AIドリブンのインサイトを活用
数十、数百のマイクロサービスを運用している環境では、問題を引き起こしているサービスを特定するのが困難です。Splunk APMなら、AIドリブンのインサイトにより、問題のあるサービスが一目でわかります。
オブザーバビリティ
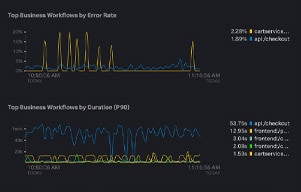
重要なビジネスKPIに影響を及ぼす問題を特定し、関連するすべてのデータを相関付けて直感的に可視化することで、MTTRを短縮
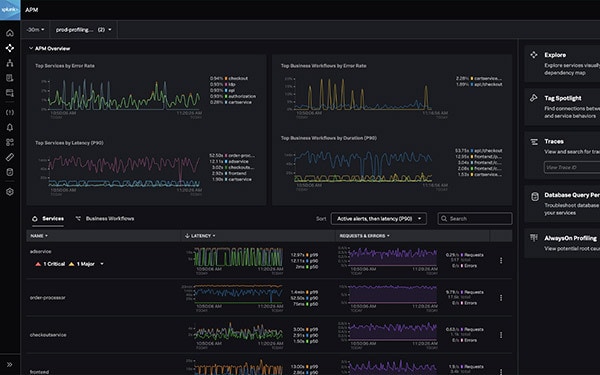
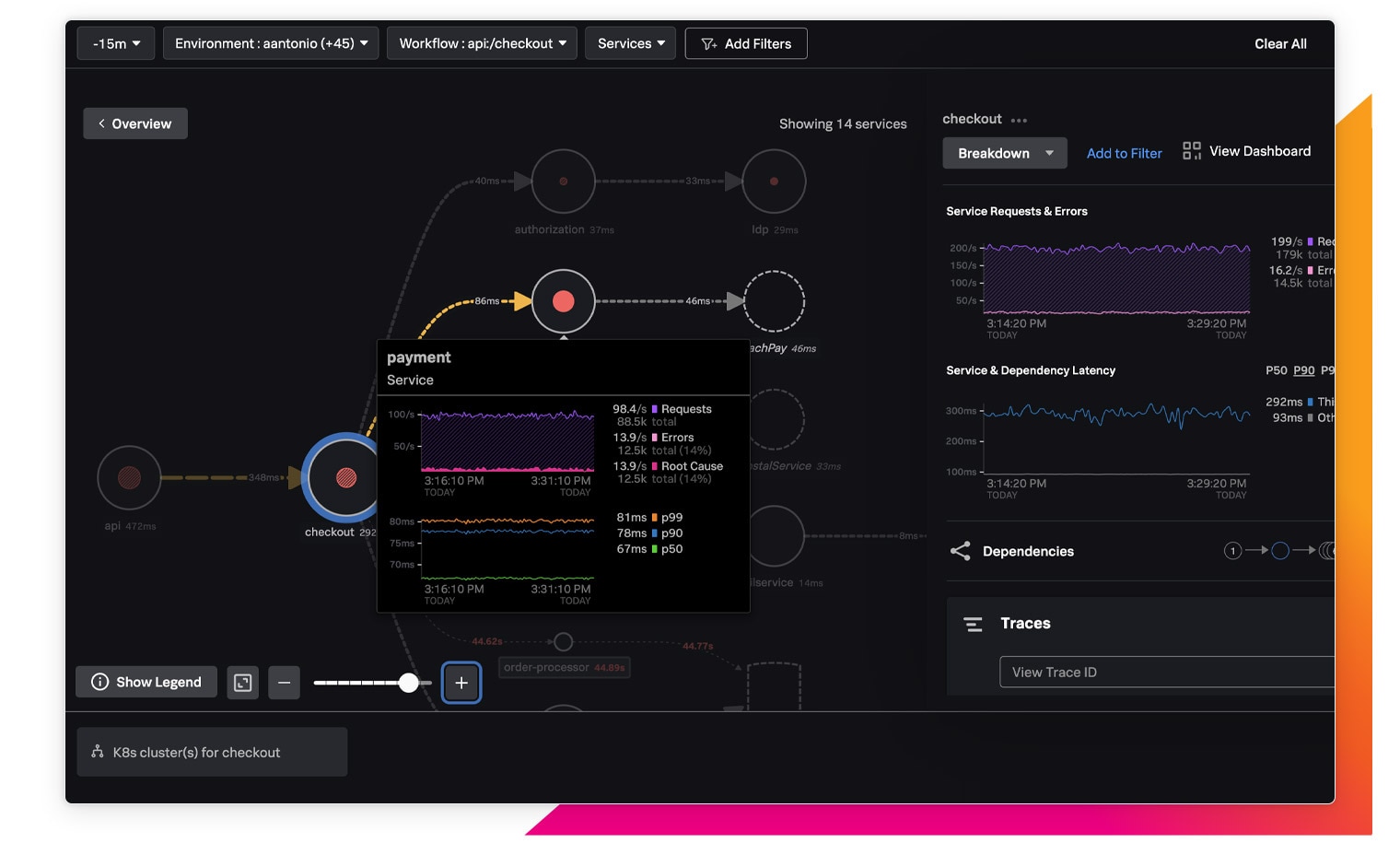
Splunk Observability Cloudの一部であるSplunk APMでは、すべてのアプリケーションデータ、インフラデータ、フロントエンドデータ、ログデータを活用して、問題の根本原因をすばやく究明できます。
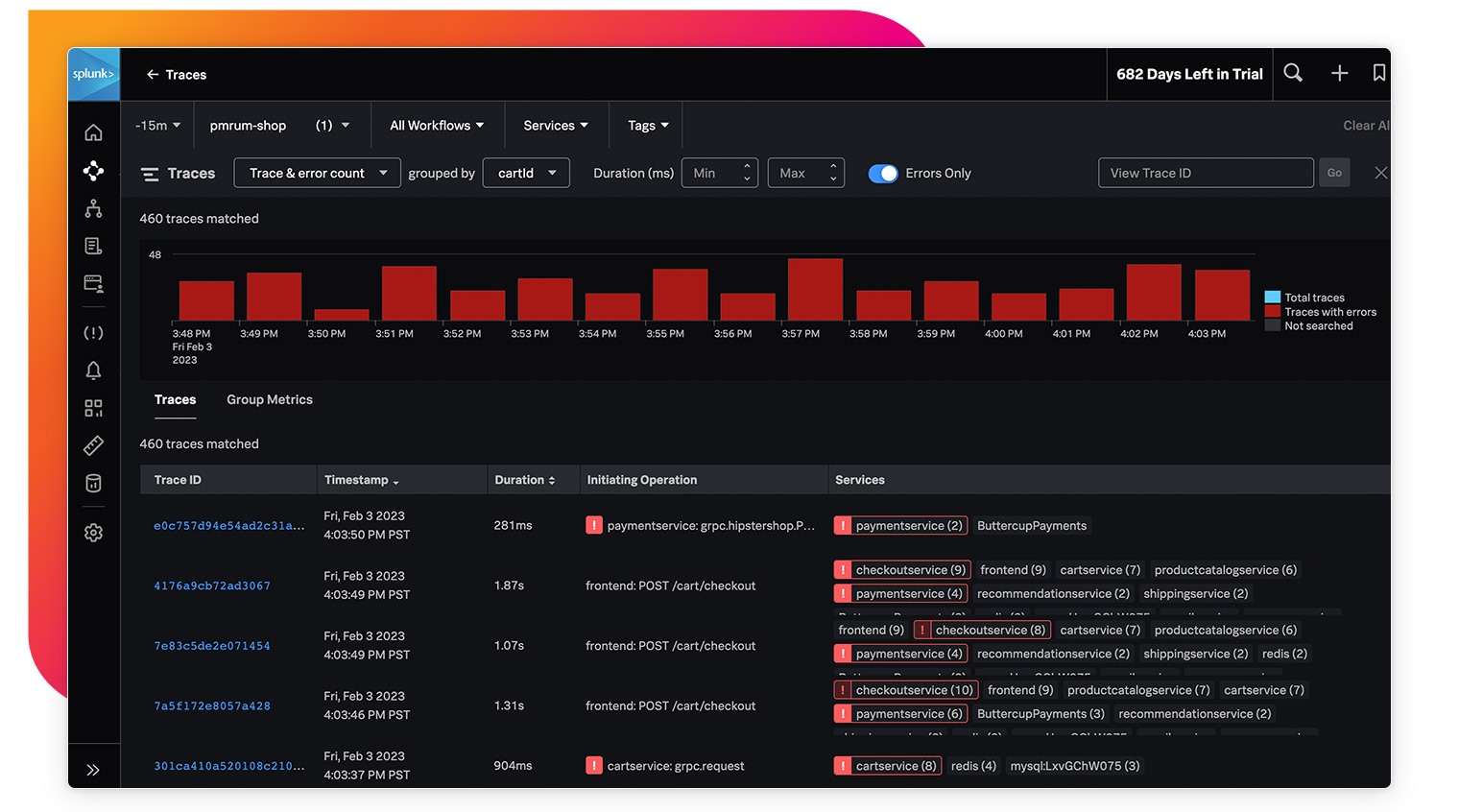
自動的に生成されるマップで赤い点を確認して、問題の根本原因となっているサービスを一目で特定
問題のあるトレースの共通点を探って、インフラ、コード、ビジネスロジックのいずれに原因があるかをすばやく判断
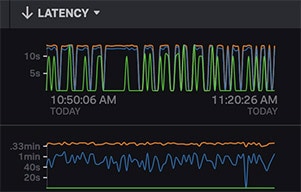
保存された完全なトレースデータを、タグ値、エラー、レイテンシーの任意の組み合わせでサーチ
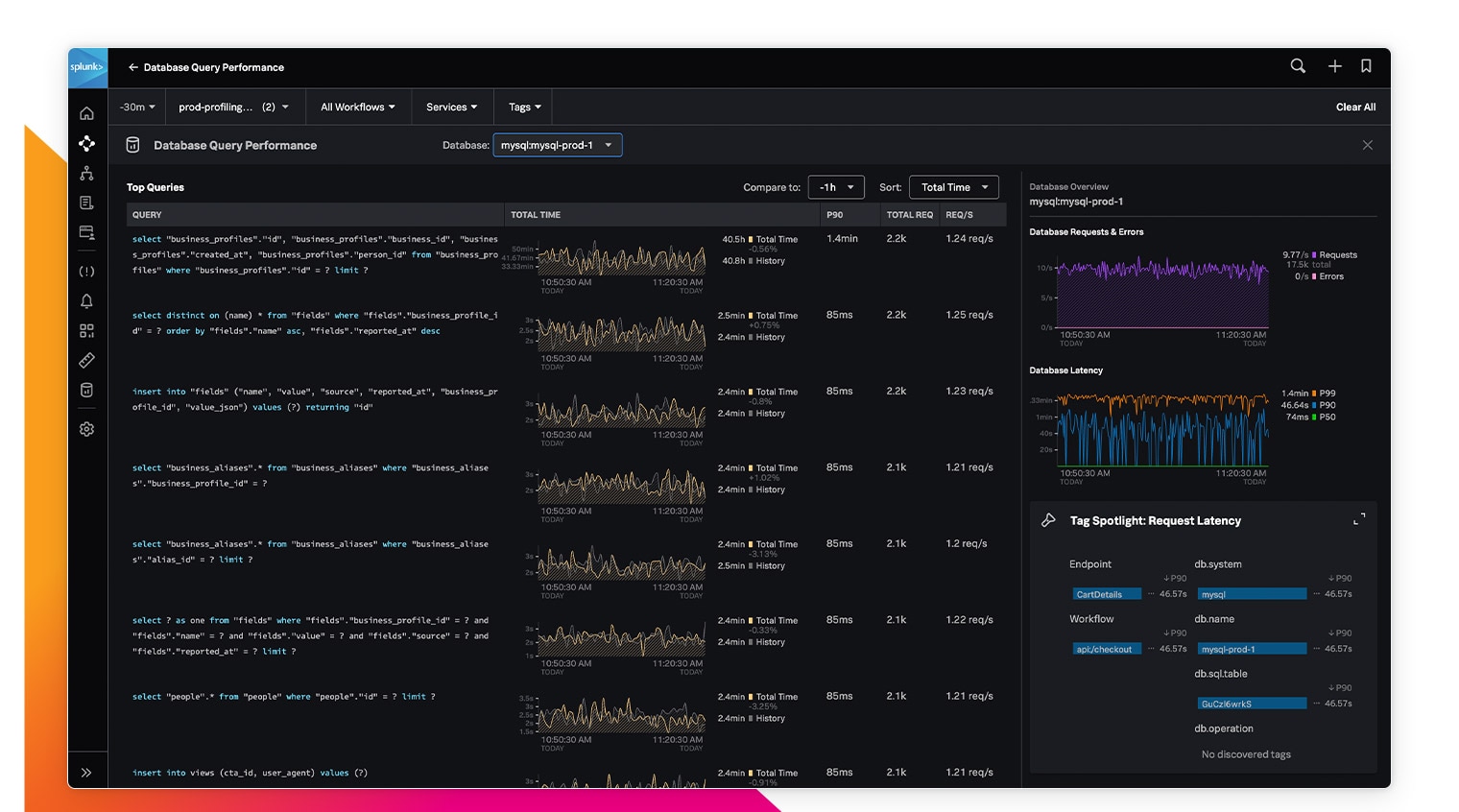
内蔵のコードプロファイリングによって、Java、.NET、Node.jsで記述されたコードによるCPUとメモリーの使用率を継続的に監視
トレース、プロファイリング、インフラメトリクス、ログデータを自動的に相関付けて、トラブルシューティングを迅速化
一般的なデータベースで、応答時間の低下や問題のあるクエリーの検出時にアラートを生成

誰かから何か言わないと気付かない環境から、自らアラートで気づいて対処もすぐにできるようになるという理想的な環境が、Splunkによって実現できました。すぐに気づけて原因特定に向けてアプローチしやすくなったことが何よりも大きい
© 2005 - 2026 Splunk LLC 無断複写・転載を禁じます。