
統合サーチ
ハイブリッドデータを統合的に分析
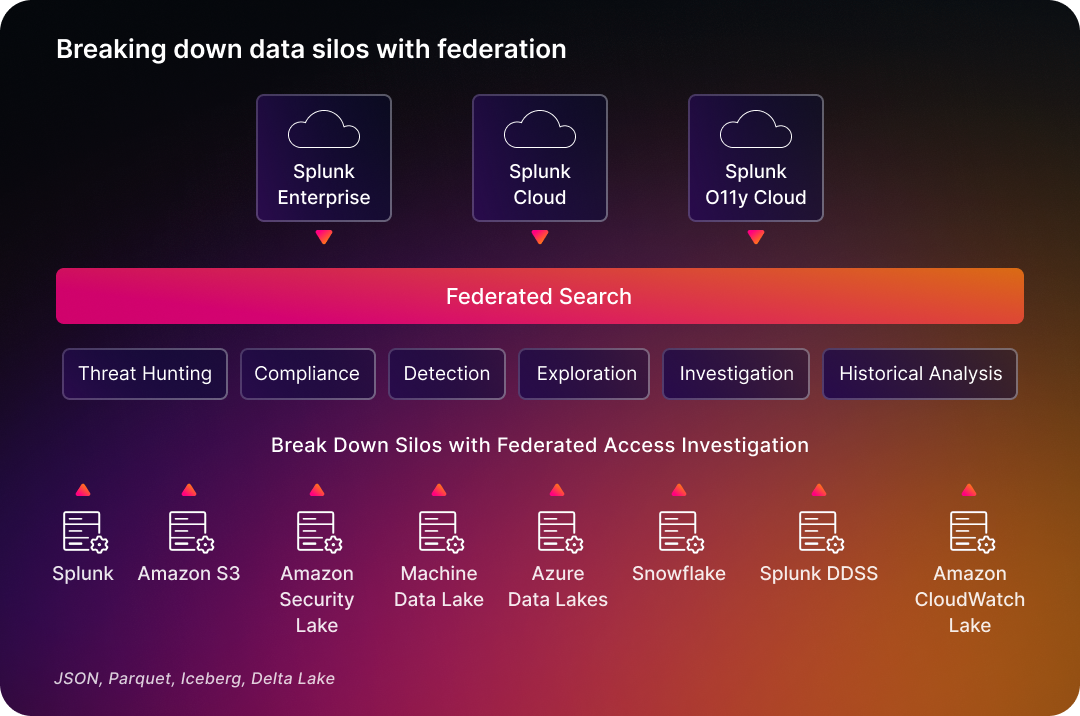
データレイク全体にわたってサーチと分析を実行できます。統合サーチと柔軟なデータ管理を組み合わせることで、コストと手間のかかるデータ移動を不要にします。
特長
分散したデータをそのままクエリー
あらゆる場所にあるデータを分析
AzureやAmazon S3をはじめとする外部のデータレイクを、データの移動や複製を行わずに横断的にサーチできます。そのため、データ移動に伴う遅延やストレージコストを発生させることなく、可視化の範囲を拡大できます。
インテリジェントで拡張性の高いデータの準備とルーティング
ストリーミングデータをSplunkや外部データレイクに転送する前にデータをフィルタリング、マスキング、変換、編集、集約するパイプラインを構築できます。AIを活用したフィールド抽出や柔軟なスキーマオプションにより、環境全体でデータを簡単に構造化、サーチ、分析できます。
SPL2クエリー言語による統合的な分析
パイプラインベースのクエリー言語であるSPL2を使用して、ストリーミングデータと履歴データにまたがる分析を簡単に実行できます。クエリーや関数はサーチとパイプラインの間で再利用できます。また、Splunk AI AssistantやCisco AI Canvasを利用して、パターン検出の迅速化や調査ワークフローの自動化を実現できます。
自動スキーマによるレジリエンス強化
上流工程でのスキーマドリフトによるクエリーの失敗を回避できます。動的スキーマ推論を使えば、外部データソースが自動的にマッピングされ、クエリー結果の一貫性を維持できます。データ構造が変化した場合でも対応でき、手動でのパイプラインメンテナンスも不要になります。



統合サーチに関するよくある質問
統合サーチを使用すると、従来のデータ取り込みプロセスを経由することなく、外部データレイクに対して直接クエリーを実行できます。Splunk統合サーチは、アドホック調査での作業負荷を減らし、インサイト取得までの時間を短縮します。Splunkの強力な分析エンジンとSPLクエリー言語を活用し、使いやすさと高速なパフォーマンスを実現しています。
統合サーチは、Amazon S3、Snowflake、Delta Lake、Iceberg、Azure Blobなどに保存されたデータに対する、低頻度のアドホック検索に適しています。代表的なユースケースとして、履歴データを対象としたセキュリティ調査、統計分析、データ拡充、データ探索などがあります。これらはSplunkにデータを取り込むことなく実行できます。
主なメリットは次の通りです。
- 不要なデータ重複を排除し、データの保存先を柔軟に管理できるため、TCOを削減できます。また、データの保存場所を問わず、統合されたサーチと分析を利用できます。
- データを元の保存環境に保持したまま、統合された強力なサーチ機能を利用できます。
- データの取り込みによる遅延を排除し、AIモデルのトレーニングや推論を高速化できます。
料金はスキャンしたデータ量に基づいて決まります。料金の詳細については、こちらにお問い合わせください。