
Ein Fahrplan zu digitaler Resilienz im Unternehmen

Es gibt spannende News rund um das Deep Learning Toolkit (DLTK): Die Splunk App wird jetzt unter dem Namen Splunk App for Data Science and Deep Learning (DSDL) geführt. Das klingt jetzt vielleicht nicht ganz so griffig, spiegelt aber besser die beiden Use Cases wider, für die die App konzipiert ist. Neuerungen gibt es aber nicht nur beim Namen: Die Splunk App for Data Science and Deep Learning 5.0 hat ab sofort den offiziellen Status „Splunk Supported“. Wer die App herunterlädt, kann bei Problemen nun also einfach via Ticket Unterstützung bei unserem Team anfordern.
 Für mich persönlich markiert dies hier einen bedeutenden Meilenstein einer ziemlich beachtlichen Entwicklung. Denn als ich das Projekt 2018 ins Leben rief, wollte ich eigentlich nur die technische Umsetzbarkeit davon ausloten, inwieweit sich innerhalb von Docker-Containern Deep-Learning-Modelle auf GPUs ausführen und dabei an Splunk anbinden lassen. Noch im gleichen Jahr wurde auf der .conf18 mit dem MLTK Container für TensorFlow das vorgestellt, was dann schließlich den Grundstein für das Deep Learning Toolkit bildete, das seit der .conf19 als Splunk App auf Splunkbase kostenlos zur Verfügung steht. Ein Jahr darauf kam mit der DLTK 4.0 zudem ein Update mit einer komplett überarbeiteten App-Architektur dazu, das auf Open-Source-Quellen verfügbar gemacht wurde. Recht herzlich bedanken möchte ich mich an dieser Stelle bei meinem Freund und ehemaligen Kollegen Robert Fujara, der diese Entwicklung durch seinen Einsatz entscheidend mitgeprägt hat. Innerhalb von gerade einmal 5 Jahren ist so aus einem vermeintlich unbedeutenden Prototypen eine App mit bis dato mehr als 7.000 Downloads auf Splunkbase herangewachsen, die von einer breiten Userbase zur Integration komplexer Methodiken rund um Data Science, Machine Learning und Deep Learning in Splunk genutzt wird. Möglich gemacht haben dies nicht zuletzt auch diverse Unterstützer und Förderer, die von Konzeptvorschlägen bis hin zu Ergänzungen des Quellcodes aktiv Verbesserungen in das Projekt einbrachten. Allen diesen Menschen gilt mein Dank für den herausragenden Support – und gerne möchte ich diese Zusammenarbeit auch weiterhin fortführen. Wer möchte, kann sich hierzu bitte jederzeit bei mir melden.
Für mich persönlich markiert dies hier einen bedeutenden Meilenstein einer ziemlich beachtlichen Entwicklung. Denn als ich das Projekt 2018 ins Leben rief, wollte ich eigentlich nur die technische Umsetzbarkeit davon ausloten, inwieweit sich innerhalb von Docker-Containern Deep-Learning-Modelle auf GPUs ausführen und dabei an Splunk anbinden lassen. Noch im gleichen Jahr wurde auf der .conf18 mit dem MLTK Container für TensorFlow das vorgestellt, was dann schließlich den Grundstein für das Deep Learning Toolkit bildete, das seit der .conf19 als Splunk App auf Splunkbase kostenlos zur Verfügung steht. Ein Jahr darauf kam mit der DLTK 4.0 zudem ein Update mit einer komplett überarbeiteten App-Architektur dazu, das auf Open-Source-Quellen verfügbar gemacht wurde. Recht herzlich bedanken möchte ich mich an dieser Stelle bei meinem Freund und ehemaligen Kollegen Robert Fujara, der diese Entwicklung durch seinen Einsatz entscheidend mitgeprägt hat. Innerhalb von gerade einmal 5 Jahren ist so aus einem vermeintlich unbedeutenden Prototypen eine App mit bis dato mehr als 7.000 Downloads auf Splunkbase herangewachsen, die von einer breiten Userbase zur Integration komplexer Methodiken rund um Data Science, Machine Learning und Deep Learning in Splunk genutzt wird. Möglich gemacht haben dies nicht zuletzt auch diverse Unterstützer und Förderer, die von Konzeptvorschlägen bis hin zu Ergänzungen des Quellcodes aktiv Verbesserungen in das Projekt einbrachten. Allen diesen Menschen gilt mein Dank für den herausragenden Support – und gerne möchte ich diese Zusammenarbeit auch weiterhin fortführen. Wer möchte, kann sich hierzu bitte jederzeit bei mir melden.
Splunk Nutzer setzen zumeist auf UI-Elemente wie die Suchleiste und Dashboards. Viele Data Scientists ziehen zum Experimentieren und Modellieren aber dennoch Jupyter Notebooks vor. DSDL spannt hier die Brücke mit einem Workflow, der beide Interfaces nahtlos zusammenführt und so die Operationalisierung von Data-Science- und anderen Forschungsprojekten in Splunk erleichtert und beschleunigt.
Hierzu können via Splunk Search Processing Language (SPL) beliebige Jupyter- und Python-Frameworks und -Bibliotheken wie etwa matplotlib oder seaborn genutzt werden, um Visualisierungen und andere zentrale Aufgaben für Data-Science-Kontexte einzurichten. Mit der SPL als Herzstück wird damit das Beste der Welt von Splunk mit der weitreichenden Flexibilität verbunden, die Jupyter bzw. Python in Sachen Data Science bietet. Die dem zugrunde liegende Architektur (siehe Abblidung unten) blieb auf dem Weg zur Umsetzung der DSDL im Wesentlichen unverändert, wurde jedoch sukzessive um funktionale Verbesserungen und Erweiterungen der Schnittstellen ergänzt.
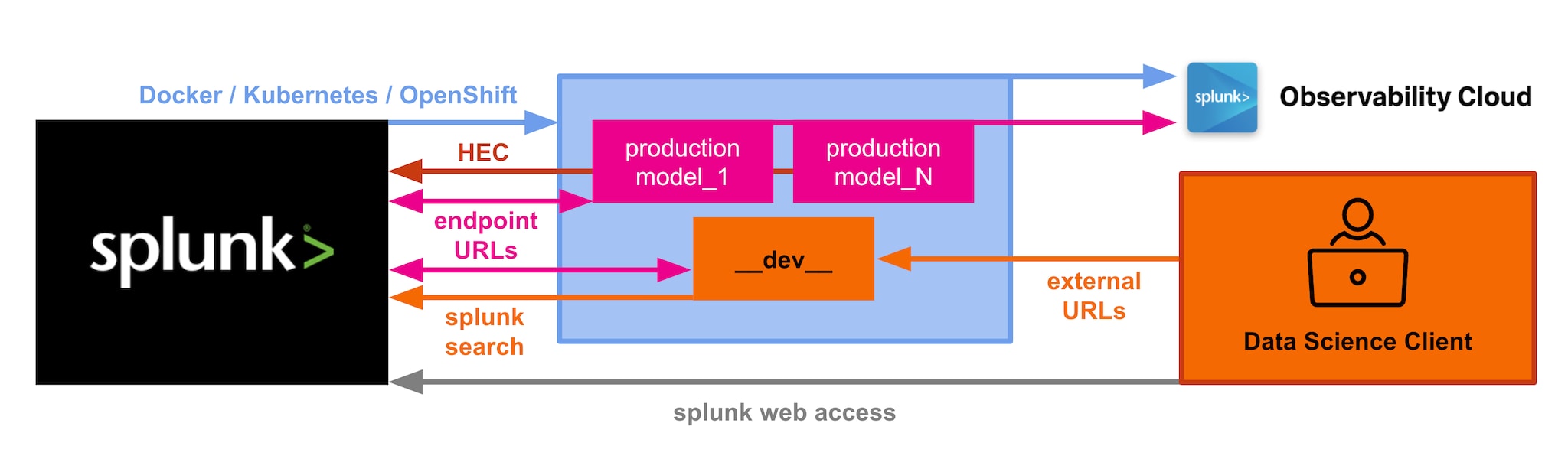
Mit Version 3.9 z. B. wurde neben einer interaktiven Splunk Suchleiste in Jupyter ein äußerst nützliches Standardverfahren implementiert, anhand dessen via HTTP Event Collector (HEC) Daten aus Jupyter- oder Python-Code in Form von Logs direkt an Splunk übermittelt werden können. In Aktion könnt Ihr diese Funktionen über das Jupyter-Notebook barebone_template.ipynb in eurem Entwicklungs-Container. Neuerungen gab es zudem mit einem Beispiel-Szenario zur Anomalie-Erkennung, bei dem mit der gestützt auf die PyOD-Bibliothek ein äußerst leistungsfähiger Algorithmus zum Einsatz kommt. Weiter optimiert wurden zudem MLOps-Kontexte, indem sich DSDL-basierte Container-Modelle automatisch instrumentieren lassen: Ergänzt Ihr die dabei erfassten Kennzahlen in Container-Umgebung, erhaltet ihr ein äußerst differenziertes Bild eurer Data-Science-, Machine-Learning- oder Deep-Learning-Operationen direkt in der Splunk Observability Suite. Durch erweiterte Konfigurationsoptionen für Ingress-Vorgänge in Kubernetes-Deployments wurde zudem die Ntzung von Splunk und DSDL-Containern innerhalb eines Clusters (z. B. via Splunk Operator for Kubernetes) nahtloser gestaltet
Bei Version 5.0 haben wir den Fokus insbesondere darauf gelegt, die Prozesse rund um die DSDL-App noch sicherer und effizienter zu gestalten. So ist nun erstmals eine Dokumentation auf den offiziellen Splunk doc Seiten verfügbar. Mein persönlicher Dank gilt Emma Lauder und ihrem Team, die dabei Herausragendes geleistet haben – ganz offensichtlich gibt es hier Personen, die die Konzepte hinter DSDL noch besser verstehen als ich selbst. Im Zuge dessen wurden zudem eine Reihe von Nachbesserungen im Hinblick auf die Strukturierung der App-Inhalte eingesteuert.
Weiter wurden für Container-Images die neuesten Updates und Fixes implementiert. Auch stellte sich heraus, dass viele Kunden ihre eigenen Container-Images erstellen wollten. Hierzu haben wir eine geführte und mit einem Mausklick ausführbares Feature zur Erstellung von Docker-Images in die UI eingeführt: Damit lassen sich Container-Images mühelos erstellen und an die jeweils bevorzugten Data Science-Bibliotheken in Python anpassen. Zudem brachten einige Kunden das Anliegen vor, Netzwerke leichter erstellen zu können. Dies erfüllt Version 5.0 mit dem neuen Neural Network Designer. Dieser vordefinierte Workflow ermöglicht es Splunk-Benutzern, neuronale Netze für ihre Splunk-Daten auf unkomplizierte Weise zu definieren, zu erstellen, zu trainieren, anzuwenden und zu bewerten. Ich hoffe, dieses Feature ist nützlich für euch. Vorschläge und Anregungen dazu nehme ich jederzeit gerne entgegen.
Möglich ist nun außerdem die Nutzhung komplexer Data-Science-Methoden für Use Cases im Bereich der Cybersicherheit. Mein Kollege Josh Cowling hat hierzu ein Juypter Notebook und eine Beispiel für ein Splunk Dashboard in DSDL erstellt, das zeigt, wie Host-Systeme mithilfe der UMAP-Dimensionalitätsreduktion auf JA3-Signaturen geclustert werden können. Dies sorgt für ein besseres Versändnis verschiedener Verhaltensmuster und damit verbundener Anomalien, die wiederum interessante Hinweise für Untersuchungen im Zusammenhang mit Angriffen auf die Lieferkette liefern, wie sie das Splunk SURGe-Team beschreibt.
Unbedingt erwähnt werden muss zudem ein neuer Feature-Beitrag, der die Nutzung von Splunk Enterprise Security zur Erkennung von DGA-Domains mit einem vorab trainierten Modell in der DSDL App ermöglicht. Dies stellt einen neuen Ansatz zur Erkennung von DGAs über ein ebenso breit wie tief angelegtes neuronales Netzes dar. Wie hier modernste Deep Learning-Verfahren zur Stärkung der Cybersicherheit angewendet werden, ist wirklich extrem spannend zu sehen. Umso größere Anerkennung verdienen Namratha Sreekanta, Kumar Sharad, Glory Avina und das ganze Security Threat Research Team für diesen Beitrag und Einsatz. Jüngst war zudem eine Integration der DSDL App in Attack Range zu vermelden – hierzu an dieser Stelle noch einmal herzlichen Dank an Patrick Bareiss, Jose Hernandez und das Team für die hervorragende Zusammenarbeit!
Ihr seht also: Die Entwicklungen rund um die DSDL App und die Community hinter ihr sind äußerst dynamisch. Falls Ihr die App noch nicht kennen solltet, ladet sie euch am besten direkt über Splunkbase herunter bzw. installiert sie – dies natürlich vollkommen kostenlos. Sofern Ihr die DSDL App oder ihren Vorgänger bereits nutzt, könnt ihr sie einfach aktualisieren. Erstellt zuvor aber sicherheitshalber ein Backup eurer Arbeit und testet alles auf Herz und Nieren, insbesondere bei Use Cases, in der Ihr die DSDL App in Produktionsumgebungen nutzt.
Viel Spaß beim Splunken und beim Gestalten neuer Innovationen mit DSDL,
Philipp
Ein besonderer Dank geht an Emma Lauder, Namratha Sreekanta, Kumar Sharad, Glory Avina, Patrick Bareiss, Jose Hernandez, Josh Cowling, Marcus LaFerrera, Ryan Kovar, Greg Ainslie-Malik und allen anderen Splunk-Kollegen für ihre Unterstützung und ihre Beiträge zu DSDL. Danke auch an Judith Silverberg-Rajna, Katia Arteaga, Mina Wu und Carleanne O'Donoghue für ihre Unterstützung beim Redigieren und Veröffentlichen dieses Blog-Beitrags.

Die führenden Unternehmen der Welt vertrauen auf Splunk, einem Unternehmen von Cisco, um ihre digitale Resilienz mit der einheitlichen Sicherheits- und Observability-Plattform, unterstützt durch branchenführende KI, kontinuierlich zu stärken.
Unsere Kunden setzen auf die preisgekrönten Sicherheits- und Observability-Lösungen von Splunk, um die Zuverlässigkeit ihrer komplexen digitalen Umgebungen zu sichern und zu optimieren – in jeder Größenordnung.

Die neuesten Artikel von Splunk, direkt im eigenen Posteingang.
© 2005 - 2026 Splunk LLC All rights reserved.
© 2005 - 2026 Splunk LLC All rights reserved.