
Wege zum Aufbau erfolgreicher Observability-Praktiken
IT- und DevOps-Teams sehen sich heutzutage mit immer komplexeren Umgebungen konfrontiert. Dadurch wird es schwieriger, kritische Probleme schnell zu erkennen und in Echtzeit zu lösen. Um diese Herausforderung zu meistern, können Splunk-User von ML-gestützten IT-Monitoring- und DevOps-Lösungen profitieren, die auf einer skalierbaren Plattform mit modernsten Datenanalyse- und KI/ML-Funktionen zur Verfügung stehen. In diesem Blog setzen wir die in Splunk integrierten Streaming-ML-Algorithmen ein, um anormale Muster in Fehlerprotokollen in Echtzeit zu erkennen. In einfachen Schritten zeigen wir euch, wie ihr vorkonfigurierte Splunk-Funktionen nutzen könnt, um Logs zu erfassen, Daten vorzuverarbeiten, Machine Learning in Echtzeit anzuwenden und Ergebnisse zu visualisieren. Legen wir los!
Mit der Anomalieerkennung können Unternehmen Muster und ungewöhnliche Ereignisse in Datenströmen erkennen. Ziel ist es, Abweichungen von den erwartbaren, normalen Mustern in Daten zu entdecken und IT- und DevOps-Teams frühzeitig über potenzielle Probleme zu informieren. Die Bandbreite der Anwendungsfälle reicht von der Erkennung von betrügerischen Anmeldeversuchen über Benachrichtigungen bei Spitzen in KPI-Metriken bis hin zur Erkennung von ungewöhnlichem Ressourcenverbrauch.
In vielen Branchen stellt der explosionsartige Anstieg des Datenvolumens und die zunehmende Komplexität der Daten eine enorme Herausforderung für IT-Abteilungen dar. Nehmen wir zum Beispiel einmal die Telekommunikationsbranche, für die weltweit ein mobiler Datenverkehr von 77,5 Exabyte pro Monat prognostiziert wird. Diese schnell wachsenden Umgebungen lassen sich mit einem statischen, regelbasierten Ansatz nicht mehr verwalten. Moderne DevOps-Teams setzen beim Monitoring des „unbekannten Unbekannten“, bei der Reduzierung des Over-Alerting oder beim Generieren von Erkenntnissen aus Anwendungslogs auf KI/ML-basierte Lösungen zur Anomalieerkennung. Im Allgemeinen lassen sich diese Lösungen in folgende Gruppen unterteilen: Predictive Analytics, intelligente Benachrichtigungen und Troubleshooting/Incident-Behebung. In diesem Blog untersuchen wir, wie Splunk Machine Learning Environment (SMLE) genutzt werden kann, um Anomalien und Fehler in Anwendungsserverlogs genauer einzugrenzen und die Anzahl der Events zu reduzieren, die eine manuelle Prüfung erfordern.
Wie ihr vielleicht wisst, können Benutzer mit dem Machine Learning Toolkit (MLTK) von Splunk Lösungen zur Anomalieerkennung erstellen. Dabei kommen entweder traditionelle Methoden zum Einsatz, bei denen Modelle mit historischen Daten „trainiert“ werden, oder aber statistische Analysemethoden. Splunks neuestes ML-Produkt, Splunk Machine Learning Environment (SMLE), bietet eine Lösung zur Anomalieerkennung in Echtzeit und zwar mit modernsten KI/ML- und Streaming-Analysefunktionen, die im Datenstrom lernen und Prognosen erstellen.
Ein einfacher und intuitiver Workflow zur Erstellung einer Lösung zur Anomalieerkennung mit SMLE umfasst vier Schritte:
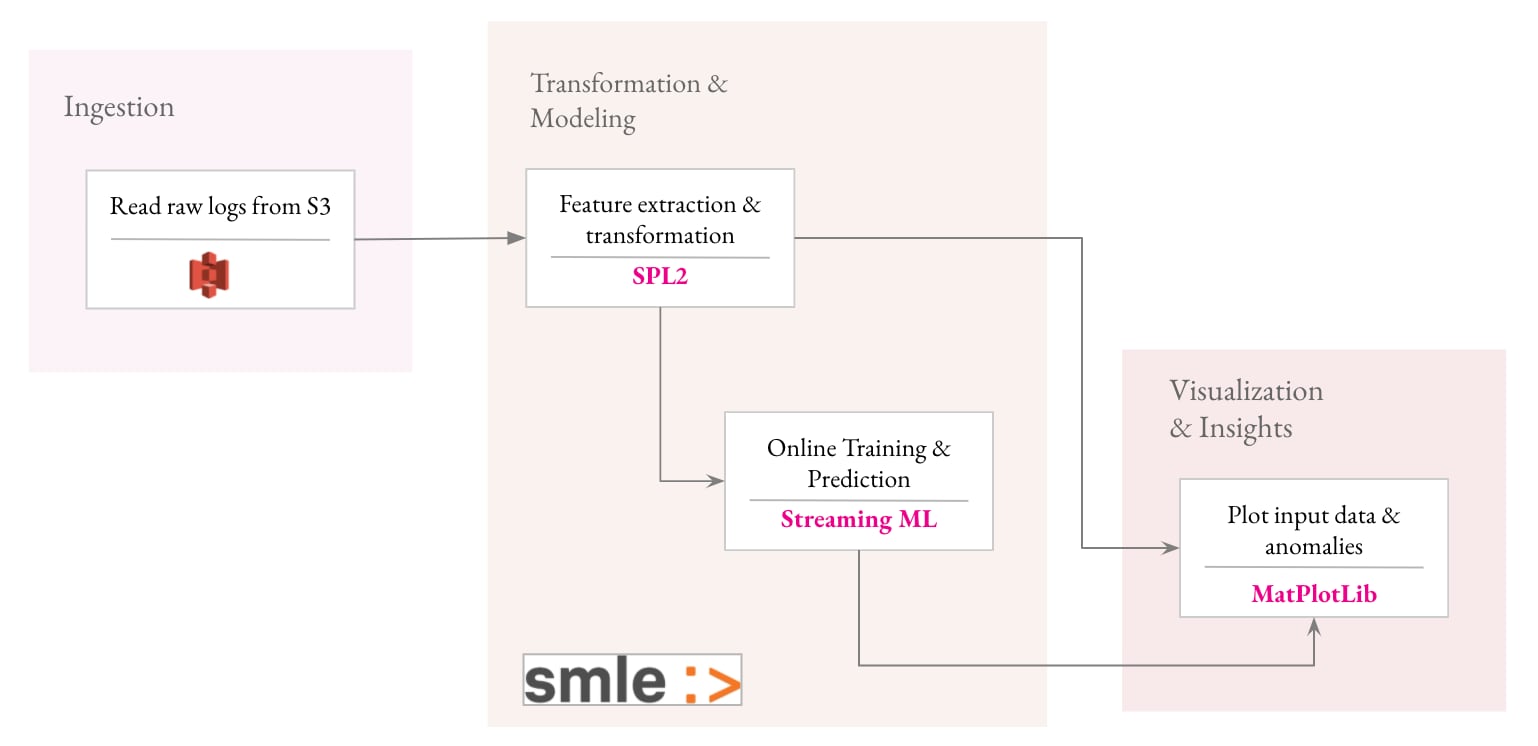 Schritt 1: Daten aus Serverlogs mit SPL2 streamen
Schritt 1: Daten aus Serverlogs mit SPL2 streamen
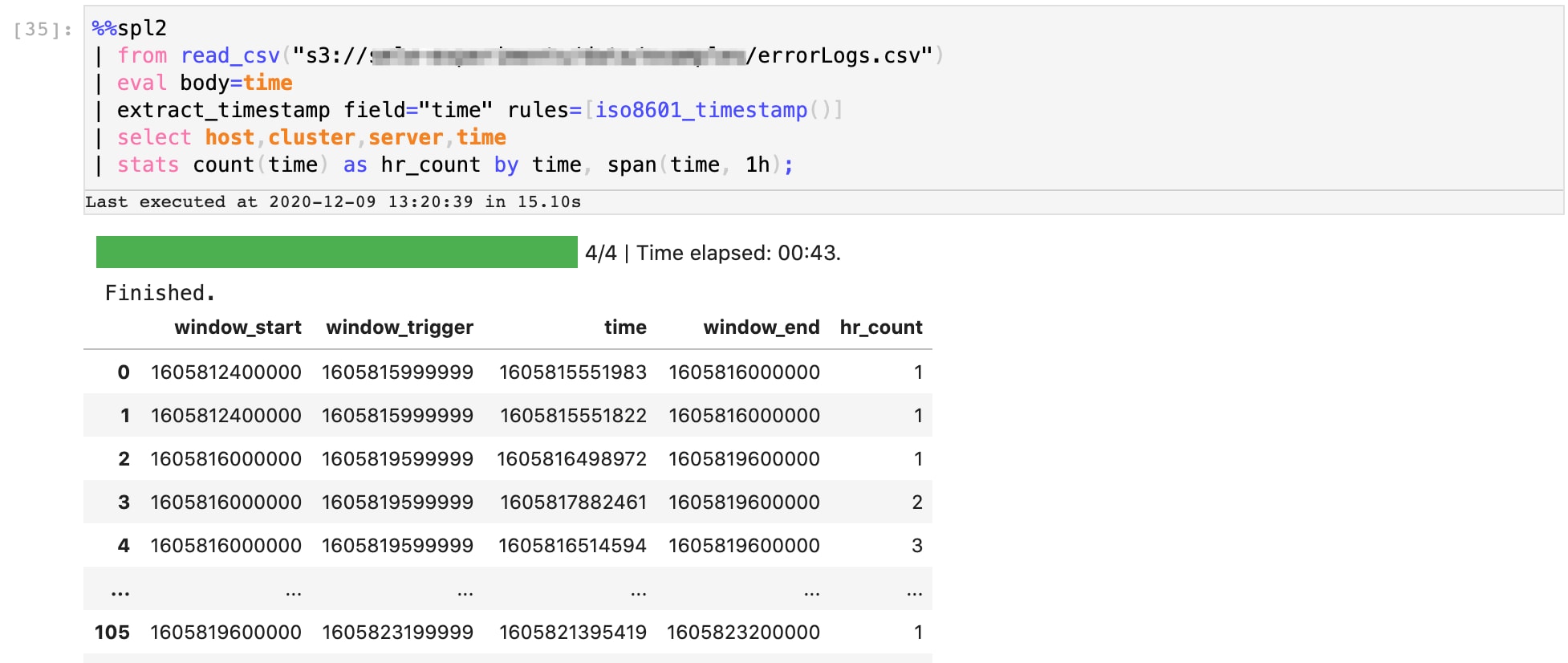
Beginnen wir mit dem Streamen der Daten in unsere Pipeline. Im vorliegenden Beispiel erfassen wir Daten aus einem AWS S3-Bucket, in den wir die rohen Serverlogs einer Woche hochgeladen haben. Hier seht ihr unsere SPL2-Datenpipeline, über die die Daten vom S3-Bucket in unsere Jupyter Notebook-Umgebung transferiert werden. Das Ergebnis ist eine Reihe roher Logdaten.
Schritt 2: Extrahieren von Features und Transformieren von Daten mit SPL2-Operatoren
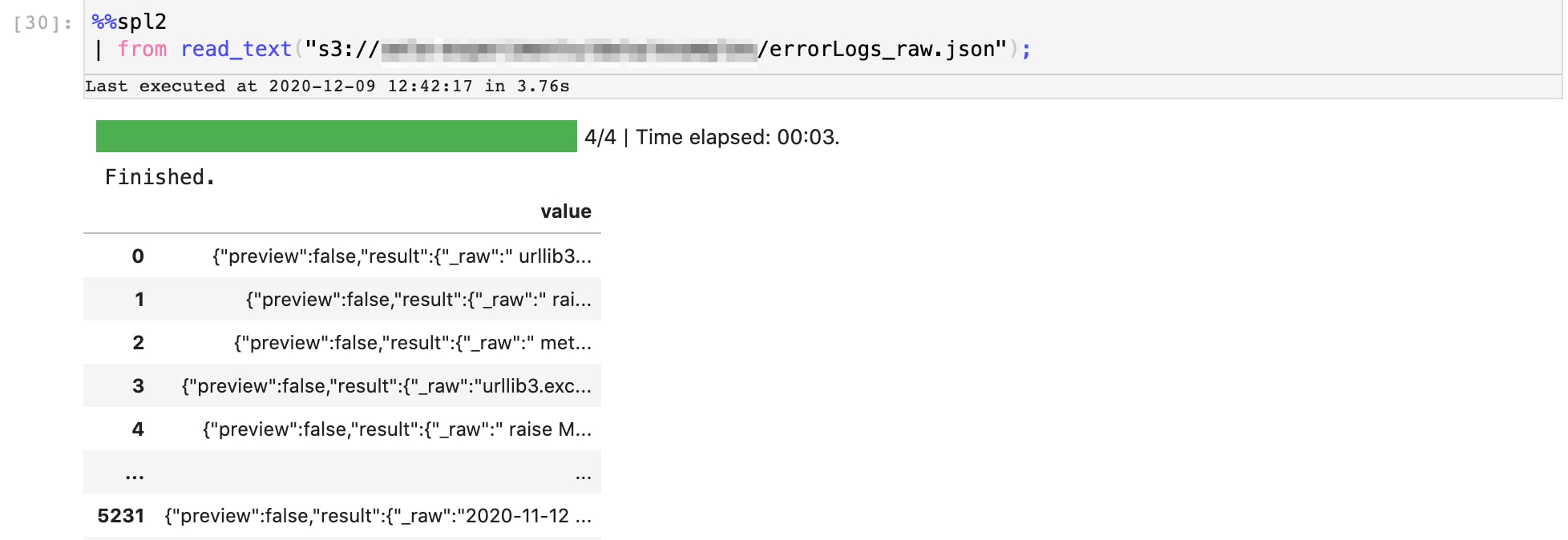
Nachdem wir nun die Rohdaten haben, extrahieren wir die relevanten Features mit einer Reihe einfacher SPL2-Vorgänge und transformieren die Daten, um anormale Muster zu entdecken.
In dieser Phase führen wir zwei Schritte aus:
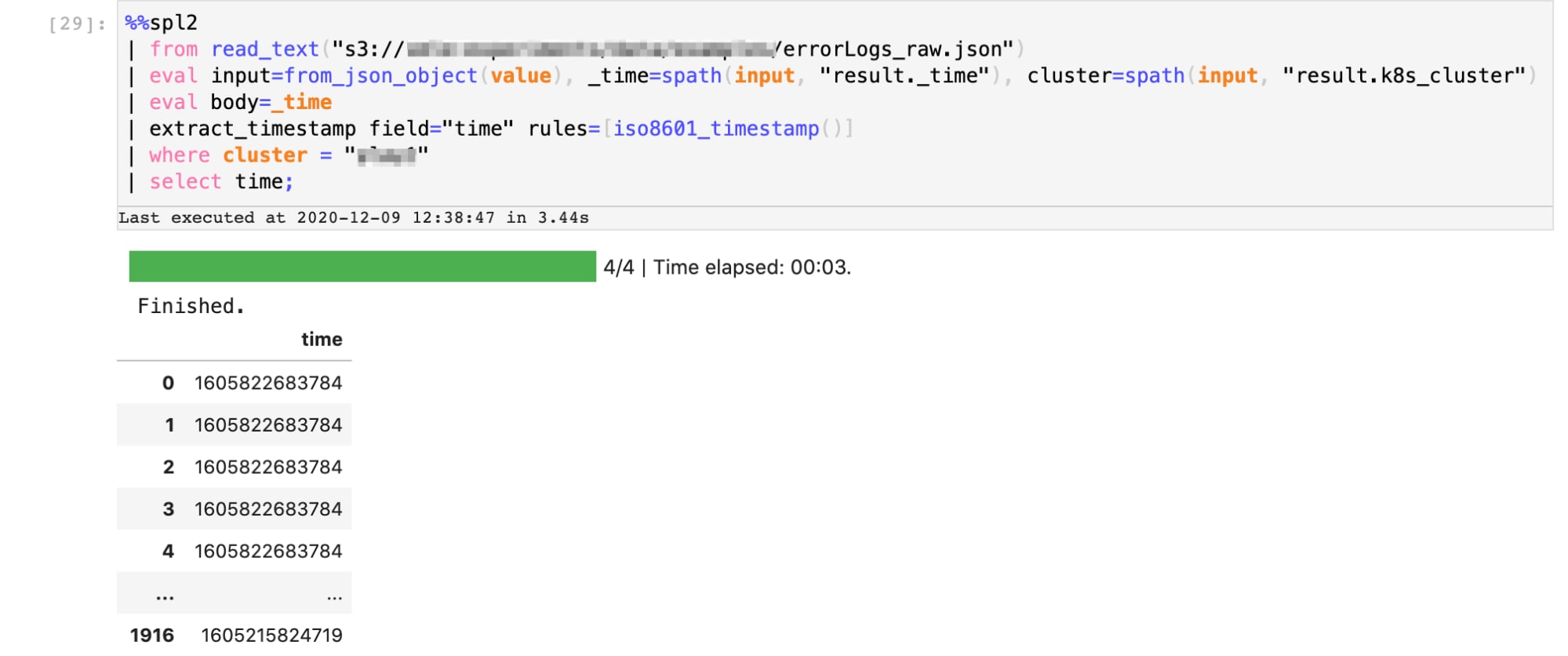
Hier seht ihr die SPL2-Datenpipeline, welche die erste Extraktionssequenz ausführt. Das Ergebnis ist eine Reihe von Zeitstempeln, bei denen in den Serverlogs Fehler gemeldet wurden.
Als Nächstes aggregieren wir diese Zeitstempel in Fenstern von je einer Stunde. Hier seht ihr eine Fortsetzung der SPL2-Pipeline, die diesen Vorgang ausführt. Das Ergebnis beinhaltet eine neue Spalte „hr-count“, in der angezeigt wird, wie viele Fehler innerhalb dieser Stunde des Tages über die Woche hinweg aufgetreten sind.
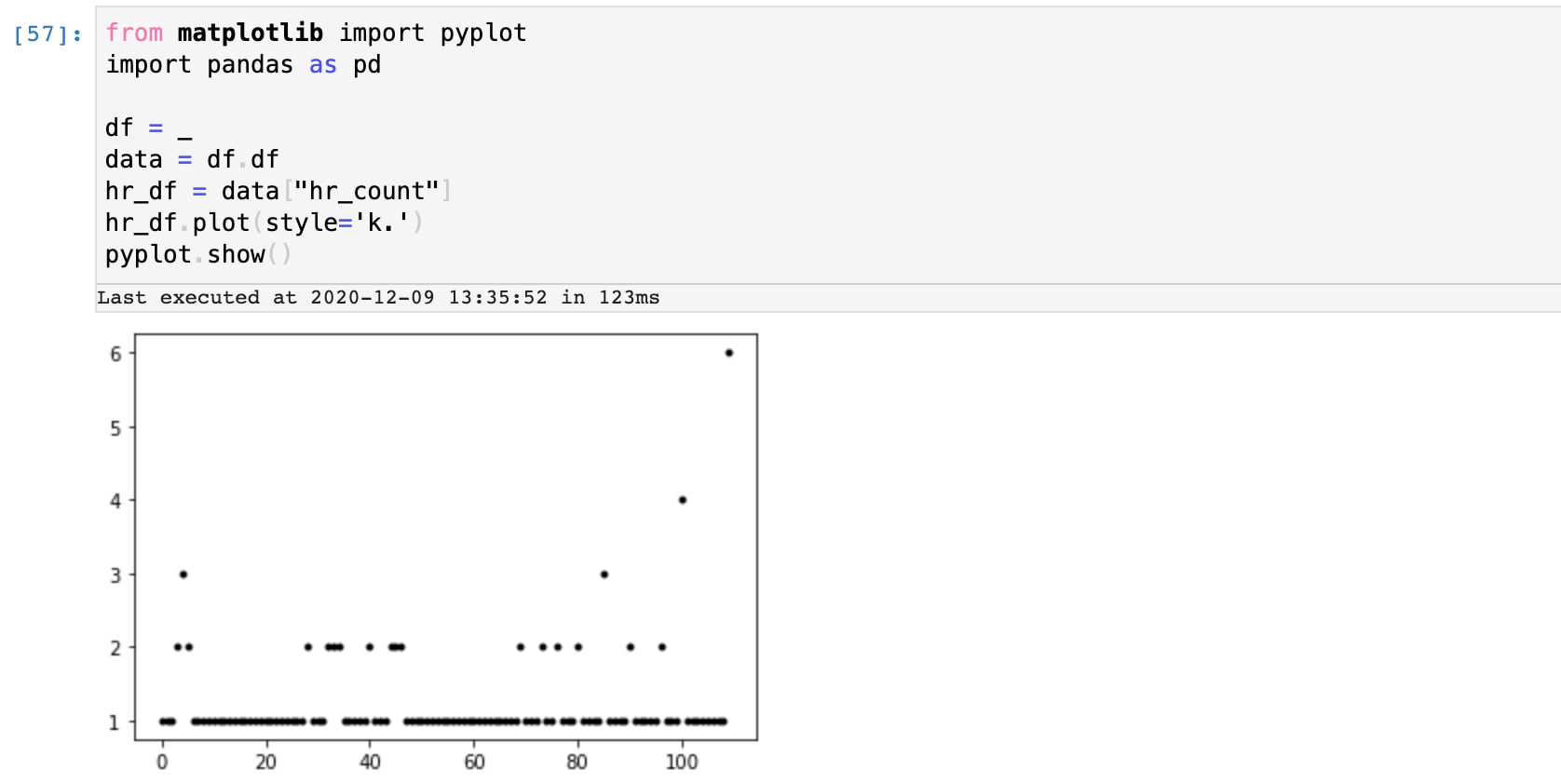
Nun stellen wir diese Werte grafisch dar, um einen Eindruck davon zu bekommen, was normal ist und welche Werte möglicherweise Ausreißer sind. Mit einem einfachen Python-Skript, das in das SPL2 Jupyter Notebook eingebettet ist, können wir eine Stichprobe des Ergebnisses nehmen und sehen, dass es vermutlich einige Ausreißer bei Werten größer gleich 3 gibt.
Schritt 3: Nutzen von Streaming-ML-Algorithmen, um adaptive Schwellenwerte in Echtzeit anzuwenden
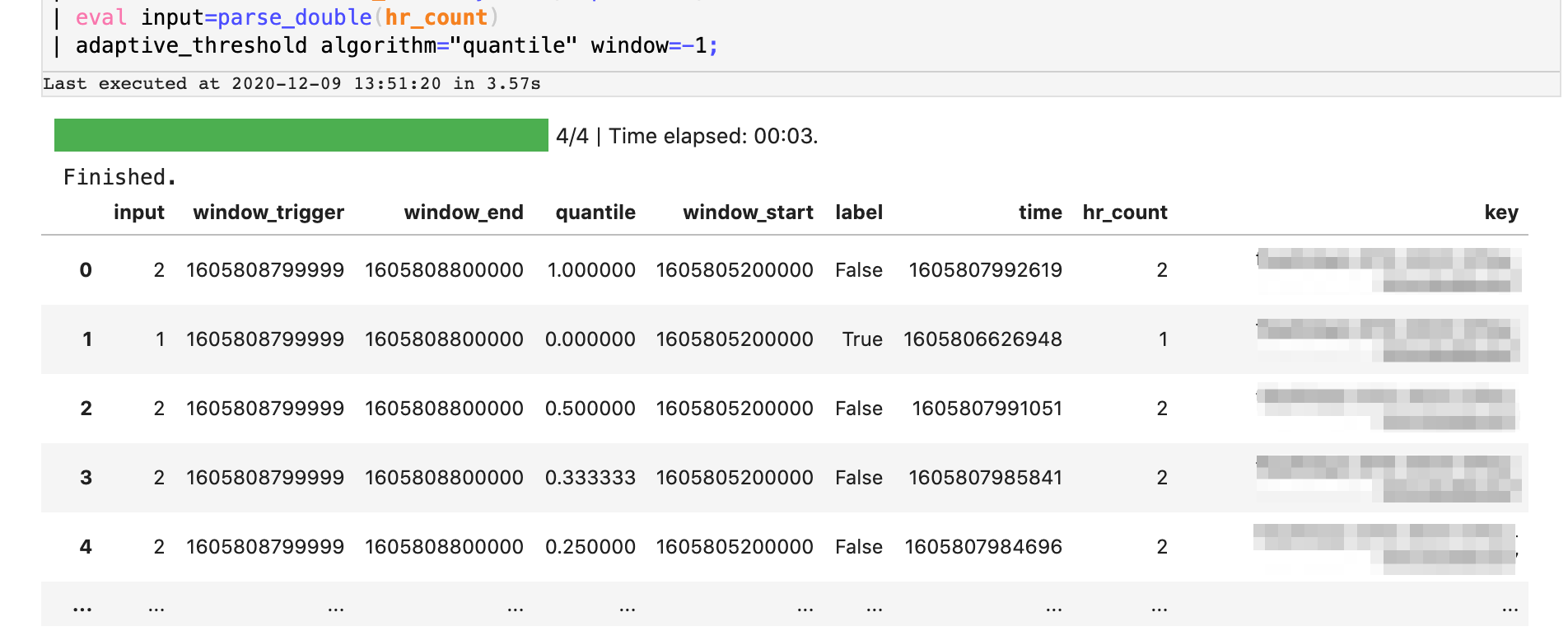
Als Nächstes verwenden wir den in Splunk integrierten Algorithmus, um eine adaptive Schwellenwertbestimmung mit der 'quantile'-Methode in Echtzeit auszuführen. Bei diesem Vorgang wird in Echtzeit ein Profil des Streams erstellt und jedem Wert in der Verteilung ein bestimmter Rangplatz zugewiesen. Im Wesentlichen ermittelt der Algorithmus, wie wahrscheinlich es ist, dass ein bestimmter Wert in diesem Datenstrom auftritt. Ausreißer entsprechen Beobachtungen, die außerhalb bestimmter Schwellenwerte liegen, zum Beispiel außerhalb des 99. Perzentils. Wir verwenden diese Eigenschaft, um Fehlerzahlen zu identifizieren, die unwahrscheinlich und daher anormal sind. Hier seht ihr eine Fortsetzung der SPL2-Datenpipeline, die wir bisher erstellt haben. Wir wenden den Operator „adaptive_threshold“ auf die Datenpipeline an, um die Fehlerzahlen der Zeitfenster zu streamen. Ausgegeben wird dann eine Reihe von 'quantile'-Werten für jeden Datensatz, während der Algorithmus vom Datenstrom lernt.
Schritt 4: Gewinnen von Erkenntnissen
Die Schwellenwerte, die als Ergebnis unserer Datenpipeline ausgegeben werden, geben die Wahrscheinlichkeit an, einen weiteren ähnlichen Wert im Datenstrom zu finden. Für den Use Case der Anomalieerkennung wenden wir einen Perzentil-Schwellenwert an, um anormale Fenster herauszufiltern und diese Anomalien mit einfachen Python-Visualisierungen grafisch darzustellen.
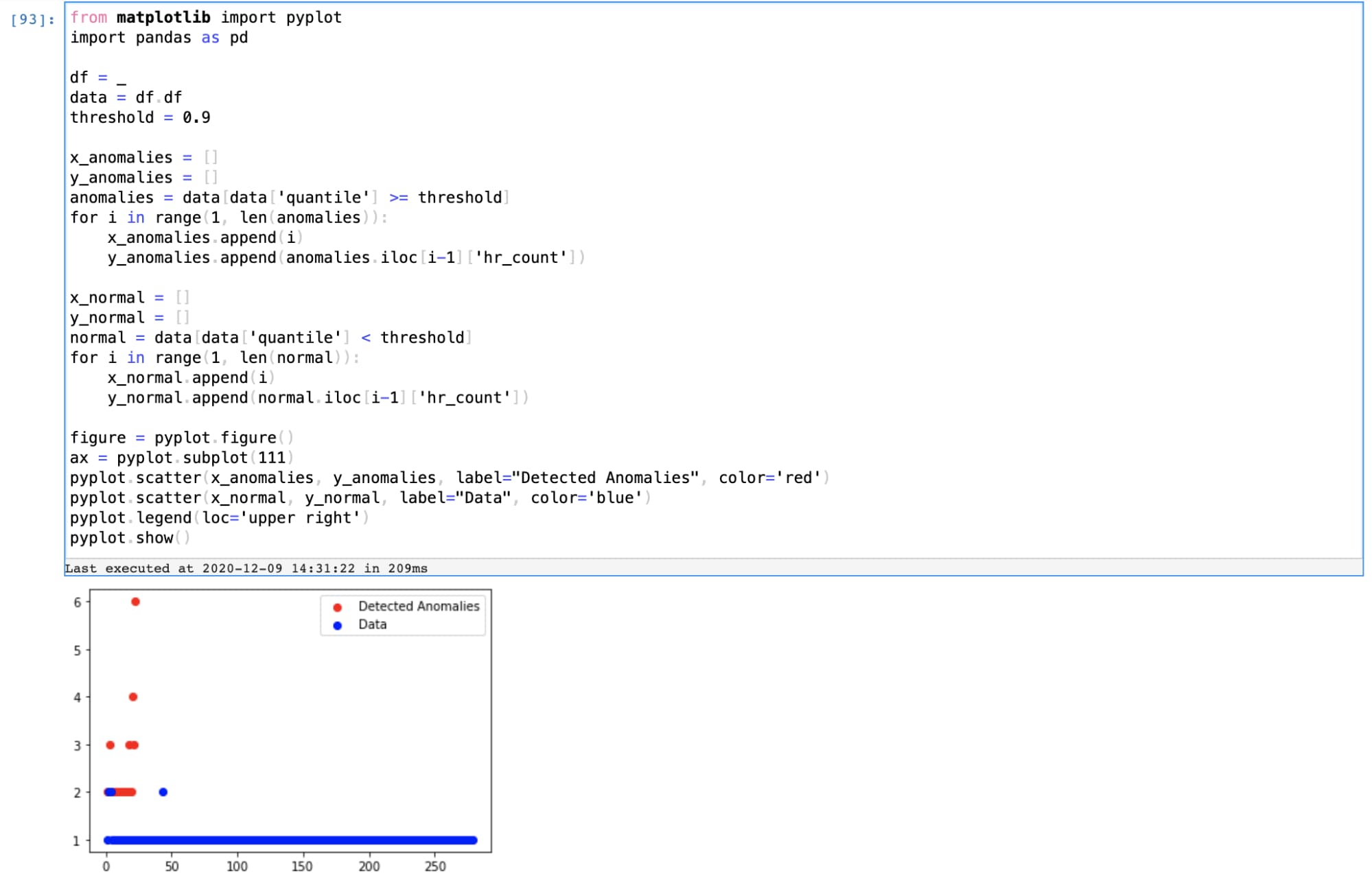
Die aus den Daten gewonnenen Erkenntnisse sind nur so gut, wie der geschäftliche Mehrwert, den sie ermöglichen. Damit diese Erkenntnisse auch umsetzbar sind, bietet die KI/ML-Plattform von Splunk Funktionen zum Erstellen von Dashboards zur Erkennung dieser Anomalien sowie zum Generieren von Warnmeldungen und Workflows zur Reaktion auf diese Warnmeldungen.
Wir haben oben eine Lösung zur Anomalieerkennung mit SMLE vorgestellt. SMLE (Splunk Machine Learning Environment) ist eine Plattform, mit der sich Machine Learning innerhalb des Splunk-Ökosystems bedarfsgerecht aufbauen und bereitstellen lässt. Durch die Erweiterung der von den Kunden geschätzten Splunk-Funktionen um eine Suite von Data Science- und Operations-Funktionen ermöglicht SMLE Splunk-Nutzern und Data Scientists die gemeinsame Erstellung von Lösungen, die eine Kombination aus SPL- und ML-Bibliotheken beinhalten. Die Beta-Version der SMLE-Plattform steht interessierten Benutzern zur Verfügung. Hier könnt ihr euch registrieren und hier erfahrt ihr mehr über unsere Angebote und Ankündigungen.
Es wurde gezeigt, wie ihr mit Streaming-ML auf der SMLE-Plattform eine einfache Lösung zur Erkennung von Anomalien in Echtzeit entwickeln und damit operative Herausforderungen für IT/DevOps-Benutzer meistern könnt. Mit einer Kombination aus leistungsstarken und benutzerfreundlichen SPL2-Operatoren und flexiblen, weit verbreiteten Programmiersprachen wie Python ermöglicht SMLE den Aufbau ganzer Workflows mit einer Sequenz von SPL2- und ML-Vorgängen. Bald gibt es an dieser Stelle weitere Beispiele für Use Cases von SMLE.
Ihr möchtet SMLE ausprobieren? Registriert euch für unser Betaprogramm!
Dieser Blogbeitrag von Splunk wurde von Vinay Sridhar, Senior Product Manager for Machine Learning, und Mohan Rajagopalan (Hauptautor), Senior Director of Product Management for Machine Learning, gemeinsam verfasst.
*Dieser Artikel wurde aus dem Englischen übersetzt und editiert. Den Originalblogpost findet ihr hier: Improve DevOps Workflows Using SMLE and Streaming ML to Detect Anomalies.
----------------------------------------------------
Thanks!
Splunk

Die führenden Unternehmen der Welt vertrauen auf Splunk, einem Unternehmen von Cisco, um ihre digitale Resilienz mit der einheitlichen Sicherheits- und Observability-Plattform, unterstützt durch branchenführende KI, kontinuierlich zu stärken.
Unsere Kunden setzen auf die preisgekrönten Sicherheits- und Observability-Lösungen von Splunk, um die Zuverlässigkeit ihrer komplexen digitalen Umgebungen zu sichern und zu optimieren – in jeder Größenordnung.

Die neuesten Artikel von Splunk, direkt im eigenen Posteingang.
© 2005 - 2026 Splunk LLC All rights reserved.
© 2005 - 2026 Splunk LLC All rights reserved.