
データ管理の新たなルール
データ管理の新たなルールを取り入れて、データの複雑さを軽減し、サイバーセキュリティとオブザーバビリティを向上させる方法をご紹介します。

ログ、ログ、どこを向いてもログ!2025年に世界全体のデータ生成量が181ゼタバイトを超えると予想されていることをご存じでしたか?だからこそ、今必要なデータはすばやく検索でき、急を要しないデータは必要に応じて後から検索する、そんな柔軟なデータ戦略がこれまで以上に重要になっています。
Splunkは2023年に、Federated Search for Amazon S3 (略して「FS-S3」)をリリースしました。FS-S3を使えば、Splunk Cloud PlatformでAWS GlueとAmazon S3間の接続を設定して、S3内のデータをSplunkに取り込むことなくサーチできます。後ほど説明するように、スピードとコストに関するビジネス要件はデータのタイプによって異なるため、このようなサーチ機能はあらゆるデータ戦略において重要です。そこで役立つのがFS-S3です。
次の図に、その仕組みを簡単に示します。
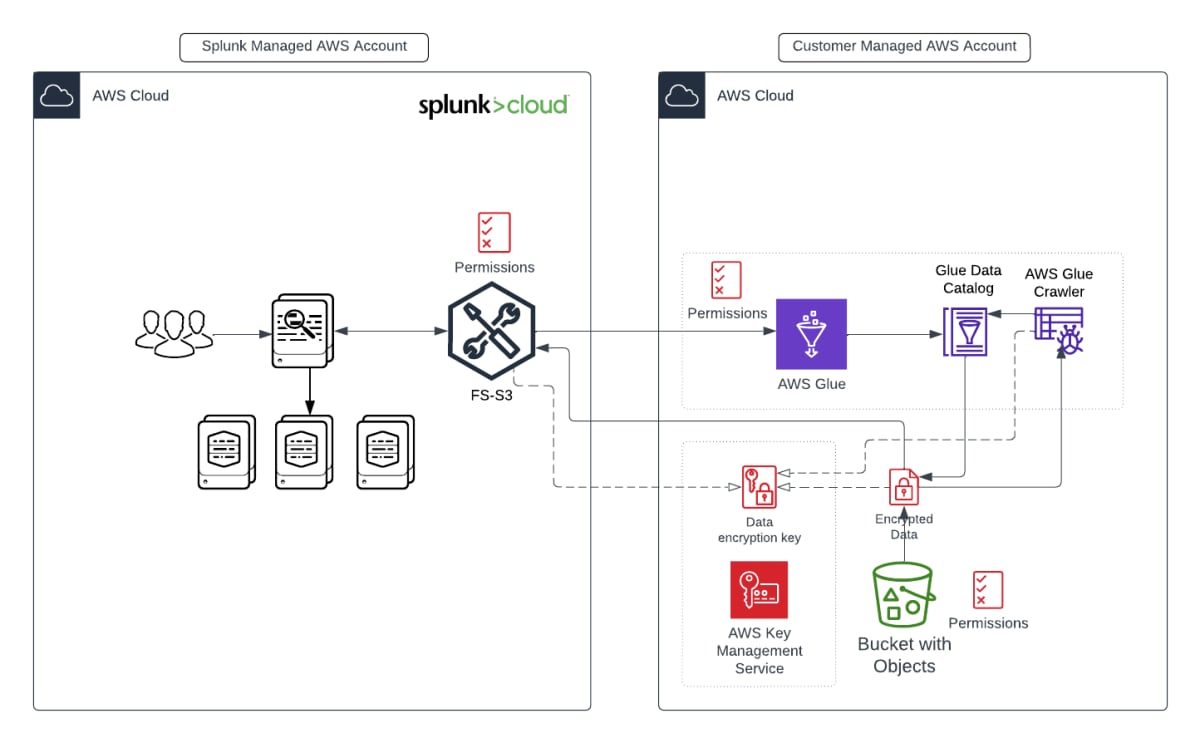
詳しい仕組みの説明に入る前に、重要なポイントである「この機能が必要な理由」をご説明しましょう。
データは増加の一途をたどっていますが、特に重要な点は、その増加ペースがあまりに速いことです。データがこのまま増加し続けることを考えれば、データの保存と利用方法についてアプローチを見直す必要があるでしょう。ビジネスの観点からも、純粋にコストの観点からも、すべてのデータを同じように扱う余裕はありません。まず取り組むべきは、ビジネスユースケースでの価値に基づくデータの階層化です。子供の頃、車で旅行に出かけるときに、親から「持っていくおもちゃを1つだけ選びなさい」と言われたときと同じです。もちろん、「その他」のデータに価値がないわけではありません。これらのデータは監査や事後調査で必要になるかもしれません。
これをセキュリティユースケースの観点から説明すると、次の図のように分類できます。
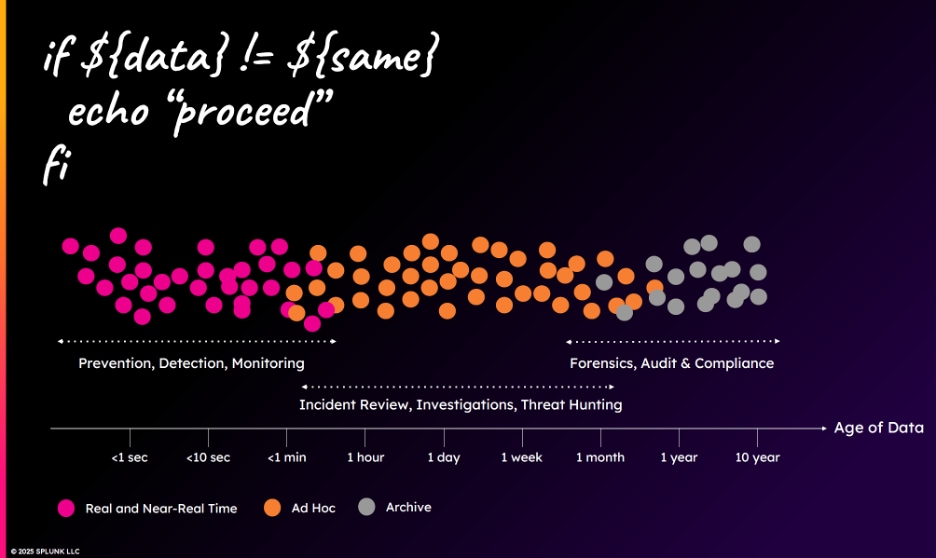
左側3分の1ほどの点は、価値の高いビジネスクリティカルデータを表します。これらのデータは、ビジネスクリティカルなサービスのセキュリティ対策、脅威検出、セキュリティ監視などに使われます。そこから右の、オレンジの大部分と灰色の点は、重要度が低く、即時のアクセスは不要と考えられるデータを表します。これらのデータは、インシデントレビュー、フォレンジック調査、コンプライアンス目的などに使われます。ただし、この図には注意が必要です。この例では、データの有用性を時間に基づいて評価し、過去数分以内の新しいデータはビジネスクリティカルで、1カ月以上経つような古いデータは有用性が薄いと判断しています。しかし、データの価値は常に時間によって決まるわけではなく、データを分類するための基準はさまざまなので、他の観点も考慮して評価する必要があります。
Splunkが最近公開したレポート『データ管理の新たなルール』では、次の3つの重要項目に基づいてデータ要件を見直すことを推奨しています。
このレポートは一読に値します。このブログでは、このうちの「データの階層化」に焦点を当てます。
ここで重要になるのが、データを「すぐにアクセスしたいデータ」(ホットデータ)と「必要になったときにアクセスできればよいデータ」(古いデータや使用頻度の低いデータ)に分類して階層化できるプラットフォームを利用することです。ホットデータは、高いパフォーマンスが求められるため、通常、最も高価なアーキテクチャに保存します。一方、古いデータや使用頻度の低いデータは、主に耐久性と保持期間が重要になるため、コスト効率の高いアーキテクチャに保存します。そのため、その両方の種類のデータとアーキテクチャに対応するプラットフォームが必要になります。
ここ数年の新しいトレンドは「インプレースサーチ」です。これは、データを現在の保存場所に置いたまま検索する機能です。「データ統合」とも呼ばれます。この機能は、「必要になったときにアクセスできればよいデータ」へのアクセスに最適です。
統合サーチが必要な理由をおわかりいただけたでしょうか。では次に、統合サーチに適したデータを考えていきましょう。
Splunkユーザーから「どのデータソースがインプレースサーチに適していますか」とよく尋ねられます。技術的にはあらゆるデータソースが適していると言えますが、私の考えに基づいてもう少し具体的な例を探ってみましょう。
包括的なアプローチとしては、「稀にランダムに検索したい」というカテゴリに該当するログは、FS-S3に最適な候補です。私がすぐに思いつく例は、AWS Web Application Firewall (WAF)で生成されるログです。
ご存じない方のために申し上げておくと、AWS WAFでは膨大な量のログが生成されます。AWS WAFのログをAmazon S3に送信するように設定すると、{年}/{月}/{日}のフォルダーだけでなく、その下に{時}/{分}のフォルダーも作成されます。通常は5分単位でログがまとめられます。
一方、このログの良い点は、パーティション分割に便利な形式であるため、FS-S3でのサーチに適していることです。
では、AWS WAF向けのAWS Glueの設定方法と、Splunk FS-S3でのログサーチの設定方法を簡単に見ていきましょう。
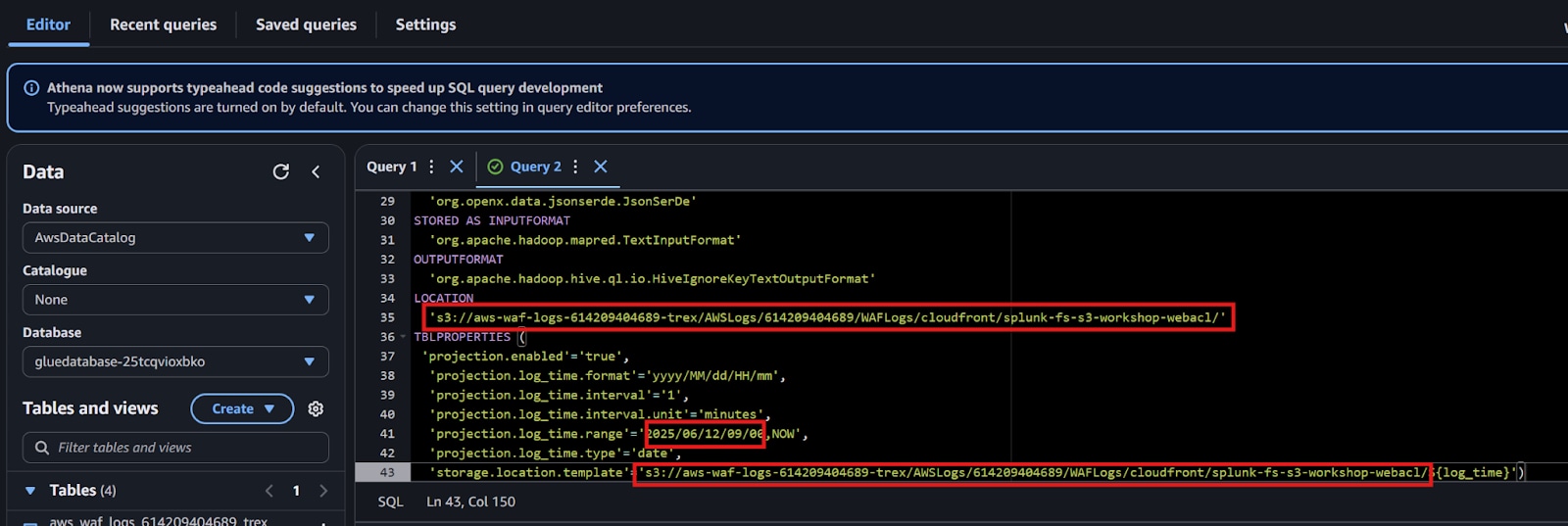
前述のとおり、AWS WAFでは5分単位でフォルダーが作成されます。そのため、ここではGlueクローラーのような機能ではなく、パーティション射影が可能なAmazon Athena DDLを使用します。AWS Glueクローラーのような機能では、特定の時点でスキーマが作成されるため、常に最新のログのスキーマを取得するには、クローラーを5分ごとに自動または手動で実行する必要があります。Athena DDLのパーティション射影を使えば、高度にパーティションされたテーブルのクエリー処理を高速化し、パーティション管理を自動化できます。
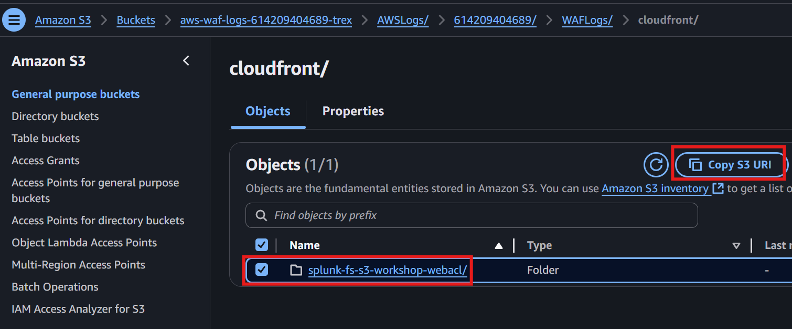
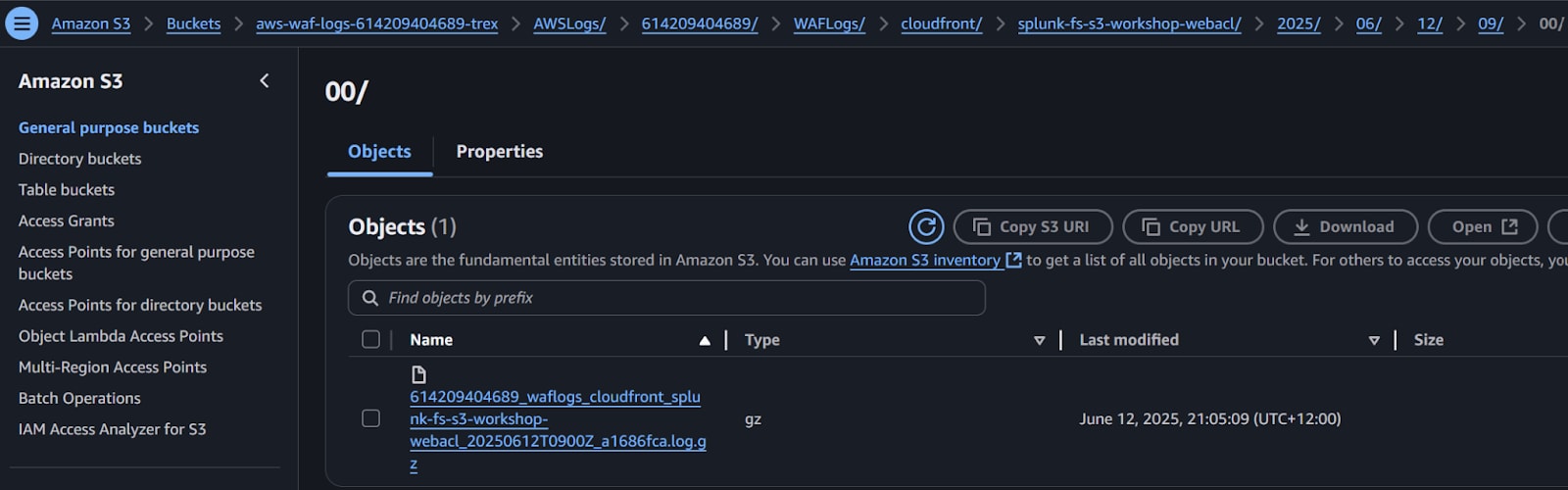
それではAthenaとS3の設定を見ていきましょう!
前提条件の概要:
手順
CREATE EXTERNAL TABLE `waf-logs-ddl`(
`timestamp` bigint,
`formatversion` int,
`webaclid` string,
`terminatingruleid` string,
`terminatingruletype` string,
`action` string,
`terminatingrulematchdetails` array>>,
`httpsourcename` string,
`httpsourceid` string,
`rulegrouplist` array>>>,nonterminatingmatchingrules:array>>,challengeresponse:struct,captcharesponse:struct>>,excludedrules:string>>,
`ratebasedrulelist` array>,
`nonterminatingmatchingrules` array>>,challengeresponse:struct,captcharesponse:struct>>,
`requestheadersinserted` array>,
`responsecodesent` string,
`httprequest` struct>,uri:string,args:string,httpversion:string,httpmethod:string,requestid:string,fragment:string,scheme:string,host:string>,
`labels` array>,
`captcharesponse` struct,
`challengeresponse` struct,
`ja3fingerprint` string,
`ja4fingerprint` string,
`oversizefields` string,
`requestbodysize` int,
`requestbodysizeinspectedbywaf` int)
PARTITIONED BY (
`log_time` string)
ROW FORMAT SERDE
'org.openx.data.jsonserde.JsonSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
''
TBLPROPERTIES (
'projection.enabled'='true',
'projection.log_time.format'='yyyy/MM/dd/HH/mm',
'projection.log_time.interval'='1',
'projection.log_time.interval.unit'='minutes',
'projection.log_time.range'='<FIRST DATE IN S3>,NOW',
'projection.log_time.type'='date',
'storage.location.template'='<S3 URI>/${log_time}')
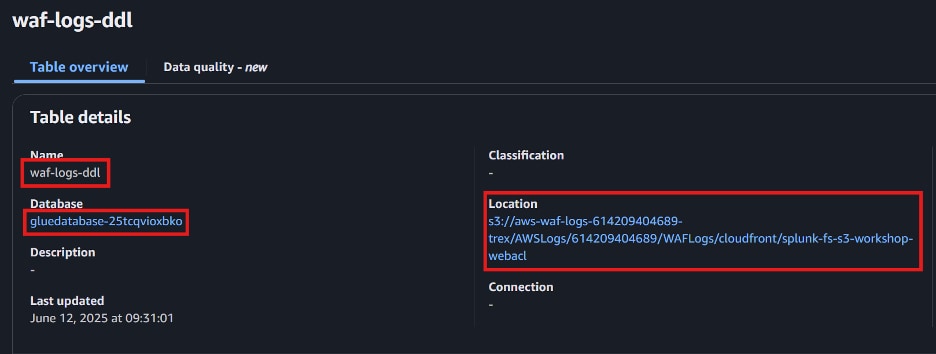
これで、Splunk Federated Search for Amazon S3を使用するためのAWSの準備が整いました。パート1はここまでです。
パート2では、Splunk側でのSplunk Federated Search for Amazon S3の設定方法についてご説明します。
お読みいただきありがとうございました。ご感想や良いアイデアがありましたら、いつでもお寄せください。
このブログはこちらの英語ブログの翻訳、森本 寛之によるレビューです。

© 2005 - 2026 Splunk LLC 無断複写・転載を禁じます。
© 2005 - 2026 Splunk LLC 無断複写・転載を禁じます。
