
オブザーバビリティの現状
グローバル調査で明らかになった、AI導入、セキュリティチームとのコラボレーション、ビジネス収益の促進要因に関する現状をご紹介します。

Splunkを使用しているお客様や導入を検討しているお客様から、「AWS CloudWatchや、Azure Monitor、Google Cloudオペレーションスイート(旧称Stackdriver)でクラウドを監視できるのに、なぜわざわざSplunkを使う必要があるのか?」とよく尋ねられます。実に良い質問です!
クラウドプロバイダーが提供する監視ソリューションは一般的に「安い」、「簡単」、「統合性が高い」と言われ、特にクラウドの導入初期には重宝されがちです。私たちもこのようなアプローチをよく目にしますが、実はこれが間違いの元なのです。
このブログでは、Splunkが必要な理由をご理解いただくため、先ほどの質問に対する回答の「要約」を示してから、その裏付けとして、クラウドプロバイダーのソリューションだけでは決して得られない5つのインサイトとその具体例をご紹介します。
なぜ、クラウドプロバイダーの監視ソリューションだけでなく、Splunkが必要なのでしょうか?
端的に言えば、クラウドプロバイダーの監視ソリューションだと、多くの場合、データが独自に管理され、サイロ化して、他のソースのデータと統合処理したり相関付けたりできないためです。また、機能や操作性が、Amazon、Microsoft、Google各社が「これで十分」と考える範囲に限定されるという弱点もあります。
いずれも以前からある問題です。だからこそSplunkは、何年も前からデータを「解放」し、相関付けるソリューションとして標準的な地位を確立しているのです。たとえば、VMWareについて考えてみましょう。VMWare管理者は、VMWareプラットフォームを監視、管理、トラブルシューティングするためのツールとしてvSphereに満足しているかもしれません。では、VMWare仮想マシン上で実行するアプリケーションオーナーはどうでしょうか?通常、アプリケーションで問題が発生してもvSphereにログインすることはないでしょう。しかし、アプリケーションの問題の原因が、予期しないvMotionイベントや「ノイジーネイバー(うるさい隣人)」のVMにある可能性は十分にあります。同じことが、データベース、ネットワーク、ストレージ、その他すべてのテクノロジーにも言えます。複数のシステムのデータを1カ所に統合できないと、問題が発生したときにデータを相関付けて調査し、根本原因に辿り着くことは難しくなります。
要約的な回答ではまだ納得できないという方のために、クラウドプロバイダーの監視ソリューションでは得るのが難しい5つのインサイトを具体的にご紹介します。
今日、多くの組織が複数のクラウドアカウントを管理し、複数のリージョンにリソースを分散配置しています。この場合、「インフラ全体の使用状況」を把握したいときは請求明細書を調べるしかありません。しかし、クラウドプロバイダーのコンソールでアカウントやリージョンを切り替えながら使用状況を1つ1つ調べていくのは骨の折れる作業です。Splunkなら、すべてのアカウントとリージョンを含むインフラ全体の状況を把握するための重要な情報を簡単に確認できます。たとえば、以下の疑問を解決できます。
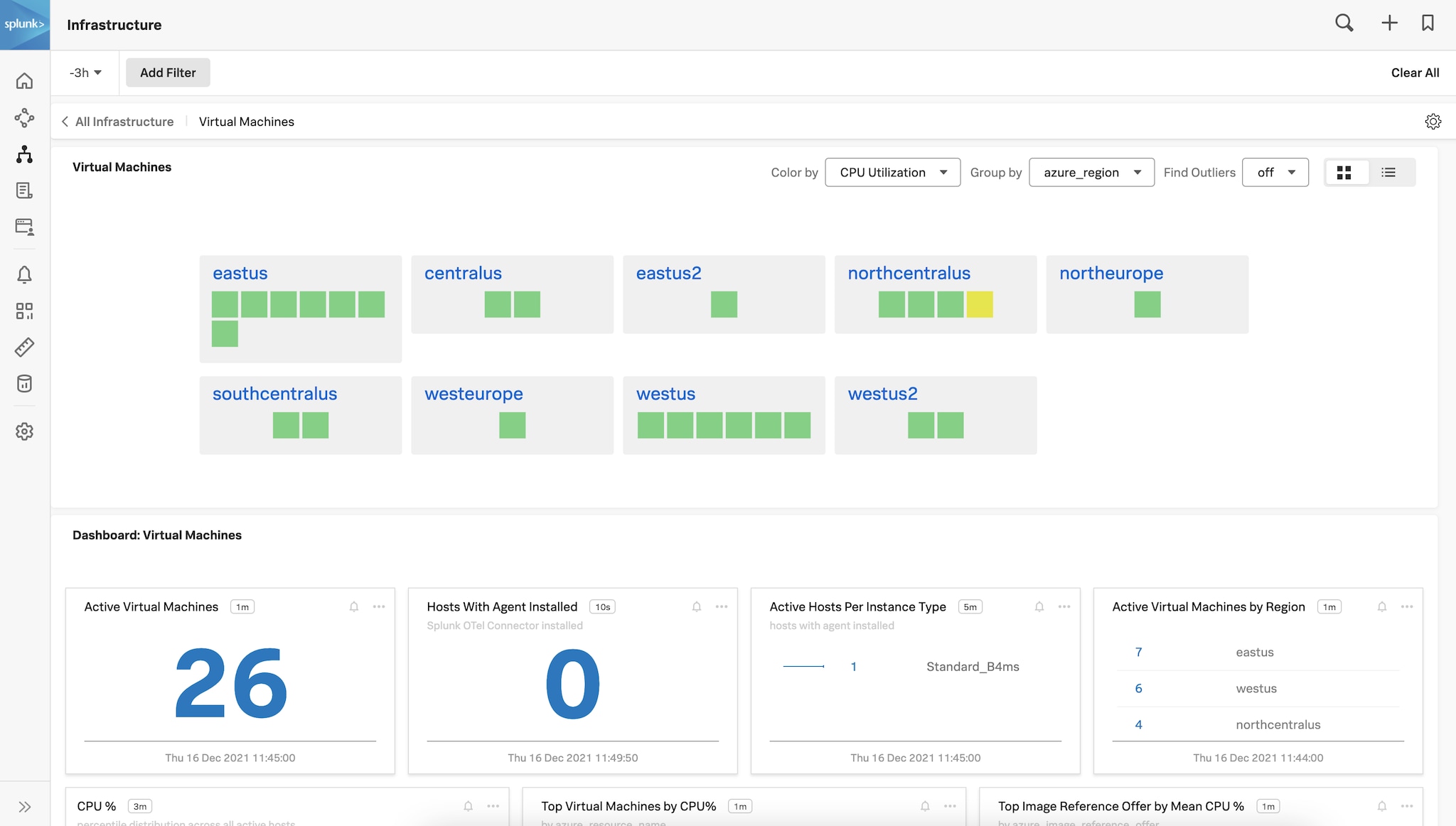
図1:アカウント全体のすべてのAzure VMに関するリージョン別インベントリ
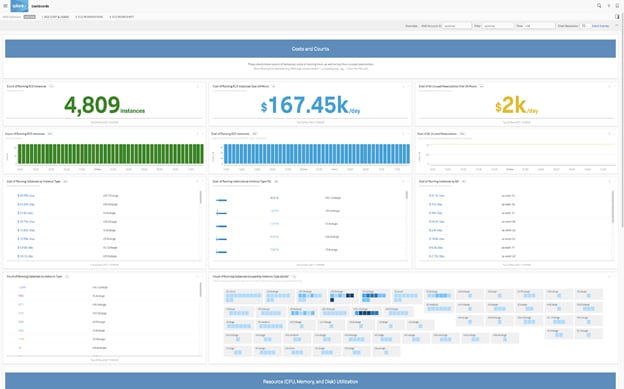
図2:SplunkのAWS EC2コスト分析ダッシュボード
多くの組織がワークロードのクラウド移行を進めていますが、オンプレミスに残して外部サービスと依存関係にあるワークロードもあるでしょう。実際、組織のビジネスに欠かせない重要な基幹システムを支えるワークロードはオンプレミスに残すことがよくあります。一方、ワークロードのクラウド移行は段階的に行い、リスクの低いコンポーネントから移行するのが一般的です。そして、ほとんどの場合、移行したワークロードは機能を遂行するためにコールバックを使用してオンプレミスの依存サービスを呼び出します。
このようなアプリケーションのトラブルシューティングをする場面を想像してみてください。実際に経験したことがある方も多いでしょう。それは、次のような感じではないでしょうか。まず、クラウド運用チームが特定のクラウドプロバイダーの監視ソリューションで確認すると、「すべて正常」と報告されています。そこで、IT運用チームが独自の監視ツールで調査すると、こちらも「すべて正常」と報告されます。
Splunkなら、監視と調査を1つのプラットフォームで行えるため、このような複雑な問題も解決できます。Splunkのサーチ、ダッシュボード、各種グラフを「共通言語」として、各チームが連携しながら問題のトリアージ、切り分け、調査に当たることができます。
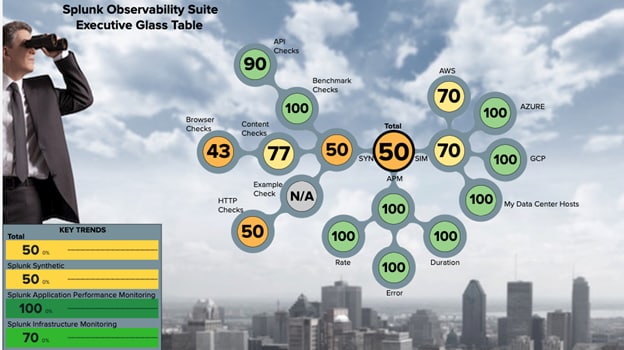
図3:マルチクラウドのサービス健全性スコアが表示されたSplunk ObservabilityのExecutive Glass Table
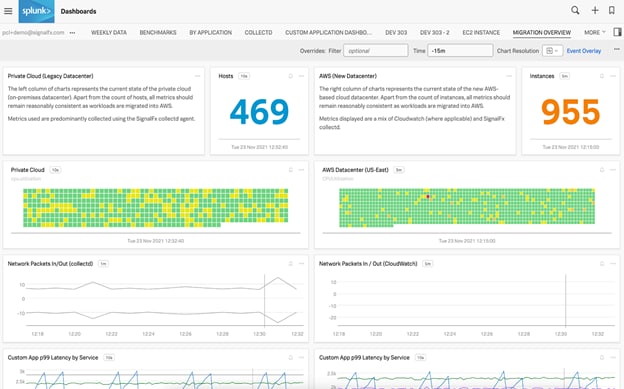
図4:プライベートクラウドホストのメトリクスとAWSインスタンスのメトリクスが表示されたSplunkダッシュボード
クラウドプロバイダーの監視ソリューションでは、監視対象のデータタイプや監視の精度が制限されます(仕方のないことですが)。たとえばAWS CloudWatchでは、デフォルトでメトリクスが5分単位で収集され、精度を最大にしても1分が限度です。もし、子守りを頼んだベビーシッターがずっとスマートフォンをいじっていて、5分に1回、子どもにちらっと目をやるだけだったらどう思うでしょうか?「二度と頼まない」と思いますよね。5分あれば、多くの問題が噴出する可能性があります。
精度に加えて、あるデバイスについて収集したいテレメトリがクラウドプロバイダーのメトリクスでサポートされていないという状況も起こり得ます。再びアマゾン ウェブ サービス(AWS)を例に挙げると、EBSストレージは、実際に使用している容量ではなく、割り当てたディスクの合計サイズに基づいて課金されます。では、クラウドコストを節約したい場合、CloudWatchで各EBSボリュームのストレージ使用率を監視、視覚化すればよいのでしょうか。残念!CloudWatchでは、ボリュームのサイズは簡単に確認できても、使用容量を知るために必要なメトリクスは収集されません。そこがSplunkとの違いです。
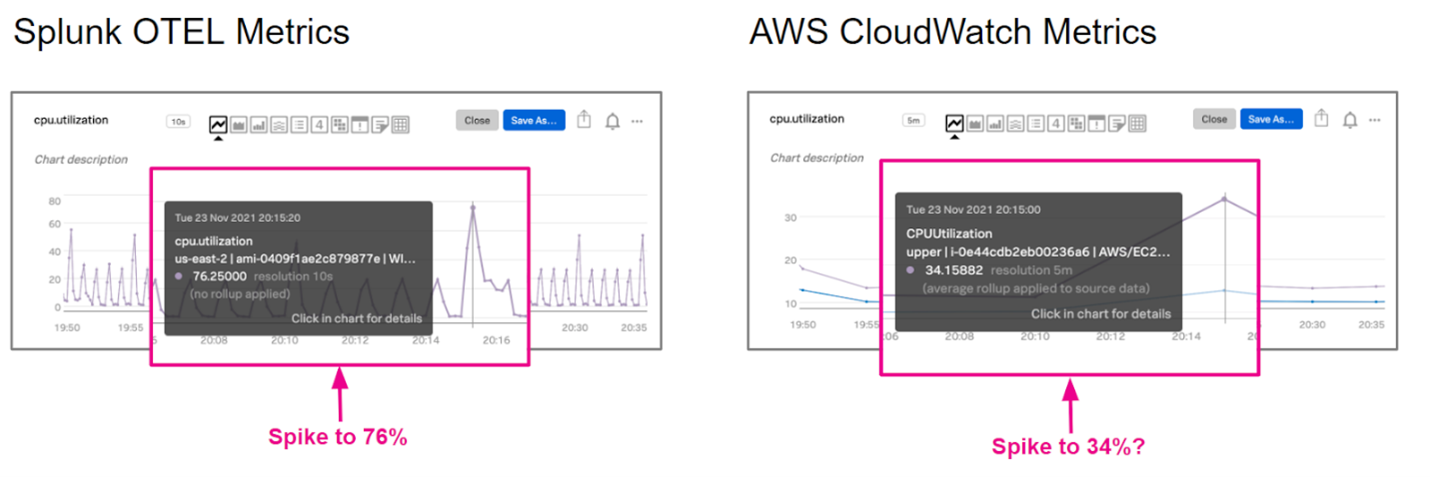
図5:SplunkのOpen Telemetry (OTEL)メトリクスとAWS CloudWatchのメトリクスを比較した図
Splunkは調査と分析には自信があります。正直なところ、クラウドプロバイダーの監視ソリューションでログを調査、分析すると、すぐにがっかりし、物足りなく感じるでしょう。基本的な収集、サーチ、インサイト導出はできても、詳細な調査や環境全体の分析を行うには、Splunk独自の高度なデータ収集、解析、サーチ機能が欠かせません。具体例をいくつか挙げましょう。
最近デプロイしたコードによって環境内で新たな問題が発生していないかどうかを調べたいとします。高度な分析スキルがあれば、過去に見たことのないスタックトレースを探すという方法もありますが、これは容易ではありません。同じスタックトレースが過去に生成されていないかを1つ1つ調べる必要があるからです。しかしSplunkなら、強力なSPL (サーチ処理言語)を使って簡単に検出できます。
また、誤って公開する設定になっているS3バケットデータがないかどうかを調べたい場合はどうでしょうか。これもSplunkがなければ大仕事です。Splunkなら、やはりSPLを使って、S3アクセスログを収集し、ルックアップで位置情報を追加して、S3バケット名ごとのアクセス状況を地図にプロットできます。簡単ですね!
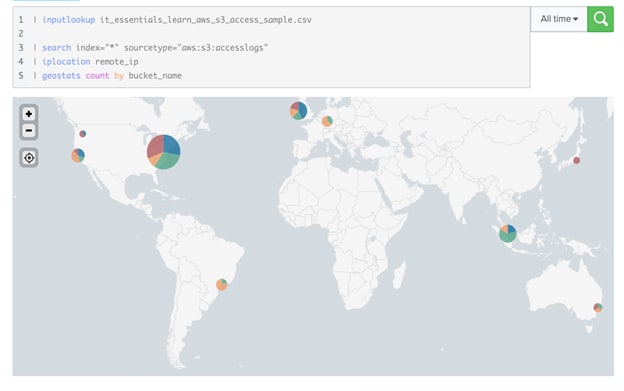
図6:AWS S3の位置情報ルックアップとプロットが表示されたSplunkダッシュボード

図7:Splunkでのスタックトレースサーチの詳細

図8:Splunkでのスタックトレースの検出とトレンド分析
当然ですが、データの収集は第一歩にすぎません。データは活用してこそ価値があります。クラウドプロバイダーの監視ソリューションでは各社のサービスからデータを収集するのは簡単で、多くの場合、ドメイン固有のダッシュボードも用意されています。しかし、異なるサービスのデータを相関付けたり、すべてのサービスのデータを一元的に表示したい場合は、ほぼ手動で行わなければなりません。さらに、すべてのアプリケーションとその基盤のアーキテクチャはそれぞれ固有の情報を持つため、多数の異なるソースのデータを有意義に視覚化するのは至難の業です。
Splunk Infrastructure Monitoring (SIM)とSplunk Application Performance Monitoring (APM)では、用意されたワークフローを使用して、すべてのソースの重要データをさまざまな方法で処理できます。コンテキストに基づくデータの詳細調査がすぐに可能になるため、ROIを早期に実現し、データの価値を最大限に引き出すことができます。また、ドメイン固有のダッシュボードの代わりに、Splunkの事前構築済みのダッシュボードをテンプレートとして使用すれば、ミッションクリティカルなサービスのデータを相関付けて処理をエンドツーエンドですばやく把握できます。さまざまなダッシュボードから特定用途のダッシュボードにチャートやその他のグラフを簡単にコピーして、アクションにつなげることもできます。そのダッシュボードをチームメンバーと共有してチーム用ダッシュボードにすれば、共同作業を効率化できます。
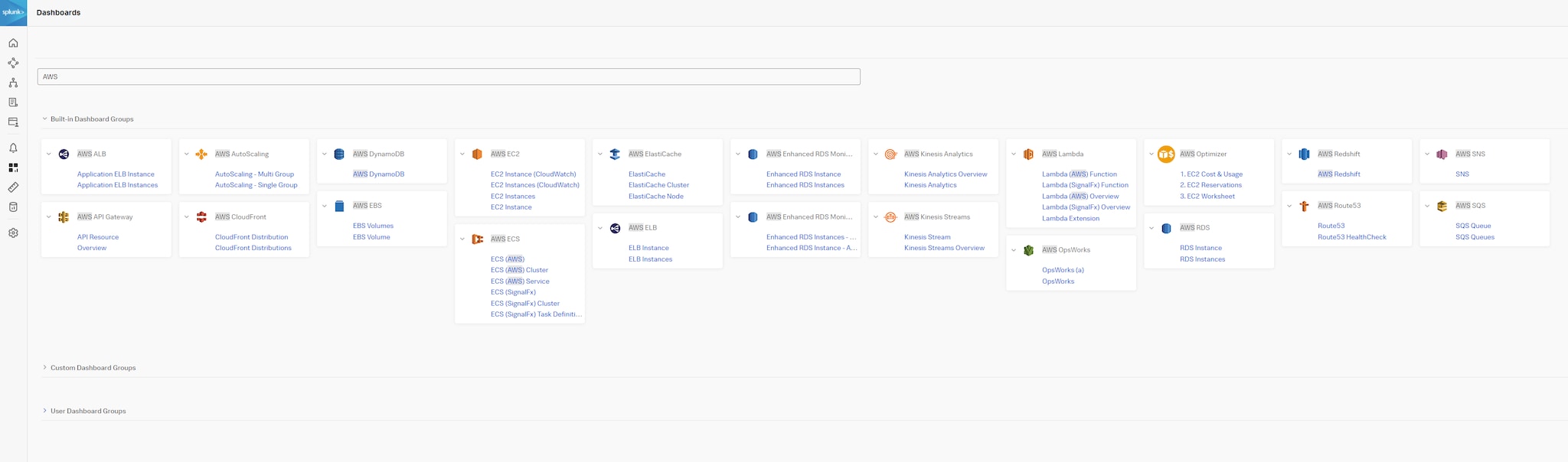
図9:Splunk Observability Cloudに用意されたAWS用ダッシュボードグループ
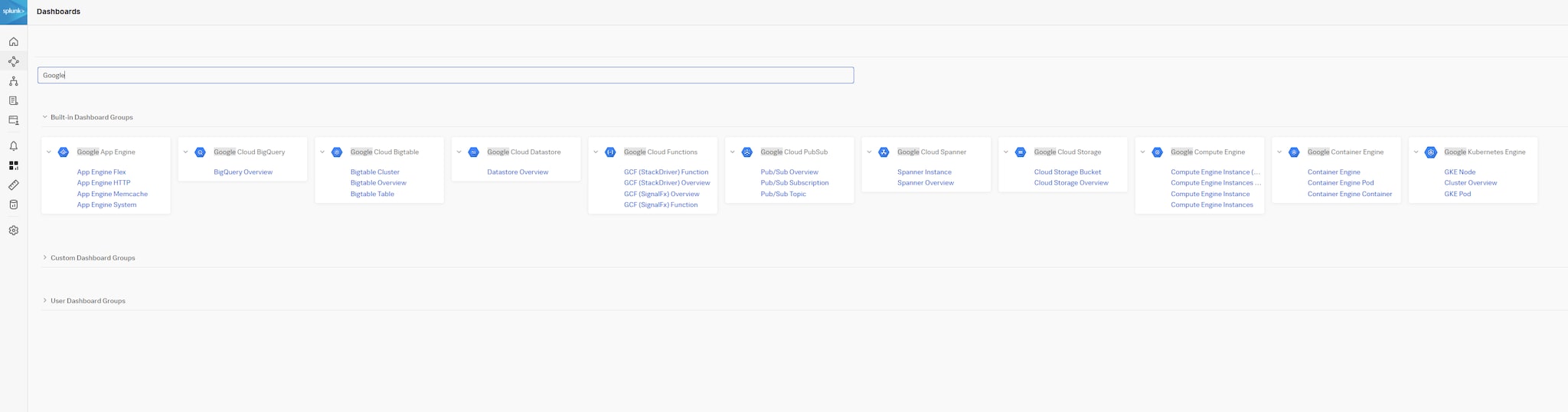
図10:Splunk Observability Cloudに用意されたGoogle Cloud Platform用ダッシュボードグループ
図11:Splunk Observability Cloudに用意されたAzure用ダッシュボードグループ
クラウドプロバイダーの一番の目的は、インフラ、プラットフォーム、ソフトウェアをサービスとして提供することです。インフラを効果的に監視するためのツールの提供は最優先事項ではありません。Splunkは何年もの間、新しいテクノロジーが登場する中でその状況を注視してきましたが、どのクラウドプロバイダーもだいたい同じで、突出した点はありません。一方、Splunkの一番の目的は、あらゆるタイプのマシンデータを効果的に収集、サーチ、分析、監視して、データを行動に変えられるようにすることです。
進化を続けるクラウド環境をプロアクティブに監視、分析するための、ITチーム、クラウド運用チーム、DevOpsチーム向けのSplunk機能について詳しくは、Splunk Observability CloudのWebページをご覧ください。
このブログはこちらの英語ブログの翻訳です。

© 2005 - 2026 Splunk LLC 無断複写・転載を禁じます。
© 2005 - 2026 Splunk LLC 無断複写・転載を禁じます。
