
Digitale Resilienz zahlt sich aus
Wie resilient ist eure Organisation? In diesem kostenlosen Leitfaden erfahrt ihr, wie ihr eure digitale Resilienz steigern könnt.
Finanzkriminalität ist in den letzten zwölf Monaten zu einem heißen Thema geworden, weil die zunehmende Nutzung (digitaler) Fernkommunikation zu einer immer größeren Angriffsfläche geführt hat. Seitdem stoßen Betrüger in die Monitoring-Lücken zwischen Menschen, Prozessen und Technologie. Schon vor dem jüngsten Anstieg der Fallzahlen entstanden durch Betrug und Finanzkriminalität erhebliche Kosten. Schätzungen von Refinitiv zufolge belaufen sich die weltweiten Kosten gar auf über eine Billion Dollar jährlich! Die Bekämpfung und Abwehr derartiger Angriffe, die sich direkt auf das Geschäftsergebnis auswirken, hat also für alle Unternehmen hohe Priorität.
Die wachsende Angriffsfläche hat auch dazu geführt, dass ein immer breiteres Spektrum an Datenquellen nötig ist, um verdächtige Aktivitäten präzise zu identifizieren. Es genügt nicht mehr, sich auf einzelne Interaktionen zu konzentrieren. Heute ist es unbedingt erforderlich, die (digitalen) Wege nachverfolgen, die zu Finanzkriminalität führen. Dazu muss eine ganze Reihe unstrukturierter Datenquellen – Web-Logs, Authentifizierungslogs, Anwendungslogs etc. – in die Analysen eingebunden werden, denn diese Quellen enthalten wichtige Informationen.
Es gilt als ausgemacht, dass Daten und Analysen der Schlüssel im Kampf gegen Finanzkriminalität sind, besonders dann, wenn man in der Lage ist, alle relevanten Daten zu korrelieren. Aussagekräftige Erkenntnisse zu gewinnen, ist jedoch alles andere als trivial. Es gibt eine Vielzahl unterschiedlicher Indikatoren für Finanzkriminalität in ganz verschiedenen Bereichen, die alle einem Monitoring unterzogen werden müssen, damit man die Aktivitäten ausmachen kann, die eine eingehendere Untersuchung erfordern.
Splunk hat ein Framework zur exakten Ermittlung von Entitäten entwickelt (Accounts, Personen oder Mitarbeiter), bei denen verdächtiges Verhalten festzustellen ist (siehe die folgende Abbildung).
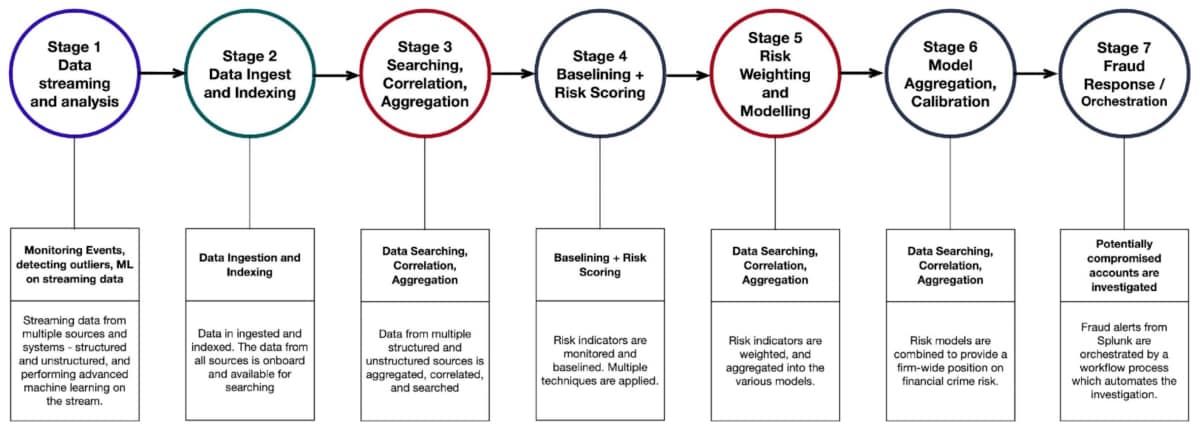
Dieses Framework basiert auf dem Prinzip, dass man in der Lage sein sollte, Daten zu jedem relevanten Risikoindikator effizient zu identifizieren, zu erfassen und zu analysieren.
Doch was ist überhaupt ein Risikoindikator? Wikipedia definiert den Begriff als „risk metric used by organizations to provide an early signal of increasing risk exposure in various areas of the enterprise“, also als Kennzahl, die Unternehmen als frühes Anzeichen für ein steigendes Risiko in einzelnen Unternehmensbereichen dient. Und genau das versuchen wir mit unserem Framework gegen Finanzkriminalität zu erreichen: Entitäten identifizieren, deren Verhalten auf ein Risiko hindeutet, weshalb sie näher untersucht werden sollten.
Nur wenn man alle Risikoindikatoren zu einer Entität betrachtet, kann man exakt bestimmen, welche Entitäten wahrscheinlich kompromittiert sind und unter Umständen ein Einfallstor für Finanzkriminelle darstellen.
Die einzelnen Risikoindikatoren haben für das Unternehmen allerdings unterschiedliche Bedeutung – und dies muss auch die Analytik berücksichtigen. Unser Framework ordnet daher jedem Indikator einen Risk Score zu, der seiner relativen Gewichtung entspricht. Zum Beispiel beginnen viele Fälle von Finanzkriminalität mit der Übernahme eines Benutzerkontos. Angesichts dessen ist es sinnvoll, wenn ihr den Hauptindikatoren für eine Kontoübernahme (zum Beispiel mehrere fehlgeschlagene Anmeldungen in einem kurzen Zeitraum) einen höheren Risk Score zuweist.
Wenn die Risk Scores zugewiesen sind, solltet ihr unbedingt weiter überlegen, wie sich diese Werte anpassen müssen, wenn die Daten eines Risikoindikators zunehmend besorgniserregend werden, wenn also beispielsweise nicht nur eine einzige Anmeldung fehlschlägt (was durch einen Tippfehler schon vorkommen kann), sondern drei, vier oder fünf. In diesem Beispiel ist mit jeder weiteren Anmeldung ein zusätzliches Risiko verbunden, sodass der Risk Score für fehlgeschlagene Anmeldungen nach dem ersten Fehlversuch rasch ansteigen sollte, um das zunehmende Risiko abzubilden. An dieser Stelle kommt die Mathematik ins Spiel. Denn bei diesem Indikator steigt das Risiko definitiv nichtlinear.
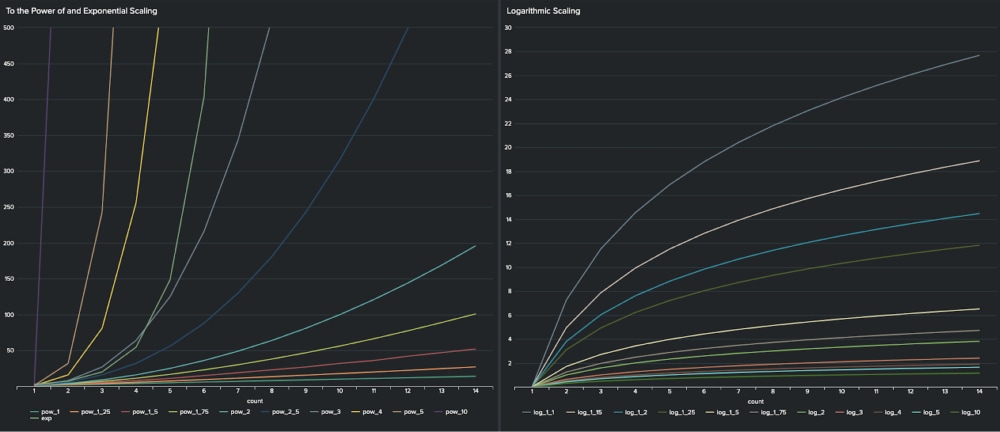
Es gibt eine Reihe nichtlinearer mathematischer Funktionen, mit denen sich der Risikozuwachs bei einem einzelnen Indikator darstellen lässt. Einige Beispiele zeigt die folgende Abbildung. Die Kurven im linken Diagramm steigen steil an (quadratisch, kubisch, exponentiell etc.) – sie eignen sich für Indikatoren, bei denen das Risiko durch aufeinanderfolgende Events, etwa anomale Transaktionen, sehr schnell steigt. Das rechte Diagramm zeigt eine Reihe logarithmischer Kurven, bei denen das Risiko mit den ersten Events schnell ansteigt, dann aber kaum mehr, sodass die Kurve ab einem bestimmten Wert abflacht – dies entspricht etwa dem Szenario wiederholter fehlgeschlagener Anmeldungen.
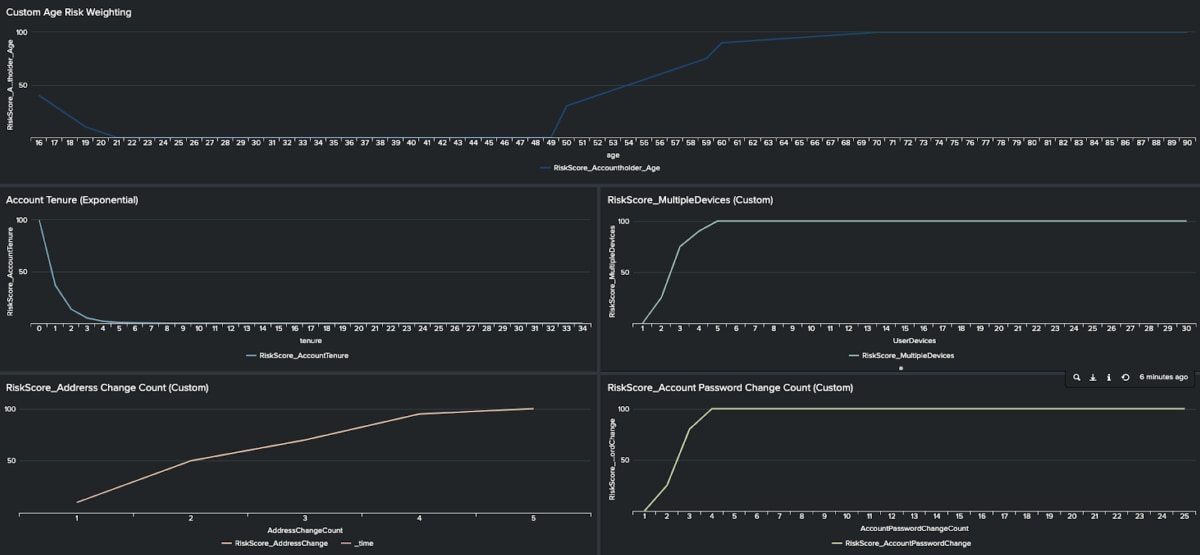
Die folgende Abbildung zeigt einige maßgeschneiderte Beispiele für die Risikobewertung, die wir auf einzelne Indikatoren anwenden. Bei jedem dieser Beispiele haben wir die Kurve so angepasst, dass sie das mit dem betreffenden Indikator verbundene Risiko abbildet. Das mit einer Entität verbundene Risiko kann nur dann präzise bewertet werden, wenn man wirklich für jeden Risikoindikator die am besten passende Kurve wählt.
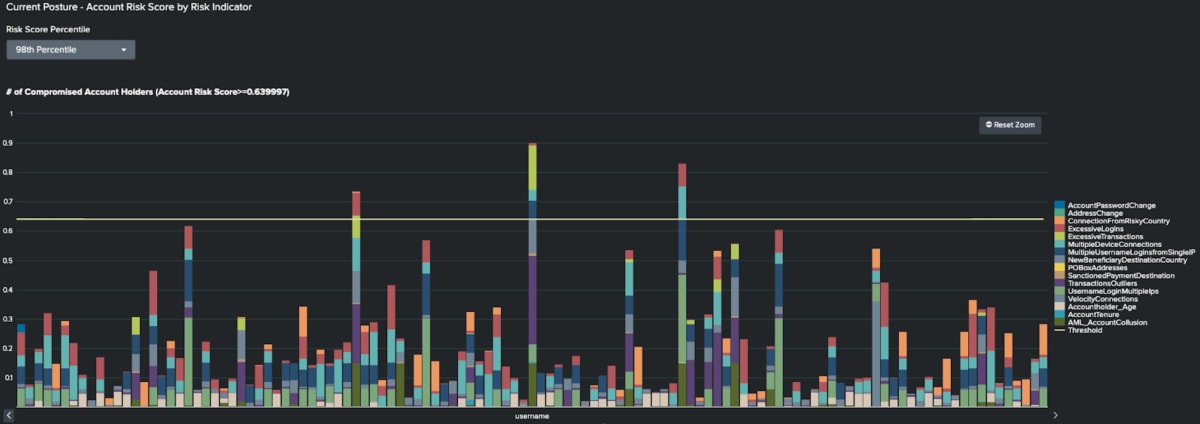
Wenn alle Risikoindikatoren definiert sind, kann man einen kumulativen Risk Score berechnen. Mit diesem Gesamtwert lassen sich die Entitäten ermitteln, die am meisten Sorge bereiten und daher eingehender untersucht werden sollten. Die folgende Abbildung ist ein Beispiel für eine solche Ausgabe.
In diesem Beispiel gibt es 15 Risikoindikatoren. Der Risk-Score-Gesamtwert für jede Entität errechnet sich aus der Summe der Risk Scores aller Einzelindikatoren. Nur die Entitäten mit den höchsten Risk Scores sollten eingehender untersucht werden. Um die Entitäten deutlich zu machen, bei denen eine Untersuchung oberste Priorität haben sollte, haben wir in der Abbildung beim 99. Perzentil eine Linie gezogen.
Dieser Ansatz lässt sich in jedem Unternehmen konsequent umsetzen, um Finanzkriminalität aufzudecken. Er ist äußerst flexibel und anpassbar, da man nur die relevanten Risikoindikatoren in Betracht zieht. Außerdem kann man bei Bedarf sowohl die Risikoindikatoren als auch den Ansatz der Risikobewertung ändern, um beispielsweise Änderungen der Marktbedingungen oder der individuellen Risikolage Rechnung zu tragen.
Also, worauf wartet ihr noch? Es ist höchste Zeit, sich daran zu erinnern, was Mathe alles kann, und den Kampf gegen Finanzkriminalität aufzunehmen!
*Dieser Artikel wurde aus dem Englischen übersetzt und editiert. Den Originalblogpost findet ihr hier: Using Maths to Fight Financial Crime.
----------------------------------------------------
Thanks!
Splunk

Die führenden Unternehmen der Welt vertrauen auf Splunk, einem Unternehmen von Cisco, um ihre digitale Resilienz mit der einheitlichen Sicherheits- und Observability-Plattform, unterstützt durch branchenführende KI, kontinuierlich zu stärken.
Unsere Kunden setzen auf die preisgekrönten Sicherheits- und Observability-Lösungen von Splunk, um die Zuverlässigkeit ihrer komplexen digitalen Umgebungen zu sichern und zu optimieren – in jeder Größenordnung.

Die neuesten Artikel von Splunk, direkt im eigenen Posteingang.
© 2005 - 2026 Splunk LLC All rights reserved.
© 2005 - 2026 Splunk LLC All rights reserved.