
Ein Fahrplan zu digitaler Resilienz im Unternehmen

Moderne Unternehmen erleben nicht nur eine rasante Zunahme des Datenvolumens, sondern auch der Vielfalt der Use Cases für Daten. In solchen Umgebungen kann ein monolithischer Einheitsansatz bei der Tarifstruktur nicht immer mit dem Mehrwert skaliert werden, den die Datenplattform schafft. Um dieser wachsenden Herausforderung zu begegnen, bietet die Splunk Cloud Platform euch die Flexibilität, zwischen zwei Tarifoptionen zu wählen, die den Wert für eure spezifischen Anwendungsfälle optimieren sollen: das auf der erfassten Datenmenge basierende Tarifmodell und das Workload-basierte Tarifmodell.
Das auf der erfassten Datenmenge basierende Tarifmodell ist ein mengenbasierter Ansatz, der mit der Datenmenge skaliert, die pro Tag in die Splunk Cloud Platform eingespeist wird. Das Workload-basierte Tarifmodell skaliert dagegen in Abhängigkeit von der Kapazität, die für den erwarteten Ressourcenbedarf für die Verarbeitung von Datensuchen und -analysen vorab erworben wird. Das auf der erfassten Datenmenge basierende Tarifmodell eignet sich daher ideal für Unternehmen, die über separate Datensets verfügen und ihr Datenvolumen und ihre Suchmuster bereits im Vorfeld abschätzen können. Wenn beispielsweise erwartet wird, dass Suchvorgänge in großem Umfang im Datenbestand durchgeführt werden, dann ist der auf der erfassten Datenmenge basierende Tarif der passende Ansatz.
Dagegen gibt euch das Workload-basierte Tarifmodell die Flexibilität, mehr Daten in die Splunk Cloud Platform einzulesen, ohne dass ihr euch Sorgen machen müsst, dass durch große Datenmengen mit geringem Reporting hohe Kosten entstehen. Wenn ihr beispielsweise annehmt, dass ein großer Teil eurer Daten nur selten durchsucht wird, ihr aber dennoch die Möglichkeit haben möchtet, diese Daten mit anderen Daten in eurer Plattform zu korrelieren, dann ist das Workload-basierte Tarifmodell die richtige Option. Dieses Modell eignet sich auch ideal für Unternehmen, die sich die Möglichkeit offen halten möchten, Daten in die Plattform einzuspeisen, ohne dass sie davon ausgehen, diese Daten für Suchen zu verwenden.
Wir sehen uns nun die Komponenten des Workload-basierten Tarifmodells näher an, klären, was SVC-Einheiten sind, und erläutern, wie ihr Workloads dimensioniert, überwacht und verwaltet, wenn sich eure Datenanforderungen mit Splunk weiterentwickeln.
Beim Workload-basierten Tarifmodell werden die anfallenden Kosten auf der Grundlage der Ressourcen, die für die gewünschten Workloads benötigt werden, sowie des Speicherbedarfs für die zu analysierenden Daten ermittelt:
Splunk Virtual Compute (SVC) ist eine Einheit aus Computing- und zugehörigen Ressourcen, die ein konsistentes Niveau von Such- und Erfassungsvorgängen bietet, das dem Benchmark-Wert für die SVC-Leistung entspricht. Sie basiert auf zwei Hauptbestandteilen der Splunk Cloud Platform: Indexern und Search Heads.
Beispiele für Workloads sind die Compliance-Speicherung, einfaches Reporting und kontinuierliches Monitoring. Um diese Workloads zu bewältigen, nutzen SVCs im Wesentlichen zwei Faktoren: die Suche und die Erfassung. Jede Workload hat ihr eigenes Profil, das sich irgendwo zwischen „Viel Erfassung/wenig Suche“ und "Wenig Erfassung/viel Suche“ einordnen lässt. In den nachfolgenden Beschreibungen und der Grafik findet ihr einige der gängigsten Workload-Profile:
Compliance-Speicherung: Beim Speicher-Management wird sichergestellt, dass die Speichersysteme eines Unternehmens und seine Daten vollständig geschützt sind, so wie dies in den Sicherheitsanforderungen des Unternehmens (Compliance) vorgesehen ist. Der Hauptzweck besteht darin, Daten für Compliance-Zwecke aufzubewahren, d. h. sie für den Fall bereitzuhalten, dass in Zukunft Analysen oder Untersuchungen erforderlich werden. Bei Use Cases im Zusammenhang mit der Compliance-Speicherung wird von einem sehr geringen Suchaufkommen ausgegangen, weshalb die Workload-Anforderungen für jedes verarbeitete GB niedrig sind.
Data Lake: Ein Data Lake ist ein flexibles Speicher-Repository, in dem strukturierte und unstrukturierte Rohdaten gespeichert werden können. Bei einem Data Lake-Anwendungsfall geht es darum, Daten aus verschiedenen Quellen verfügbar und bei Bedarf zugänglich zu machen. Es wird davon ausgegangen, dass nur selten auf die Daten zugegriffen wird, der Zugriff aber häufiger erfolgt als bei Daten, die aus Compliance-Gründen gespeichert werden. Die Workload-Anforderungen sind immer noch relativ gering, aber höher als bei der Compliance-Speicherung.
Einfaches Reporting: Dies ist der Vorgang, bei dem Rohdaten gesammelt, formatiert und in ein verständliches Format umgewandelt werden, um die Unternehmensleistung zu bewerten. Diese Daten werden nur selten durchsucht oder genutzt. Sie werden für fest eingeplante Berichte und/oder Dashboards verwendet, die nur zur Ansicht dienen. Daher sind die Workload-Anforderungen pro verarbeitetem GB beim einfachen Reporting durchschnittlich hoch.
Ad-hoc-Untersuchung: Ad-hoc-Untersuchungen werden von Business-Nutzern nach Bedarf durchgeführt, um Datenanalyseanforderungen zu erfüllen, die von den statischen, regelmäßigen Berichten des Unternehmens nicht abgedeckt werden. Endbenutzer führen Ad-hoc-Untersuchungen durch, wenn sie bestimmte Erkenntnisse gewinnen wollen. Das Suchvolumen ist relativ hoch und weniger vorhersehbar, was zu höheren Workload-Anforderungen pro verarbeitetem GB führt.
Kontinuierliches Monitoring: Kontinuierliches Monitoring bietet Echtzeiteinblicke in die IT-Umgebung eines Unternehmens. Typisch für kontinuierliches Monitoring sind geplante und häufige Suchen in bestimmten Datensets. Dies führt zu einer sehr hohen Suchaktivität, dem Use Case mit der höchsten Workload-Intensität und erfordert den größten Ressourcenaufwand pro GB des überwachten Datenvolumens.

Speicherblöcke bilden den zweiten Teil der Formel für das Workload-basierte Tarifmodell. Die Menge an benötigtem Speicherplatz wird durch das Datenvolumen und die Dauer der Speicherung bestimmt. Die Splunk Cloud Platform bietet folgende Speicherarten in 500 GB-Blöcken, um viele verschiedene Anwendungsfälle und Speicherschemata abzudecken:
Weitere Informationen über DDAA und DDSS findet ihr im Blog Dynamische Daten: Datenspeicheroptionen in Splunk Cloud.
Messwerte für die SVC-Nutzung pro Rechner werden alle paar Sekunden erfasst. Die SVC-Nutzung für eure Splunk Cloud Platform-Umgebung wird ermittelt, indem diese Nutzungswerte über alle Such- und Indizierungsschichten pro Stunde aggregiert werden. Ihr könnt euch eure SVC-Nutzung pro Stunde jederzeit in der Cloud-Monitoring-Konsole (CMC) ansehen.
Die Gesamtzahl der benötigten SVCs entspricht der maximalen Anzahl an Rechen-, I/O- und Speicherressourcen, die während des Zeitraums der höchsten Nutzung verwendet werden.
Bei vielen Unternehmen kommt es im Tagesverlauf zu Lastspitzen auf der Plattform, also einem Zeitraum mit sehr hoher Nutzung, gefolgt von einem langen Zeitraum mit geringer Nutzung. So kommt es beispielsweise in der Minute nach Mitternacht meist zu einer Lastspitze, da sich häufig alle täglichen, stündlichen und minütlichen Suchvorgänge zu diesem Zeitpunkt überschneiden, wie in der Abbildung unten zu sehen ist.
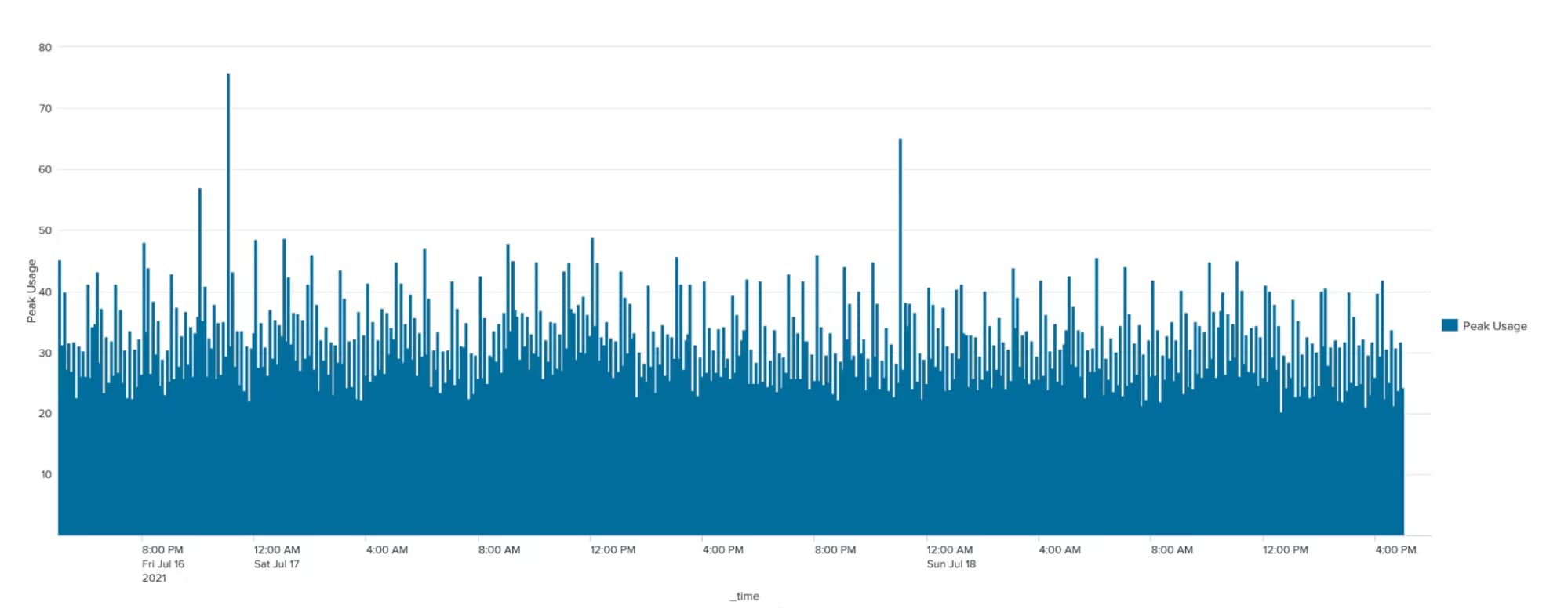
Diese Workloads können durch die Verteilung von Workloads, die sich nicht unbedingt überschneiden müssen, gemanagt werden. Andere Faktoren, die sich auf Workloads auswirken, können ebenfalls optimiert werden, z. B. die Suchnutzung, Apps und die Benutzerzahl. Wenn sich eure anhaltende Workload im Tagesverlauf konstant der zugewiesenen Anzahl von SVCs nähert, ist dies ein Hinweis darauf, dass ihre mehr SVC-Einheiten benötigt, um die Arbeitslast zu bewältigen.
Das auf der erfassten Datenmenge basierende Tarifmodell orientiert sich nur am Datenvolumen (eine Dimension) und stellt deshalb einen einfachen Ansatz für den Einstieg in die Splunk Cloud Platform dar.
Das Workload-basierte Tarifmodell ist zweidimensional (es basiert auf dem Datenvolumen und der Suchintensität) und erfordert ein genaueres Verständnis der Anforderungen. Es ist unter Umständen jedoch kostengünstiger, wenn euer Workload-Profil weniger Suchanwendungsfälle umfasst.
Splunk-Neulingen empfehlen wir, zunächst die erwarteten Workloads und das pro Tag erwartete Datenvolumen für jede Workload zu ermitteln. Denkt daran, dass jedes Profil auf zwei Hauptfaktoren basiert: Suche und Erfassung. Die Kombination dieser Faktoren bestimmt eure SVC-Nutzung. Ausgehend von historischen Mustern bei bestehenden SVC-Kunden ist euer Suchprofil wahrscheinlich der größte Treiber bei der SVC-Nutzung. Die nachstehende Tabelle zeigt die Arten von Suchvorgängen, die Kunden für verschiedene Use Cases durchführen, sowie die Spanne an Erfassungsvolumen im Verhältnis zu den jeweils benötigten SVC-Einheiten. Wir geben hier Spannen an, da die Zahlen auf den Nutzungsstatistiken einer Gruppe von Kunden und nicht auf einem einzelnen Datenpunkt basieren. Die SVC-Nutzung kann je nach Komplexität der erfassten Daten und der durchgeführten Suchvorgänge variieren.
| Workload-Typ / Datenanwendungsbeispiel | Beschreibung | GB/Tag pro SVC für jeden Use Case |
Compliance-Speicherung |
Compliance-Daten werden einmal in den Speicher geschrieben und fast nie durchsucht. Diese Daten werden nur aus Gründen der Compliance und Datenaufbewahrung gespeichert. |
35-45 oder mehr |
Data Lake (Untersuchung/Use Case-Entwicklung) |
Daten mit unbekanntem/nicht erschlossenem zugeschriebenem Wert. Diese Daten werden in der Regel indiziert und vergessen oder nur sehr selten verwendet, und es wird nicht erwartet, dass Suchen in diesen Daten sehr leistungsfähig sind. |
25-35 oder mehr |
Einfaches Reporting |
Diese Daten werden für fest geplante Berichte und/oder nur für die Anzeige bestimmter Dashboards verwendet. Diese Daten werden nur selten durchsucht oder verwendet. |
20-30 |
Ad-hoc-Untersuchung |
Daten mit wenigen Feldern bzw. Daten, die für Ad-hoc-Suchen verwendet werden. Daten, auf die selten zugegriffen wird, werden in der Regel einige Male am Tag oder öfter durchsucht und für interaktive Untersuchungen verwendet. |
15-25 |
Kontinuierliches Monitoring |
Hochwertige Daten werden in der Regel proaktiv bei live oder nahezu in Echtzeit durchführten Hintergrundsuchen verwendet. Diese Daten sind in der Regel extrem wertvoll und werden häufig für Informationen aus den Bereichen Sicherheit, Geschäftsbetrieb und IT verwendet. |
10-20 |
Premium-Lösung ES oder ITSI (Workload gering)
|
Splunk Premium-Lösungen bieten Funktionen für kontinuierliches Monitoring und Untersuchungen, um die Sicherheitslage zu verbessern und die Verfügbarkeit und Zuverlässigkeit des Unternehmens-Service aufrechtzuerhalten. Diese Premium-Anwendungen verwenden die meisten Systemressourcen. |
10-15 |
Premium-Lösung ES oder ITSI (Workload hoch)
|
Splunk Premium-Lösungen bieten Funktionen für kontinuierliches Monitoring und Untersuchungen, um die Sicherheitslage zu verbessern und die Verfügbarkeit und Zuverlässigkeit des Unternehmens-Service aufrechtzuerhalten. Diese Premium-Anwendungen verwenden die meisten Systemressourcen. |
5-10 |
Diese Beispielspannen geben einen ungefähren Anhaltspunkt für die Dimensionierung eurer SVC-Anforderungen. Euer Splunk-Vertriebsteam kann euch dabei helfen, die angemessene Menge an GB/Tag pro SVC für eure Workloads abzuschätzen. Wir verwenden diese Schätzungen, um eure SVC-Buchung zu dimensionieren. Wenn euer primärer Use Case beispielsweise die Compliance-Speicherung ist, erfasst ihr wahrscheinlich etwa 35 bis 45 GB/Tag pro 1 SVC-Einheit.
Ihr könnt den Splunk-Dimensionierungsrechner nutzen, um die Anzahl der SVCs abzuschätzen, die ihr benötigt. Die Berechnung basiert dabei darauf, wie effizient ihr glaubt, Splunk betreiben zu können. Der Splunk-Dimensionierungsrechner gibt euch zwar eine gute Schätzung der benötigten SVC-Anzahl, wir empfehlen euch jedoch, euch für weitere Einzelheiten mit eurem Splunk Account Team in Verbindung zu setzen.
Was bestehende Splunk Enterprise-Kunden mit On-Premise- oder Bring Your Own License-Systemen (BYOL) angeht, so hilft die Splunk Cloud Migration Assessment-App euch, Datenpunkte zu erfassen und eure Bewertung zu automatisieren. Dies ist extrem hilfreich, wenn ihr bereits über eine Splunk-Bereitstellung verfügt, die mehrere unterschiedliche Use Cases abdeckt.
Bestehende Splunk Cloud Platform-Kunden mit auf der erfassten Datenmenge basierendem Tarifmodell, die zum Workload-basierten Tarif wechseln möchten, können sich direkt an ihr Splunk Account Team wenden. In der Splunk Cloud Platform stehen bereits sämtliche Metriken zur Verfügung, die eurem Team bei seiner Empfehlung helfen.
Das auf der erfassten Datenmenge basierende Tarifmodell skaliert mit dem Volumen der in die Plattform eingespeisten Daten und eignet sich für Unternehmen mit vorhersehbarem Datennutzungsbedarf. Das Workload-basierte Tarifmodell ist auf die für die Datenverarbeitung verwendeten Computing-, I/O- und Speicherressourcen ausgerichtet. Mit dem Workload-basierten Tarif haben Unternehmen die Flexibilität, im Vorfeld viel mehr Daten zu erfassen, und können verschiedene Use Cases untersuchen, wobei die Nutzung durch die CMC vollständig überwacht wird.
Weitere Einzelheiten dazu, was ihr in der CMC anzeigen und steuern könnt, findet ihr im Blog über das Workload-basierte Tarifmodell und SVCs: Was ihr sehen und steuern könnt.
*Dieser Blog wurde erstmals am 13. September 2021 veröffentlich und zuletzt am 26. Mai 2023 überarbeitet.

Die führenden Unternehmen der Welt vertrauen auf Splunk, einem Unternehmen von Cisco, um ihre digitale Resilienz mit der einheitlichen Sicherheits- und Observability-Plattform, unterstützt durch branchenführende KI, kontinuierlich zu stärken.
Unsere Kunden setzen auf die preisgekrönten Sicherheits- und Observability-Lösungen von Splunk, um die Zuverlässigkeit ihrer komplexen digitalen Umgebungen zu sichern und zu optimieren – in jeder Größenordnung.

Die neuesten Artikel von Splunk, direkt im eigenen Posteingang.
© 2005 - 2026 Splunk LLC All rights reserved.
© 2005 - 2026 Splunk LLC All rights reserved.