盲点と推測を排除し、監視ツールの切り替えの手間を省きましょう。Splunk Observability CloudとAI Assistantを使えば、1つのソリューションですべてのメトリクス、ログ、トレースを自動的に相関付けることができます。

オブザーバビリティの現状
グローバル調査で明らかになった、AI導入、セキュリティチームとのコラボレーション、ビジネス収益の促進要因に関する現状をご紹介します。
ブラウザ外形テストがもたらすのは確かさであるべきで、不確かさではありません。このシリーズをお読みいただいている方なら、本当に価値のあるテストをすでに実践していることでしょう。それらのテストでは実際のユーザー体験が反映され、結果が検証され、意味のあるアラートが発せられているはずです。
しかし、最高の外形テストでも、計画的な変更の際にノイズを発生させることがあります。
リリースの展開や定期メンテナンスの実施のたびに、外形テストによって、変更に伴う影響がすべて記録され始めます。キャッシュが温まるまでの間、ページの読み込みが遅くなるかもしれません。依存先が再起動することもあるでしょう。処理のフローが、その基盤となるインフラの切り替えに伴い、数分間不安定になることもあります。
しかし、これらは障害ではなく、単なる変更作業の影響に過ぎません。問題なのは、その過程で生じるノイズです。
そこで重要なのが、計画的なダウンタイムの管理です。リリースをマーキングし、想定される失敗を抑制し、メンテナンス期間を明確なビジネスコンテキストとともに明示しましょう。そうすることで、大きな環境変更の際にも、外形テストの品質を保ち、シグナルを有用に保つことができます。
この記事では、「外形監視を正しく行う方法」シリーズから、次のベストプラクティス「計画的なダウンタイムの適切な管理」についてご説明します。このシリーズを初めてお読みになる場合は、まず「はじめに」の記事で、これらのベストプラクティスを組み合わせてブラウザ外形テストの信頼性と実用性を高める方法の概要をご確認ください。
計画的なダウンタイムの管理とは、予定されている変更に備えてブラウザ外形テストを事前に調整する手法です。これにより、テストで判断を誤らせるような失敗やパフォーマンスデータの歪みが生じるのを防ぎます。この手法では、オブザーバビリティプラットフォームに対し、次のように指示します。「これから通常とは異なる状況が発生します。結果の解釈はその文脈を踏まえて行うこと」
Splunk Observability Cloudでは、ダウンタイムの設定によって次のことができます。
これにより、計画的な運用作業の前後や実施中においても、外形テストのシグナルを明確に保つことができます。たとえば、管理下でのデプロイ、アップグレード、パス変更といった作業です。
計画的なダウンタイムが重要な理由は、変更作業中にはノイズが生じやすく、ノイズによって本当に対応すべき問題が見えなくなってしまうためです(または、見えても確信が持てなくなります)。
リリースやメンテナンスの際にも、外形テストが正しく動作することで、ページの遅延やフローの不整合、一時的な失敗などが検出されます。問題は、メンテナンス中にこれらのシグナルが発生するのは想定内であることです。そのため、これらを本当のインシデントのように扱ってしまうと、偽のアラートが発生し、ダッシュボードにノイズが混入して、パフォーマンス傾向を誤って判断する原因となります。
主なリスクを挙げてみましょう。
計画的なダウンタイムでは、こうした問題を解決するために、想定される変更を明示し、不要なシグナルを抑制して、外形テストのデータの品質を保ちます。目標は、メンテナンス期間外に外形テストでアラートが発生した場合、それに何らかの意味があると確信できるようになることです。
Splunk Observability Cloudで計画的なダウンタイムを効果的に管理する方法をご説明します。これにより、外形テストのデータの品質と精度を保ち、実際の運用上の変更との整合性を確保できます。
Splunk Synthetic Monitoringでは、2種類のダウンタイムルールをサポートしています。それぞれメンテナンス中の外形テストのデータを収集したり解釈したりする方法が異なります。下の表に、ダウンタイムのオプションと使用例をまとめました。
ダウンタイムオプション
| ルール | 説明 | 結果 | 主な使用例 |
|---|---|---|---|
| テストの一時停止 | ダウンタイム期間中、指定した外形テストの実行を停止します。 | 外形テストのデータは収集されません。グラフには空白が表示されます。 | ログインメンテナンス、データベースの切り替え、既知の障害発生期間、インフラ関連作業 |
| データの補強 | テストの実行を継続し、各runにunder_maintenance=trueのタグを付与します。これらのrunは稼働率、SLA、SLO、平均値の計算から除外されます。 | 状況を継続的に可視化しながら、稼働率やベースラインのレポートの精度低下を防ぎます。 | リリースの際にウォームアップ時の挙動、依存先の再起動、ドリフトの観察が必要な場合 |
under_maintenance=trueタグが付与されたrunはSLAやSLOの対象外となりますが、変更時に生じる重要な挙動を確認するうえで役立ちます。
| 確認ポイント | 重要である理由 |
|---|---|
・デプロイ後のウォームアップによる影響 ・一時的な遅延のスパイク |
アプリケーションのキャッシュ、レディネスチェック、安定化のステップが必要と考えられる箇所を明らかにします。 |
・影響に対する依存関係の感度やサードパーティの不安定さ |
変更時に挙動が変わる脆弱な統合ポイントの特定に役立ちます。 |
・RUMやAPMと比較した性能低下の指標 |
外形テストでのパフォーマンスの低下が、実際のユーザーへの影響やバックエンドサービスの問題と一致しているかを確認します。 |
Splunkでは、ダウンタイムが外形テストのグラフ上に直接表示されるため、メンテナンスの実施時期や、実施に伴うパフォーマンスの変化をすばやく識別できます。
視覚的なインジケーターには以下が含まれます。
たとえば、以下のスクリーンショットをご覧ください。
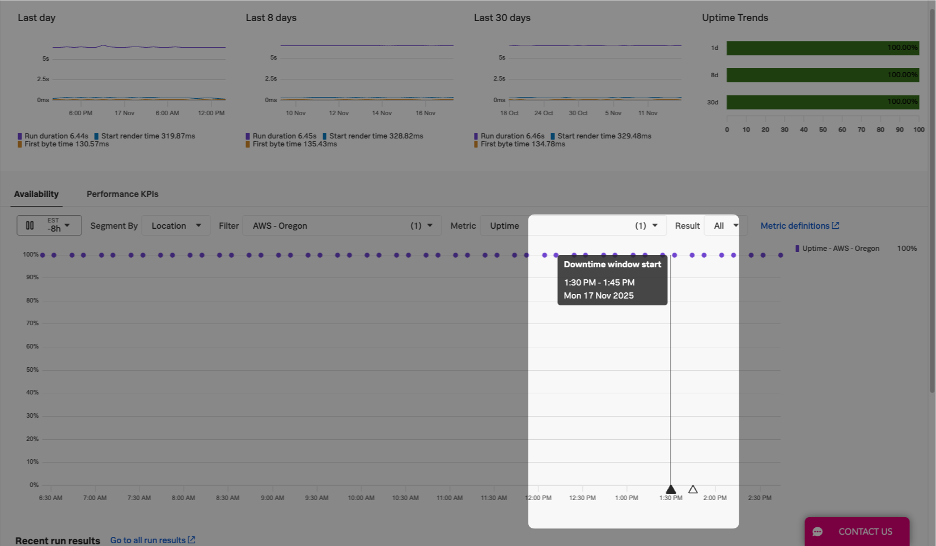
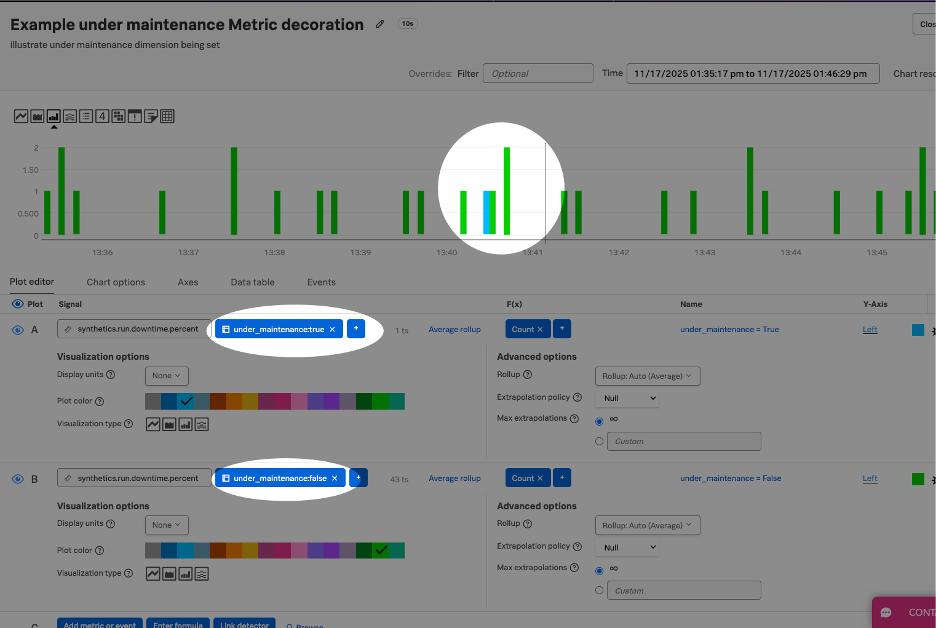
ダウンタイムの記録は13か月間保持され、過去の正確な状況の確認に利用できます。
Splunk Observability Cloudで外形テスト向けにダウンタイムを設定する方法は2つあります。次のいずれかから選択します。
いずれのアプローチもテストデータの品質を保つために役立ちます。どちらを選ぶかは、チームの運営方法によります。
Splunk UIの利用が適しているのは、運用上必要なメンテナンス期間や定期リリース、そして明快な視覚化を自動化せずに実現したい場合です。以前はダウンタイム期間の設定が変更管理プロセスの一環として行われ、変更承認後に変更タスクとの関連付けを通じて実施されていました。
以下はUIでの設定が適しているケースです。
UIでできるダウンタイム関連のアクション
| アクション | 説明 | 詳細 |
|---|---|---|
| ダウンタイム期間の作成 | 単発または繰り返しのダウンタイム期間の設定を、選択したテストに対して行います。 | ダウンタイム設定のスケジュールを作成する |
| 既存のダウンタイムの変更 | ダウンタイム期間の編集、延長、早期終了、削除をライフサイクルに応じて行います。 | 既存のダウンタイムを変更する |
UIベースの管理はシンプルかつ予測可能で、チームを横断した運用も容易です。
ダウンタイムの作成と管理はプログラムによって行うこともできます。それにはObservability Cloud APIを利用します。この選択肢が適しているのは、デプロイワークフローを自動化しているチームや、ダウンタイムの管理を直接リリースパイプラインや変更管理ツールから行いたいチームです。
以下はAPIでの設定が適しているケースです。
詳細:APIを活用して外形テストのダウンタイム設定を管理する
例:APIを使用したダウンタイム期間の作成
curl -X POST "https://api.us1.signalfx.com/v2/synthetics/downtime_configurations" \
-H "Content-Type: application/json" \
-H "X-SF-TOKEN: $TOKEN" \
-d '{
"downtimeConfiguration": {
"name": "release-maintenance",
"rule": "augment_data",
"testIds": [12345],
"startTime": "2025-05-01T02:00:00Z",
"endTime": "2025-05-01T03:00:00Z",
"timezone": "America/New_York"
}
}'
APIでダウンタイムを管理することで、オブザーバビリティにアプリケーションのデプロイや運用の状況が正しく反映されます。
メンテナンス期間の前後にはバッファ時間が必要です。デプロイ後にはシステムのウォームアップ、依存関係の初期化、キャッシュの再構築、トラフィックの安定化が行われるためです。
バッファ時間の役割には以下があります。
import requests
from datetime import datetime, timedelta
TOKEN = ""
REALM = "us1"
TEST_IDS = [12345]
start = datetime(2025, 5, 1, 2, 0)
end = datetime(2025, 5, 1, 3, 0)
buffer = timedelta(minutes=15)
downtime_start = start - buffer
downtime_end = end + buffer
payload = {
"downtimeConfiguration": {
"name": "release-maintenance",
"rule": "augment_data",
"testIds": TEST_IDS,
"startTime": downtime_start.isoformat()
+ "Z",
"endTime": downtime_end.isoformat() + "Z",
"timezone": "America/New_York"
}
}
resp = requests.post(
url=f"https://api.{REALM}.signalfx.com/v2/synthetics/downtime_configurations",
json=payload,
headers={"Content-Type": "application/json", "X-SF-TOKEN": TOKEN},
)
print(resp.status_code, resp.text)
メンテナンスが完了したら、重要性の高いテストを直ちに実行し、主要なワークフローが正常に動作していることを確認します。これには、次のいずれかの方法を用います。
これにより、リリースが正常に完了したことを直ちに確認できます。
詳細:
計画的なダウンタイムの目的は、アラートを止めることだけではありません。それは、管理下での変更の間も外形テストのデータの品質とシグナルの信頼性を保つことでもあります。外形監視は、的確なダウンタイムルール、十分なバッファ、APIによる自動化、メンテナンス後の検証を活用し、補強されたテストrunを適切に利用することで、オブザーバビリティプラクティスの安定性と信頼性を支える要素となります。
適切に管理されたダウンタイムは強みになります。たとえば、メンテナンス期間外に外形テストでアラートが発生した場合、それが本物のアラートであることを確信できます。リリース中にアラートが発生しなければ、設定が正しく機能しているとわかります。また、補強されたrunを通じてドリフトや脆弱性が明らかになれば、それを早期警告のサインと捉えて、ユーザーに影響が及ぶ前に対処できます。
現在のダウンタイム設定を見直し、重要なテストに適切なルールが設定されていることを確認しましょう。次回のリリース前後にはバッファ時間を設け、ダウンタイムAPIを使ってプロセスを自動化し、メンテナンス完了後に主要なワークフローを検証してみてください。
今後もチームが信頼できる外形テストを構築していくために、本シリーズの他の記事もぜひご覧ください。また、Splunk Observability Cloudの無料トライアルを利用して、Synthetics、RUM、APMがどのように連携して完全にエンドツーエンドの可視性を実現するかをご確認いただけます。

盲点と推測を排除し、監視ツールの切り替えの手間を省きましょう。Splunk Observability CloudとAI Assistantを使えば、1つのソリューションですべてのメトリクス、ログ、トレースを自動的に相関付けることができます。

© 2005 - 2026 Splunk LLC 無断複写・転載を禁じます。
© 2005 - 2026 Splunk LLC 無断複写・転載を禁じます。
