
Wege zum Aufbau erfolgreicher Observability-Praktiken
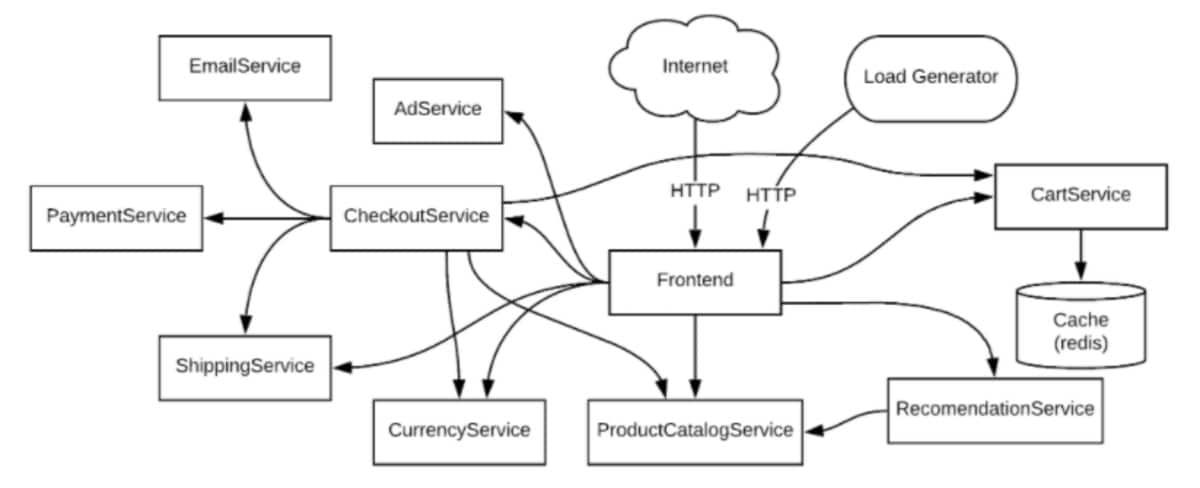
Der Aufbau moderner verteilter Systeme und Microservices mit einem hohen Maß an Observability ist enorm wichtig. In diesem Blog-Beitrag wird erläutert, warum die notwendige Transparenz, mit der DevOps-Teams den Gesamtzustand des Systems überwachen und Fehlerquellen schnell und effizient finden können, über den Erfolg oder Misserfolg eines Systems entscheiden kann.
Auf Microservices basierende Systeme
Eventgestützte Architektur
Die inhärente Herausforderung moderner Softwaresysteme
Das „Wie“ der End-To-End Observability
Der monolithische Ansatz vs. moderne Softwarearchitekturen
Hohe Transparenz in modernen Systemen mit der Observability Suite von Splunk erzielen
Fazit
Im Gegensatz zum monolithischen Ansatz besteht ein auf Microservices basierendes System aus einer Reihe unabhängiger Komponenten, den so genannten Services. Jeder Service wird separat ausgeführt und ist für seine eigene Teilmenge an Funktionalität verantwortlich. Die Services kommunizieren lose gekoppelt miteinander, und ihre Interaktionen definieren das System als Ganzes. Microservices sind in anfragebasierten Anwendungen (wie E-Commerce) weit verbreitet und werden in Cloud-Umgebungen häufig eingesetzt.
Die lose Kopplung des Systems ist in mehrerlei Hinsicht vorteilhaft. DevOps-Teams können beispielsweise problemlos weitere Instanzen bestimmter Services hochfahren, um den Bedarf des Unternehmens zu decken. Außerdem können Microservices laufend verbessert und unabhängig voneinander bereitgestellt werden, was das Risiko minimiert, da bei jeder Einzelbereitstellung nur ein begrenzter Teil der Funktionalität involviert ist. Darüber hinaus ermöglicht die lose Kopplung eine höhere Resilienz innerhalb des Systems. Da jeder Service unabhängig und (elastisch) skaliert werden kann, ist auch die Resilienz höher. Fällt ein Service aus, funktionieren die anderen weiter. So kann das System in manchen Fällen ein gewisses Maß an Funktionalität aufrechterhalten, während der problematische Service wiederhergestellt wird.
Ein weiteres Beispiel für ein lose gekoppeltes Muster eines Anwendungsdesigns ist eine ereignisgestützte Architektur. Bei diesem Ansatz löst eine Zustandsänderung die Erstellung eines Ereignisses durch einen Ereignisproduzenten (Event Producer) aus. Diese Ereignisse werden von einem oder mehreren Ereigniskonsumenten (Event Consumer) erkannt, die entsprechend auf die Ereignisse reagieren. Wenn beispielsweise auf einer E-Commerce-Plattform ein Artikel in den Einkaufswagen eines Kunden gelegt wird, könnte ein Ereignisproduzent ein Ereignis auslösen, das diese Aktion detailliert beschreibt. Zugleich könnte ein Ereigniskonsument sich bei diesem Produzenten anmelden und das Inventar aktualisieren, um die Änderung der Produktverfügbarkeit widerzuspiegeln. Ereignisgestützte Architekturen setzen oftmals Messaging ein und sind sehr lose gekoppelt, da die Ereignisproduzenten weder wissen, welche Konsumenten zuhören, noch was das Ergebnis der Konsumentenaktion sein könnte.
Wie bei Microservices werden Produzenten und Verbraucher unabhängig voneinander verwaltet, und durch diese Entkopplung können Entwicklungsorganisationen die oben beschriebenen Vorteile im Hinblick auf Resilienz, Skalierbarkeit und Wartung erzielen.
In Anbetracht der oben beschriebenen Vorteile scheint es schwer vorstellbar, dass die Verwendung dieser in höherem Maß resilienten und skalierbaren modernen Designmuster mit irgendwelchen Nachteilen verbunden ist. Aber gerade die entkoppelte Struktur, die so viele Vorteile bietet, führt auch zu zusätzlicher Komplexität, durch die die Fähigkeit eines DevOps-Teams zu effektivem Monitoring von Infrastruktur und Anwendungsstatus beeinträchtigt wird. Gleiches gilt für die ordnungsgemäße Bestimmung und Behebung von Problemen, die unweigerlich auftreten werden.
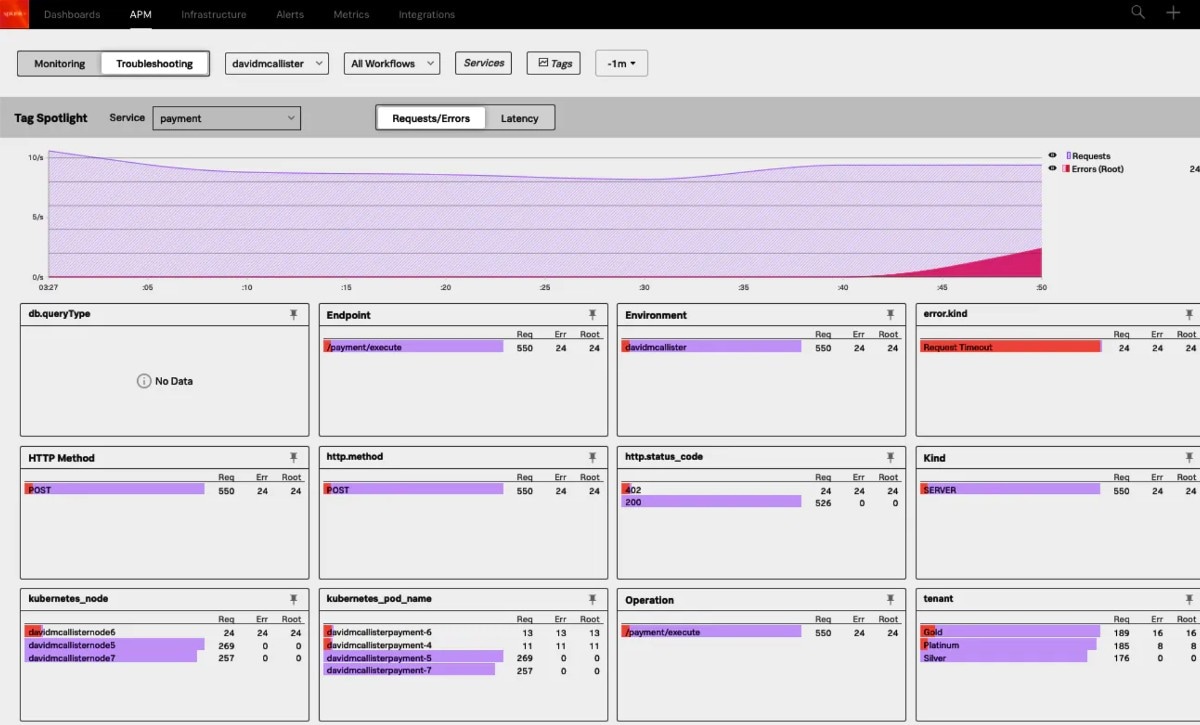
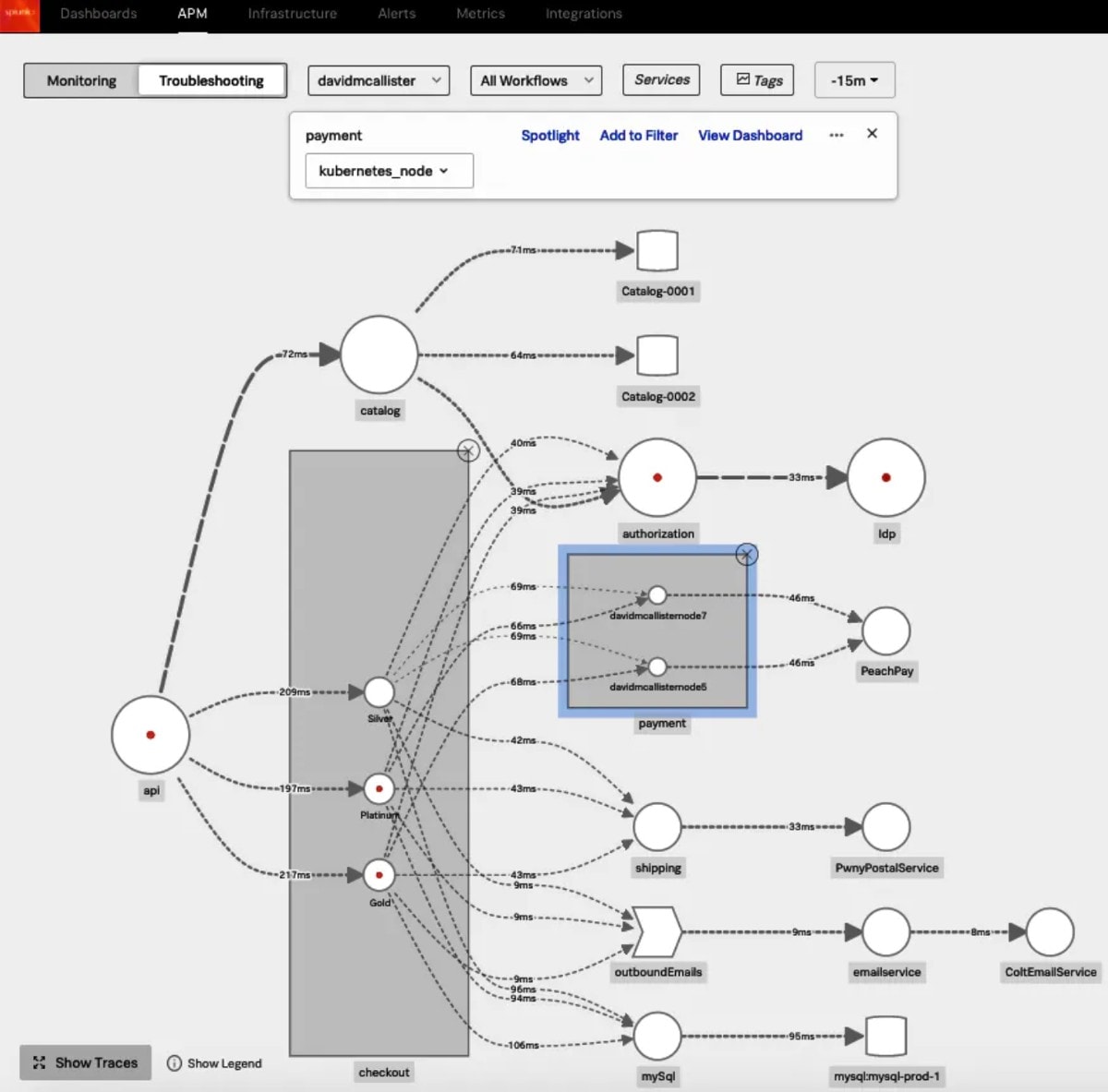
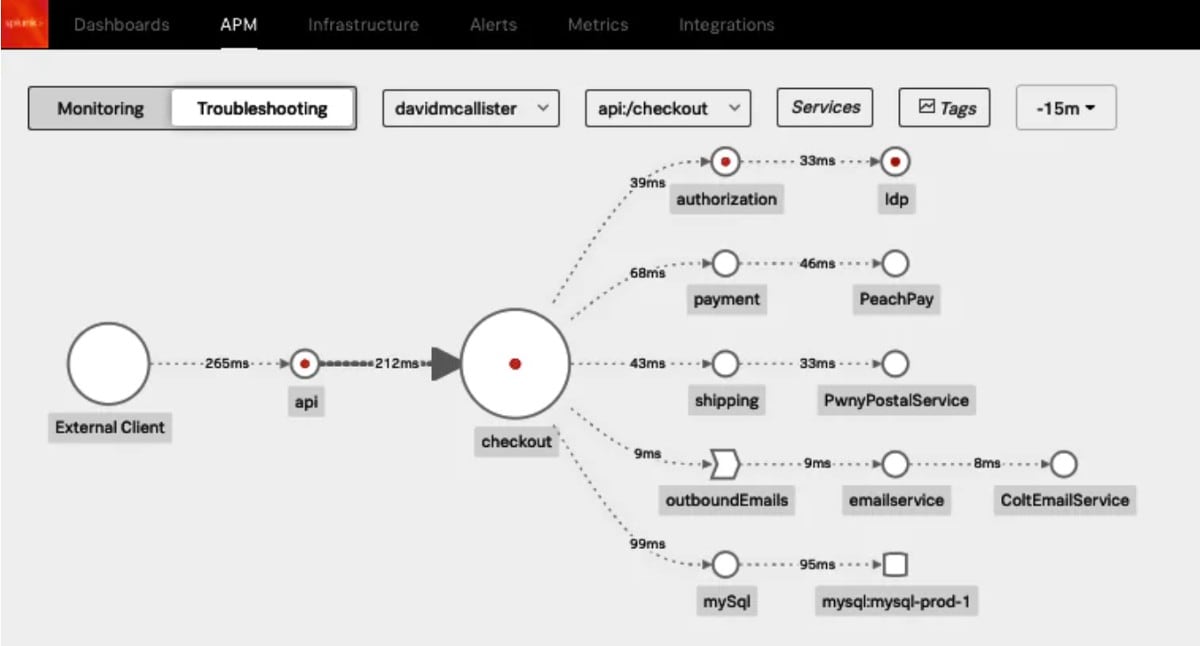
Betrachten wir dies einmal aus der Perspektive von Microservices. Eine einzelne Anfrage an ein auf Microservices basierendes System kann hundert oder mehr Services durchlaufen, die in einer verteilten Cloud-Infrastruktur ausgeführt werden und Informationen zur Anfrage an einer großen Menge von Speicherorten protokollieren. Das macht es nahezu unmöglich, Ereignisse zu korrelieren und problematische Anfragen effektiv zu verfolgen. Wo sollen Entwicklungs- und IT-Teams bei langsamer Ausführung oder Ausfall ansetzen, wenn sie versuchen, die Grundursachen zu ermitteln? Wie können sie unkompliziert den Zustand und die Leistung des Systems bewerten? Die Antwort auf beide Fragen ist, die Systeme so beobachtbar (Stichwort Observability) wie möglich zu machen.
Wenn Systeme in hohem Maße beobachtbar sind, können DevOps-Mitarbeiter den Zustand des Systems effizient beurteilen. Dies gibt ihnen die Möglichkeit, die Integrität zu überwachen, Probleme zu beheben und Anwendungen im Lauf der Zeit zu verbessern. Dies wird erreicht, indem die Transparenz für alle Komponenten des Systems maximiert wird.
Eine Möglichkeit, die Transparenz in einem modernen System zu steigern, ist ein zentrales Log-Management. Dazu gehört die Erfassung von Logdaten aus allen Services mithilfe einer modernen Log-Management-Plattform. Das Zusammenführen der Daten ermöglicht es DevOps-Teams, die Daten komfortabel zu analysieren, statt vergeblich zu versuchen, Erkenntnisse aus unterschiedlich strukturierten Logdaten abzuleiten, die über Dutzende oder sogar Hunderte von Quellen verteilt sind. Mithilfe von zentralem Log-Management erhalten DevOps-Teams einen ganzheitlichen Überblick über wichtige Systemdetails von einem einzelnen, zentralen Ort aus.
In diesem Sinne kann Distributed Tracing dabei helfen, einen besseren, ganzheitlicheren Überblick über den Weg eines Benutzers durch eine serviceorientierte Anwendung zu erhalten. Beim Distributed Tracing werden Trace-IDs genutzt, um DevOps-Teams die Möglichkeit zu geben, einzelne Anfragen bei ihrem Durchlaufen mehrerer Services zu isolieren. Diese Art der Eventkorrelation macht es wesentlich einfacher, die problematische Komponente im Falle einer Verlangsamung oder eines Ausfalls zu identifizieren.
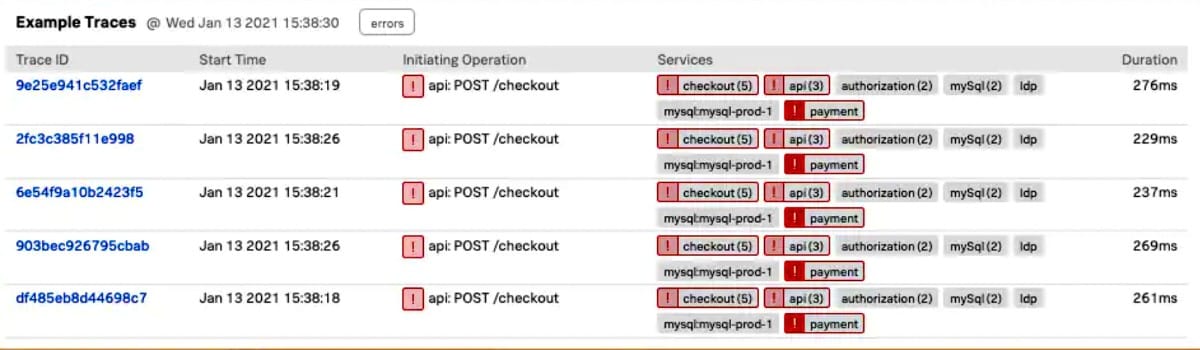
Im Kontext von Softwareanwendungen und Services wird ein System als „hochgradig beobachtbar“ (highly observable) bezeichnet, wenn keine weitere Instrumentierung und Telemetrie erforderlich ist, um den Zustand des Systems zu bestimmen. Mit anderen Worten, ein System ist beobachtbar, wenn sein Zustand leicht bestimmbar ist und die potenziellen Fehlerquellen (falls vorhanden) eingegrenzt werden können. Observability wird immer wichtiger, da Unternehmen zu Cloud-Umgebungen übergehen und die Systeme durch den Einsatz moderner Software-Architekturen immer komplexer werden.
Sehen wir uns einmal einige der modernen Architekturansätze für Anwendungen an, und finden heraus, warum Observabilty unverzichtbar ist, wenn die gesteckten Ziele für Softwareanwendungen in der Produktion erreicht werden sollen.
Viele Jahre lang verfolgten Softwareentwicklungsunternehmen meist einen monolithischen Ansatz beim Anwendungsdesign. Alle Schichten des Systems waren eng miteinander verzahnt, und die gesamte Funktionalität war in einer einzelnen Codebasis enthalten, die in nur einer Sprache geschrieben war. Bestenfalls gab es vielleicht ein Client-Server-Modell, das eine enge Kopplung zwischen zwei Codesätzen bot. Diese Anwendungen wurden in der Regel auf einer Reihe von Produktionsservern vor Ort bereitgestellt, sodass Entwickler und IT-Mitarbeiter große, zentralisierte Systeme zu betreuen hatten.
Heutige Anwendungsdesigns geben ein ganz anderes Bild ab. Microservice- und eventbasierte Architekturen verleihen Anwendungen höhere Resilienz und erleichtern die Skalierung, Modifizierung und die Bereitstellung.
Wie bereits erwähnt, ist Transparenz die Voraussetzung für Observability. Bei modernen Software-Architekturen kann das Erreichen von End-to-End-Transparenz jedoch eine echte Herausforderung darstellen.
DevOps-Teams können dieser Komplexität begegnen, indem sie moderne Plattformen einsetzen, die sich an diese lose gekoppelten Systemarchitekturen anpassen können. Observability-Plattformen (wie die von Splunk) enthalten die notwendigen Funktionen, um effektive Prozesse für Infrastruktur-Monitoring, APM und Log-Management in verteilten Softwaresystemen zu ermöglichen. Durch die Nutzung dieser Prozesse für aussagekräftige Einblicke in die Systemleistung lassen sich Incidents innerhalb dieser modernen Anwendungen mit größerer Effizienz identifizieren und beheben. Außerdem können Möglichkeiten zur Systemverbesserung richtig beurteilt und priorisiert werden.
Moderne Anwendungsarchitekturen erhöhen die Resilienz und Skalierbarkeit erheblich und vereinfachen zugleich die Prozesse zur Modifizierung und Bereitstellung von Systemen. Die erhöhte Komplexität dieser Architekturen hat jedoch zur Folge, dass das Erreichen von End-to-End-Observability für DevOps-Teams wichtiger denn je ist.
Möchtet ihr mehr über Observability erfahren? Seht euch Observability: Ein Leitfaden für Einsteiger an.
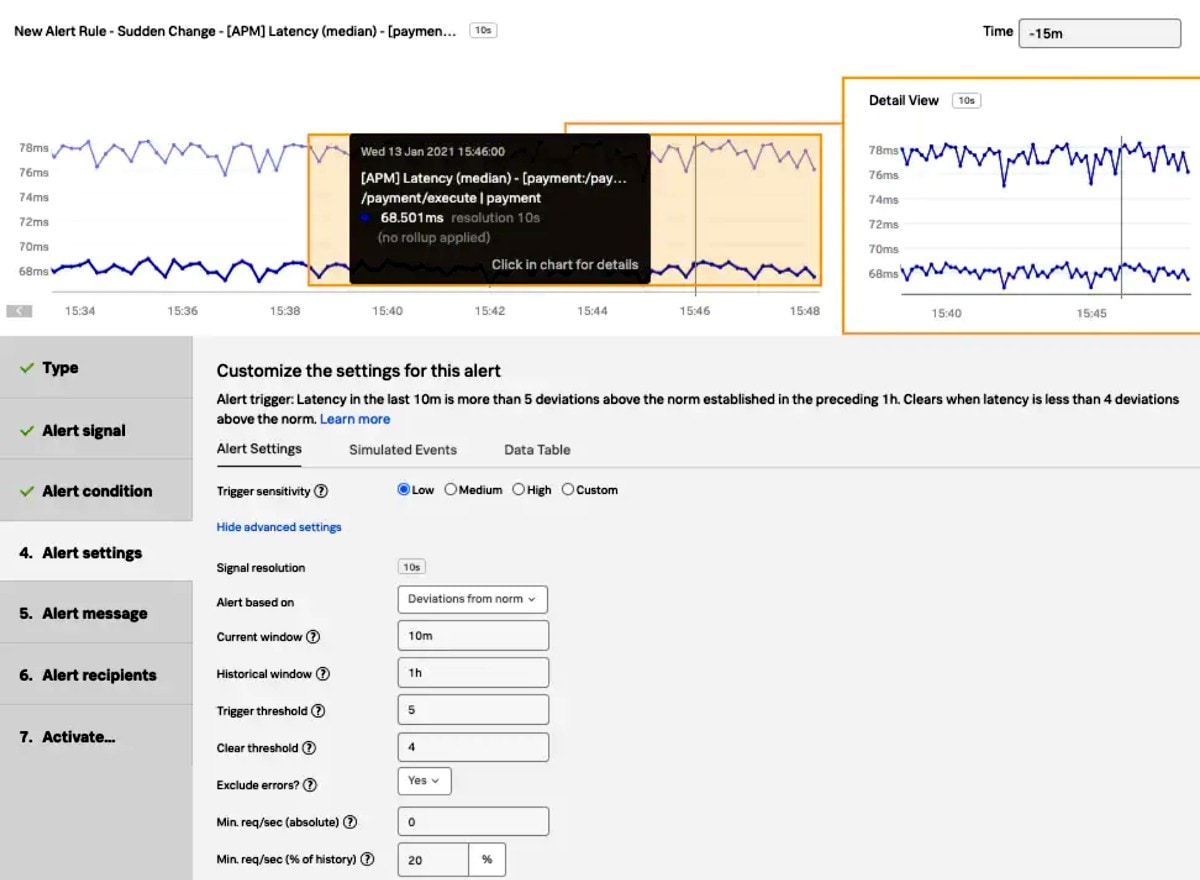
Darüber hinaus funktioniert das Monitoring von Infrastrukturen und Anwendungen (insbesondere solcher mit KI-gestützten Funktionen) durch die Erfassung und Kontextualisierung von Leistungsmetriken und Warndaten. Erfolgt dies übergreifend über alle Systemkomponenten, erhöht sich die Transparenz erheblich, und es werden wertvolle Einblicke in den allgemeinen Systemzustand erreicht. Außerdem ermöglichen es Echtzeit-Warnmeldungen und kontextualisierte Warndaten es den DevOps-Teams, Bedrohungen der Systemzuverlässigkeit zum frühestmöglichen Zeitpunkt zu erkennen (was die MTTD verringert) und rechtzeitig auf diese Incidents zu reagieren (was die MTTR reduziert).
Startet noch heute mit einer kostenlosen Testversion von Splunk Observability Cloud.
*Dieser Artikel wurde aus dem Englischen übersetzt und editiert. Den Originalblogpost findet ihr hier.
----------------------------------------------------
Thanks!
Splunk

Die führenden Unternehmen der Welt vertrauen auf Splunk, einem Unternehmen von Cisco, um ihre digitale Resilienz mit der einheitlichen Sicherheits- und Observability-Plattform, unterstützt durch branchenführende KI, kontinuierlich zu stärken.
Unsere Kunden setzen auf die preisgekrönten Sicherheits- und Observability-Lösungen von Splunk, um die Zuverlässigkeit ihrer komplexen digitalen Umgebungen zu sichern und zu optimieren – in jeder Größenordnung.

Die neuesten Artikel von Splunk, direkt im eigenen Posteingang.
© 2005 - 2026 Splunk LLC All rights reserved.
© 2005 - 2026 Splunk LLC All rights reserved.