
データ管理の新たなルール
データ管理の新たなルールを取り入れて、データの複雑さを軽減し、サイバーセキュリティとオブザーバビリティを向上させる方法をご紹介します。

Splunkのレポートやダッシュボードの表示を何分も待っていたりしませんか?
そのような運用をしている場合は、高速化したデータモデルやサマリーインデックスの活用を検討してください。
高速化したデータモデルやサマリーインデックスは、グリム童話の「小人の靴屋」の小人たちのような存在であり、本来あなたがやらなければいけない仕事をあなたのいない間にやっておいてくれます。
具体的には、高速化したデータモデルの場合はあなたのいない間に生データから使いそうな部分を抽出してリストにしておいてくれますし、サマリーインデックスの場合はあなたのいない間に前処理としてデータの抽出や集計をしておいてくれるので、あなたがレポートやダッシュボードを表示する時にはいちいちすべての生データを読み込んで集計しないでも結果を表示できます。
ただし、グリム童話の小人と違って、高速化したデータモデルやサマリーインデックスは、事前にそれらの設定をしておかないといけなかったり、働いていてくれている間にCPUやメモリを消費したり、やってくれた結果を保存しておくためにディスクを消費したりします。
1人目の小人である高速化したデータモデルについて説明する前に、まずは(高速化していない)データモデルについて説明します。
データモデルは、SPLを使用しないでも特定のデータを集計して表やグラフとして表示できるようにする仕組みです。ユーザーはSplunkに取り込まれた特定のデータを、Web画面上でExcelのピボットテーブルのように操作して表やグラフを作成し、それらをレポートやダッシュボードパネルとして保存することができます。
データモデルは複数のデータセットからなり、データセットはExcelのテーブルのように特定の列(フィールド)を持った行(イベント)の集まりです。ユーザーは(あらかじめナレッジマネージャが作成した)データセットを使用してピボットテーブルを作成することができます。
ナレッジマネージャによるデータセットの作成の仕方には下記の3種類があります。
このうちサーチ データセットとトランザクション データセットはレポートやダッシュボードの高速化に使用できないため、このブログではイベント データセットについてのみ説明します。
イベント データセットは制約(検索条件)とフィールド定義を持ちます。制約で指定した検索条件に適合するイベントのうち、フィールド定義で指定したフィールドを対象としてピボットテーブルを作成することができます。
また、既存のイベント データセットをもとに子データセットを作成することができます。子データセットは親データセットの制約やフィールド定義を継承し追加の制約を持つため、親データセットのサブセットとなります。孫データセットや曾孫データセットを作成することもできます。
ここではSplunk Enterprise Securityでも使用しているCIM(Common Information Model)のAuthenticationデータモデルを例にピボットテーブルの作成方法を説明します。
AuthenticationデータモデルにはAuthenticationデータセット(データモデルと同名)を最上位のデータセットとしていくつかのデータセットが定義され、それぞれ検索条件に合致した認証ログが含まれています。
Authenticationデータセットを指定してピボットテーブルを作成し、図のように指定する事で日次の認証結果を簡単に表示することができます。
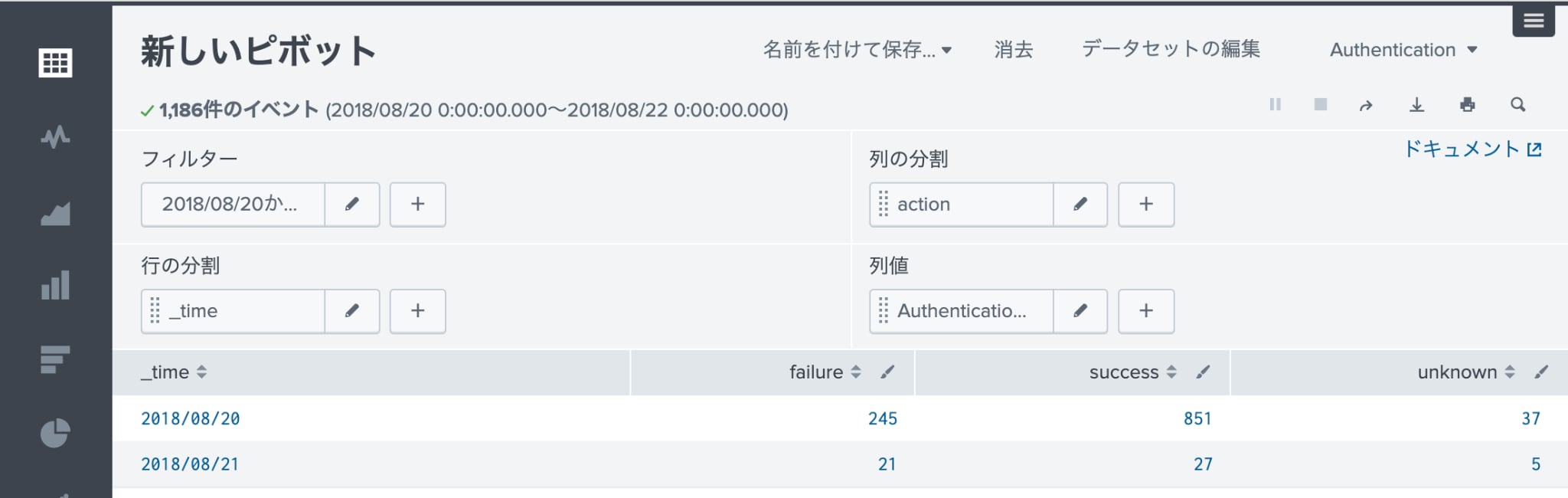
また、この表を簡単にグラフ化することもできます。
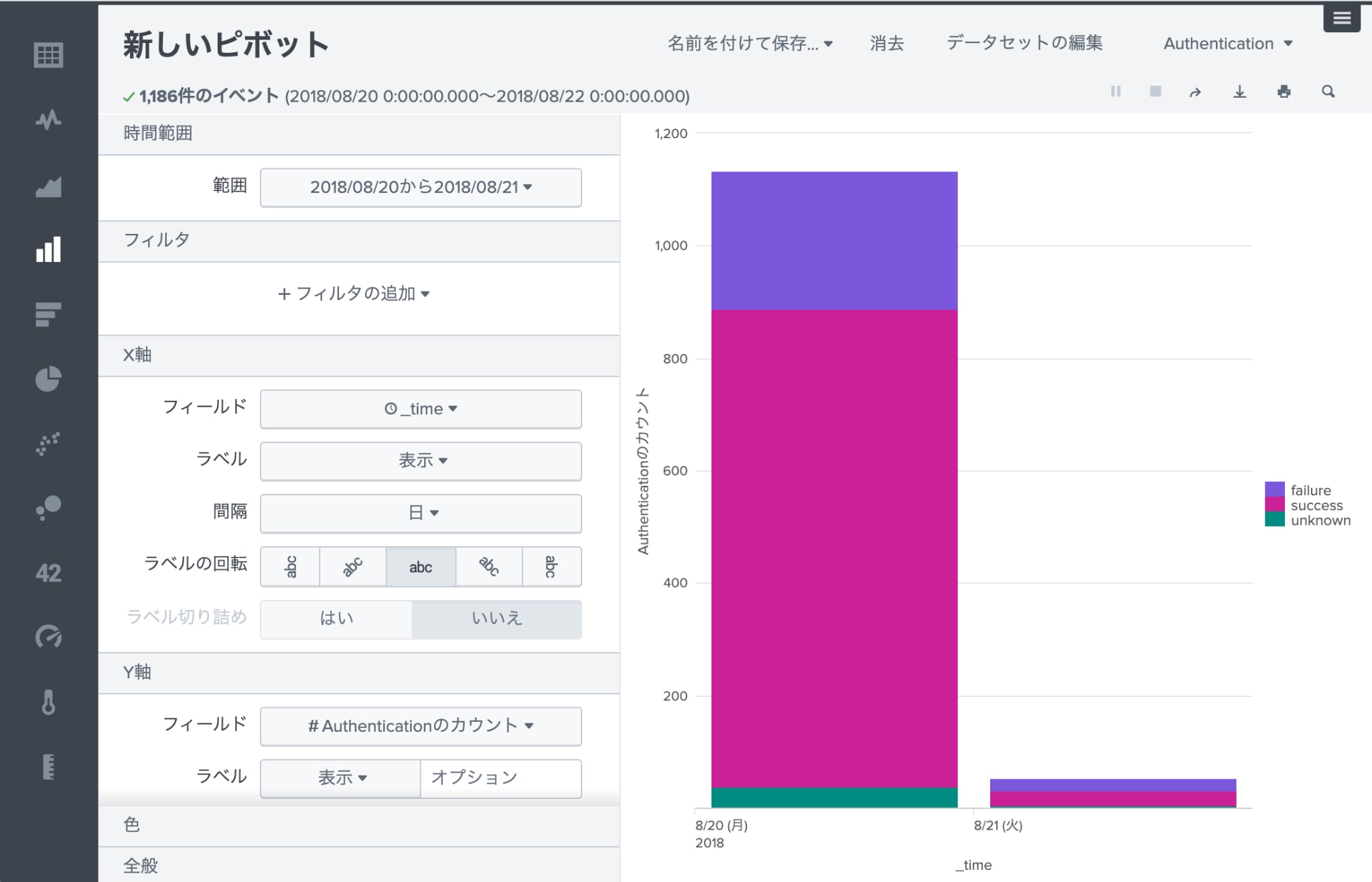
ここまでデータモデルについて説明してきましたが、データモデルは設定画面で高速化のチェックボックスをチェックするだけでピボットテーブルの検索時間を短縮することができます。
その理由は、データモデルを高速化しない場合は圧縮された生データを解凍してフィールドの抽出を行ってからでないとデータの集計ができませんが、データモデルを高速化した場合はデータセットで定義したフィールドの内容をサマリーとして圧縮された生データとは別のリストに保存する処理がバックグラウンドで動くため、ピボットテーブルの表示時にはそのリストを読み込むだけで集計を開始できるからです。
また、データモデルはピボットテーブルの作成に使用するだけでなく、tstatsコマンドを使用する事で通常の検索におけるstatsコマンドのように集計を行うこともできます。
例えば、下記のSPLではbotsv3インデックスの認証ログから日次の認証結果を表示できますが、
| SPL | 説明 | 実行時間 |
|---|---|---|
| index=botsv3 tag=authentication | botsv3インデックスから認証ログを検索 | 9.056秒 |
| i fillnull value="unknown" action | 認証結果がNULLの場合は”unknown”を代入 | |
| timechart span=1d count by action | 各認証結果の数を日次で集計 |
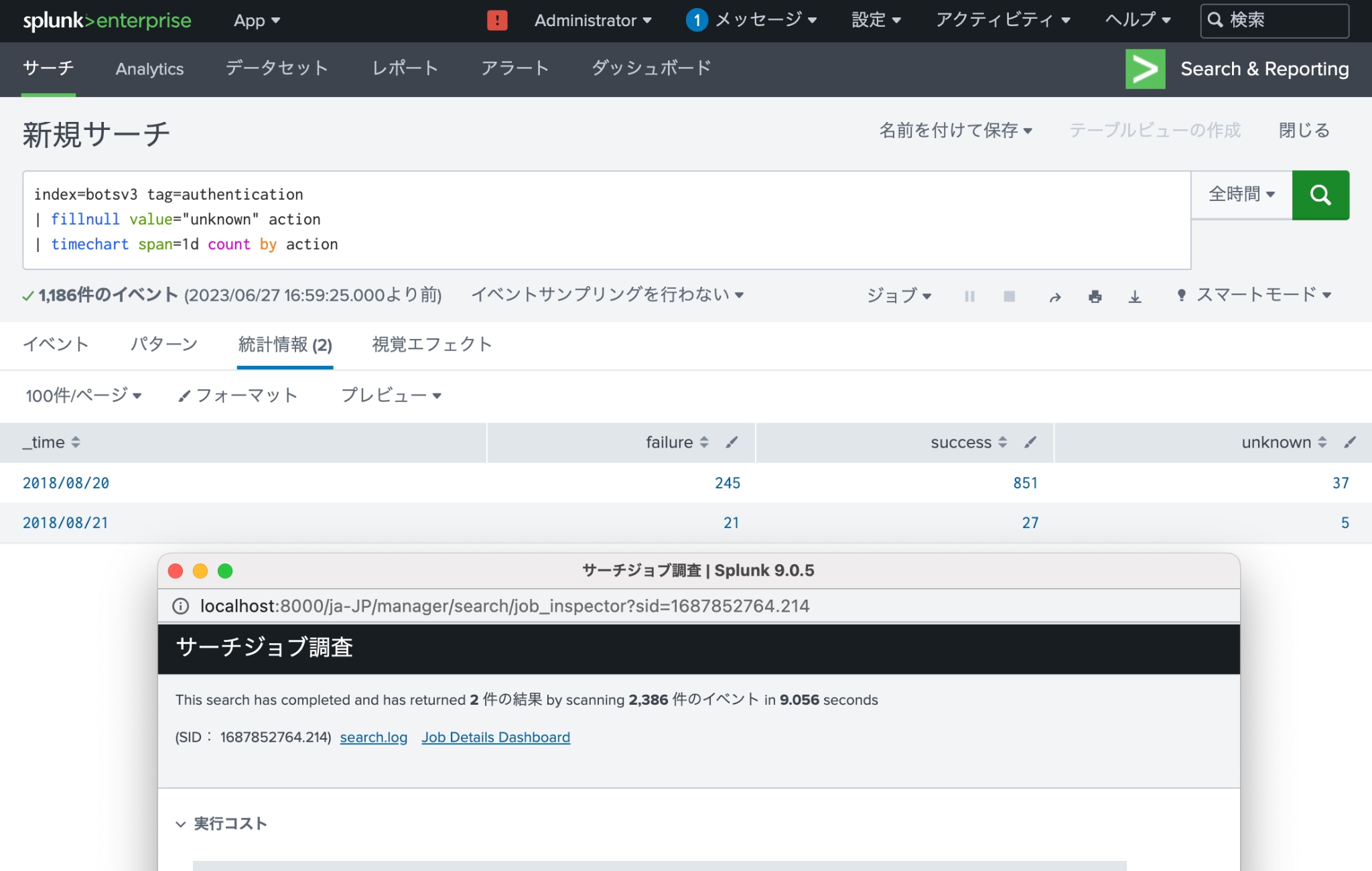
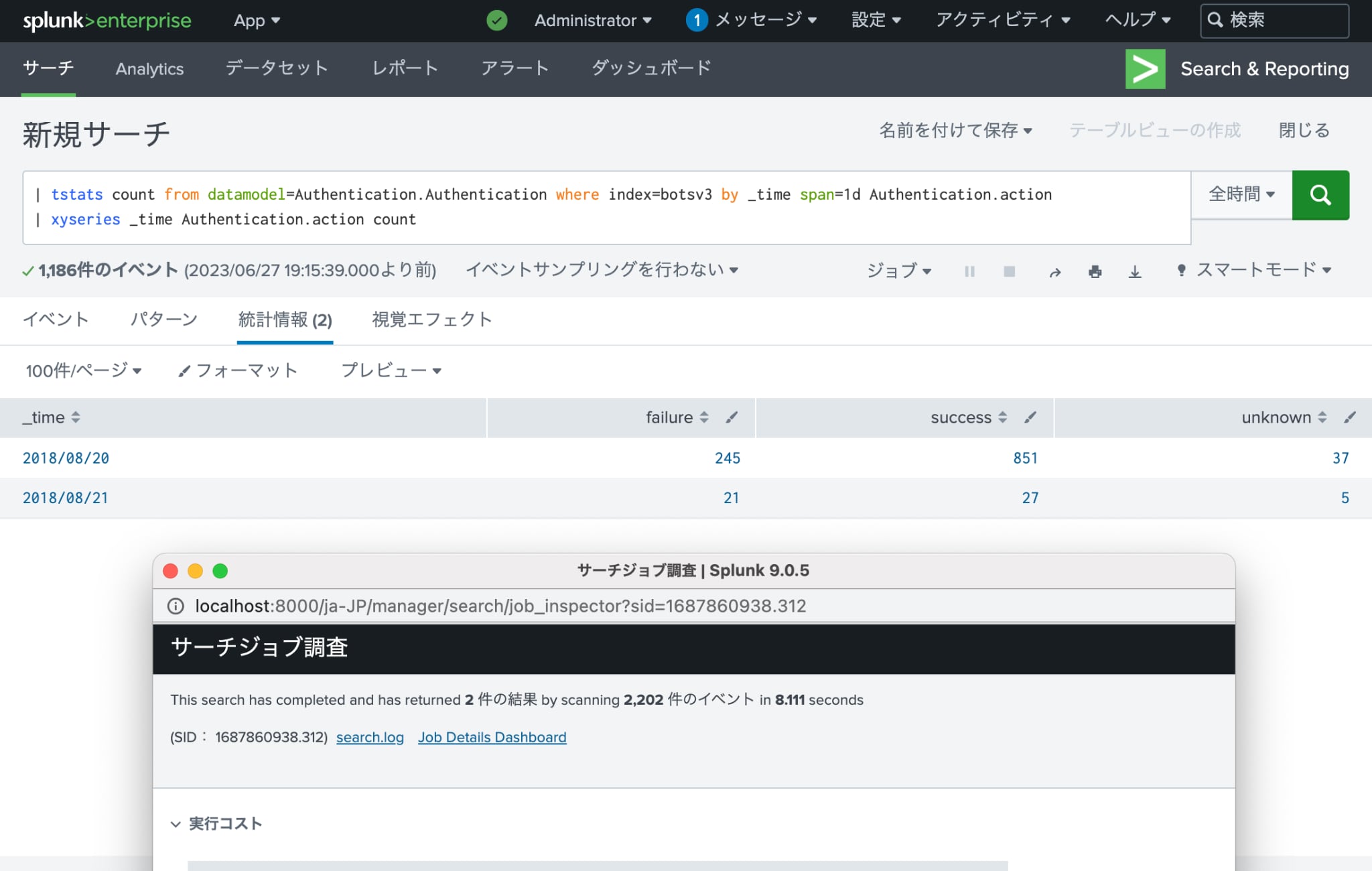
tstatsコマンドを使用すると、これと同様の結果を下記のSPLで表示できます。
| SPL | 説明 | 実行時間 |
|---|---|---|
| | tstats count from datamodel=Authentication.Authentication where index=botsv3 by _time span=1d Authentication.action | AuthenticationデータモデルのAuthenticationデータセットのデータのうちbotsv3インデックスにあるものを対象に各認証結果の数を日次で集計 | 8.111秒 |
| | xyseries _time Authentication.action count | 表をピボットして縦軸に日付を横軸に認証結果の数を表示 |
また、Authenticationデータモデルを高速化し、下記のようにtstatsコマンドにsummariesonly=trueオプションを指定することで検索時間を短縮できます。
| SPL | 説明 | 実行時間 |
|---|---|---|
| | tstats summariesonly=true count from datamodel=Authentication.Authentication where index=botsv3 by _time span=1d Authentication.action | AuthenticationデータモデルのAuthenticationデータセットのデータのうちbotsv3インデックスのサマリーにあるものを対象に各認証結果の数を日次で集計 | 0.582秒 |
| | xyseries _time Authentication.action count | 表をピボットして縦軸に日付を横軸に認証結果の数を表示 |
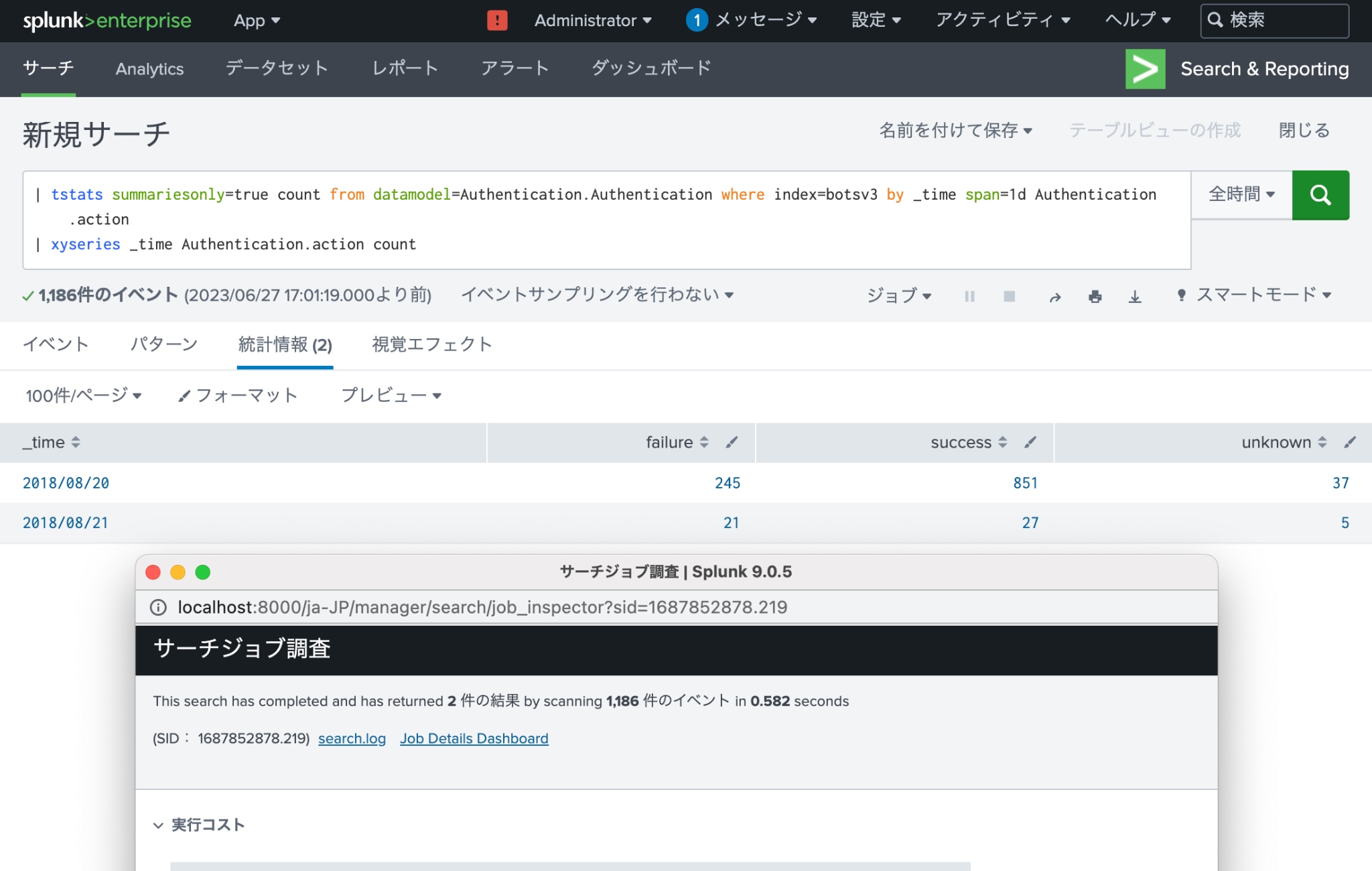
ただし、summariesonly=trueオプションを指定すると、最近取り込まれてまだサマリーに記録されていないデータは集計対象とならないため、高速化したデータモデルを使用しない場合に比べて検索結果のリアルタイム性が失われるというデメリットが生じます。
上記3つのSPLの実行時間ですが、通常のSPLが9.056秒、高速化しないtstatsが8.111秒かかりましたが、高速化したtstatsは0.582秒で表示できました。通常のSPLでフェッチしたイベント件数は2,386件なのでデータ件数が増えるとこの差がどんどん広がっていくのが想像いただけると思います。
これが1人目の小人がしてくれる仕事です。
高速化したデータモデルについては、英語ですがこちらに情報があります。
また、日本語字幕付きの無料eLearningコースがあります。
2人目の小人であるサマリーインデックスは、名前にインデックスという文字列が含まれているため特別なインデックスと思われがちですが、SPLによる検索結果をイベントとして保存しておくための仕組みであり、一度作成してしまえば後は通常のイベントと同じものです。
このようなイベントを格納するためのインデックスとして、デフォルトでsummaryという名前のインデックスが用意されていますが、この他のインデックスに保存することも可能です。
また、サマリーインデックスの特徴として、イベントのsourcetypeに自動的にstash(日本語でヘソクリの意)という値が設定される点と、取り込みライセンスの容量としてカウントされないという点が挙げられます。
サマリーインデックスによる検索の高速化は、まず検索を2段階に分割し、前段の処理の結果をサマリーインデックス(イベント)として保存しておき、そのサマリーインデックス(イベント)を対象として後段の処理を実行してレポートやダッシュボードを表示し、実際にユーザーが体感する検索時間(後段の検索時間のみ)を短縮することで実現します。
例えば、botsv3インデックスのpsコマンドの実行ログから、各プロセス(同名のプロセスが同一ホスト内で複数同時に実行している場合はその合計)のCPU使用率の各日の最大値が20%を超えるものを抽出するSPLは下記のようになります。
| SPL | 説明 | 実行時間 |
|---|---|---|
| index=botsv3 sourcetype=ps | botsv3インデックスからpsコマンドの実行ログを検索 | 8.575秒 |
| | stats sum(pctCPU) as pctCPU by _time host process_name | 時刻/ホスト名/プロセス名毎にCPU使用率の合計値を集計 | |
| | bin span=1d _time | 時刻を日付毎に集約 | |
| | stats max(pctCPU) as pctCPU by _time host process_name | 日付/ホスト名/プロセス名毎にCPU使用率の最大値を集計 | |
| | eval time=strftime(_time, "%Y-%m-%d"), host_name=host | 日付を文字列に変換 ホスト名のフィールド名を変更 |
|
| | table time host_name process_name pctCPU | 日付/ホスト名/プロセス名/CPU使用率をテーブルとして出力 | |
| | where pctCPU > 20 | CPU使用率が20%を超えるものを抽出 |
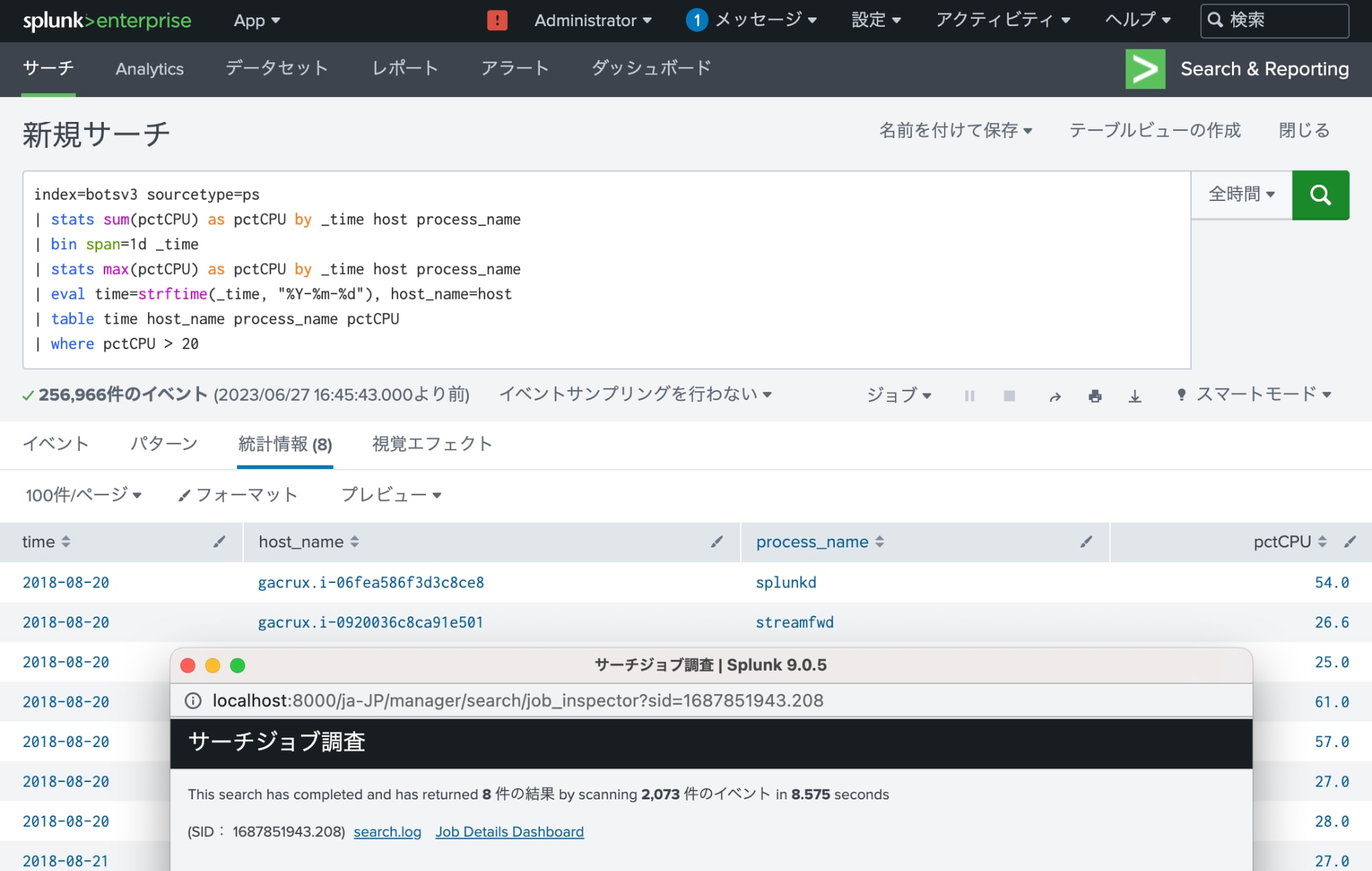
このSPLを2段階に分割すると、サマリーインデックスを作成するSPL (事前にps_summaryインデックスを作成する必要あり)とサマリーインデックスを検索して表示するSPLになります。
| SPL | 説明 | 実行時間 |
|---|---|---|
| index=botsv3 sourcetype=ps | botsv3インデックスからpsコマンドの実行ログを検索 | 11.877秒 (バックグラウンドで実行されるため表示待ち無し) |
| | stats sum(pctCPU) as pctCPU by _time host process_name | 時刻/ホスト名/プロセス名毎にCPU使用率の合計値を集計 | |
| | bin span=1d _time | 時刻を日付毎に集約 | |
| | stats max(pctCPU) as pctCPU by _time host process_name | 日付/ホスト名/プロセス名毎にCPU使用率の最大値を集計 | |
| | eval time=strftime(_time, "%Y-%m-%d"), host_name=host | 日付を文字列に変換 ホスト名のフィールド名を変更 |
|
| | table time host_name process_name pctCPU | 日付/ホスト名/プロセス名/CPU使用率をテーブルとして出力 | |
| | collect index=ps_summary | 結果をps_summaryインデックスにサマリーインデックスとして保存 |
| SPL | 説明 | 実行時間 |
|---|---|---|
| index=ps_summary | ps_summaryインデックスからサマリーインデックスを検索 | 1.627秒 |
| | table time host_name process_name pctCPU | 日付/ホスト名/プロセス名/CPU使用率をテーブルとして出力 | |
| | where pctCPU > 20 | CPU使用率が20%を超えるものを抽出 |
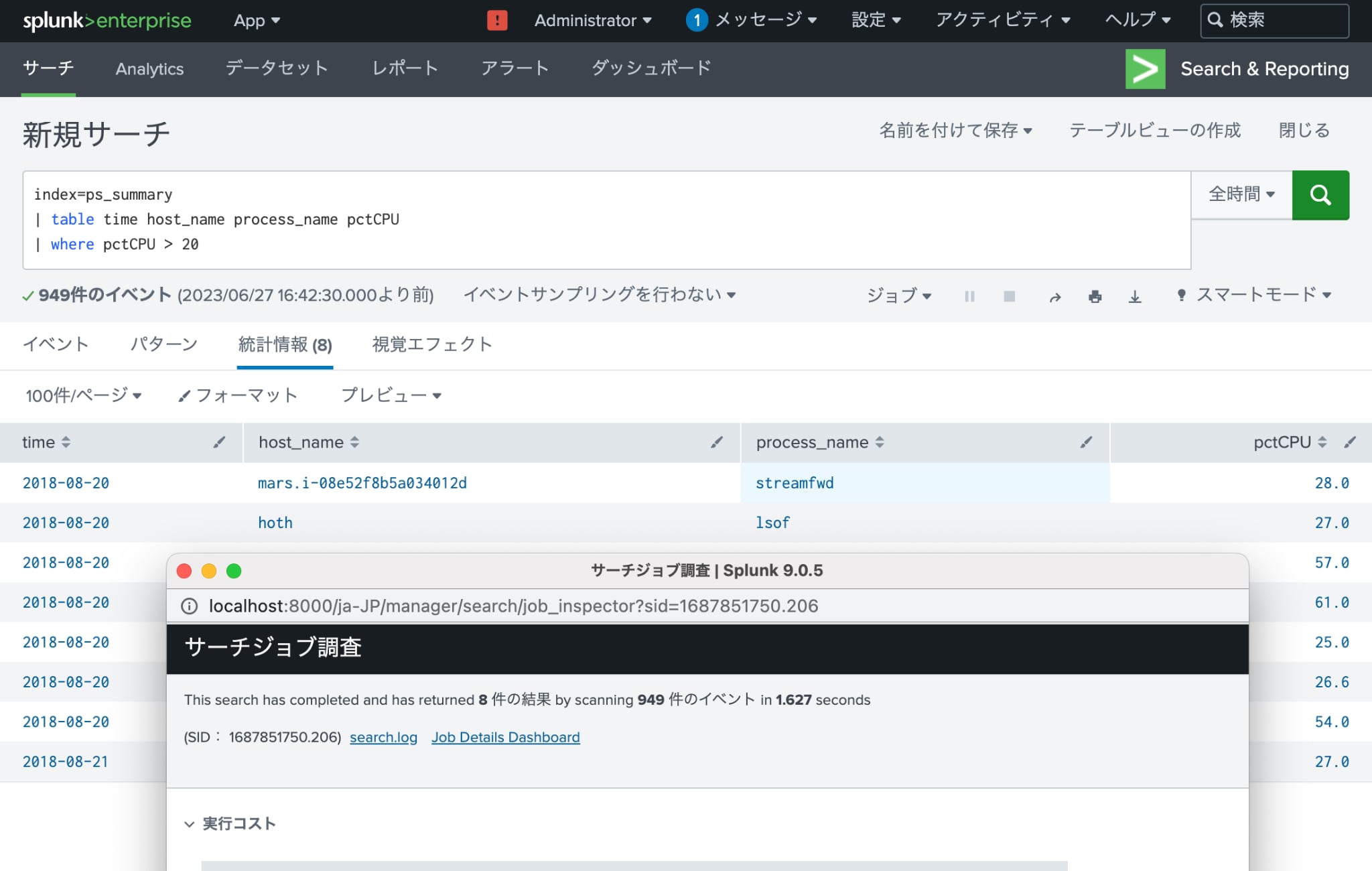
ここでは全体のイメージを掴んでいただくためにcollectコマンドを使用してサマリーインデックスを一括で作成しましたが、実際にはこの例では前日分のpsコマンドの実行ログを集計するスケジュールサーチを日次で実行してサマリーインデックスの作成を行います。
サマリーインデックスを作成する周期は要件や設計によって変わりますが、いずれにしてもサマリーインデックスを使用しない場合に比べてリアルタイム性が失われるというデメリットが生じます。
SPLの実行時間ですが、分割前のSPLは8.575秒かかりましたが、分割後の後段の表示に使用するSPLは1.627秒で表示できました。分割前のSPLでフェッチしたイベント件数は2,073件なのでデータ件数が増えるとこの差がどんどん広がっていくのが想像いただけると思います。
これが2人目の小人がしてくれる仕事です。
サマリーインデックスについては、英語ですが下記に情報があります。
1人目の小人である高速化したデータモデルと2人目の小人であるサマリーインデックスを比較したのが下記の表です。
| 高速化したデータモデル | サマリーインデックス | |
|---|---|---|
| 特徴 | 元のイベントも保持しておく必要があるため、比較的短期間の大量のイベントを集計するのが得意。 どのように集計するかはレポート毎に変える事ができるため柔軟性が高い。 |
元のイベントとは独立した保持期間を設定できるため、長期間のイベントを集計するのが得意。 集計単位(日次であれば1日)あたりのデータ件数が多ければ多いほど高速化の効率が良い。 |
| SPL修正の必要性 | tstatsを使用して修正する必要がある。 | サマリーインデックスを作成するSPLと利用するSPLに分割する必要がある。 |
| 管理 | Web UIで有効にすると、初期構成が行われ、以後5分毎に新しいイベントについてサマリーが自動的に更新される。 必要に応じてサマリーを再構成することができる。 |
サマリーインデックスを作成するSPLをスケジュールサーチとして登録してサマリーインデックスを作成する必要がある。 スケジュールがスキップされた場合のデータ抜けや、何らかの理由によるデータ重複は、手作業で対応する必要がある。 |
上記を参考に高速化したデータモデルとサマリーインデックスを使い分けてください。
Splunkの小人たちにうまく仕事をしてもらうことで、レポートやダッシュボードの表示にかかる時間を短縮し、運用ユーザーの生産性を向上しましょう。これにより問題の発見や解決に掛かる時間を短縮でき、レジリエンスを向上することも可能です。
なお、例で使用したbotsv3インデックスは下記からダウンロードできますので、実際に動作を試していただくことができます(リンク先の指示に従って指定のAdd-onもインストールしてください)。
GitHub - splunk/botsv3: Splunk Boss of the SOC version 3 dataset

© 2005 - 2026 Splunk LLC 無断複写・転載を禁じます。
© 2005 - 2026 Splunk LLC 無断複写・転載を禁じます。
