
オブザーバビリティの現状
グローバル調査で明らかになった、AI導入、セキュリティチームとのコラボレーション、ビジネス収益の促進要因に関する現状をご紹介します。

Splunk Observability Cloudがさまざまな点でさらに進化しました。エンジニアリングチームは、環境全体をより詳細に可視化し、より統合的なインシデント対応アプローチを取り入れることで、雑音をはねのけ、トラブルシューティングを加速できます。最前線で対応に当たるエンジニアは、観測できないデジタルリソースは十分に守れないことを知っています。Splunkの新たなイノベーションによって、組織内で問題が発生したときに、クラウドネットワーク全体と各トランザクションでのエンドユーザーエクスペリエンスに関するより詳細なコンテキストを獲得して、問題の原因をすばやく特定できるようになりました。また、アラートの精度が向上したことで問題への対応をいっそう効率化でき、オンコールでの複雑なプロセスが単一の画面によって整理されています。
さらに、業界をリードするSplunkのログ機能とインシデント対応機能がSplunk Observability Cloudに統合されたことで、本番環境全体に及ぶ問題のトラブルシューティング時に複数のチーム間でコンテキストを共有できるようになりました。
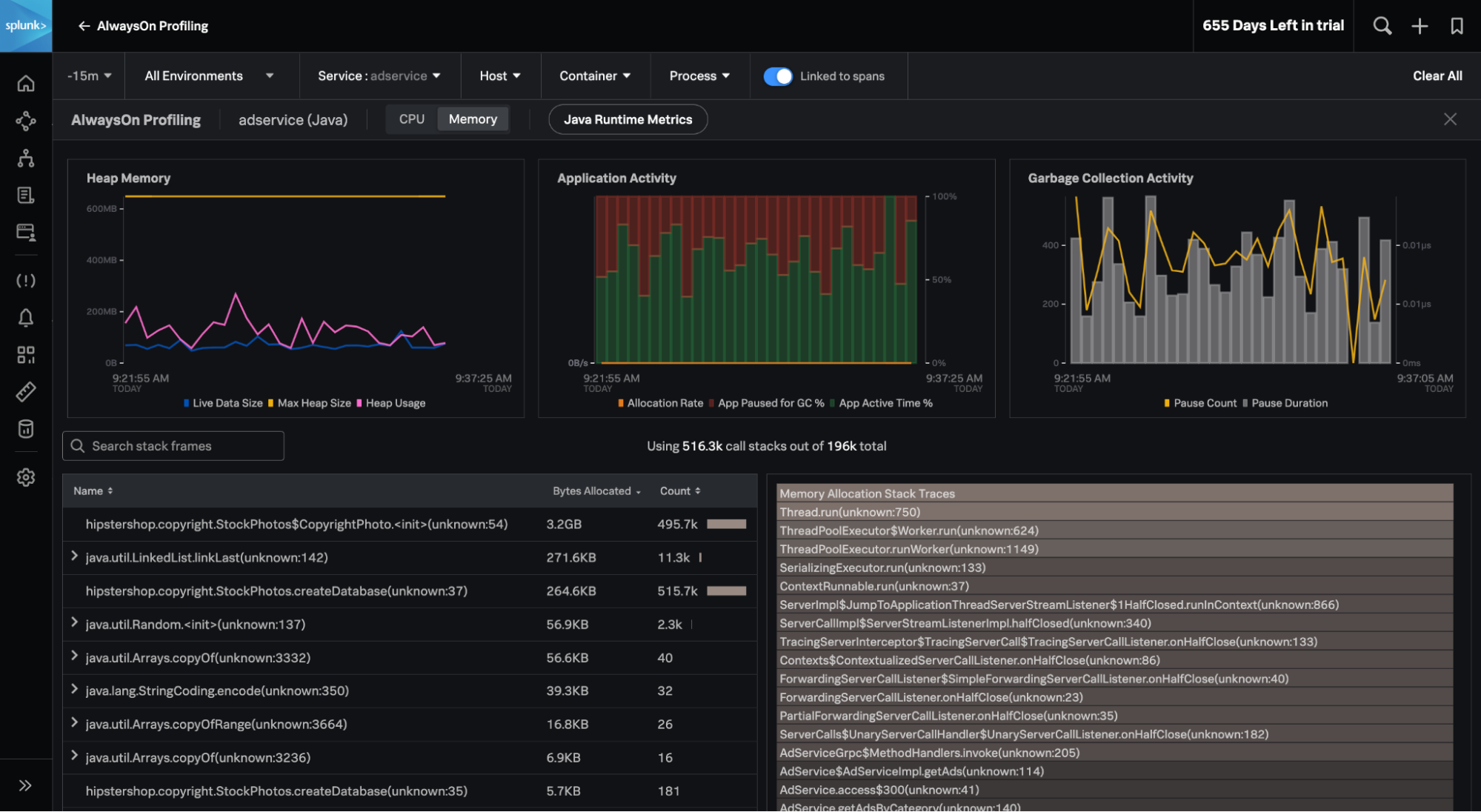
複数の新機能により、テクノロジースタックとエンドユーザーエクスペリエンス全体をより詳細に可視化し、豊富なコンテキストを獲得することで、問題解決を加速できます。モノリシックアーキテクチャとマイクロサービスアーキテクチャのどちらでも、クラウドネットワークやKubernetesクラスター全体を対象に、問題が発生しているユーザーセッションやタグに関するコンテキストを獲得して、問題の原因をすばやく特定して顧客への影響を把握できます。
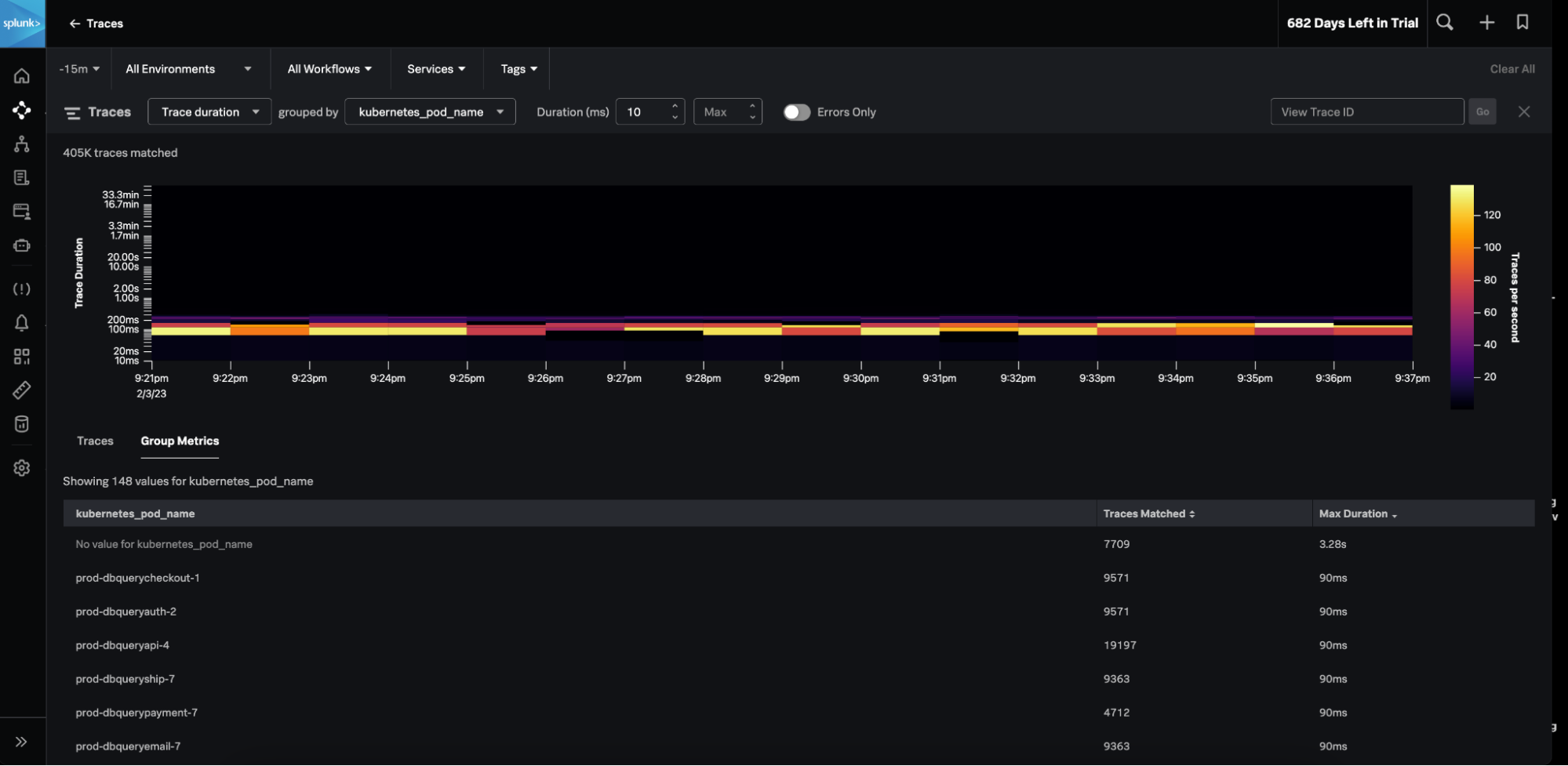
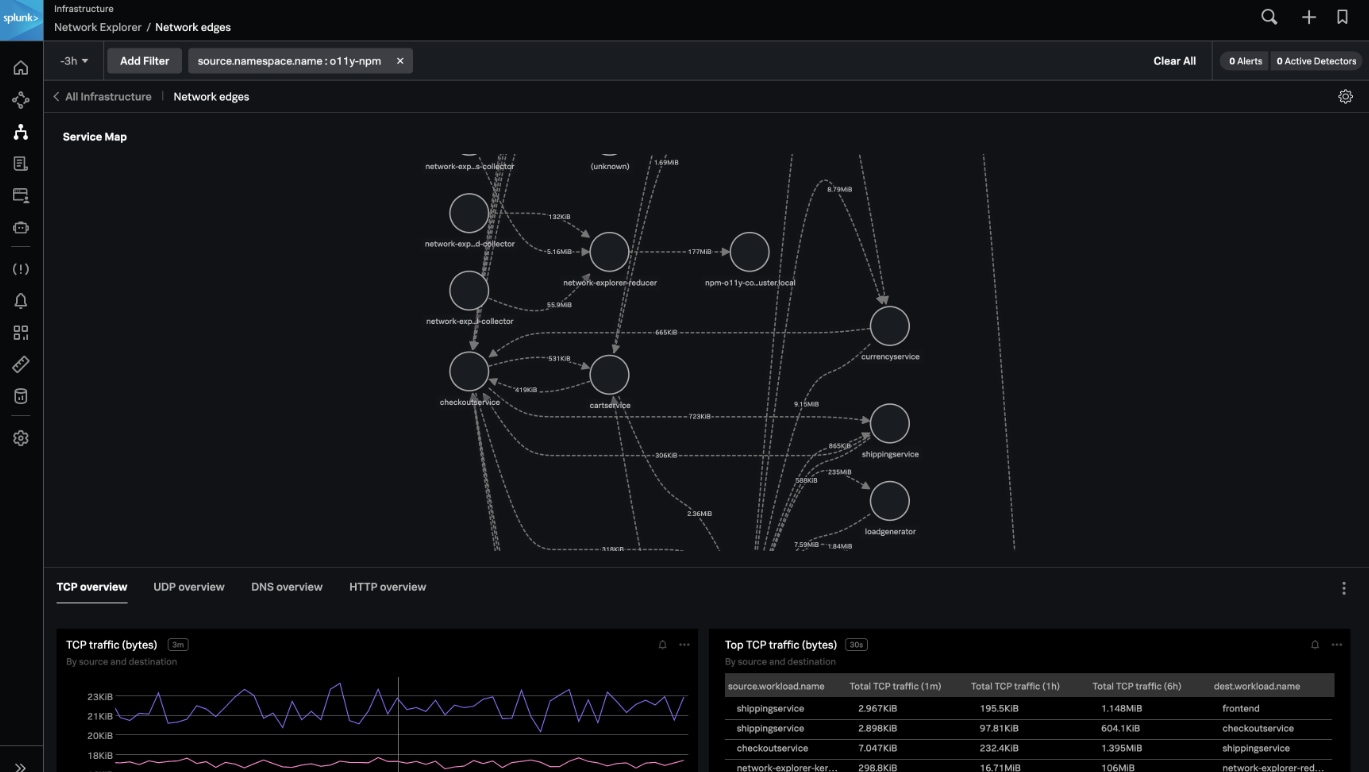
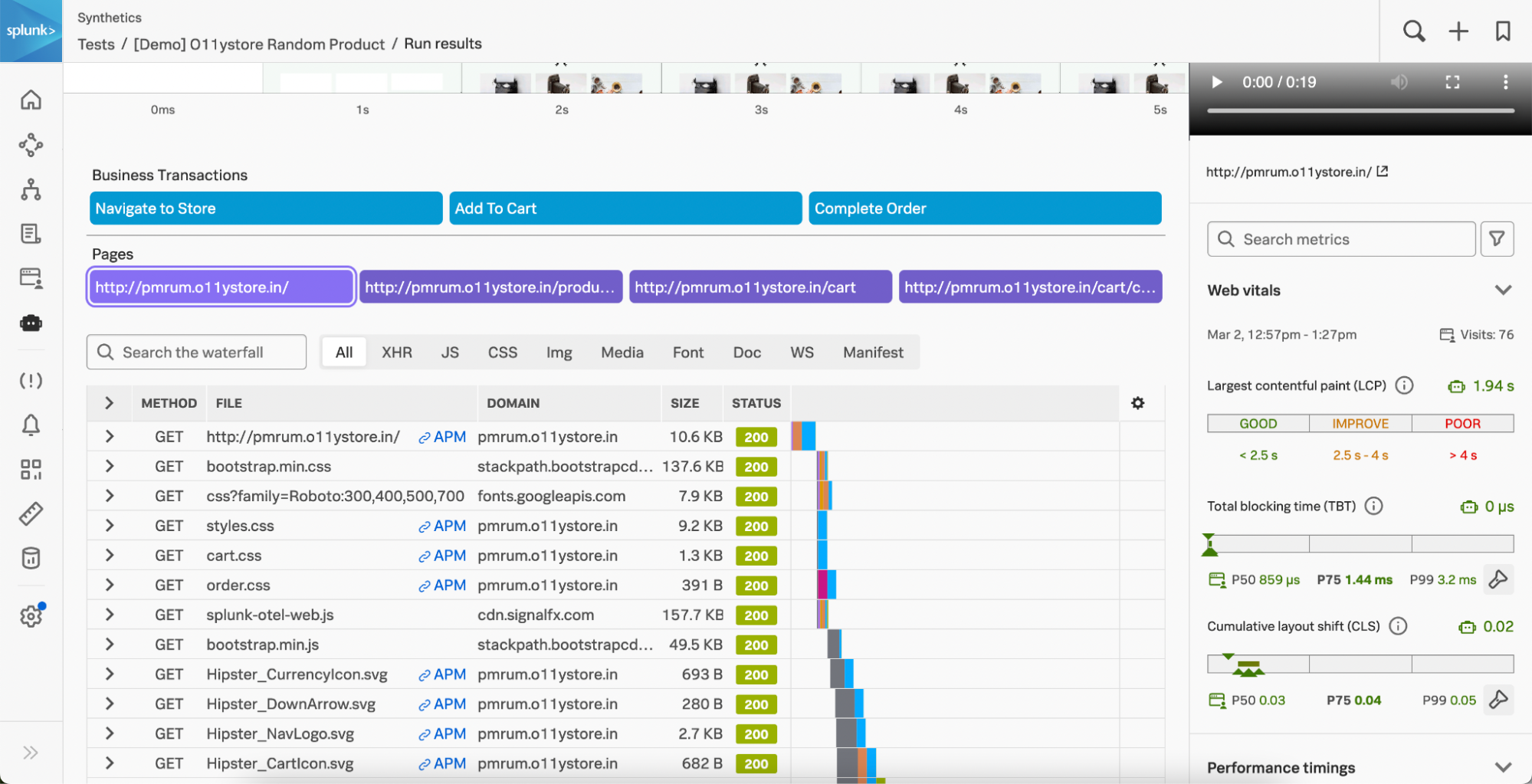
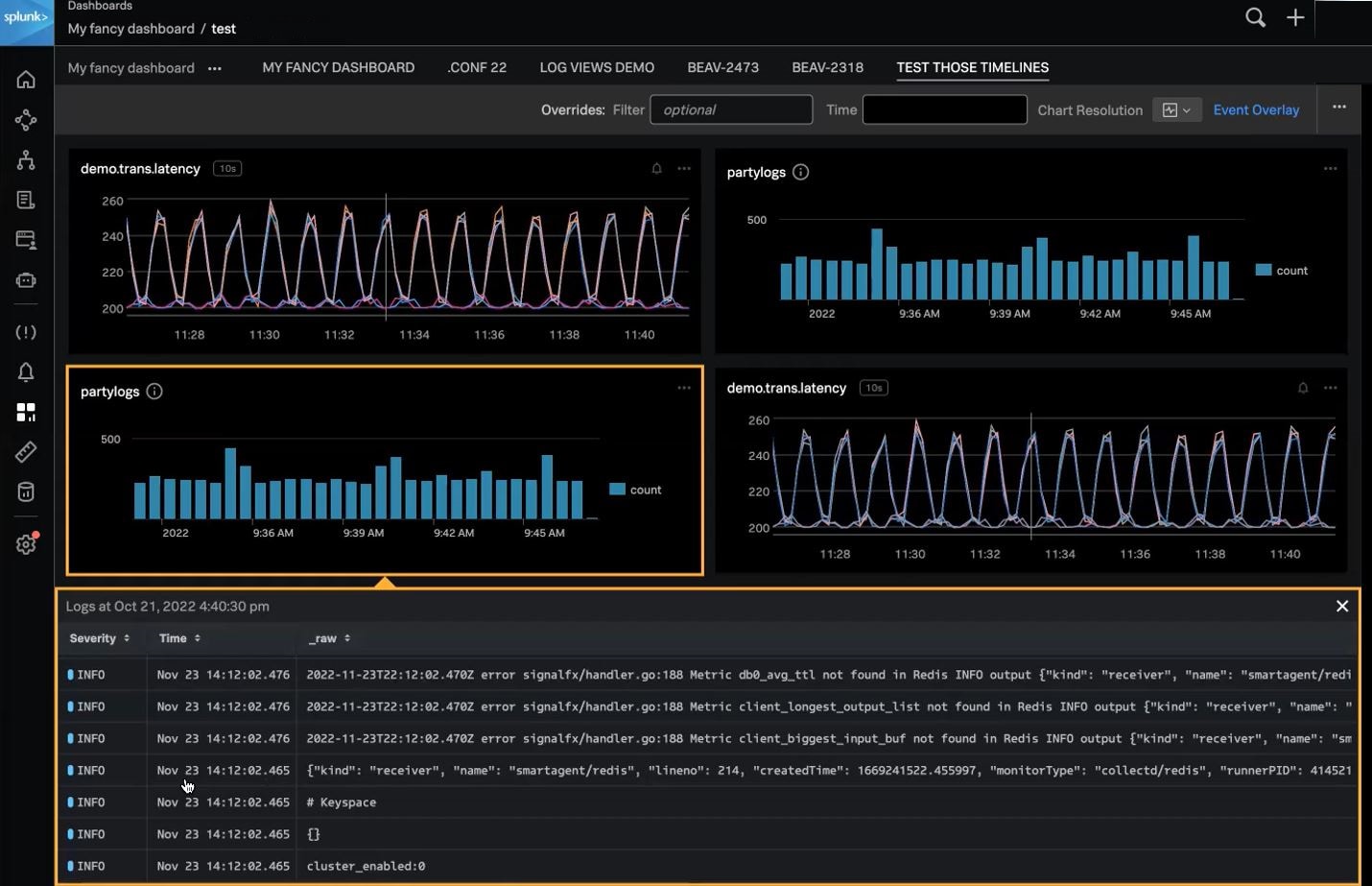
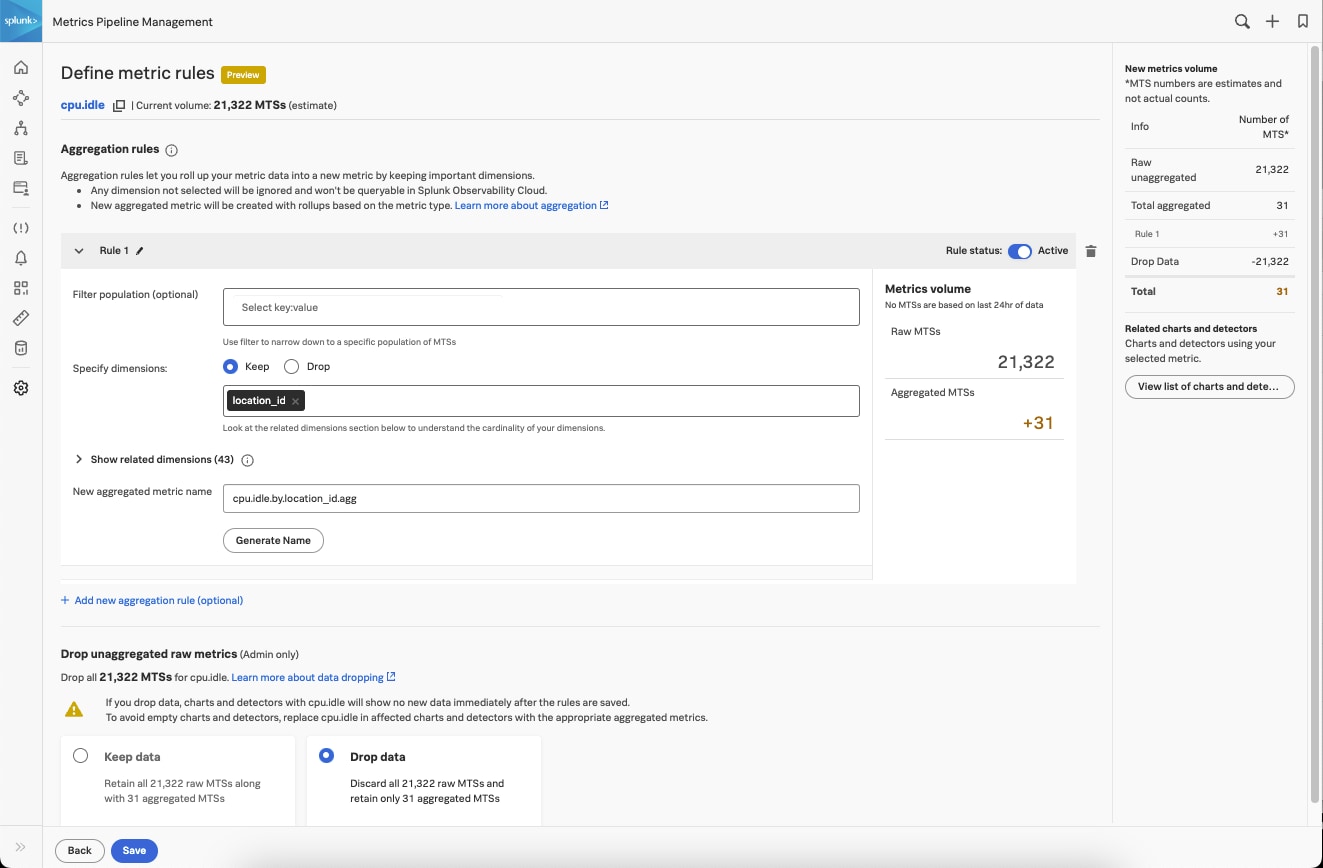
新たに追加されたSplunk Incident IntelligenceとAutoDetect機能によって、オンコールチームの効率を大幅に向上できます。アラートの精度を高め、ワークフローを合理化することで、チームの連携と効率を改善し、アラート発生から解決までのプロセスを加速してMTTD、MTTA、MTTRを短縮できます。
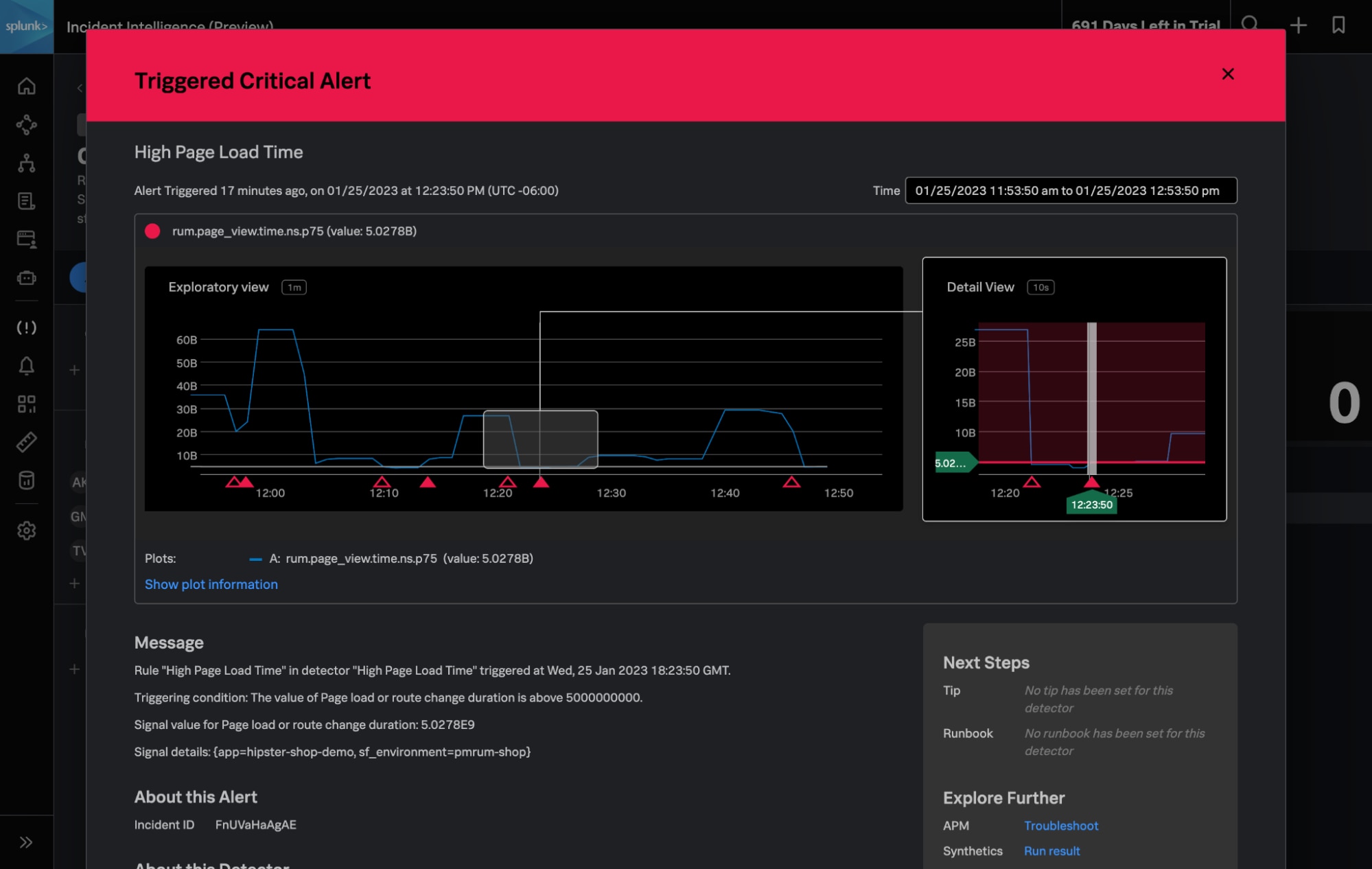
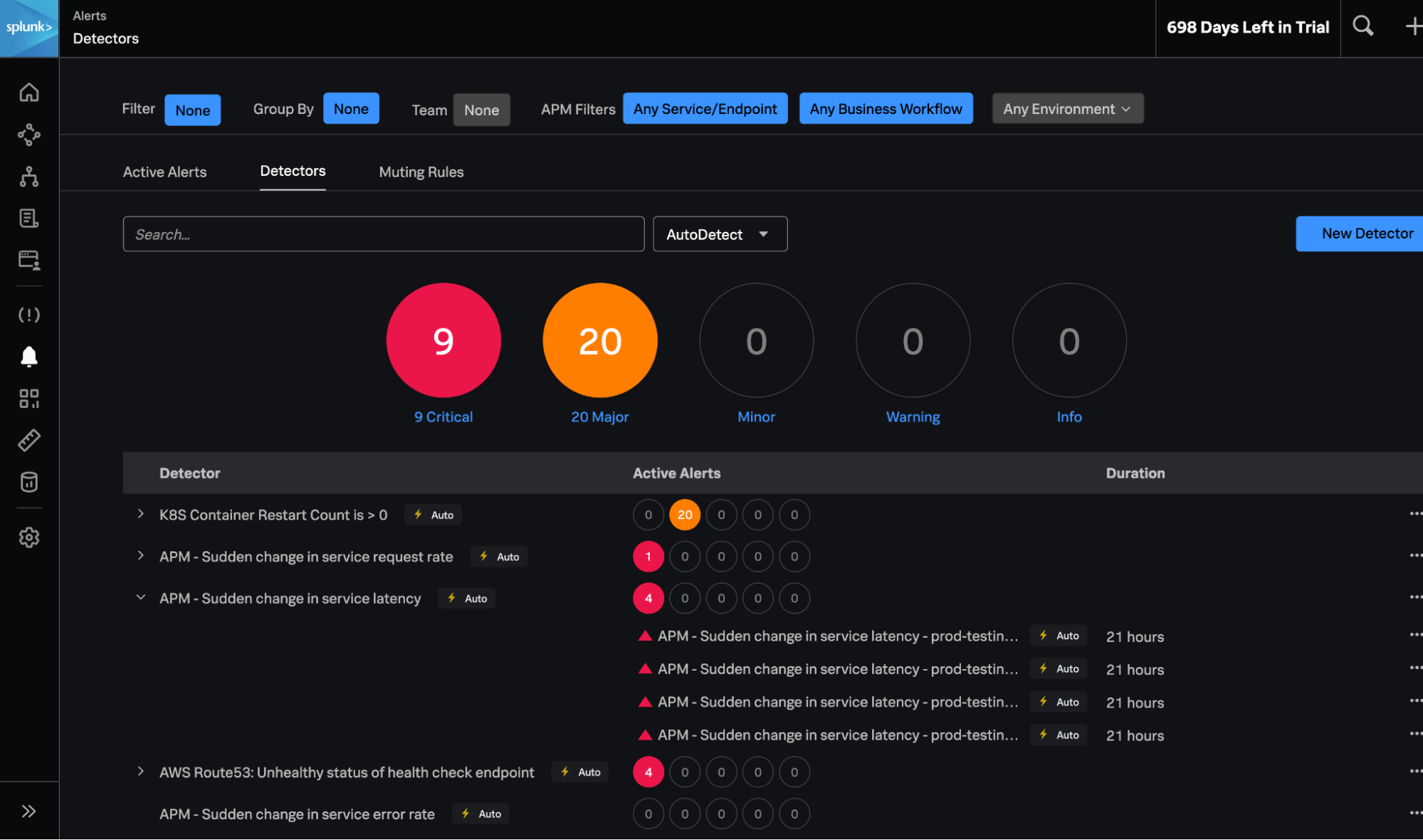
Splunkオブザーバビリティ製品の新しいイノベーションについて詳しくは、ウェビナー「Splunk Observability Innovations Showcase: Increased Visibility & A Unified Approach to Incident Response (Splunkのオブザーバビリティイノベーションのご紹介:可視化の強化と統合的なインシデント対応アプローチ)」にご参加ください。次のリンクから各ライブセッションにご登録いただけます。
ダウンタイム、サービス停止、重大なシステム障害は、ビジネスに深刻な影響をもたらす可能性があります。実際、Uptime Institute社の2022年障害分析によると、60%の障害が10万ドル以上のビジネス損失につながっています。統合セキュリティ/オブザーバビリティプラットフォームを提供するSplunkは今後も、お客様のパートナーとして、システムのパフォーマンスと信頼性を維持するデジタルレジリエンスの構築を全力でご支援します。
Splunk Observability Cloudの新機能について学んだら、次はぜひそれらを体験してください。トライアル版ではSplunk Observability Cloudを、次のいずれかの方法でお試しいただけます。
14日間無料のトライアル版はこちらからお申込みいただけます!
このブログはこちらの英語ブログの翻訳、大森 明央によるレビューです。

© 2005 - 2026 Splunk LLC 無断複写・転載を禁じます。
© 2005 - 2026 Splunk LLC 無断複写・転載を禁じます。
