
Wege zum Aufbau erfolgreicher Observability-Praktiken

Gute Nachrichten für technische Teams, die Splunk Observability Cloud nutzen: Wir haben mehrere neue Verbesserungen vorgenommen, die euch die Fehlersuche und -behebung erleichtern, transparentere Einblicke in eure Umgebungen bieten und für eine einheitlichere Incident Response sorgen. Wenn ihr als Techniker an vorderster Front arbeitet, wisst ihr, dass sich digitale Ressourcen nur warten und schützen lassen, wenn ihr sie beobachten könnt. Und genau hier setzen unsere Innovationen an: Sie bieten zusätzlichen Kontext zum Endnutzererlebnis, zum Cloudnetzwerk und zu jeder einzelnen Transaktion. Dadurch könnt ihr Problemursachen schnell eingrenzen, sobald ihr eine interne Service-Anfrage erhaltet, dank präziserer Warnmeldungen effizienter auf Probleme reagieren und bringt so über nur eine einzige Benutzeroberfläche Ordnung ins On-call-Chaos.
Außerdem haben wir unsere branchenführenden Logging- und Incident-Response-Funktionen nun auch auf Splunk Observability Cloud erweitert. Damit erhalten jetzt alle Teams den nötigen Kontext, den sie für das Troubleshooting ihrer gesamten Produktionsumgebung brauchen.
Die vielen verbesserten Funktionen geben euch tiefergehende Transparenz und mehr Kontext, sodass ihr Probleme – angefangen bei eurem Tech-Stack bis hin zur User Experience – schneller erkennt und behebt. Egal, ob ihr eine monolithische oder Microservices- Architektur betreibt, ihr erhaltet Kontext zu jedem technischen Problem im Cloud-Netzwerk oder in Kubernetes-Clustern, beispielsweise bei fehlerhaften User-Sessions oder Tags. Damit könnt ihr schnell Kernursachen auf den Grund gehen und entsprechende Folgen auf Kundenseite nachvollziehen.
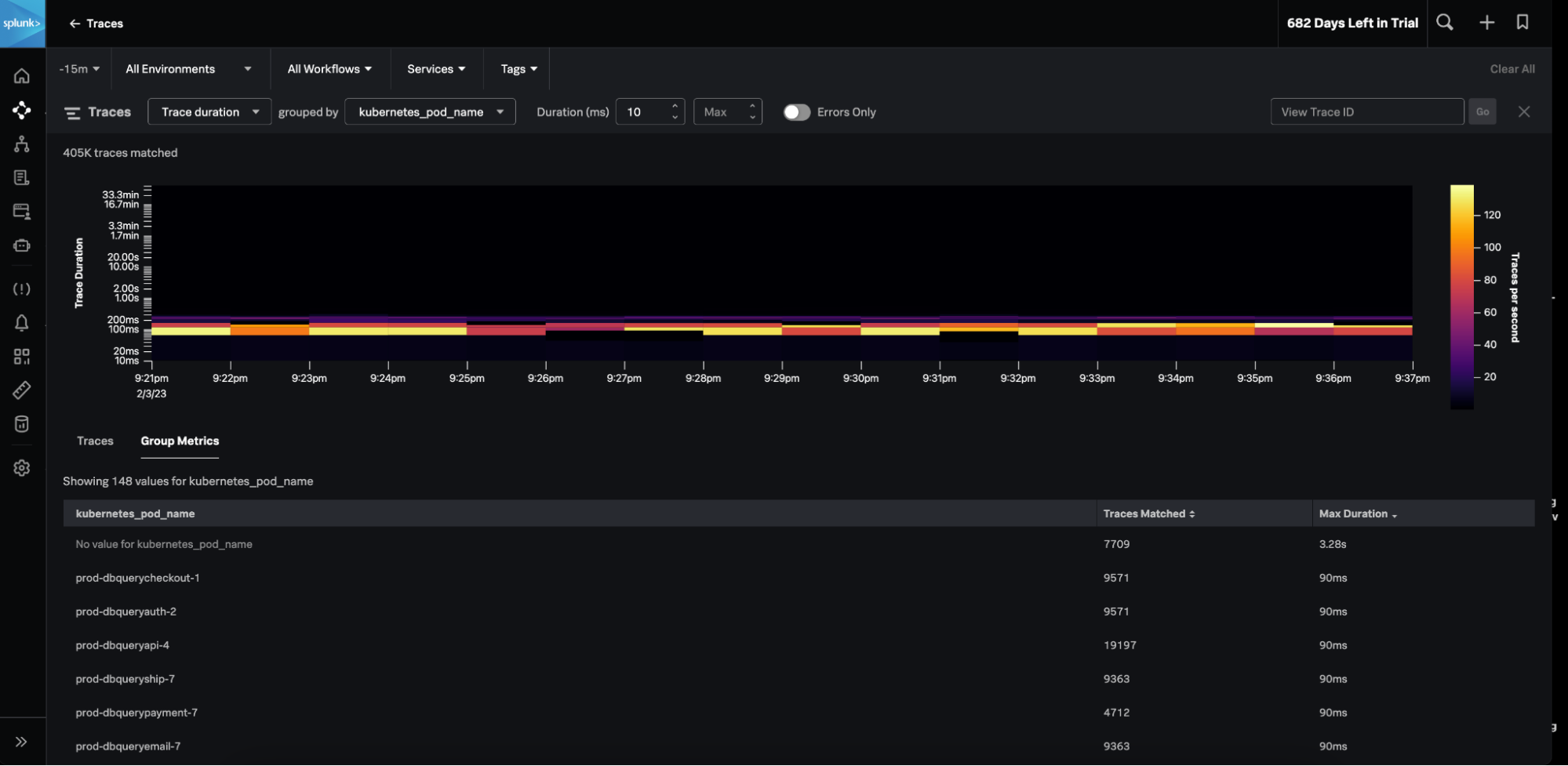
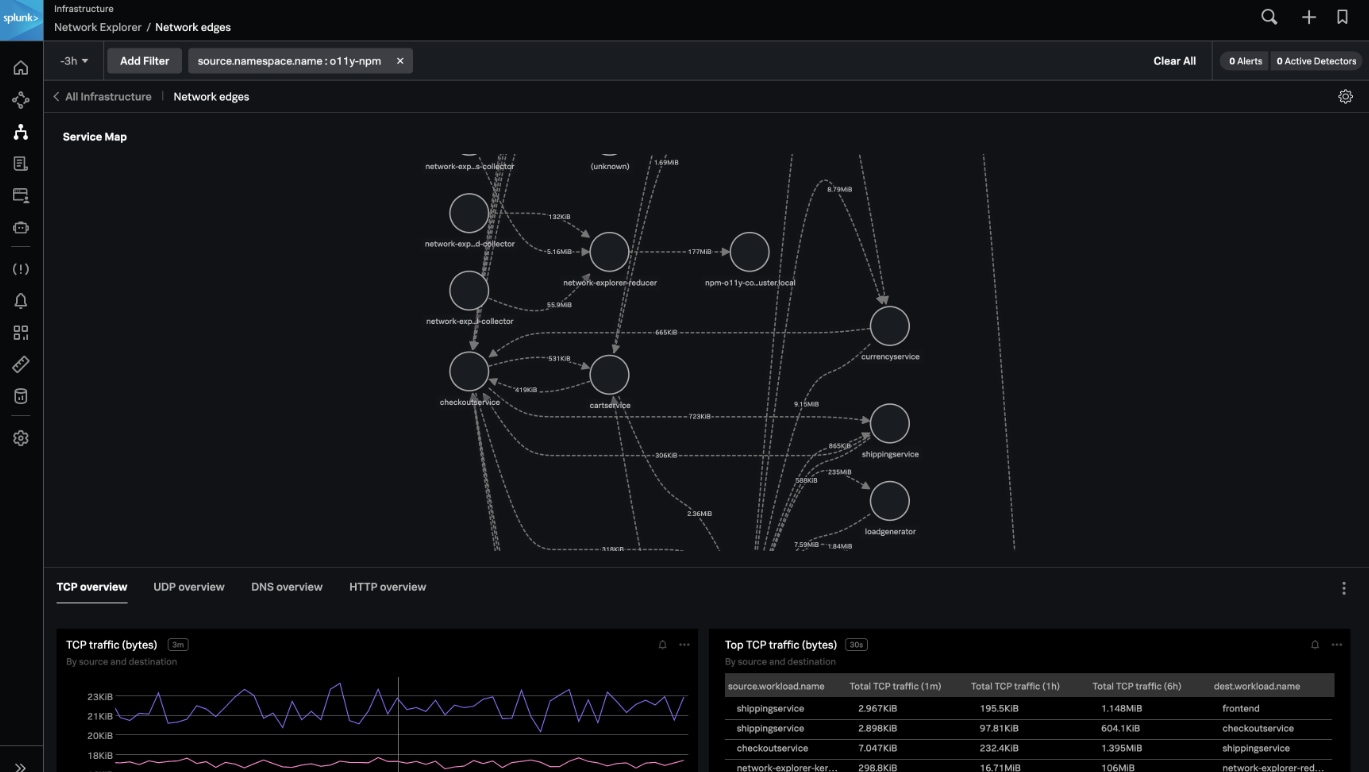
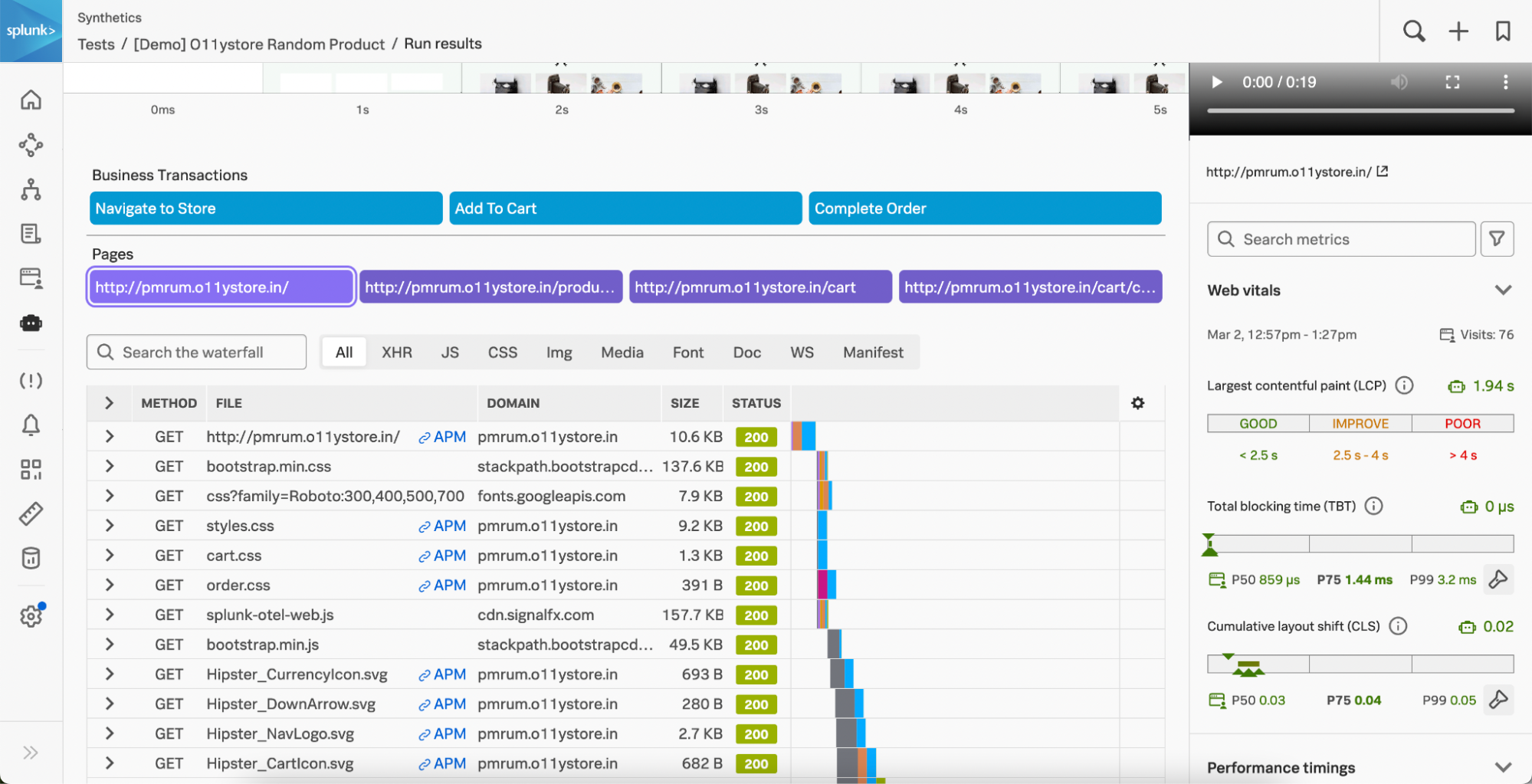
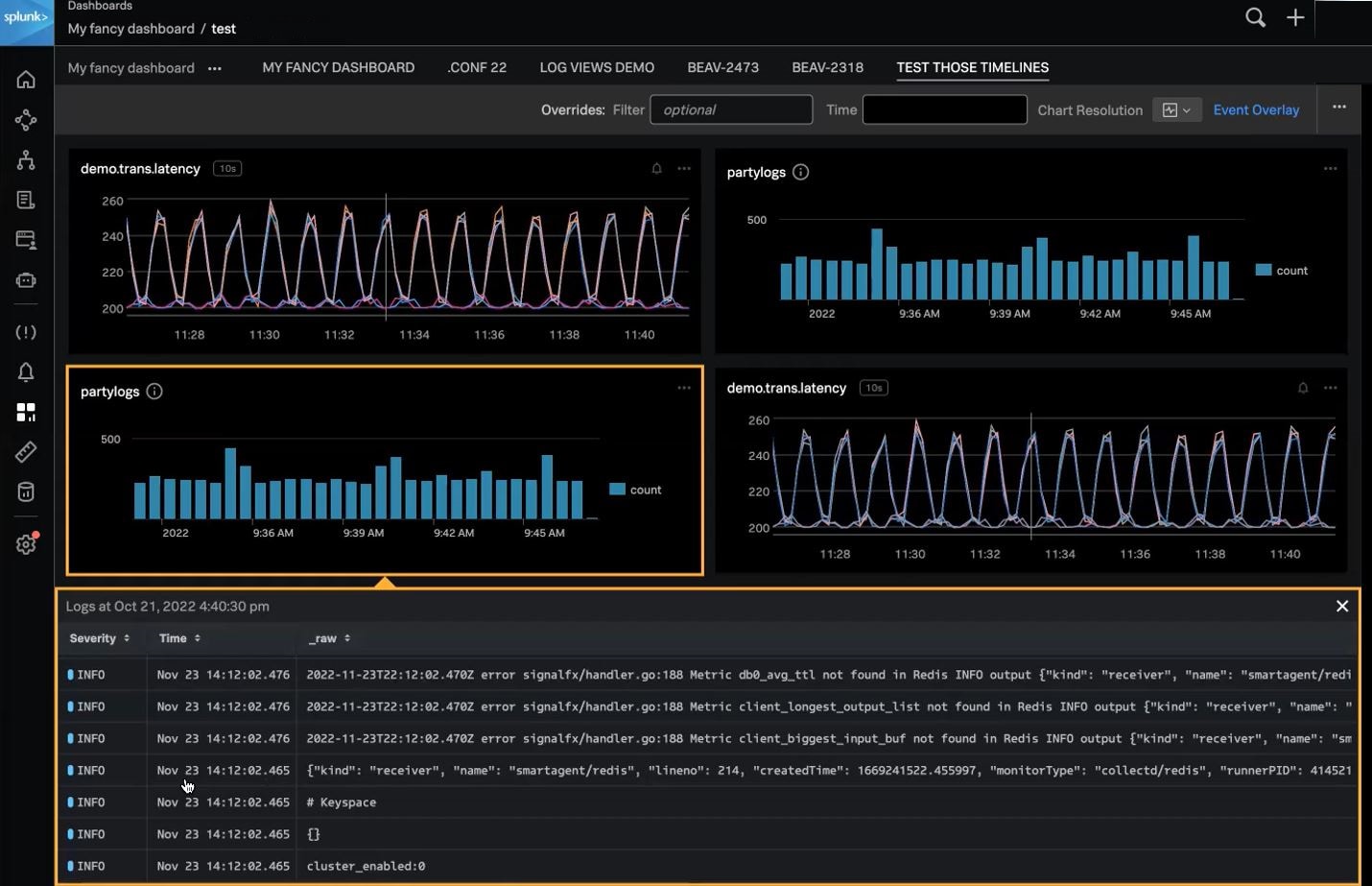
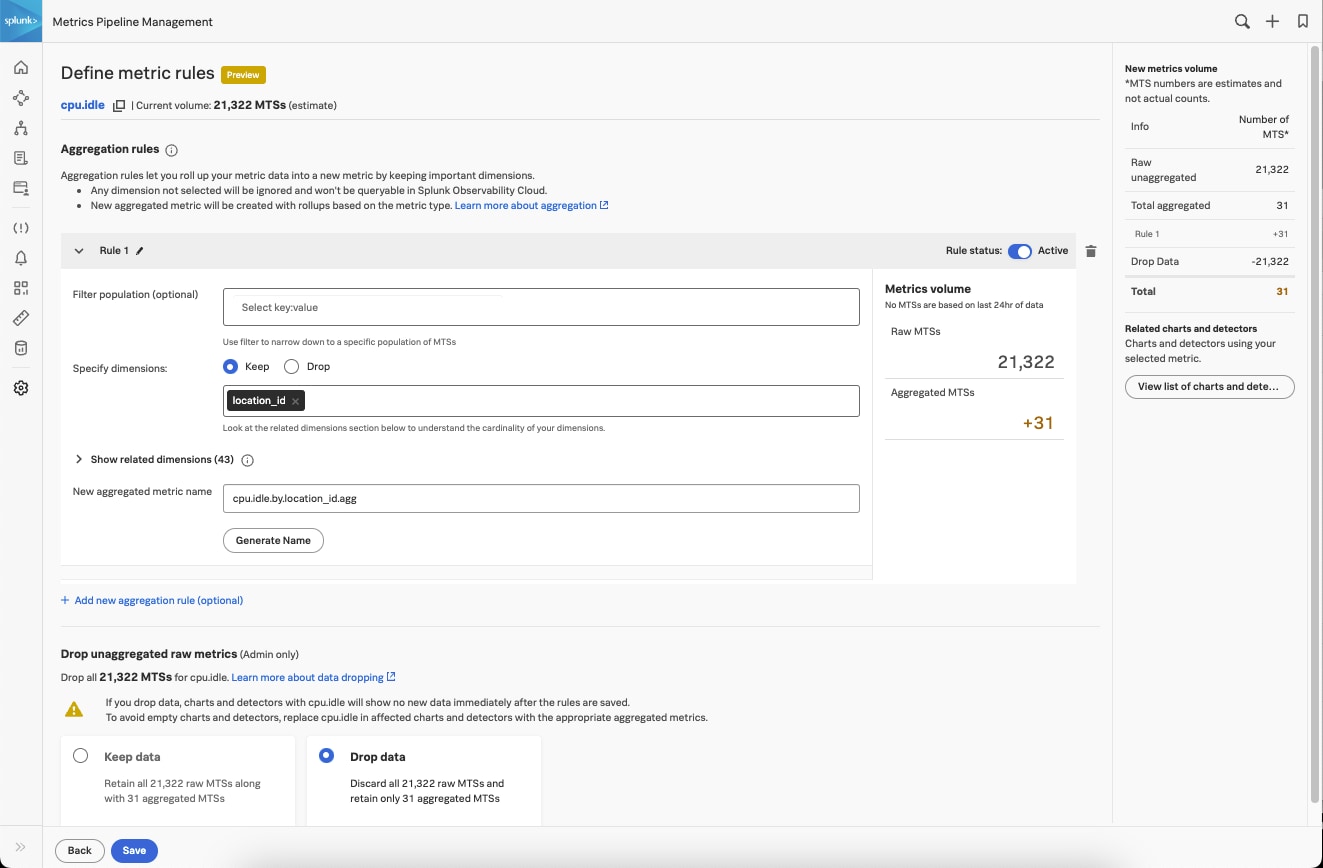
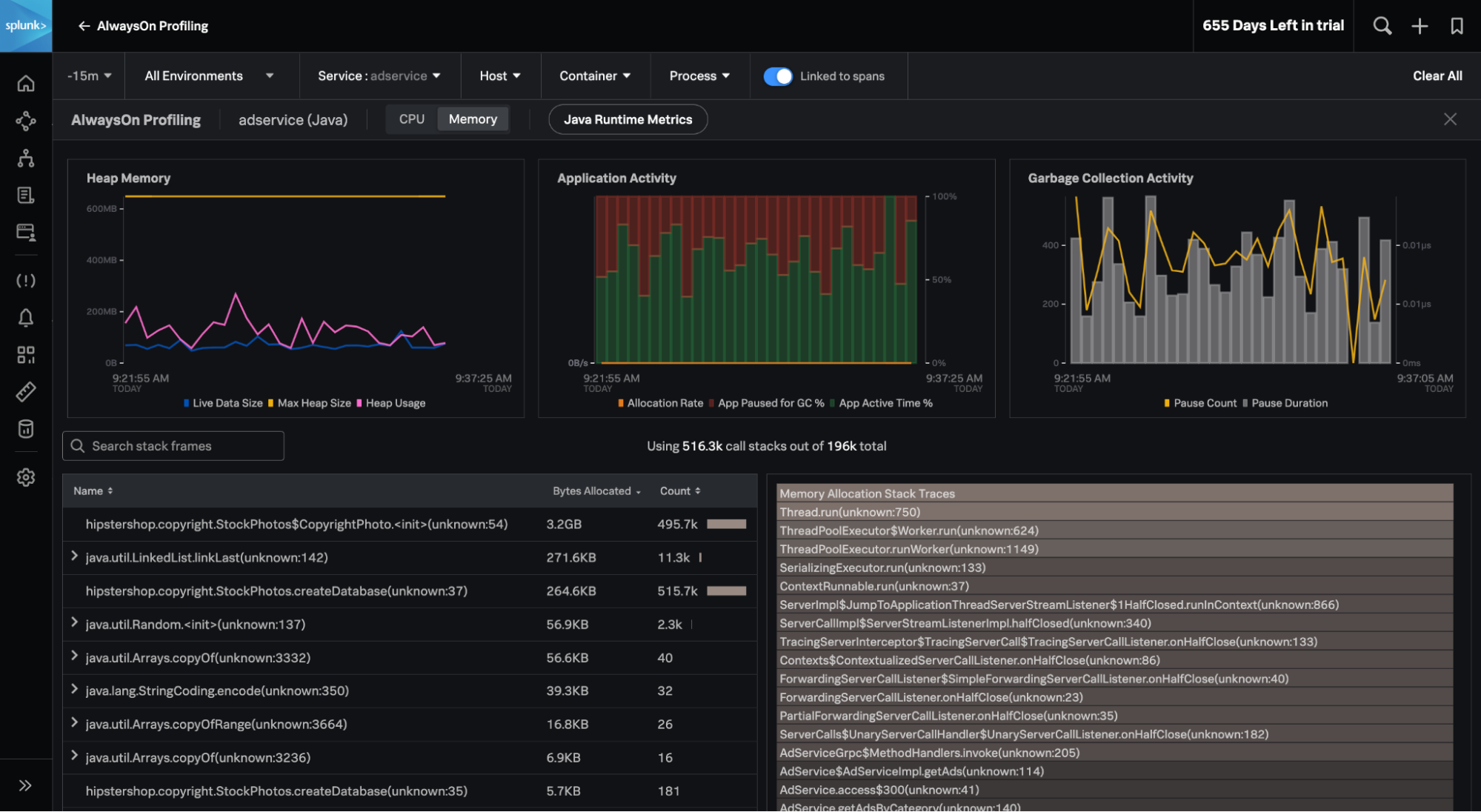
Mit Splunk-Incident-Intelligence- und AutoDetect-Funktionen habt ihr nun die Möglichkeit, die Effizienz eurer On-call-Teams deutlich zu steigern. Diese neuen Funktionen sorgen mit aussagekräftigeren Warnmeldungen und optimierten Abläufen für eine bessere Koordination und mehr Effizienz eurer Teams, was die MTTD, MTTA und MTTR verkürzt. Sprich: Gemessen ab dem Zeitpunkt der Warnmeldung ist das Problem schneller gelöst.
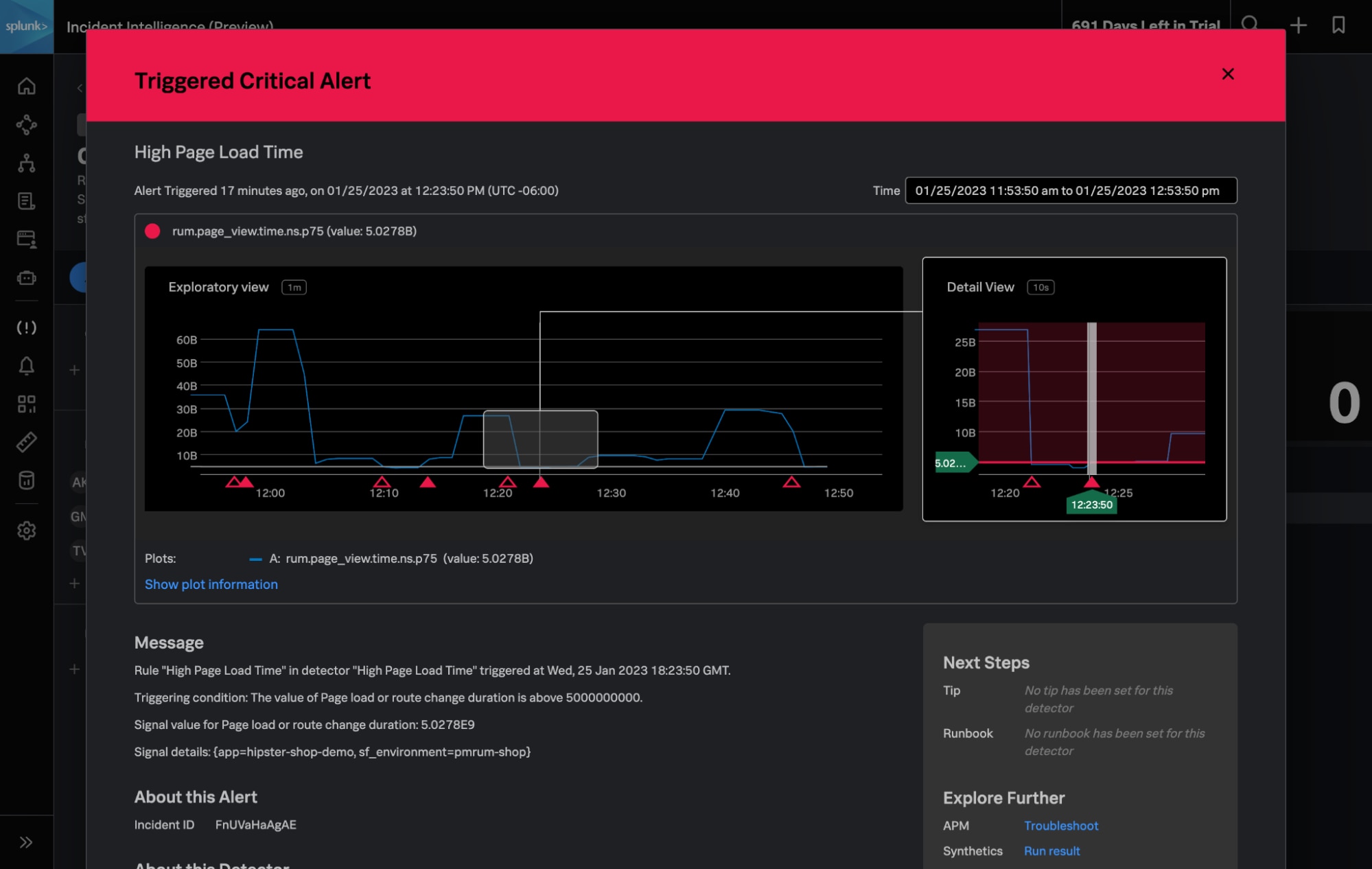
Splunk Application Performance Monitoring (APM) AutoDetect: Das auf Machine Learning (ML) basierende Feature APM AutoDetect verbessert die Genauigkeit erheblich und reduziert den manuellen Aufwand zur Einrichtung von Service-Warnmeldungen. Mit AutoDetect könnt ihr spielend leicht Performance-Vorgaben für einzelne Services festlegen sowie automatische Detektoren, Warnmeldungen und Benachrichtigungen für den Fall erstellen, dass sich Latenzzeiten oder Abfrageraten plötzlich ändern oder Fehler auftreten. In der Folge spart ihr euch das häufige Neukonfigurieren von Warnmeldungen und erhaltet immer hochpräzise Meldungen für alle cloud-nativen Umgebungen.
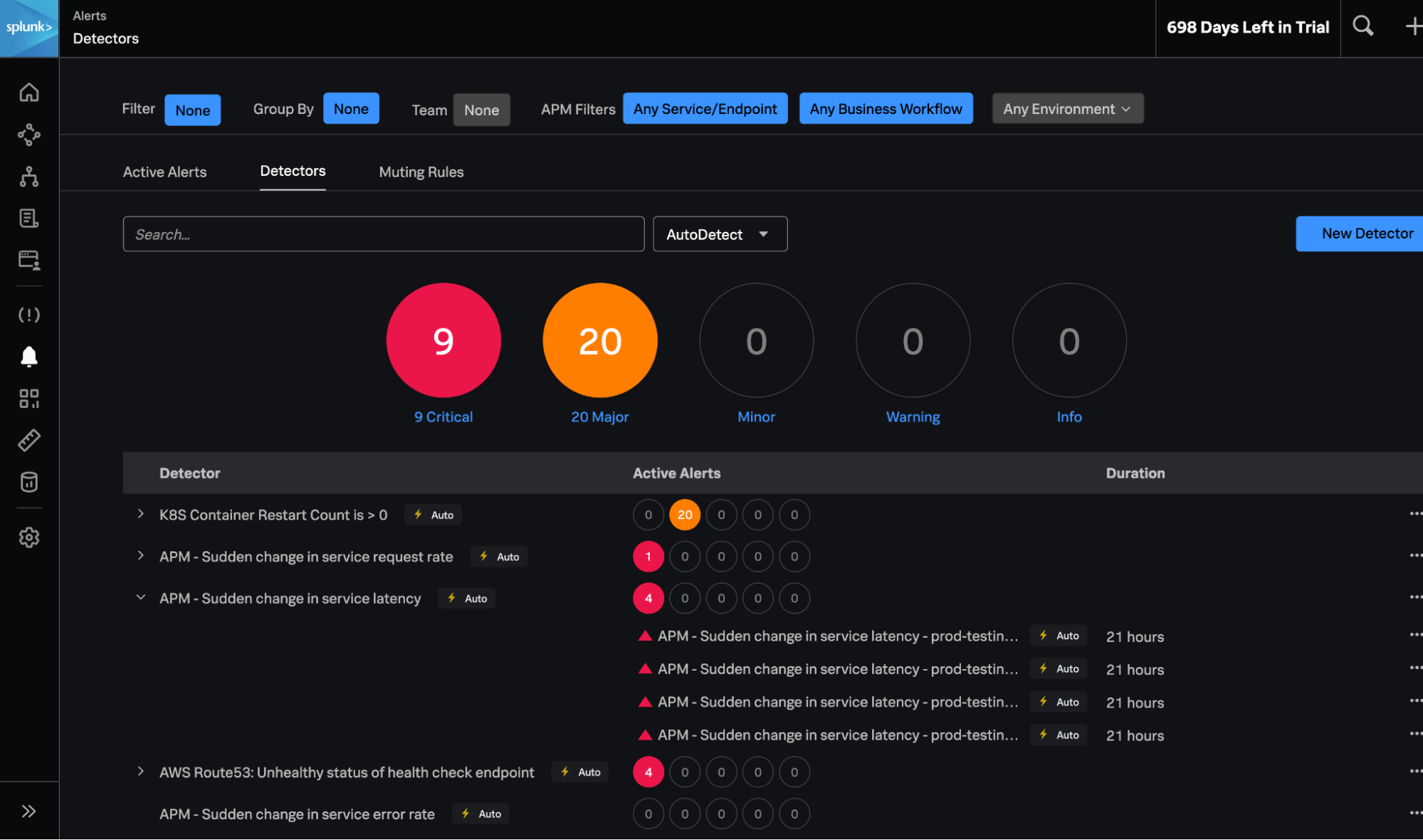
Möchtet ihr mehr über die neuen Features von Splunk Observability erfahren? Dann empfehlen wir euch unser Webinar Splunk Observability Innovations Showcase: Increased Visibility & A Unified Approach to Incident Response. Klickt einfach auf einen der verlinkten Termine, um euch für die Live-Session zu registrieren (Sessions zu EMEA-freundlicheren Zeiten sind in Arbeit!):
Ausfallzeiten und kritische Systemfehler können euer Geschäft erheblich beeinträchtigen. So fand das Uptime Institute in seiner Outage Analysis 2022 heraus, dass Unternehmen bei 60 % der Ausfälle Verluste in Höhe von mindestens 100.000 USD erlitten. Damit euch das nicht passiert und ihr eure digitale Resilienz ausbauen könnt, setzt Splunk mit seiner Plattform für einheitliche Sicherheit und Observability alles daran, die Performance und Zuverlässigkeit eurer Systeme zu gewährleisten.
Möchtet ihr euch gerne selbst von den neuen Features der Splunk Observability Cloud überzeugen? Dann habt ihr zwei Möglichkeiten, unser Tool zu testen:
Ladet euch jetzt eure kostenlose 14-tägige Testversion herunter!
*Dieser Artikel wurde aus dem Englischen übersetzt und editiert. Den Originalblogpost findet ihr hier.

Die führenden Unternehmen der Welt vertrauen auf Splunk, einem Unternehmen von Cisco, um ihre digitale Resilienz mit der einheitlichen Sicherheits- und Observability-Plattform, unterstützt durch branchenführende KI, kontinuierlich zu stärken.
Unsere Kunden setzen auf die preisgekrönten Sicherheits- und Observability-Lösungen von Splunk, um die Zuverlässigkeit ihrer komplexen digitalen Umgebungen zu sichern und zu optimieren – in jeder Größenordnung.

Die neuesten Artikel von Splunk, direkt im eigenen Posteingang.
© 2005 - 2026 Splunk LLC All rights reserved.
© 2005 - 2026 Splunk LLC All rights reserved.