
セキュリティの脅威トップ50
サイバー脅威は急速に進化しています。『セキュリティの脅威トップ50』の最新版では、最新の攻撃パス、脅威の実例、次に取るべき対策をご紹介しています。

今日、あらゆるサイバーセキュリティ侵害で初期アクセスに最もよく使われる技法は何だと思いますか?それは以前と変わらず、認証情報の悪用です。実際、Cisco Talosの2025年第1四半期IRトレンドレポートによると、すべてのインシデントの半数以上で正規の認証情報が悪用されていました。Verizon社の『2025年度データ漏洩/侵害調査報告書』でも、確認された全侵害の22%に認証情報の悪用が関わっていると報告されています。また、Mandiant社の『M-Trends 2025レポート』では、盗まれた認証情報が初期アクセス経路の16%を占め、フィッシングを上回ったことが示されています。さらにSplunkのMacro-ATT&CK分析では、2023~2024年にかけて正規の認証情報の悪用が17ポイント増加したことが明らかになりました。
では次に、世界でも特に危険なAPT (Advanced Persistent Threat)グループの一部が、地球上で最も厳重に保護されているいくつかのネットワーク内で、何カ月も、ときには何年もの間検出を逃れて、同じ認証情報を使い続けていることをご存じでしたか?これも本当の話です。そして、それこそが、私がこのプロジェクトを立ち上げるきっかけとなった問題です。
私は、正規の認証情報の悪用をできるだけ早い段階で検出できるツールを作りたいと思いました。そして、そのツールを「Post-Logon Behaviour Fingerprinting and Detection (ログオン後の行動のフィンガープリント生成と検出)」の頭文字を取って「PLoB」と名付け、「ユーザーのログオン直後という重要な時点のアクティビティを重点的に調べる」というシンプルなミッションを設定しました。
目標は、脅威をできるだけ早い段階で検出すること、つまり、攻撃者がネットワークへの侵入に成功して、あらゆる破壊行為を容易に実行できるようになる前に検出することです。
さらに私は、それを他の人が理解して、できれば改善できるような方法で実現したいと考えました。私は自分をこの分野のエキスパートだとは思っていません。ただ、古くからの問題を解決するための新しい方法を見つけることに情熱を持って取り組んでいます。それではPLoBについて詳しく見ていきましょう。
まずは、SplunkなどのSIEMソリューションから生のセキュリティログを取り込みます。これらのログには、イベントがフラットな記録として書き込まれています。当初は、正確でクリーンなデータを十分に収集するのに苦労しましたが、あるすばらしいお客様(本当にありがとうございます)と、私の同僚であるJames Hodgkinsonが開発した優れたデータサニタイザーのおかげで、問題を解決できました。Splunkのレポート『データ管理の新たなルール』によると、データの準備(ラングリング)は業界内でも広く課題になっているようです。
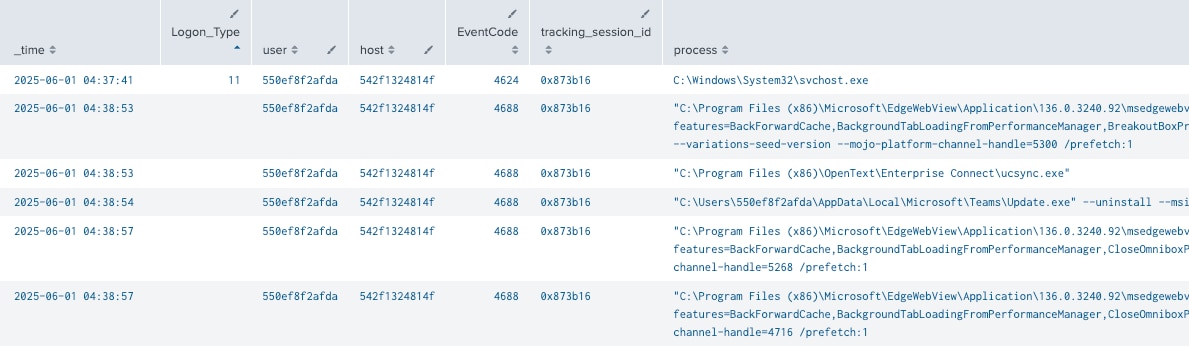
Splunkのサーチ結果
PLoBは、Neo4jを使って、このデータをユーザー、ホスト、セッション、プロセス間の関係を可視化するリッチなグラフモデルに変換します。これにより、ばらばらのログ行を苦労してつなぎ合わせなくても、複雑な関係を簡単にたどることができます。
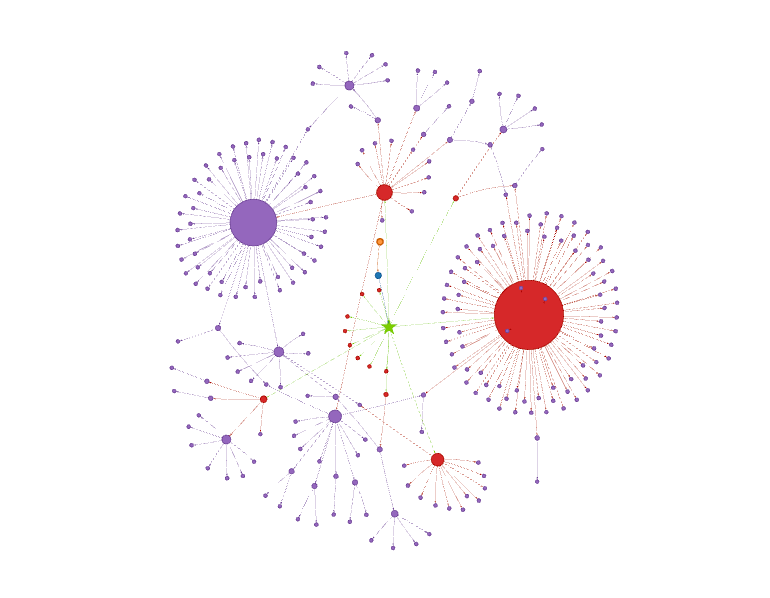
Neo4jによるセッションのグラフ
次に、各ログオン後のセッションから、詳細な行動フィンガープリントを生成して、脅威の重要なシグナル(新しいツールの使用、高速なコマンド実行、複雑なプロセスツリーなど)を要約します。このフィンガープリントは、特に重要な行動を一目で把握できるように設計された簡潔なテキストサマリーです。

フィンガープリントの例
その後、フィンガープリントのテキストを強力なAI埋め込みモデル(OpenAIのtext-embedding-3-large)に入力して、3072次元ベクトルに変換します。これにより、行動の微妙な違いを数値表現で捉えることができます。

text-embedding-3-largeによる埋め込み
これらのベクトルをMilvusに保存してインデックスします。Milvusは、大規模な類似性検索を効率的に実行できる高性能なベクトルデータベースです。
一致や異常の検出にはコサイン類似度を使用します。コサイン類似度は、ベクトル間の距離ではなく角度を測定するメトリクスです。これにより、単なる量や大きさではなく、行動パターン(ベクトルの方向)に重点を置くことができます。
類似度スコアの範囲は0~1で、1はセッションでの行動が完全に同じであること、0は完全に無関係であることを示します。このスコアリングにより、PLoBでは、新しい外れ値と不審な繰り返しのクラスターの両方を正確に特定できます。
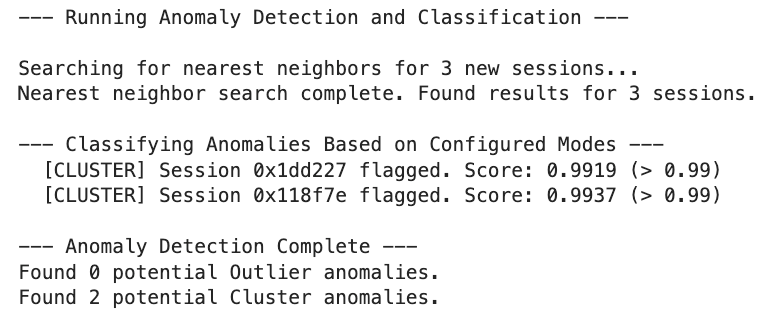
アノマリ検出の例
異常なセッションを検出したら、グラフデータベースから取り出し、AIエージェントに送信して、詳細分析を行います。下の図に、Splunk独自のFoundation AI Securityモデルからの回答例を示します。このモデルでは、セッションの詳細なコンテキストとリスク評価も返されるため、アナリストが情報に基づいて意思決定を行うために役立ちます。

Foundation AIでの分析結果の例
Splunkからのログの取り込みから、Neo4jでのグラフモデリング、AIによるフィンガープリントの埋め込み、Milvusでの類似性検索、AI分析までのスタックが連携することで、ログイン直後という重要な時点に潜む脅威の微細なサインを捉えることができます。
そうですね。おそらく、皆様のセキュリティスタックには検出機能が満載でしょう。ルールベースのアラート、高度な行動ベース分析、さらには新しいAI搭載ツールもいくつかあるかもしれません。
しかし残念ながら、これらの機能をもってしてもすべての脅威を捕えきれず、多くの取りこぼしが生じているのが現実です。多層防御のアプローチを取り入れるのは正しいことですが、新しいツールを追加するたびにコストと複雑さが増し、ツール独自の盲点が生まれます。
そこでPLoBの出番です。PLoBは、既存のツールを置き換えるものではなく、既存のツールで生じがちな非常に限定的な隙間を埋めることを目的としています。
PLoBの目標は、ログオン後の初期アクティビティの異変に特に重点を置いた、高速で軽量な層を導入することで、攻撃者が足場を固める前に脅威を検出するチャンスを増やすことです。
この言葉を聞いたことがある方もいらっしゃるかもしれません。私の意見では、これはセキュリティ業界における大嘘の1つです。
問題は、防御者がリストで考えることではなく、これまで使ってきたツールによって、リストで考えることを余儀なくされてきた点です。
たとえばSIEMについて考えてみましょう。ユーザーを調査したときに何が得られるでしょうか?タイムスタンプ順に並べられた、長くて単調なイベントリストです。ログオンイベント(4624)の後にプロセス実行(4688)があり、さらに別のイベントが続きます。そこから、どのプロセスがどのホストのどのログオンセッションに対応するかを紐付けるのはアナリストの仕事です。つまり、アナリストが頭の中でグラフを描くことになります。これには時間も労力もかかります。
これこそまさに、PLoBで最初からNeo4jのようなグラフデータベースを使う理由です。PLoBは、単調なリストを返す代わりに、現状をモデル化して表示します。どのユーザーノードがどのホストに接続し、そのホストではどのようなログオンセッションが実行されているかを追跡して、そこからプロセスノードのツリーを生成します。セッションをグラフ化するメリットには、ほかにもプロアクティブな脅威ハンティングの支援や可視性の向上などがあります。
エンティティ同士の関係は、データ構造から明確にわかるものであり、推測する必要はありません。グラフ化すれば、リストをただ延々とスクロールする代わりに、物語を追うように探索できるようになります。1つのプロセスから多方面に視点を広げることも、攻撃チェーン全体を可視化して追跡することもできます。これにより、分析を迅速化するだけでなく、データからより有意義で複雑な疑問を引き出すことで、攻撃者の目線で状況を捉えることが可能になります。
このプロジェクトの核となるのは「フィンガープリント」、つまり、AIモデルに入力するユーザーセッションのテキストサマリーです。目的は、各フィンガープリントをベクトル埋め込みに変換し、ベクトルデータベースを使ってセッション間の類似性を正確に測定することです。とてもシンプルですよね?
このフィンガープリントを生成するために最初に試したのは、セッションの生のアクティビティを簡潔に要約することです。
"User: admin on Host: DC01. Session stats: procs=15... Timing: mean=5.2s... Processes: svchost.exe, cmd.exe... Commands: cmd.exe /c whoami..."
このアプローチには、重大かつ屈辱的な欠陥がありました。
Living off the Land攻撃では、schtasks.exeやcertutil.exeなどの正規のツールを悪用する手法がよく使われます。それを模して作った攻撃でテストを行ったところ、異常をまったく検出できませんでした。さらに悪いことに、この悪質なセッションは、ベースラインデータに基づいて無害と判断された実際の管理セッションとの比較で、非常に高い類似度スコア(約0.97)を示しました。
システム自体は間違っていませんでした。むしろ、正しすぎたのです。PLoBは、悪質なセッションと正常なセッションの両方で同じ管理ツール(cmd.exe、svchost.exeなど)が多く使われていることを正確に特定しました。フィンガープリントは、こうした「ノイズ」に溢れています。そして、1~2行の悪質なコマンドが示す重要な「シグナル」は、長くて平凡なサマリーの末尾に埋もれています。その結果、全体的なパターンの類似点が先に認識され、2つのセッションが根本的に同じだと結論付けられたのです。
たとえて言うならば、スキー用のフェイスマスクをかぶった人物に注意するようにシステムに指示していましたが、攻撃者は正規の社員IDバッジも付けており、システムはバッジを見て判断してしまったということです。
この結果から、AIに対して、何が起きたかを説明するだけでなく、何が重要かを伝える必要もあることがわかりました。そこで、フィンガープリントのロジックを見直して、アナリスト向けのサマリーとして機能するようにしました。具体的には、「Key Signals (重要シグナル)」セクションを追加し、テキストの先頭に配置するように修正しました。
新しいロジックでは、次の3つの柱に基づいて、セッション内で特に不審な特徴を最初に示します。
同じ悪質なセッションの新しいフィンガープリントは、以前とはまったく違うものになりました。
"Key Signals: Novel commands for this user: certutil.exe -urlcache... | Extremely rapid execution (mean delta: 0.08s). Session Summary: User: admin on Host: DC01..."
有効なフィンガープリントができたので、次に、それをサーチ可能にします。コンピューターで実際に「類似性」を判断するにはどうすればよいでしょうか?それは、不審な行動をgrepするといった単純な作業ではありません。
そこで登場するのが、ベクトル埋め込みの魔法です。その目的は、非構造化テキストによるフィンガープリントを、コンピューターにとって比較しやすい、構造化された数学的オブジェクト(ベクトル)に変換することです。
イメージとしてはこうです。まず、埋め込みモデルがフィンガープリントを読み取り、それを高次元の巨大なライブラリ内に1つの点として配置します。各セッションは棚の上の固有の位置に置かれ、その位置はセッションの行動の意味によってのみ決まります。行動パターンが類似するセッションは近くに置かれ、大きく異なるセッションは部屋の反対側に置かれます。
これにより、複雑なサーチ問題が単純な幾何学の問題に変わります。それを実現する埋め込みスタックは以下のとおりです。
類似度スコアの範囲は0~1で、1はセッションでの行動パターンが完全に同じであること、0は完全に異なることを示します。この尺度により、新しいセッションが過去の行動とどの程度一致しているかを定量化できます。
このエンジンの導入により、新しいセッションのフィンガープリントをそれぞれベクトルデータベース内のサーチ可能な点に変換できるようになったことで、いよいよ異常を検出する準備が整いました。
フィンガープリントの変更は劇的な効果をもたらしました。最も重要なシグナルを先頭に置くことで、ベクトル埋め込みを生成する際にAIモデルがこれらの特徴に重点を置くようになりました。これで、悪質なセッションは無害なセッションと「瓜二つ」と判断されることはなくなりました。
アノマリ検出を再度実行したところ、最も類似しているセッションは、テスト用に作成した別の悪質な模擬セッションになり、類似度スコアは0.9151でした。これは、しきい値の0.92を十分に下回っているため、異常として正しくフラグが立てられます。このしきい値は、私たちがデータセットで試行錯誤を繰り返して設定したもので、最適なしきい値は環境によって異なります。
類似度0.92 (92%)というしきい値は、一見すると非常に厳しいように思えるかもしれません。より多くの異常を検出するには基準をもう少し下げた方がよさそうな気もするでしょう。
重要なのは、類似性がここで何を意味するかです。類似性スコアが1に近いということは、セッションの行動パターンがほぼ同一であることを意味します。0.92をわずかに下回るスコアは、セッションが表面的には似ていても、有意な差があることを示します。
実際、しきい値を0.92に設定すると、感度と特異度のバランスを取ることができます。
今回の実験では、しきい値を0.92に設定すると、攻撃者が正規の管理者の行動を真似した場合でも、日常業務のアクティビティと、これまで確認されたことのない悪質なセッションとを正確に区別できることがわかりました。
このしきい値の高さは、非常によく似た正規の行動のバリエーションがたくさんある中で微妙に異なる悪質な行動を区別することがいかに難しいか、また、重要なシグナルを増幅するようにフィンガープリントを設計することがいかに大切であるかを物語っています。ただし、他のしきい値と同様に、このしきい値も通常、組織の要件に合わせて調整したり、時間とともに生じるデータドリフトに応じて調整したりする必要があります。
最大の教訓は、AIモデル自体ではなく、AIモデルへの情報の伝え方にありました。単に行動を説明するのではなく不審な点を強調するようにフィンガープリントを設計することで、AIを受動的なサマライザーから能動的な脅威ハンターへと進化させることができました。
ここからが検出戦略の核心です。新しいセッションごとにMilvusにクエリーを発行して、「過去のベースライン全体の中からこのセッションに最も類似するセッションを1つ見つけてください」という簡単な指示を出します。これにより、最近傍のコサイン類似度スコアという1つの強力な数値が得られます。
このスコアに基づいて、異なる2種類の脅威を探し出すための、真逆とも言える2つのルールを適用します。
ロジック:if similarity_score < OUTLIER_THRESHOLD (< 0.92など)
目的:非常に独特なセッションを探します。新しいセッションの行動が、これまでに確認されたどのセッションとも類似度92%未満の場合、真の外れ値と言えます。これは、新しい管理ツールが導入されたか、開発者が何らかの実験を行っているか、新しい攻撃パターンが使われている可能性を示します。このルールでは、他との顕著な違いに基づいてアラートを生成します。
ロジック:if similarity_score > CLUSTER_THRESHOLD (> 0.99など)
不自然に繰り返される行動を探します。人間の行動は基本的に雑であり、複雑な作業をまったく同じ方法で行うことは二度とありません。類似度スコアが極めて高い場合は、ボット、スクリプト、マルウェアが複数のターゲットに同じ処理をロボットのような精度で自動実行している可能性を示す重大な危険信号です。このルールでは、他との違いがなさすぎることに基づいてアラートを生成します。
この2つのチェックを実行することで、単に「異常」を探すのではなく、新しい脅威と自動化された攻撃の両方の兆候に絞って異常を探し出すことができます。
この時点で、ルールを適用して、注意すべきアラートを「外れ値」または「クラスター」のいずれかに分類できるようになりました。
しかし、アラートがもたらすのは答えではなく、疑問です。セキュリティアナリストが本当に知りたいのは、session_id_123の類似度スコアが0.45であることではなく、それが何を意味するのか、それは悪い兆候なのか、それに対してどう対処すべきか、ということです。
ここで、AIアナリストの登場です。これは、初期の詳細調査を実行するための、Cisco Foundation SecモデルとOpenAI GPT-4oエージェントをベースにしたAIエージェントです。
まず思いつく方法は、生のセッションデータをAIに投入して「これは悪質なものですか?」と尋ねることでしょう。しかし、人間のアナリストのやり方を考えてみると、彼らはすべてのアラートを同じように扱うわけではありません。アラートが発生した理由に基づいて調査を行います。
外れ値の場合は、「このセッションはなぜ他のセッションと大きく異なるのか?」を考えます。開発者が新しいツールをテストしているのかもしれませんし、管理者がめったに実行しない正常な作業を実行しているのかもしれません。または、これまで確認されたことのない新しい攻撃パターンを示しているのかもしれません。
クラスターの場合は、「このセッションはなぜ不自然に繰り返されているのか?」を考えます。無害なバックアップスクリプトが実行されているか、CI/CDパイプラインでコードが自動デプロイされているのでしょうか?または、ボットが窃取した認証情報のリストを使って悪質な処理を実行しているのでしょうか?
こうしたコンテキストを与えなければ、AIにとって大きな制約となり、十分な能力を発揮できません。
この問題を解決するため、AIエージェントに、異常のタイプに応じた指示を与える仕組みを作りました。グラフデータベースから取得したセッションデータを送信する前に、プロンプトの先頭に以下のコンテキストブロックを追加します。
外れ値の場合は、次の指示を追加します。
"CONTEXT FOR THIS ANALYSIS: You are analyzing an OUTLIER. Your primary goal is to determine WHY this session is so unique. Focus on novel executables, unusual command arguments, or sequences of actions that have not been seen before." (この分析のコンテキスト:外れ値を分析しています。主な目的は、このセッションはなぜ他のセッションと大きく異なるのかを明らかにすることです。これまで確認されたことのない実行可能ファイル、通常とは異なるコマンド引数、初めて実行される一連のアクションに注目してください。)
クラスターの場合は、次の指示を追加します。
"CONTEXT FOR THIS ANALYSIS: You are analyzing a session from a CLUSTER of near-identical sessions. Your primary goal is to determine if this session is part of a BOT, SCRIPT, or other automated attack. Focus on the lack of variation, the precision of commands, and the timing between events." (この分析のコンテキスト:ほぼ同一のセッションのクラスターに含まれるセッションの1つを分析しています。主な目的は、このセッションが、ボットやスクリプトなど、自動化された攻撃の一部であるかどうかを判断することです。変化の少なさ、コマンドの正確さ、イベント間の間隔に注目してください。)
事前にコンテキストを提供することで、AIに単にデータを分析するように求めるのではなく、どのような脅威を探すべきかを正確に伝えて、AIが焦点を絞れるようにします。
AIは分析後、リスクスコア、調査結果のサマリー、推論の詳細を、構造化されたJSONオブジェクトとして返します。この詳細なレポートは、パズルの最後のピースであり、人間のアナリストがレビューして最終判断を下すための質の高い情報を提供します。このステップは、異常の程度を示す単純なスコアを実用的なインテリジェンスに変える点で非常に重要です。
この旅のきっかけとなったのは、悪者が普通のユーザーを装う手口がますます巧妙化しているという、単純でありながら厄介な問題を何とかしたいと思ったことです。攻撃者は、正規の認証情報と正規のツールを使ってありふれた場所に潜むようになりました。これは、検出する側にとってはまさに悪夢です。PLoBは、その問題に対する私なりの答えであり、ログオン直後という重要な時点でこれらの脅威を捕捉するための、目的を絞った軽量なシステムを構築するという試みの成果です。
このブログでは、パイプライン全体を説明してきました。その歩みをまとめると以下のとおりです。
まず、Splunk内のフラットなイベントをNeo4jのリッチなグラフに変換して、生データから、相互につながるストーリーを引き出しました。
しかし、苦労の末に、アクティビティを単に要約するだけでは不十分であることを学びました。新規性、速さ、構造に基づくわずかなシグナルを増幅する、より有効なフィンガープリントを設計する必要がありました。
次に、強力な埋め込みモデルとMilvusベクトルデータベースを使って、それらのフィンガープリントをサーチ可能な行動ライブラリに変換しました。
その後、類似度スコアを使って、特異な外れ値と不自然な繰り返しのクラスターを見つける、2重のアノマリ検出戦略を実行しました。
最後に、これらの高品質なアラートを、複数のコンテキスト認識型のAIアナリストにエスカレーションしました。AIアナリストは、初期の詳細調査を行って、人間が最終判断を下すために役立つ詳細レポートを返します。
このプロジェクトは完成にはまだ程遠く、これから構築するシステムの土台に過ぎません。私が今後取り組みたいと考えている、いくつかの興味深いアイデアをご紹介します。
現時点ではWindowsセキュリティログに重点を置いていますが、このフレームワーク自体にWindows特有の要素はありません。「アイデンティティ+アクション=行動」という基本原則は普遍的です。そのため、このパイプラインは以下の分析にも応用できます。
PLoBは単なるWindowsツールではなく、ユーザーがアクションを実行するあらゆるシステムに対応する行動パターン分析フレームワークです。
このブログ記事が、PLoBプロジェクトに対する理解を深めるお役に立てば幸いです。このプロジェクトは、試行錯誤と発見の連続であり、興味深い旅でした。コードは公開されています。ぜひご自由に探索、評価し、改善してご活用ください。
Splunkはセキュリティチームをいつでも支援いたします。

© 2005 - 2026 Splunk LLC 無断複写・転載を禁じます。
© 2005 - 2026 Splunk LLC 無断複写・転載を禁じます。
