
Ein Fahrplan zu digitaler Resilienz im Unternehmen
Zunächst einmal möchte ich euch für das anhaltende Interesse an meinen Blogbeiträgen danken. Bei meinen letzten .conf-Vorträgen habe ich viel positives Feedback bekommen und bin gebeten worden, mehr Beiträge mit Inhalten dieser Art zu veröffentlichen. Das ist natürlich eine großartige Motivation, um weiterzumachen. Kürzlich hat mein Kollege Dimitris einen Beitrag über die Einrichtung von DLTK auf einer AWS-GPU-Instanz geschrieben. In diesem Artikel möchte ich euch nun drei interessante neue Algorithmusmethoden vorstellen, die in der neuesten Version der Deep Learning Toolkit (DLTK) App für Splunk verfügbar sind:
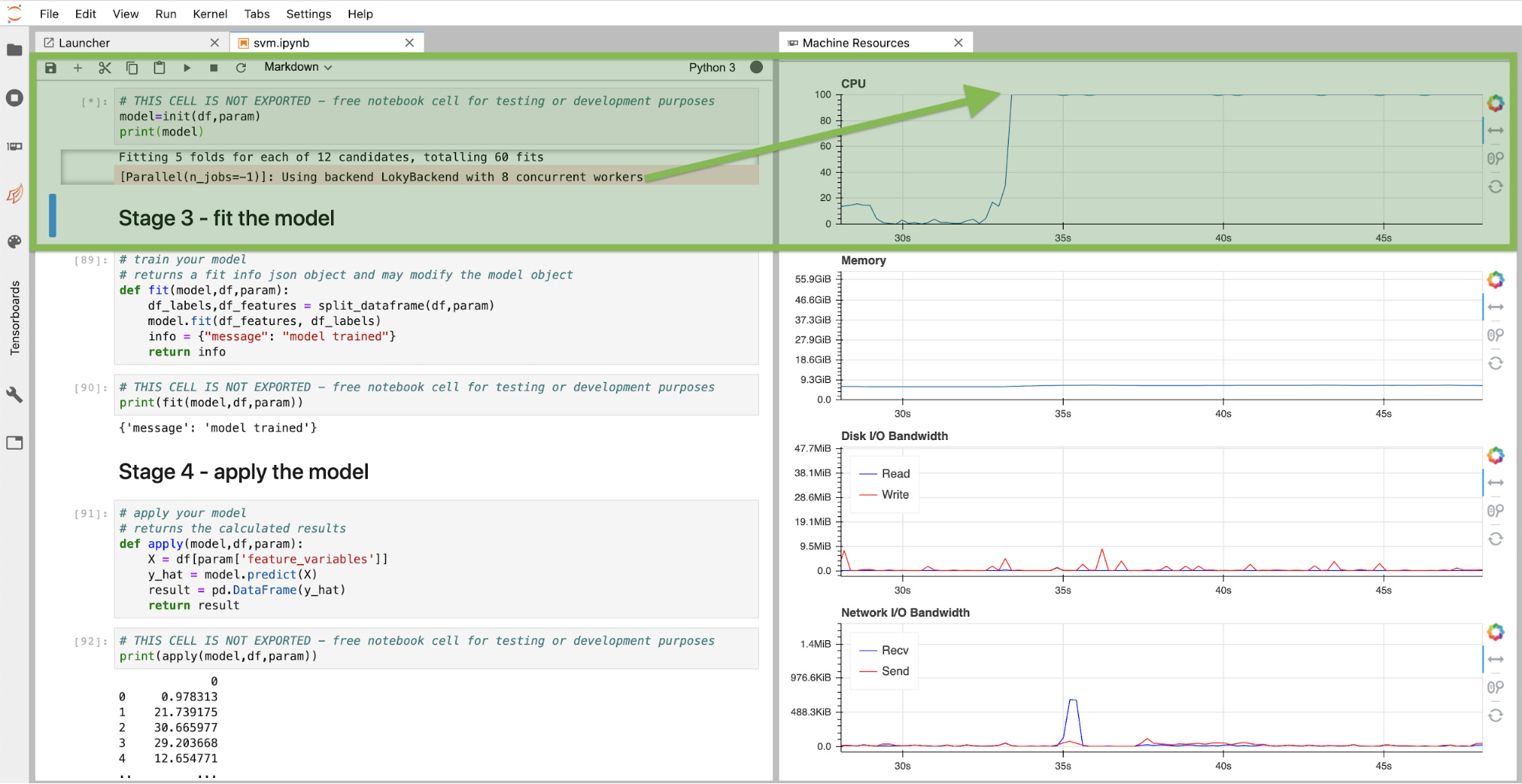
Kunden, die an Machine Learning-Modellen arbeiten, stellen uns häufig die Frage, wie sie innerhalb gegebener Einschränkungen das optimale Modell und die zugehörigen Parameter finden können. Hyperparameteroptimierung ist der Fachbegriff für diesen Prozess, für den es unterschiedliche Herangehensweisen gibt. Eine einfache Möglichkeit ist das Definieren von Bereichen für Hyperparameter und das Trainieren von Modellen für alle Kombinationen. Durch die Validierung der einzelnen Modelle anhand der Testdaten kristallisiert sich schließlich das Modell mit der höchsten Bewertung und den entsprechenden Hyperparametern heraus. Und schon habt ihr das optimale Modell gefunden. Dies kann natürlich ein sehr rechenintensiver Prozess sein, für den aber glücklicherweise in den meisten Fällen viele CPU-Kerne (oder GPU-Kerne) parallel genutzt werden können. Mein Kollege Phil Salm hat vor kurzem an einem solchen Beispiel gearbeitet und wir stellen es euch gern im Rahmen des DLTK zur Verfügung. Ihr könnt es direkt für eure Use Cases oder für die Optimierung eurer Modelle verwenden. Ihr könnt die Rastersuche direkt im JupyterLab-Notebook des DLTK ausführen, wie unten dargestellt. Bei dieser Instanz standen acht CPU-Kerne für die gleichzeitige Ausführung der Rastersuche zur Verfügung. Wie ihr auf den Monitoringpanels für Systemressourcen ablesen könnt, sind die CPU voll ausgelastet.
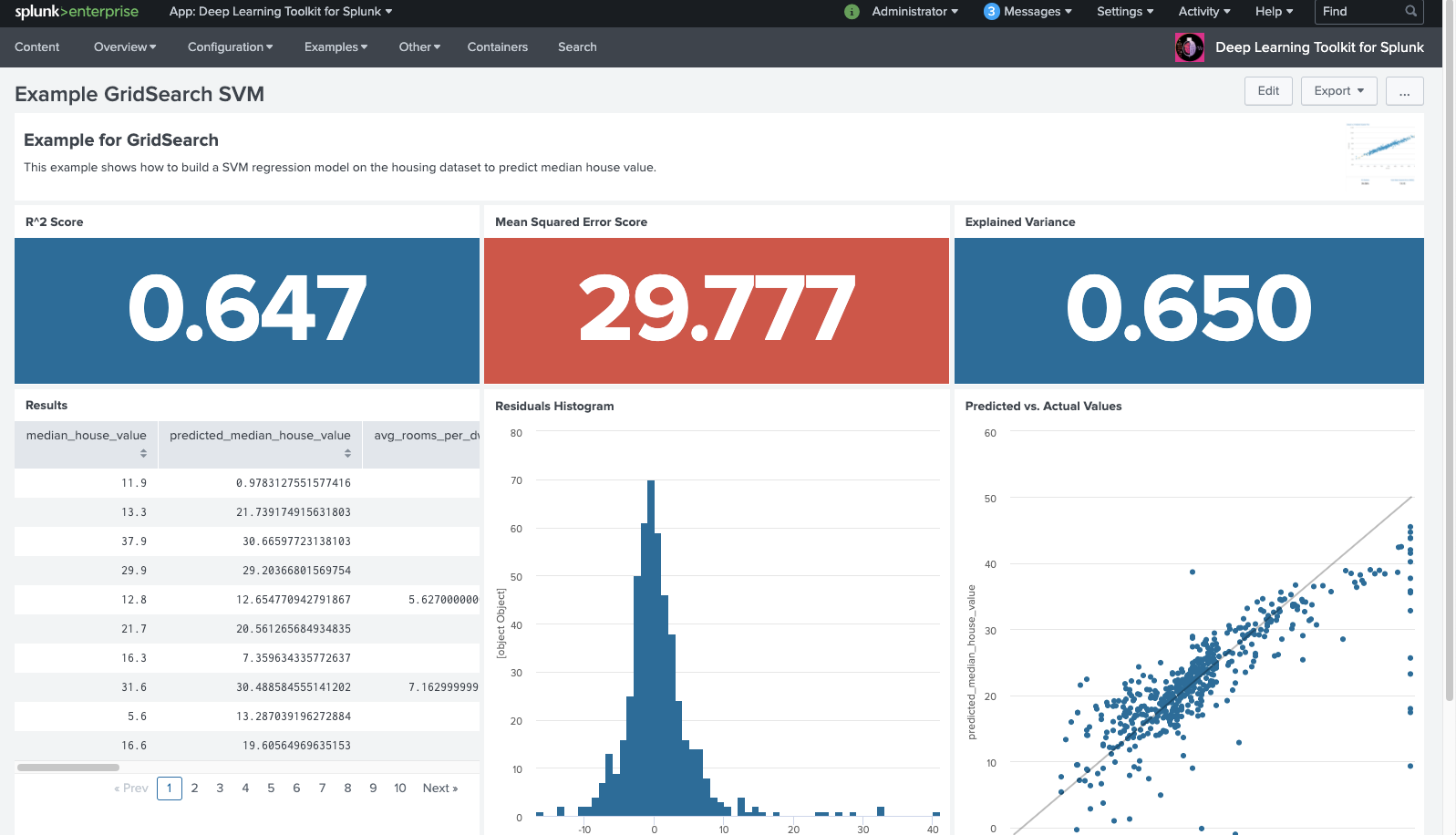
Ihr könnt den auf der Rastersuche basierenden Algorithmus weiter automatisieren und direkt implizit aus der Splunk-Suche aufrufen, das optimale Modell trainieren, auswählen und auf eure Daten anwenden lassen. Auf dem folgenden Screenshot seht ihr, wie die Prognose-Ergebnisse auf dem Beispiel-Dashboard im DLTK zurückgegeben und bewertet werden:
Das Konzept der Rastersuche ist natürlich nicht nur für eine Support Vector Machine anwendbar, sondern lässt sich leicht auf andere Algorithmen von Scikit-learn oder anderen Machine Learning-Frameworks ausweiten. Anhand dieses Beispiel-Notebooks solltet ihr problemlos in der Lage sein, das Konzept an euren Modellierungsbedarf anzupassen.
Vor kurzem hat mein Kollege Greg Ainslie-Malik in seinem Blog „Causal Inference: Determining Influence in Messy Data“ (Kausale Inferenz: Einflüsse in ungeordneten Daten bestimmen) anschaulich erklärt, wie ihr die von QuantumBlack Labs veröffentlichte Bibliothek causalnex im DLTK einrichten und nutzen könnt. Da dieser Algorithmus für viele Anwendungen nützlich sein kann, versteht es sich von selbst, dass wir Gregs Arbeit mit einem kombinierten Splunk-Dashboard und Jupyter Notebook im DLTK als Beispiel zur Verfügung gestellt haben, das sich leicht nachahmen lässt:
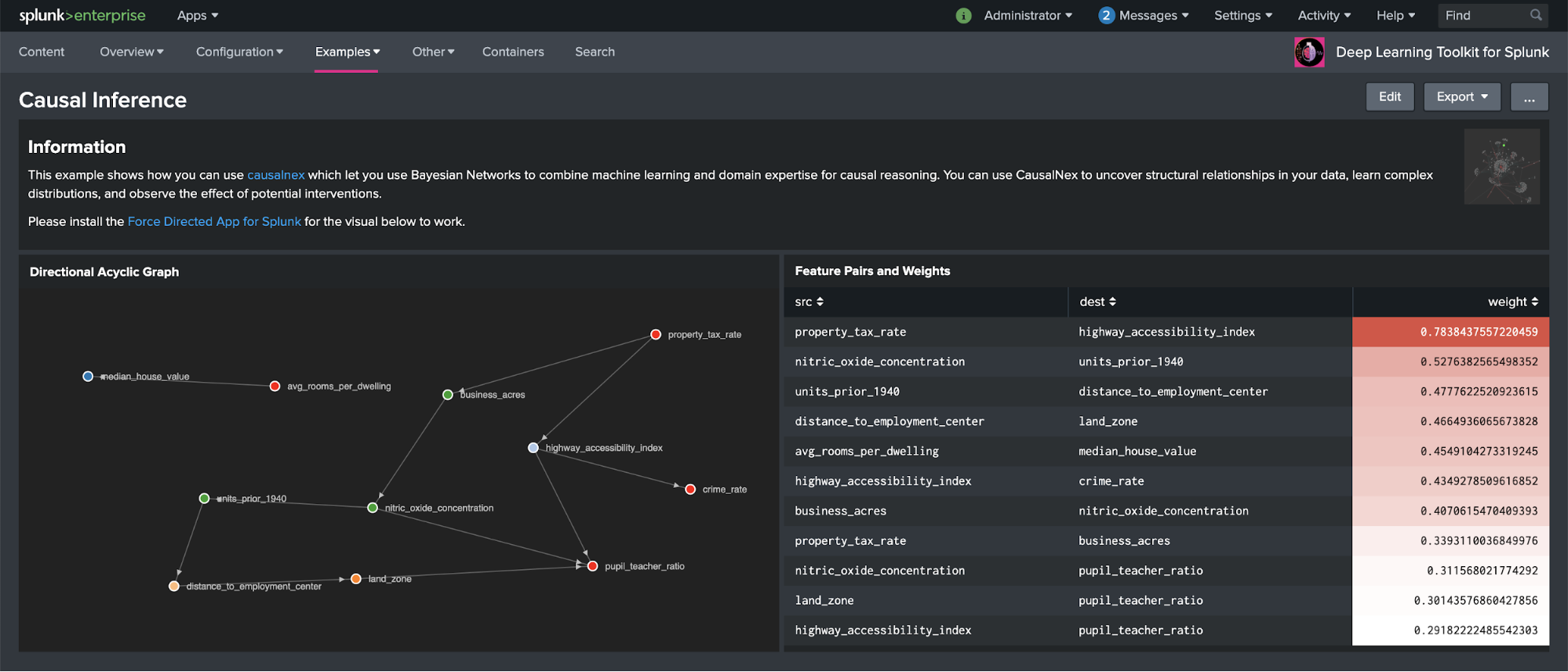
Auf dem obigen Beispiel-Dashboard ist zu sehen, wie die Features in dem Housing-Dataset, das im Splunk Machine Learning Toolkit enthalten ist, miteinander in Beziehung stehen. Die Beziehungen werden in einem Graphen im linken Teilfenster, die Gewichtung der einzelnen Feature-Paare im rechten Teilfenster des Dashboards dargestellt. Anhand dieses Beispiels solltet ihr problemlos in der Lage sein, diese Methode auf beliebige eigene Daten anzuwenden und interessante Beziehungen zu entdecken. Dafür nutzt ihr einfach die entsprechende SPL-Abfrage und führt dann causalnex aus. Dieser Ansatz kann auch nützlich sein, wenn es auf die Erklärbarkeit von Machine Learning-Modellen ankommt. Weiterhin lassen sich so andere Techniken wie SHAP ergänzen. Darauf bin ich kürzlich in meinem letzten Blogbeitrag „Deep Learning Toolkit 3.3 - Examples for Explainable AI and XGBoost“ (Deep Learning Toolkit 3.3 – Beispiele für erklärbare KI und XGBoost) eingegangen.
Viele Kunden von Splunk verfügen über umfangreiche Logdatenbestände. Diese Daten können sehr wertvolle Informationen über die technischen oder geschäftlichen Prozesse enthalten, die diese Logs generieren. Process Mining hilft beim Aufdecken und Modellieren dieser Prozesse und macht sie für weitere Analysen und Untersuchungen zugänglich. Im folgenden Beispiel wird ein vollständiger Workflow dargestellt, der zeigt, wie ihr die Search Processing Language (SPL) von Splunk nutzen könnt, um relevante Felder aus Rohdaten abzurufen, und wie ihr sie in Kombination mit Process Mining-Algorithmen zur Prozesserkennung verwenden und die Ergebnisse auf einem Dashboard visualisieren könnt:
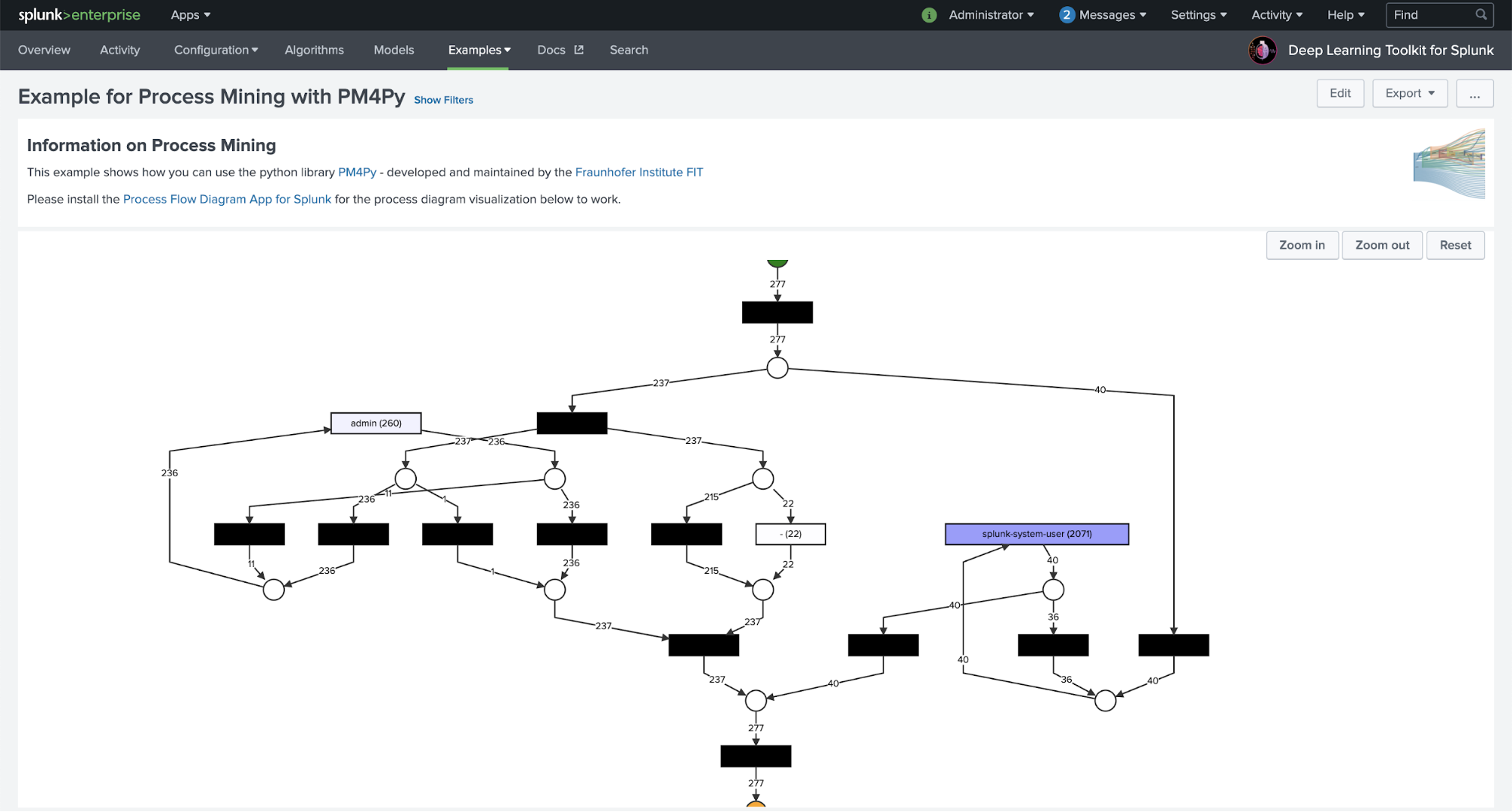
Mit dem DLTK könnt ihr problemlos beliebige Python-basierte Bibliotheken nutzen, beispielsweise eine hochmoderne Process Mining-Bibliothek namens PM4Py. Sie wird vom Fraunhofer-Institut für Angewandte Informationstechnik entwickelt und gepflegt und ich möchte mich an dieser Stelle noch einmal bei der Process Mining-Gruppe für die Unterstützung und die sehr hilfreichen Rückmeldungen bedanken. Dieses Beispiel kratzt tatsächlich nur an der Oberfläche dieser leistungsstarken Bibliothek. In der PM4Py-Dokumentation könnt ihr noch viele weitere Funktionen entdecken und problemlos Anpassungen nach euren Bedürfnissen und Process Mining-Anwendungsfällen vornehmen.
Macht euch die hier dargestellte Visualisierung neugierig? Ein großes Lob an unser fantastisches Team für Forward Deployed Software Engineering! Mein Kollege Daniel Federschmidt hat kürzlich die App Process Flow Visualization for Splunk auf GitHub veröffentlicht. Damit könnt ihr solche Prozessdiagramme im Handumdrehen auf einem Splunk-Dashboard anzeigen. Sie kann Eingabedaten aus einer SPL-Suche übernehmen oder direkt die Ergebnisse eines PM4Py-basierten Process Mining-Algorithmus darstellen, der im DLTK ausgeführt wird. Damit solltet ihr einige gute Ansatzpunkte für eure spezifischen Use Cases für Process Mining haben, die ihr in Splunk auf eure Daten anwenden könnt.
Wenn ich auf die letzte Zeit zurückblicke, kann ich persönlich sagen, dass diese von der produktiven und dynamischen Zusammenarbeit mit zahlreichen Kunden gekennzeichnet war. Eines meiner Highlights stellt auf jeden Fall ein Use Case des Innovation Lab der BMW Group dar, bei dem es um die Entwicklung einer prädiktiven Teststrategie unter Verwendung eines Deep Learning-Ansatzes mit DLTK ging. Ein großes Dankeschön geht nochmal raus an Marc Kamradt, Andreas Schoch und ihr Team für die großartige Zusammenarbeit innerhalb dieses Projekts.
Mit den verschiedenen in SplunkBase bereitgestellten Versionen des DLTK ist eine breite Palette von fortschrittlichen Algorithmen, Tools, Frameworks und Use Cases für Machine Learning und Deep Learning direkt und bequem für Splunk-Nutzer verfügbar. Infos zu allen anderen Innovationen findet ihr in meinen anderen Blogs, falls ihr sie noch nicht gelesen habt.
Zu guter Letzt möchte ich die Gelegenheit nutzen, um allen aktiv Mitwirkenden, Kollegen und der großen Splunk-Community für die Unterstützung dieser Initiative zu danken! Anlässlich der .conf20 haben wir DLTK Version 4.0 als Open-Source-App auf GitHub bereitgestellt. Das ist hoffentlich eine zusätzliche Erleichterung für alle, die aktiv am DLTK mitwirken möchten. Ihr seid herzlich eingeladen, Ideen oder offene Fragen zu posten oder euch einfach bei uns zu melden.
Niemand weiß, was die Zukunft bringt, aber ein Blick auf die Splunk Technologieprognosen für 2021 lohnt sich in jedem Fall. Für mich gilt 2021 nach wie vor: Lasst es uns zum Jahr des Kunden machen!
Bleibt gesund und passt auf euch auf!
– Philipp
Ein besonderer Dank geht an die Process Mining-Gruppe des Fraunhofer-Instituts für Angewandte Informationstechnik für die großartige Unterstützung und die wertvollen Tipps zu PM4Py und an meinen Kollegen Daniel Federschmidt aus dem Splunk-Team für Forward Deployed Software Engineering für seine fantastische neue Prozessflussvisualisierung. Und zu guter Letzt noch vielen Dank an meine Kollegen Greg Ainslie-Malik und Phil Salm, Machine Learning Architects, für ihre wertvollen Beiträge zur Entwicklung neuer, nützlicher Machine Learning- und Analysetechniken. Damit wird es Splunk-Kunden ermöglicht, Daten in Taten zu verwandeln.
*Dieser Artikel wurde aus dem Englischen übersetzt und editiert. Den Originalblogpost findet ihr hier: Deep Learning Toolkit 3.4: Grid Search, Causal Inference and Process Mining.

Die führenden Unternehmen der Welt vertrauen auf Splunk, einem Unternehmen von Cisco, um ihre digitale Resilienz mit der einheitlichen Sicherheits- und Observability-Plattform, unterstützt durch branchenführende KI, kontinuierlich zu stärken.
Unsere Kunden setzen auf die preisgekrönten Sicherheits- und Observability-Lösungen von Splunk, um die Zuverlässigkeit ihrer komplexen digitalen Umgebungen zu sichern und zu optimieren – in jeder Größenordnung.

© 2005 - 2026 Splunk LLC All rights reserved.
© 2005 - 2026 Splunk LLC All rights reserved.