Hauptunterschied liegt im Ort, an dem die Filteroperation stattfindet: tief in einem Log-Pfad, lange nachdem die Anbieter-Produkt-Kombination bestimmt worden ist. Dies ermöglicht Admins die Konfiguration wiederum hauptsächlich auf der Basis von Hostname-/CIDR-Block, jedoch können auch weitere syslog-ng-Makros (Felder) einbezogen werden, die möglicherweise intern im eigentlichen Log-Pfad erstellt wurden. Diese Überschreibungen (Unterfilter) können in Compliance-Anwendungsfällen sehr nützlich sein, wenn eine Teilmenge eines bestimmten Gerätetyps (Sourcetyps) markiert oder umgeleitet werden muss.
Wiederum gibt es zwei Dateien im selben Verzeichnis /opt/sc4s/local/context/:
compliance_meta_by_source.conf
compliance_meta_by_source.csv
Wie schon beim ersten Satz von Anbieter-Produkt-Kontextdateien, die wir oben erörtert haben, empfiehlt es sich, die Beispielversionen zu kopieren, bevor ihr beginnt. Dieser Satz Dateien ist typischerweise auch wesentlich kürzer als der erste Satz; es kann also besser sein, die Beispieldateien einfach als Referenz zu verwenden.
Hier sind die zwei compliance_meta_by_source-Dateien:


Ihr könnt auf den ersten Blick sehen, dass es sich um Dummy-Daten handelt. Und noch etwas fällt auf: Die zweite Spalte der CSV-Datei ist nicht auf Splunk-Metadaten beschränkt, sondern kann auf ein beliebiges syslog-ng-Makro festgelegt werden. Ihr könnt sie sogar verwenden, um ein beliebiges indiziertes Feld-Wert-Paar (z. B. compliance=pci) festzulegen und an Splunk zu senden, was für Compliance-Anforderungen sehr praktisch sein kann. Zu dieser Flexibilität gehört allerdings, dass auf Splunk-Metadateneinträge das intern verwendete .splunk.-Präfix angewendet werden muss (z. B. .splunk.index), um den Index zu überschreiben. Die Details hierzu werden im Konfigurationsabschnitt der Dokumentation behandelt.
Nachdem wir nun alle Konfigurationsschritte für vorhandene Datenquellen durchgegangen sind, werden wir uns im nächsten Teil (Teil 4) unserer letzten Aufgabe zuwenden: Wir behandeln dort den Prozess der Erweiterung der SC4S-Plattform mit einer Untersuchung des Templating-Prozesses sowie die Erstellung neuer Log-Pfade, damit wir Datenquellen einbeziehen können, die nicht out of the box unterstützt werden. Dies ist dann die tiefste Ebene der SC4S-Anpassung. Und obwohl etwas Erfahrung mit syslog-ng hilfreich ist, macht der Templating-Prozess diese Übung viel einfacher – das werden ihr sehen.
Splunk Connect for Syslog – Community
Splunk Connect for Syslog wird von Splunk voll unterstützt und ist als Open-Source-Projekt veröffentlicht. Wir hoffen auf eine engagierte Community, die uns mit Feedback, Verbesserungsvorschlägen, Kommunikation und vor allem der Erstellung von Log-Pfaden (Filtern) tatkräftig unterstützt! Für die aktive Teilnahme stellen wir die Git-Repos zur Verfügung, wo formelle Anfragen zur Aufnahme von Funktionen (insbesondere von Log-Pfaden/Filtern), Fehlerverfolgung usw. möglich sind. Wir gehen davon aus, dass es mit der Zeit deutlich weniger „lokale Filter“ geben wird, da immer mehr Beiträge der Community in den Out-of-the-box-Konfigurationen der Container gekapselt sein werden.
Splunk Connect for Syslog – Ressourcen
Es gibt eine ganze Menge von Ressourcen, die euch bei der erfolgreichen Nutzung von SC4S unterstützen! Neben dem Haupt-Repository und der Dokumentation gibt es zahlreiche weitere Informationsquellen, z.B. diese:
- Teil 1: Splunk Connect for Syslog – Entstehung, Designziele und Architektur
- Teil 2: Splunk Connect for Syslog – die Konfiguration im Überblick
- Support und Community-Diskussionen: https://splunk-usergroups.slack.com #splunk-connect-for-syslog
- Probleme oder Verbesserungen: https://github.com/splunk/splunk-connect-for-syslog/issues
Wir wünschen euch viel Erfolg mit SC4S. Macht mit, probiert es aus, stellt Fragen, tragt neue Datenquellen bei und findet neue Freunde!
*Dieser Artikel wurde aus dem Englischen übersetzt und editiert. Den Originalblogpost findet ihr hier: Splunk Connect for Syslog: Turnkey and Scalable Syslog GDI - Part 3..
Erfahren Sie mehr

Mapping mit Splunk

Neujahrsvorsätze 2021 mit Daten leicht gemacht