
Digitale Resilienz zahlt sich aus
Wie resilient ist eure Organisation? In diesem kostenlosen Leitfaden erfahrt ihr, wie ihr eure digitale Resilienz steigern könnt.
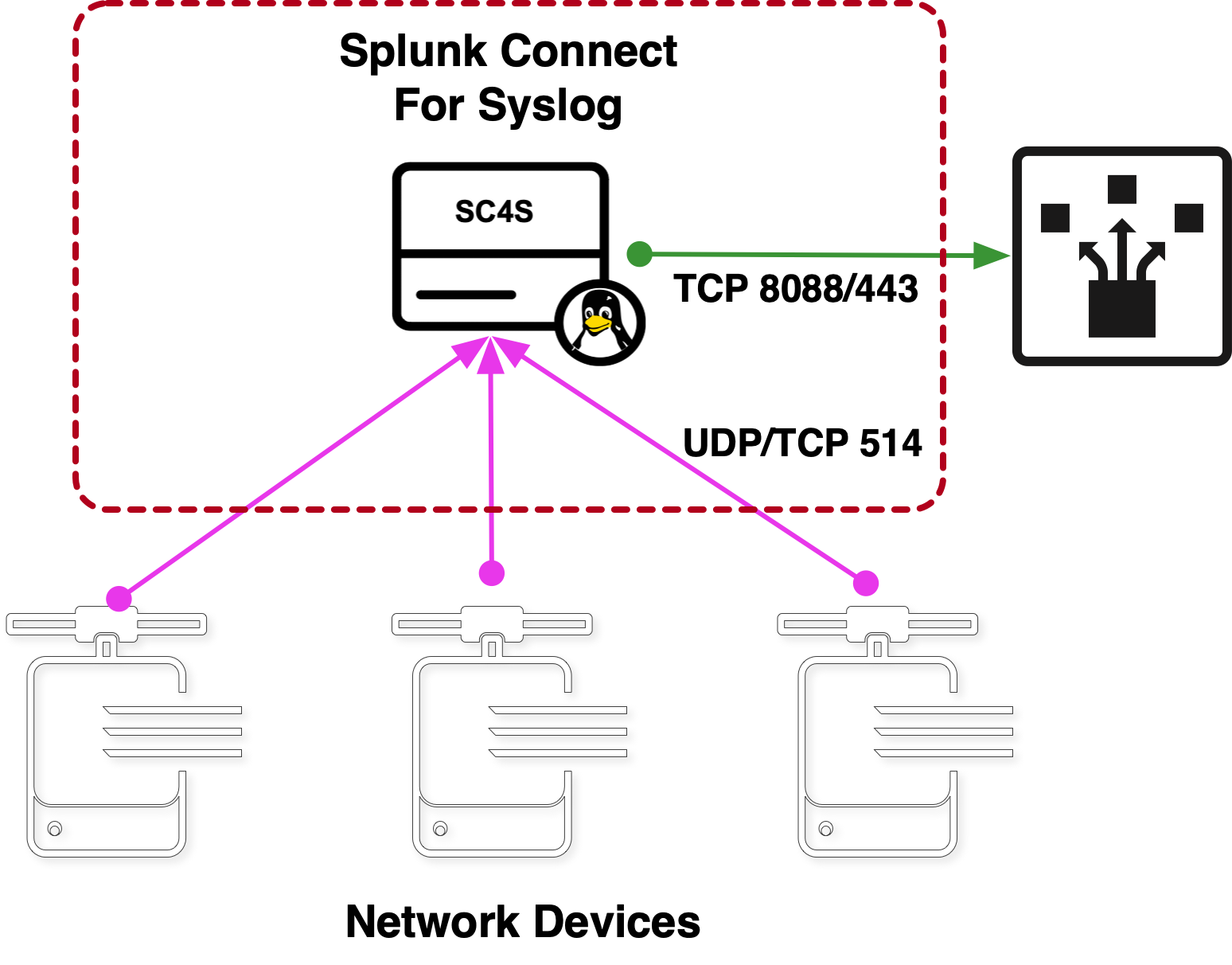
Seit ich hier bei Splunk bin – und das sind jetzt über acht Jahre – gibt es ein paar Fragen, die mir von Kunden und aus der Community der Splunk-Profis jedes Jahr immer wieder gestellt werden, und zwar vor allem Fragen rund um Syslog-Daten und ihr Onboarding. Eine Frage, die besonders hartnäckig wiederkehrt, ist diese:
Ich bin Admin und möchte Syslog-Daten problemlos in beliebigem Umfang übernehmen. Wie kann ich dies ohne große Vorarbeit und Syslog-Fachkenntnisse tun?
Wir freuen uns, euch mitteilen zu können, dass wir mit Splunk Connect for Syslog jetzt eine ganz hervorragende Antwort auf diese Frage haben! Splunk Connect for Syslog wurde genau dazu entwickelt: um Administratoren bei der Syslog-Datenerfassung zu entlasten, als ein schlüsselfertiger, skalierbarer und reproduzierbarer Ansatz für die Aufnahme von Syslog-Daten.
Splunk Connect for Syslog (SC4S) ist speziell für die folgenden Aufgaben konzipiert:
In diesem Blog-Beitrag wird es um die Überlegungen gehen, die beim Design von SC4S eine Rolle gespielt haben. Er ist als Ergänzung zum 2017 veröffentlichten Beitrag „Syslog-ng and HEC: Scalable Aggregated Data Collection in Splunk“ zu verstehen und bezieht die Erfahrungen, die wir seither gemacht haben, mit ein. Außerdem geben wir einen allgemeinen Überblick über den Konfigurationsprozess dieses neuen Produkts, hier allerdings nicht als Schritt-für-Schritt-Anleitung – ausführliche Informationen findet ihr in der Dokumentation, auf die wir an den entsprechenden Stellen verweisen.
 Werfen wir zuerst einen Blick zurück
Werfen wir zuerst einen Blick zurückVor über zwei Jahren begannen Ryan Faircloth und ich damit, an einer neuen Architektur für die Syslog-Datenaufnahme zu arbeiten, die den HTTP Event Collector (HEC) zum Datentransport von einem Syslog-Server direkt zu Splunk verwendet. Wir fanden, dass es an der Zeit für eine Alternative zum traditionellen Ansatz war (der darin besteht, Log-Meldungen auf die Festplatte zu schreiben und von dort per UF an Splunk zu übertragen), schon aus Gründen des Datenvolumens und der Benutzerfreundlichkeit. Seit unserem damaligen Blog-Beitrag zu Syslog und HEC haben sich die relevanten Trends noch beschleunigt.
Wir sehen konkret folgende Entwicklungen:
Damit war klar, dass ein offizielles Projekt zur Entwicklung einer skalierbaren, konsistenten und einfach zu konfigurierenden Lösung erforderlich war – und so entstand SC4S.
Obwohl Syslog wahrscheinlich die wichtigste Splunk-Datenquelle ist, haben sich die besonderen Herausforderungen beim GDI (Getting Data In), also beim Onboarding von Syslog-Daten, im Laufe der Zeit nicht sonderlich geändert.
Zu diesen Herausforderungen gehören die folgenden:
Ursache der meisten dieser Herausforderungen sind zwei grundlegende Probleme bei Syslog-Daten im Allgemeinen:
 Designziele von SC4S
Designziele von SC4SUnsere Recherchen zeigten, dass es aufgrund von Komplexitäts- und Skalierungsproblemen mit der Syslog-Datenaufnahme in Splunk so nicht weitergehen konnte. Und das Kundenfeedback machte deutlich, dass dieses Problem viele beschäftigte. So entstand Splunk Connect for Syslog. Und während das Produkt im Laufe des Sommers Gestalt annahm, stellten wir uns bei der Entwicklung immer diese beiden übergeordneten Fragen:
Unserer Ansicht nach sollte eine brauchbare Lösung der Splunk-Anwender-Community die folgenden Vorteile bieten:
Sehen wir uns diese Vorteile im Einzelnen an.
Den Aufwand bei der Aufnahme von Syslog-Daten für die gesamte Community zu verringern, war unser Hauptziel. Leider hat Splunk nie eine effektive Methode angeboten, Daten einfach direkt an Splunk zu senden. Es ist sogar so, dass dies eine Unmenge von Problemen verursacht, auf die wir hier nicht näher eingehen werden. Nur so viel dazu: Wir raten dringend davon ab. Und was bedeutet das für den Kunden? Die empfohlene Praxis, einen Syslog-Server (syslog-ng oder rsyslog) zu verwenden, erfordert Fachwissen in puncto Konfiguration. Klar war also: Wir mussten unbedingt erreichen, dass sich der Kunde gar nicht bzw. möglichst wenig mit den internen Abläufen von Syslog-Servern befassen muss.
Über die Jahre ist offenbar eine Unmenge von Architekturen zur Syslog-Erfassung entstanden. Ein wichtiges Ziel für uns war es, die Konfiguration flexibel genug für die meisten zu machen. Für diejenigen, die Vorhandenes nur kopieren wollen, sollte sie aber auch konsistent und reproduzierbar sein. Wir haben uns daher für syslog-ng als Syslog-Server und SC4S-Grundlage entschieden, weil er eine robuste und unkomplizierte (wenn auch nicht unbedingt einfache) Syntax hat.
Eine der größten Herausforderungen beim Erstellen von Syslog-Serverkonfigurationen in unterschiedlichen Unternehmen ist die Definition von „Filtern“ bzw. der spezifischen Konfigurationselemente, die für die Analyse einzelner Gerätetypen verwendet werden (und wiederum als einer oder mehrere verwandte Sourcetypen kategorisiert werden). Ein wichtiges Ziel von SC4S war daher die Erstellung von Filtern für die wichtigsten Geräte, die in den meisten Unternehmen vorkommen. Die war ein entscheidender Schritt in Richtung „Schlüsselfertigkeit“, sodass SC4S für die meisten (wenn auch sicher nicht alle) Kunden umstandslos einsatzfertig ist.
Bei der Entwicklung der Filter für die diversen Geräte bestand das Hauptziel im Wesentlichen darin, die Daten des Geräts richtig zu identifizieren und ihnen einen Sourcetyp zuzuweisen, der mit dem (vorhandenen) TA in Splunkbase funktioniert. Das heißt: Der Sourcetyp sollte richtig erkannt werden, und die passenden Metadaten (Zeitstempel, Host, Quelle und Zielindex) sollten mit der Nachricht an Splunk gesendet werden. Außerdem erkannten wir schon früh im Designprozess, dass man zusätzlich zu den genannten grundlegenden Metadaten eine weitaus umfassendere Datenanreicherung in Form von indizierten Feldern zur Verfügung stellen könnte. Diese Felder könnten ausdrücken, ob das Gerät im PCI-Bereich liegt, zu einem bestimmten Geschäftsbereich oder einer Region gehört oder sich einer von vielen anderen möglichen Kategorien zuordnen lässt, je nach Use Case. Diese Fähigkeit geht weit über das hinaus, was bisher mit dem UF-Transport möglich war.
Die Reduzierung des Splunk-Overheads war schon zu Anfang des Projekts ein wichtiger Nebeneffekt der Arbeit am Transportverfahren. Als HEC zum Datentransport erstmals in Betracht gezogen wurde, war nur der Endpunkt „raw“ verfügbar. Später, als erhebliche Verbesserungen am syslog-ng-Server stattgefunden hatten, wurde der „event“-Endpunkt verfügbar gemacht, ebenso wie der Batch-Modus für den Transport von Massendaten. Die Kombination des „event“-Endpunkts mit dem Transport im Batch-Modus ergab eine skalierbare Datenaufnahme mit sehr geringem Overhead.
Historisch gesehen sind Skalierung und Datenverteilung die ursprünglichen Triebfedern der SC4S-Entwicklung. Denn Kunden, die die nach dem klassischen UF-Ansatz vorgingen, hatten Schwierigkeiten mit der Datenverteilung (die Daten wurden ungleichmäßig auf eine größere Anzahl von Indexern verteilt) und der Skalierung im Allgemeinen. Vor diesem Hintergrund wurde nach Alternativen zum UF als Transportmechanismus gesucht. Frühere Blogs und .conf-Vorträge haben dargelegt, was auch gegenwärtige Kunden bestätigen können: dass HEC eine praktikable Transportalternative ist, die die Anforderungen an extrem hohe Skalierung erfüllt, wenn sie richtig konfiguriert ist. Tests mit SC4S haben gezeigt, dass eine Leistung von mehr als 5TB/Tag auf einer einzelnen SC4S-Instanz mit fünf oder mehr Indexern erreicht werden kann. Im früheren .conf-Vortrag wird außerdem die vorbildliche Datenverteilung auf die Indexer betont, die zu einer wesentlich höheren Suchgeschwindigkeit führt, besonders in Kombination mit der Datenmodellbeschleunigung, wie sie vielfach bei ES und anderen Systemen eingesetzt wird.
Damit die genannten Vorteile zum Tragen kommen, gibt es SC4S in zwei Versionen: als OCI-konformer Container, der sich leicht bereitstellen lässt und sofort einsetzbare Funktionalität bietet, und als BYOE-Option (Bring Your Own Environment) für maximale Flexibilität, aber ohne einige der einsatzfertigen Funktionen. Jede Umgebung basiert auf der syslog-ng-Server-Software und kapselt den gleichen Satz von syslog-ng-Serverkonfigurationen. Unterschiede gibt es in den Details der Instanziierung des eigentlichen syslog-ng. Beide Versionen basieren auf derselben Architektur, die hier vereinfacht dargestellt ist:
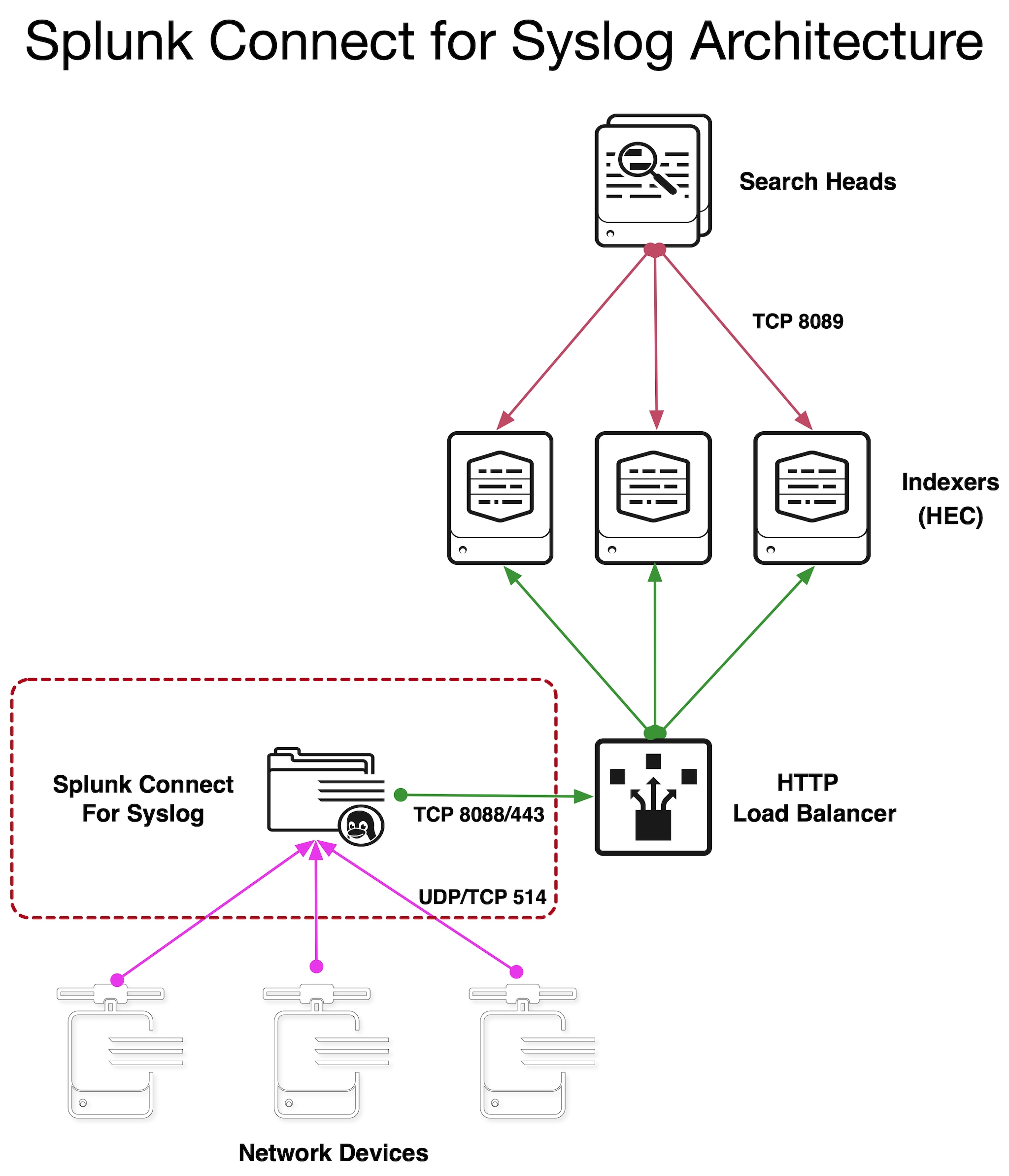
Dies sind die jeweils wichtigsten Merkmale der beiden Versionen:
Container
BYOE
Die zugrunde liegende syslog-ng-Konfiguration ist bei beiden Versionen identisch. Die Unterschiede zwischen Container und BYOE beruhen ausschließlich auf den Präferenzen (bzw. Einschränkungen) des Kunden hinsichtlich der Laufzeitumgebung. Darüber hinaus kann ein Kunde, der eine BYOE-Umgebung nutzt, einen benutzerdefinierten Container erstellen, der lokale Konfigurationselemente enthält, die dann für die Edge-Verteilung durch automatisierte Orchestrierung geeignet wären.
In Teil 2 dieses Beitrags werden wir uns die Grundkonfiguration von Splunk Connect for Syslog ansehen, die in den unten aufgeführten Ressourcen umfassend dokumentiert ist.
Splunk Connect for Syslog wird von Splunk voll unterstützt und ist als Open-Source-Projekt veröffentlicht. Wir hoffen auf eine engagierte Community, die uns mit Feedback, Verbesserungsvorschlägen, Kommunikation und vor allem der Erstellung von Log-Pfaden (Filtern) tatkräftig unterstützt! Für die aktive Teilnahme stellen wir die Git-Repos zur Verfügung, wo formelle Anfragen zur Aufnahme von Funktionen (insbesondere von Log-Pfaden/Filtern), Fehlerverfolgung usw. möglich sind. Wir gehen davon aus, dass es mit der Zeit deutlich weniger „lokale Filter“ geben wird, da immer mehr Beiträge der Community in den Out-of-the-box-Konfigurationen der Container gekapselt sein werden.
Es gibt eine ganze Menge von Ressourcen, die euch bei der erfolgreichen Nutzung von SC4S unterstützen! Neben dem Haupt-Repository und der Dokumentation gibt es zahlreiche weitere Informationsquellen, z.B. diese:
Wir wünschen euch viel Erfolg mit SC4S. Macht mit, probiert es aus, stellt Fragen, tragt neue Datenquellen bei und findet neue Freunde!
*Dieser Artikel wurde aus dem Englischen übersetzt und editiert. Den Originalblogpost findet ihr hier: Splunk Connect for Syslog: Turnkey and Scalable Syslog GDI - Part 1.

Die führenden Unternehmen der Welt vertrauen auf Splunk, einem Unternehmen von Cisco, um ihre digitale Resilienz mit der einheitlichen Sicherheits- und Observability-Plattform, unterstützt durch branchenführende KI, kontinuierlich zu stärken.
Unsere Kunden setzen auf die preisgekrönten Sicherheits- und Observability-Lösungen von Splunk, um die Zuverlässigkeit ihrer komplexen digitalen Umgebungen zu sichern und zu optimieren – in jeder Größenordnung.

© 2005 - 2026 Splunk LLC All rights reserved.
© 2005 - 2026 Splunk LLC All rights reserved.