
AIでセキュリティ分析をレベルアップ
AIが脅威の調査と対応の効果向上にどのように役立つかについてご紹介します。
Splunk Observability Cloudは、アプリケーション、インフラ、エンドユーザーの監視に特化したシステムを共通のデータモデルで統合し、単一のインターフェイスで提供するフルスタックのオブザーバビリティソリューションです。これにより、複雑なテクノロジースタックや、メトリクス、イベント、ログ、トレース(MELT)などのさまざまなデータタイプに加え、エンドユーザーセッション、データベースクエリー、スタックトレースといった重要な情報をエンドツーエンドで可視化できます。ただし、扱うデータが膨大かつ多様であるため、問題の特定と解決の作業は困難を極め、多くの場合、担当者の専門知識とツールへの習熟度に大きく依存することになります。そこで威力を発揮するのがAI Assistantです。AI Assistantが提供する対話型のインターフェイスを通じてインサイトを引き出し、環境全体にわたる調査と探索を合理化することができます。
AI Assistantの中核をなすのは、オブザーバビリティデータの操作やワークフロー(トラブルシューティングや探索)の作成を自然言語によって実行できる機能です。これにより、Kubernetesクラスターの健全性に関する検査と分析、複雑なサービストポロジーにおけるレイテンシーの原因究明、エラーに関連するスパンの属性検出、根本原因の特定、ログ全体からのパターン抽出といった、オブザーバビリティ関連の幅広いアクティビティやユースケースに対応できます。
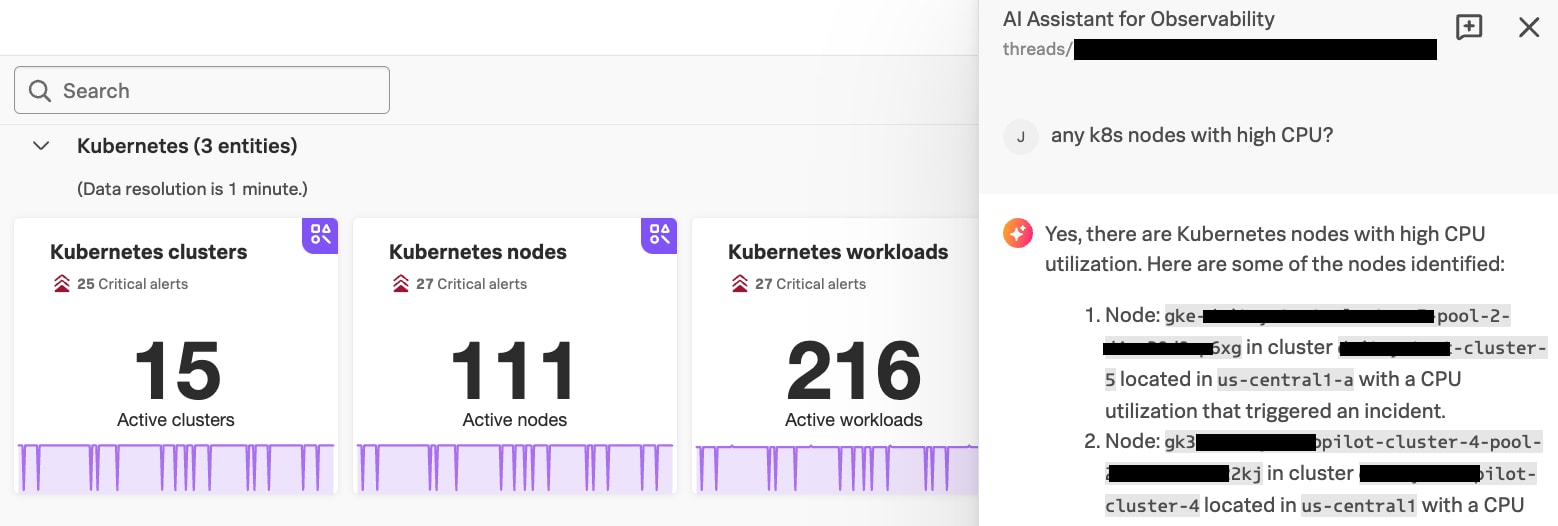
図1:Observability CloudのAI Assistantのユーザーインターフェイス
Splunkはこれまでにも、オブザーバビリティ製品とセキュリティ製品を強化するために言語モデル関連の先進的な技術を積極的に取り入れてきました。最近でも、Splunk AI Assistant for SPL (サーチ処理言語)の抜本的な機能強化を発表したばかりです(2024年7月執筆時点)。この製品は、SPL (Splunkプラットフォームのクエリー記述言語)によるクエリーを、自然言語を使って構築したり、内容を理解したりするための機能を提供します。Observability CloudのAI Assistant (以下「AI Assistant」)も、この領域での当社の継続的な取り組みを示す成果のひとつです。
Splunkは、大規模言語モデル(LLM)が誇るオブザーバビリティ領域での驚異的な解決力と分析力に注目し、その広範な知識や推論能力をSplunk製品に導入する取り組みを進めてきました。このブログ記事では、LLM活用の技術的アプローチの概要、Splunkの対象領域に組み込む際に直面した課題、そして今後の展望について説明します。
当社が採用しているのはエージェント型のアプローチです。これは、汎用的なLLMがさまざまなツールにアクセスできるようにして、その機能を強化する方式です。ユーザーとの対話を中心的に担うのはオーケストレーションエージェント(オーケストレーター)です。このエージェントは、ユーザーの意図の理解、計画立案、適切なツールの呼び出し、ツールの応答に基づく推論といった重要な機能を持つLLMを基盤としています。Splunk Observability Cloudの場合、このオーケストレーターは、まずユーザーのリクエストを理解します。次に、ツールを呼び出す順序の計画を立て、Splunk Application Performance Monitoring (APM)、Splunk Infrastructure Monitoring、Splunk Log Observer Connectなどが提供する特定のマイクロサービスにリクエストを送ります。最後に、ツールからの応答を統合して当初のリクエストに応えます。LLMには、ツールの説明と関数のシグネチャを含めたツールのリストが渡されます。複雑なタスクの場合は、複数のツールを連鎖的に使用することで最終的な回答にたどり着くことができます。たとえば、ユーザーが「決済サービスのエラー率が高い根本原因」について尋ねた場合、オーケストレーターは、ユーザーの意図が特定のサービスのトラブルシューティングであることを理解する必要があります。そして計画を立案することで、LLMはまず、サーチを行って「payment (決済)」などのサービス名を見つけ出し、APM APIを呼び出してエラーの詳細を取得し、その中から情報を抽出して可能性のある根本原因を特定する必要があることを認識します。
オーケストレーションエージェントがユーザーのクエリーのコンテキストと制約を理解できるようにするためには、効率的で安全なシステムプロンプトを作成することが肝心です。システムプロンプトには、以下の内容が含まれます。
オーケストレーターは、コンテキスト情報を保持するための短期メモリーを備えており、これによって適切な意思決定を行うことができます。このメモリーに含まれる情報は、ユーザーの現在のクエリー、ユーザーとエージェント間の現在の会話、システムプロンプト、およびツールの説明です。このメモリーは短期的なもので、現在の会話に関する情報だけが保持されます。メモリー容量は、主にオーケストレーターのLLMのコンテキスト長によって決まります。
エージェントに目的の概要とガイドラインを示したら、次はさまざまなオブザーバビリティデータとプラットフォームの各要素をツールとして提供します。
このプレビューリリースでは、エージェントのツールとして以下の領域のものが含まれています。
各ツールには、詳細な説明とパラメーターの情報が付属しています。オーケストレーターの役割は、ツールを選択し、コンテキストからのパラメーターを抽出することです(たとえば、「過去1時間」は["-1h", "now"]という時間範囲オブジェクトにマッピングされます)。
ツールの中には、複数ステップからなる複数のワークフローで構成され、それ自体がLLMを基盤とするものもあります。これらの特化型エージェントは、通常、オーケストレーションエージェントが利用するコンテキストのサブセットに基づいて処理を行っているため、サブLLMと呼ばれます。これらは、SignalFlowの生成、チャートの作成、根本原因分析などの特定のタスクの処理に特化しています。特化型エージェントは、一般的な関数呼び出しと同じ方法で他のツールを呼び出す機能を備えています。
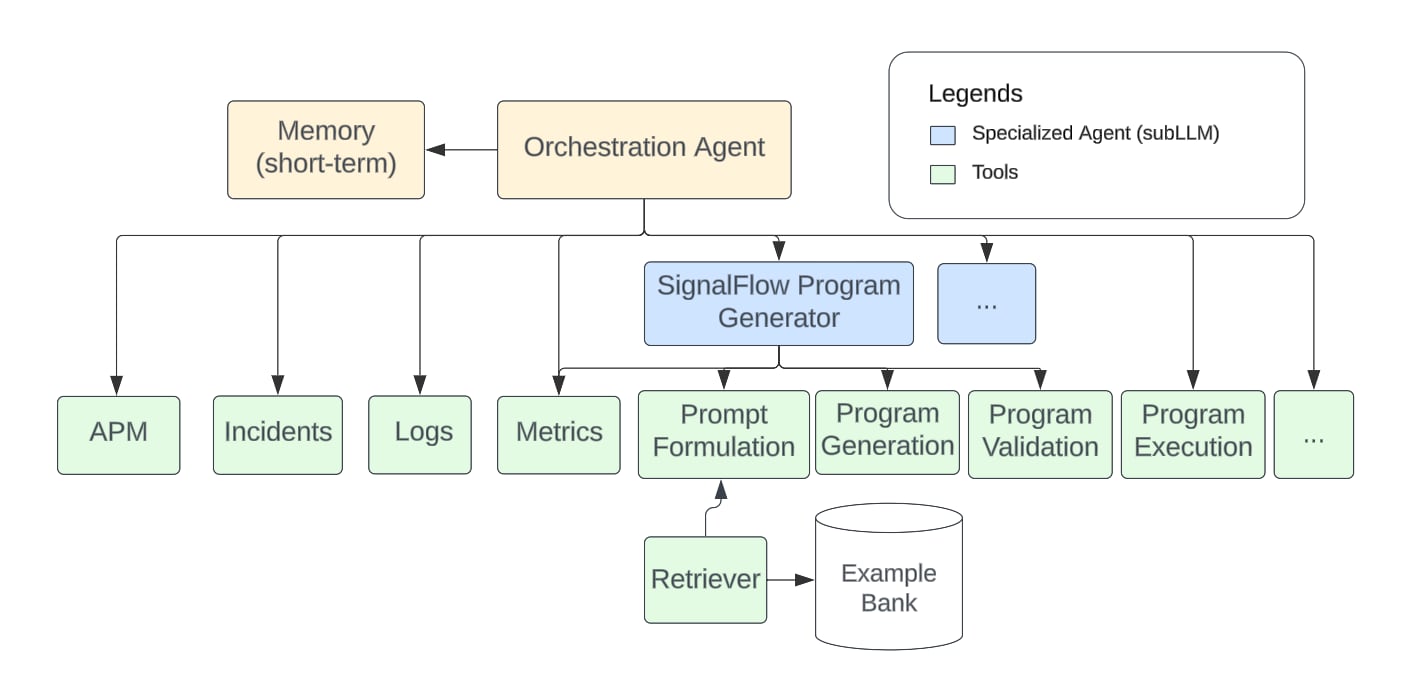
図2:Observability CloudのAI Assistantのアーキテクチャ
このハイブリッド戦略には、以下のような利点があります。
SignalFlowは、Splunk Observability Cloudの中核をなすメトリクス分析エンジンです。これはPythonに似た言語であり、ユーザーは受信したストリーミングデータを変換および分析し、カスタムチャートやディテクターを作成できます。SignalFlowは強力なツールですが、SPLと同様に習得が容易です。Splunkでは、SignalFlowの生成に特化したサブLLMを構築しました。このサブLLMは、ユーザーによる自然言語でのクエリーとタスク説明を基にプログラムを生成することが可能です。たとえば、ユーザーが「平均CPU使用率」について質問すると、エージェントは次のようなSignalFlowプログラムを生成します。
data('cpu.utilization').mean().publish()
AI Assistant for SPLの開発で得た知見から、Chain-of-Thoughtプロンプティングと検索拡張生成(RAG)を活用することで、サブLLMの能力がSignalFlowの中級ユーザーに匹敵するレベルにまで引き上げられ、ある程度の複雑さを持つプログラムを正しく生成できることが分かりました。
タスクの分解、ツールの選択、クエリーの生成に加えて、さまざまなデータタイプ(メトリクス、イベント、ログ、トレース)を処理するLLMの能力についても把握する必要がありました。これまでの取り組みから、以下のような知見が得られました。
エージェントのプロセスに組み込まれるツールの数が多くなると、適切なツールを選択することがより難しくなります。最終的な答えを導くために複数のツールを連鎖的に使う必要があるような複雑なタスクでは、エラーが発生しやすくなります。たとえば、サービスインシデントの一般的なトラブルシューティングでは、以下のような複数ステップのワークフローが必要になります。
環境名 -> サービス名 -> サービストポロジー -> サービスエラー -> ログサーチ
エージェントがこのワークフローに従って関数を順番に正しく呼び出せるのが理想的です。しかし、エージェントが環境名やサービス名を取得せずに、いきなりサービストポロジーの把握から開始するなど、正しく実行できない場合もあります。
ワークフローベースの最適化
複雑なタスクの場合は、一般的なワークフローに従うようオーケストレーションエージェントに指示を与えることで最適化を行います。この最適化には以下の3つのステップがあります。
このようなワークフローベースの最適化を通じて、複雑なツール使用を必要とするタスクのパフォーマンスを向上させることができます。ワークフローの指示を与えることで、エージェントがこうしたタスクに対処するために必要な追加のドメイン知識を得られるためです。
エージェントがツールを使用する際には、キーワードベースのシステムで情報を検索するのが一般的であるため、ユーザーのクエリーから適切な検索語を抽出する必要があります。たとえば、「What is the average disk usage? (平均ディスク使用量は?)」という質問の場合、エージェントは「disk.utilization」メトリクスを取得する必要があります。この場合に必要となる検索語は「disk」と「utilization」ですが、エージェントは通常「disk」と「usage」を検索語として抽出してしまうため、「disk.utilization」を正しく取得できない可能性があります。
そこで、LLMの知識を利用してクエリーを拡張することで、この問題に対処します。具体的には、オブザーバビリティの領域でよく使われる用語の同義語リストを組み込み、これを使って検索語を拡張します。上記の例であれば、候補となる検索語を「disk」、「usage」、「utilization」に拡張することで、検索ツールの再現率を高めることができます。その結果、キーワードベースの検索システムが、セマンティック検索に近い動作をするようになります。
エージェントの評価については、主に2つの課題があります。
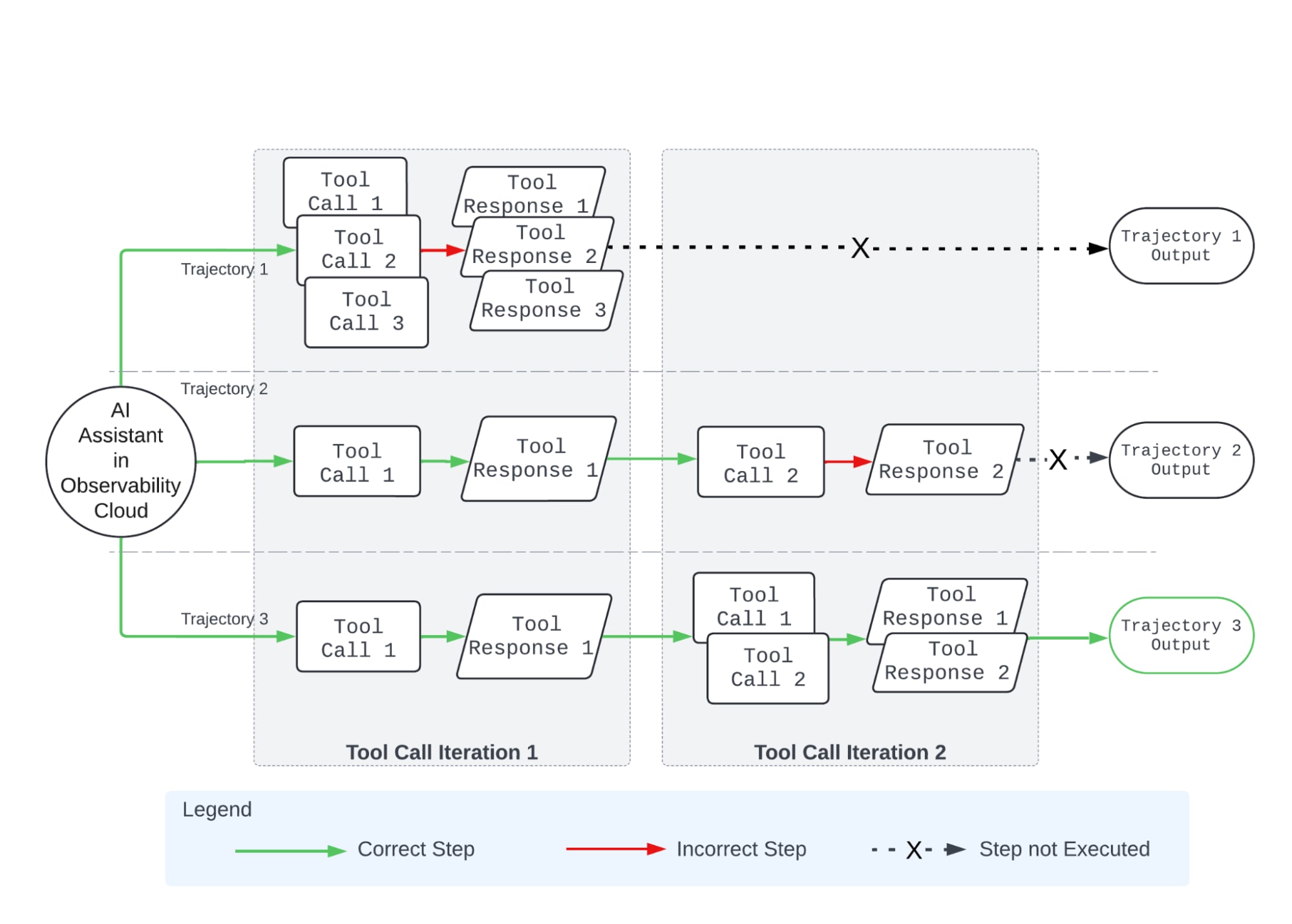
私たちは、データ収集と指標定義の両方について、ツール使用手順に基づくアプローチを開発しました。主な考え方としては、特定のクエリーに関して、まずエージェントを複数回にわたって実行し、次にツール使用手順が同一であるものを集約すると同時に、最終回答を収集します。正解データの収集フェーズでは、複数回の試行によって得られたツール使用手順と回答をすべて収集し、正しい手順と回答を手動で選別します。評価フェーズでは、「ツール使用手順の一致度」と「最終回答の埋め込みベクトルに基づく類似度」という2つの指標を設けました。以下の図は、ツール使用手順の一致を評価する方法を示しています。ツールの使用順序が正解データと完全に一致している場合、それは正しく実行されたと見なされます。最終回答を評価するには、エージェントの回答の埋め込みベクトルと正解データとなる回答との間のコサイン類似度を使用します。
図3:ツール使用手順に基づく評価方法の概要
ユーザーが実際に尋ねる可能性が高い質問の代表例を集めてテストセットを作成し、質問に対するAI Assistantの回答をSplunk Observability Cloud製品における正解と突き合わせて検証しました。システムプロンプト、ツール説明、ワークフローに関してプロンプトエンジニアリングを何度も繰り返すことで、一貫した性能の改善が見られました。AI Assistantは設計通りのビジネス要件を達成し、最高水準のパフォーマンスを発揮しています。
今後、AI Assistantの機能拡張は、主に以下のような方針で検討する予定です。
こうして私たちは、既存のスキルを向上させ、新たなスキルを開発し、それらを組み合わせる新たな方法を模索しています。
総じて、LLMアプリケーションの開発は、従来のソフトウェア開発に比べて、大変刺激的なものでした。入念に作り込んだ指示をシステムプロンプトに追加することで、まったく新しい機能(たとえば、新たなインサイトをもたらす斬新なSignalFlowのプログラムや、通常は専門家並みの製品理解が必要なAPMでの調査など)が実現します。そして、ツールを実装することによって新たなワークフローの可能性を引き出すことができます(たとえば、APMとメトリクスデータ間の移動など)。しかし、時にはもどかしさを感じる場面も経験しました。一見些細な変更をシステムに加えただけで、特定のテストシナリオに驚くほど大きな影響が及ぶこともあります。また、ハルシネーションの問題をなかなか解決できず、コードを直接修正しなければならない場合もありました。同時に、標準的なソフトウェアテストを実施するだけでなく、今後の製品に関する意思決定に活かせるよう、性能評価の仕組みも開発しました。これは最終的に、パイプラインの一部として実装することを想定しています。
Splunk社内でAI Assistantを展開したことにより、ユーザーの要望に関する豊富な知見を得ることができ、焦点を絞って研究開発に取り組むことができました。社内のエンジニアリングチームの一部では、すでにさまざまなユースケースでAI Assistantを活用しています。たとえば、新しいチームメンバーがシステムを理解できるようサポートしたり、本番環境で発生した問題を詳しく分析したりするなど、幅広い用途で役立っています。私たちは、今後ユーザーがAI Assistantをどのように利用し、どのようなユースケースに取り組みたいと考えているかを把握することで、AI Assistantのスキルやワークフローのさらなる拡張を目指します。
共同執筆者/寄稿者:
Joseph Rossは、Splunkのシニアプリンシパルアプライドサイエンティストを務めており、オブザーバビリティ分野の問題にAIを応用する研究に取り組んでいます。コロンビア大学で数学の博士号を取得しています。
Om Rajyaguruは、Splunkのアプライドサイエンティストで、主にマルチエージェントLLMシステムの設計、ファインチューニング、評価に取り組むとともに、時系列クラスタリング問題にも携わっています。2022年6月に応用数学と統計学の学士号を取得し、研究ではディープニューラルネットワークのマルチモーダル学習と低ランク近似法に焦点を当てていました。
Liang Gouは、SplunkのAI担当ディレクターとして、オブザーバビリティとエンタープライズアプリケーションを主軸とした生成AIイニシアチブに取り組んでいます。ペンシルベニア州立大学で情報科学の博士号を取得しています。
Kristal Curtisは、Splunkでプリンシパルソフトウェアエンジニアとして、エンジニアリングとAIサイエンスを組み合わせたプロジェクトに従事しています。いずれも、AIをSplunk製品に統合し、より使いやすく、ユーザーのデータやシステムに関するより強力なインサイトを提供することを目指しています。Splunkに入社する前は、カリフォルニア大学バークレー校でコンピューターサイエンスの博士号を取得し、RADおよびAMPラボで、David Patterson氏とArmando Fox氏の指導のもと研究を行っていました。
Akshay Mallipeddiは、Splunkのシニアアプライドサイエンティストです。主にObservability CloudのAI Assistantの強化に取り組んでおり、大規模言語モデルに不可欠なデータ統合の側面を改善するための戦略を策定しています。また、大規模言語モデルのファインチューニングにも携わっています。ニューヨーク州ストーニーブルック大学でコンピューターサイエンスの修士号を取得しています。
Harsh Vashishtaは、Splunkのシニアアプライドサイエンティストを務めており、Observability CloudのAI Assistantに携わっています。メリーランド大学ボルチモア郡校でコンピューターサイエンスの修士号を取得しています。
Christopher Lekasは、Splunkのプリンシパルソフトウェアエンジニアであり、Observability CloudのAI Assistantの品質責任者を務めています。スワースモア大学でコンピューターサイエンスと経済学の学士号を取得しています。
Amin Moshgabadiは、Splunkのシニアプリンシパルソフトウェアエンジニアです。サイモンフレイザー大学で応用科学の学士号を取得しています。
Akila Balasubramanianは、プリンシパルソフトウェアエンジニアであり、Splunk Observability CloudのAI Assistantの技術責任者です。大規模展開されたアプリケーションの健全性とパフォーマンスを監視するのに役立つ製品の開発に熱心に取り組んでいます。また、製品を自ら試用することを信条とし、お客様と緊密な協力関係を築いて、率直なフィードバックを得ることを心がけています。自身の分析力と創造力を駆使して問題を解決することに情熱を持ち、品質を何よりも重視しています。イリノイ大学でコンピューターサイエンスの修士号を取得しています。
Sahinaz Safariは、製品管理のディレクターであり、オブザーバビリティ分野におけるAIの責任者です。オブザーバビリティ分野で長年にわたり、最先端テクノロジーを基盤とする革新的な製品の構築と拡張に従事してきました。スタンフォード大学で電気工学の修士号を、カリフォルニア大学バークレー校でMBAを取得しています。

© 2005 - 2026 Splunk LLC 無断複写・転載を禁じます。
© 2005 - 2026 Splunk LLC 無断複写・転載を禁じます。
