
Digitale Resilienz zahlt sich aus
Wie resilient ist eure Organisation? In diesem kostenlosen Leitfaden erfahrt ihr, wie ihr eure digitale Resilienz steigern könnt.

Mit der Veröffentlichung von GitHub Copilot und anderen LLMs im letzten Jahr wurde uns klar, dass bei der Verarbeitung natürlicher Sprache und der Codegenerierung eine stille Revolution ihren Anfang nahm. Wir nutzten diese aktuellen Entwicklungen, um „SPL Copilot for Splunk (beta)“ zu entwickeln, ein Sprachmodell, das dafür optimiert war, in Englisch geschriebenen Text in SPL-Abfragen in Splunks Search Processing Language (SPL) zu übersetzen. Mit SPL könnt eure Maschinendaten, Security-Ereignisse und Observability-Logs durchsuchen und analysieren. SPL erfordert jedoch einen gewissen Einarbeitungsaufwand – leichter wird es mit dieser auf der .conf22 veröffentlichten Beta-Version.
Seit letztem Jahr konnte man einen Innovationsschub sowohl in der Wissenschaft als auch bei privaten Forschungslaboren beobachten, und die Nutzung von KI bei alltäglichen Aufgaben hat in rasantem Tempo zugenommen. Dank Early Adoptern und der kontinuierlichen Produktverbesserung konnten wir SPL Copilot for Splunk so optimieren, dass er eine viel umfassendere interaktive Umgebung für Splunk und SPL bietet. Außerdem haben wir ihn in diesem Zuge in „Splunk AI Assistant“ umbenannt.
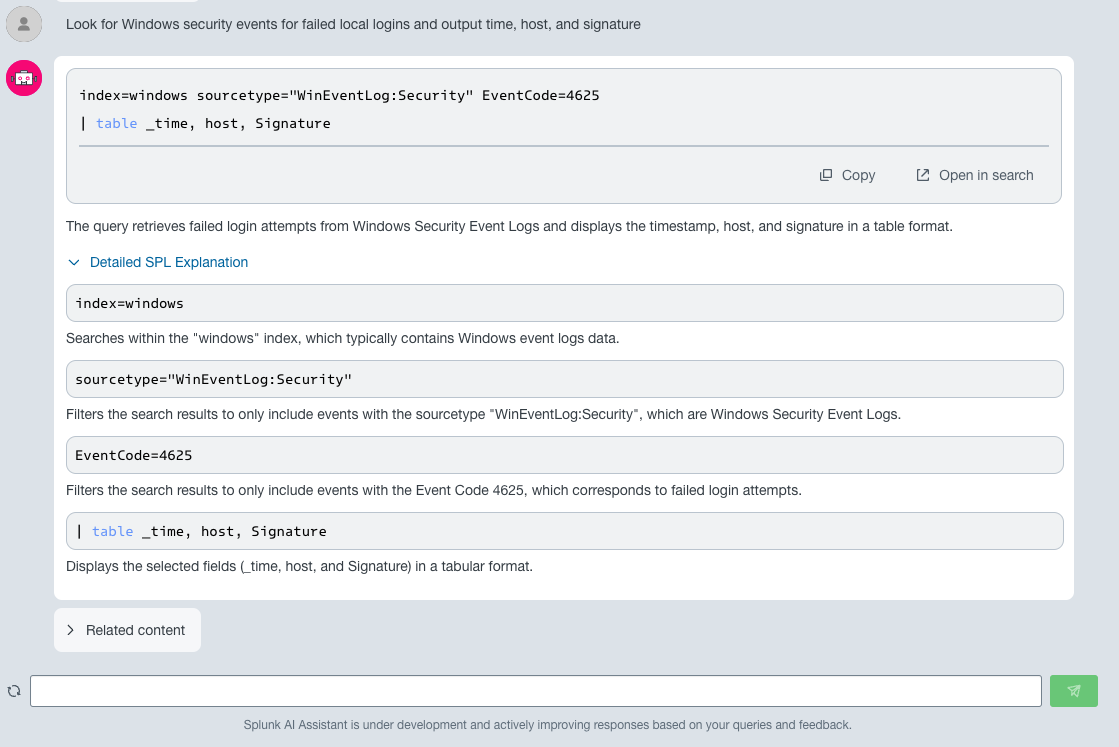
Im oben gezeigten Beispiel sucht ein Security-Analyst Windows-Sicherheitsprotokolle mit fehlgeschlagenen Anmeldeereignissen. Das Modell weiß erstens, welchen Index und Sourcetype es verwenden soll, und zweitens, dass es nach „EventCode=4625“ filtern muss. Es liefert zudem eine schrittweise Erklärung der vorhergesagten SPL-Abfrage und schlägt eine Liste von zugehörigen Inhalten in der Splunk-Dokumentation vor.
SPL ist eine leistungsfähige, aber komplexe domänenspezifische Sprache. Neue Benutzer müssen sich erst in SPL einarbeiten, und für fortgeschrittene Benutzer kann es schwierig sein, das volle Potenzial von SPL auszuschöpfen. Sie müssen möglicherweise tief in die Dokumentation eintauchen oder im Internet nach Hinweisen und Beispielen suchen. Um Kundinnen und Kunden beim Schreiben von SPL-Abfragen mithilfe von Eingabeaufforderungen in natürlicher Sprache zu unterstützen, haben wir letztes Jahr den „SPL Copilot for Splunk (beta)“ auf Splunkbase veröffentlicht. Diese Beta-Version wurde bei der Vorführung auf der .conf22 mit Begeisterung aufgenommen. Für die Vorführung veranstalteten wir eine Session mit ca. 50 Personen. Zu diesem Zeitpunkt war unser einfaches Übersetzungsmodell höchst beeindruckend. Dennoch fehlten noch einige Elemente, und ChatGPT legte die Messlatte erheblich höher. User möchten mit KI-Assistenten jetzt ganz zwanglos interagieren und erwarten, dass der Assistent viel mehr Aufgaben mit höherer Genauigkeit unterstützt.
Aufbauend auf unserem letztjährigen Erfolg kann der Splunk AI Assistant jetzt noch viel mehr:
Außerdem haben wir ein offenes Frage-/Antwort-System in den Assistenten integriert, sodass Benutzer direkt Einblicke erhalten können, ohne unsere umfangreiche Dokumentation durchsuchen zu müssen.
Ihr könntet auch ChatGPT verwenden, um SPL-Abfragen mit englischen Aufforderungen zu schreiben. Warum solltet ihr also Splunk verwenden? Bei der Verwendung von ChatGPT sendet ihr möglicherweise sensible Informationen an einen externen Anbieter – die Verwendung einer integrierten und Splunk-eigenen Lösung bietet dagegen dasselbe hohe Maß an Datenschutz und Sicherheit, das Splunk-Kundinnen und -Kunden gewohnt sind. Aber gibt es keine gute Open-Source-Lösung mit ähnlichen Fähigkeiten? Experimente mit proprietären und Open-Source-Modellen haben uns gezeigt, dass fast keines davon zufriedenstellende SPL-Abfragen liefert. Die einzige Ausnahme ist ChatGPT/GPT4, das aber noch immer unter Halluzinationen leidet und beispielsweise neue Suchbefehle oder Argumente erfindet. Die Halluzinationen rühren wahrscheinlich daher, dass es nicht viele öffentliche Beispiele für SPL gibt, die automatisch gesammelt und zum Trainieren dieser großen Modelle verwendet werden könnten. Dadurch wird SPL mit anderen Sprachen verwechselt, die in den Trainingsdaten stärker vertreten sind.
Ein Assistent ohne spezielles Wissen über unsere Produkte hat nur wenig Nutzen für unsere Kundschaft. Aus diesem Grund haben wir Splunk AI Assistant bei der Erstellung mit Splunk-spezifischem Wissen trainiert.
Letztes Jahr verwendeten wir den Text-to-Text Transfer Transformer (T5), ein öffentlich verfügbares, vortrainiertes Modell, das von Google im Februar 2020 vorgestellt wurde. T5 ist ein standardmäßiger Encoder-Decoder-Transformer, der mit dem C4-Datenset trainiert wurde, einer 750 GB großen Sammlung englischer Texte aus der öffentlichen Web-Scraping-Datenbank „Common Crawl“. Wir haben eine Modellversion namens codet5-small, die über 60 Mio. Parameter beinhaltet, mit etwa 2.000 Trainingsbeispielen für die Übersetzung von Englisch in SPL optimiert. Eine solche Optimierung kann für ein paar Euro auf einer einzigen V100-GPU durchgeführt werden. Wir beschlossen, unser Modell codet5-small zu aktualisieren, indem wir verschiedene Trainingsziele mischten (z. B. Schreiben einer SPL-Abfrage anhand einer englischsprachigen Beschreibung, Erzeugen einer mehrere Schritte umfassenden englischen Beschreibung einer SPL-Abfrage etc.) und unser Trainingsdatenset mit synthetisch generierten und benutzergenerierten Daten von Splunk-Mitarbeitern anreicherten. Das Ergebnis war ein Trainingsdatenset, das 300 Mal größer als das Datenset des Vorjahres war.
Bei der Erweiterung unseres Trainingsdatensets beschlossen wir, mit dem Trainieren neuerer und viel größerer Sprachmodelle zu experimentieren. Zunächst untersuchten wir Open-Source-LLMs, um eine Ausgangsgruppe mit der besten Performance bei der Zero-Shot-Generierung von SPL zu ermitteln. Von den Open-Source-Modellen schlugen sich hier StarCoder und StarCoder Plus am besten. Dies sind Sprachmodelle mit 15 Mrd. Parametern, die von BigCode entwickelt und speziell für die Codegenerierung und Codevervollständigung trainiert wurden.
Zum Trainieren solch großer Modelle verwendeten wir anfangs neuere A100-GPUs mit 40 GB Speicher. Verwendung findet GPU-Speicher beim Trainieren hauptsächlich für Modellgewichtungen, Optimizer-Zustände, Gradienten, gespeicherte Vorwärtsaktivierungen für die Gradientenberechnung und temporäre Puffer verwendet. Für das Training von StarCoder mit einfacher Genauigkeit ohne Optimierung belief sich die Datenmenge auf 240 GB plus Vorwärtsaktivierungen und temporäre Puffer. Wir verwendeten FSDP (Fully Sharded Data Parallel) von Pytorch, um die Modellgewichtungen, Gradienten und Optimizer-Zustände in Shards auf acht A100-GPUs (mit jeweils 40 GB Speicher) in einer Knoteninstanz zu verteilen. Dank FSDP konnten wir hierbei detailliert steuern, wie wir unser Modell splitten und verteilen. Um zu vermeiden, dass uns der Speicher ausgeht, haben wir unseren Speicherbedarf durch Gradienten-Checkpointing weiter reduziert. Auch Trainieren mit halber Genauigkeit und gemischter Genauigkeit kann den Trainingsvorgang beschleunigen und gleichzeitig den Speicherbedarf reduzieren. Da A100-GPUs das Gleitkommaformat bfloat16 unterstützen, ist bei gemischter Genauigkeit keine Verlustskalierung erforderlich. Die Auswirkungen der gemischten Genauigkeit auf den Speicherbedarf variieren je nach Modellarchitektur: Man muss hier zwischen der Speicherung einer zusätzlichen Kopie der Modellgewichte in fp16 und der Speicherung von Aktivierungen in fp16 statt fp32 abwägen.
Theoretisch könnte die gemischte Genauigkeit den Speicherbedarf um maximal die Hälfte reduzieren und eine Verdopplung der Batch-Größe ermöglichen. Wir haben auch ZeRO-3 von DeepSpeed ausprobiert, da die Accelerate-Implementierung von HuggingFace sehr praktisch ist und zusätzliche Optimierungsverfahren wie LoRA unterstützt. LoRA ist ein parametereffizientes Optimierungsverfahren, das die ursprünglichen Gewichtungen „einfriert“ und eine kleine Menge an trainierbaren, neuen Gewichtungen einführt. Mit LoRA haben wir effektiv etwa 0,22 % unserer Modellparameter trainiert. Später standen uns dann A100-GPUs mit 80 GB Speicher zur Verfügung, sodass wir zusätzlich zu den DeepSpeed-Optimierungen auch unsere Konvergenzgeschwindigkeit verbessern konnten.
Um das Modell zu einem dialogorientierten Assistenten zu machen, haben wir es mit Dialogdaten, die mit speziellen Token wie ChatML formatiert waren, weiter optimiert. Damit das Training effizienter wurde, haben wir zudem die Sätze verkettet, um Segmente mit einer bestimmten Größe zu erzeugen, anstatt jeden Satz aufzufüllen.
Außerdem haben wir ein Retriever-Reader-System für die Splunk-Dokumentation entwickelt. Dazu haben wir die Splunk-Dokumentation erfasst und vortrainierte Einbettungsmodelle von Sentence Transformers mit der erfassten Dokumentation optimiert.
Dogfooding ist gängige Praxis bei Splunk, und Splunk-Mitarbeiter sind am besten in der Lage, unser Modell mit ihrem Wissen zu trainieren. Inspiriert von Databricks Dolly 2.0 entwickelten wir ein internes Webportal und baten Mitarbeiter, mit unseren Modellen zu interagieren und Feedback zu geben. Modellvorhersagen werden anonymisiert, und Benutzer können diese Vorhersagen bewerten und Korrekturen vorschlagen. Ihr Feedback wird in Amazon RDS gespeichert, und wir haben diese Präferenzen dann in unsere Trainingsschleife integriert.
Eine Standardkennzahl für die automatische Bewertung maschineller Übersetzungssysteme für natürliche Sprache ist der BLEU-Score. BLEU ist eine Metrik auf Korpusebene, die auf einem modifizierten N-Gramm-Präzisionswert zwischen der vorhergesagten Übersetzung und Referenzübersetzungen basiert. Im Zusammenhang mit der Codegenerierung ist der BLEU-Score nicht geeignet, da durch Ändern auch nur eines einzigen Zeichens fehlerfreier Code zu Code werden kann, der sich nicht ausführen lässt. Im letzten Jahr haben wir daher vorhergesagte Abfragen auch mit einem exakten Zeichenkettenabgleich bewertet. Der exakte Abgleich von Zeichenketten kann jedoch zu einer Überbewertung von False-Negatives führen, da es mehrere Möglichkeiten gibt, eine richtige Anfrage zu formulieren. Außerdem brauchten wir Metriken, mit denen wir die neuesten Fähigkeiten des Assistenten bewerten konnten.
Wir versuchten, jede Vorhersage von Menschen bewerten zu lassen. Dies stellte sich aber als zu langsam und aufwendig heraus. Außerdem gibt es bei menschlichen Bewertungen ein gewisses Maß an Verzerrung (Bias): Sie variieren zum Beispiel je nachdem, wer die Bewertung vornimmt und welchen Kenntnisstand diese Person hat. Bei neueren Arbeiten wie Chatbot Arena wurde für das Benchmarking von LLMs die ELO-Zahl eingesetzt. LLMs agieren dabei als Spieler in randomisierten paarweisen Vergleichen, und die relative Leistung leitet sich aus der Zahl der Siege, Niederlagen und Unentschieden gegen andere Spieler ab. Dieses Bewertungssystem ist im Schach und in anderen Wettbewerbsspielen weit verbreitet.
Wir haben uns zu Anfang für eine ELO-Bewertung mit einem LLM als Juror entschieden. Mit einem LLM als Juror treten ebenfalls Verzerrungen auf, diese lassen sich jedoch kalibrieren. Eine LLM-Bewertung kann empfindlich von der Reihenfolge beeinflusst werden, in der dem LLM die zu bewertenden Antworten gezeigt werden. Bei paarweisen Vergleichen kann man diese durch die Position bedingte Verzerrung kalibrieren, indem man die Antworten der beiden Kandidaten auch in umgekehrter Reihenfolge bewerten lässt und dann den Durchschnitt der Punktzahlen aus den beiden Reihenfolgen bildet. Die Bewertung der Kandidatenantworten fällt auch konsistenter aus, wenn das LLM mehrere Belege (wie etwa korrekte Syntax, angemessene Suchbefehle, präzise Antworten, keine Halluzinationen usw.) vorlegen muss, um seine nachfolgende Bewertung zu untermauern.
Bei der ELO-Bewertung spielt die Reihenfolge, in der die Vergleiche durchgeführt werden, eine große Rolle. Da diese Bewertung auf paarweisen Vergleichen basiert, müssen darüber hinaus für den Vergleich von n Modellen 2n Vergleiche für jeden Bewertungsinput durchgeführt werden, was das Ganze unverhältnismäßig teuer macht. Stattdessen haben wir entschieden, jedes Modell anhand des erwarteten Ergebnisses zu bewerten, indem wir unseren LLM-Juror direkt um eine Bewertung von 0 bis 10 baten und die relative Leistung jedes Modells dann für das erwartete Ergebnis angaben.
Relative Leistung im Vergleich zum erwarteten Ergebnis (10 Versuche) |
|
StarCoder (2023) |
95,5 % (1,2) |
CodeT5-small (2023) |
77,7 % (1,2) |
CodeT5-small (2023, nach 8-Bit-Quantisierung) |
70,06 % (1,3) |
CodeT5-small (2022) |
42,1 % (1,5) |
Zur Bewertung des Frage-/Antwort-Systems haben wir willkürlich ca. 2.500 Dokumente aus unserem Datenkorpus genommen und zu jedem Dokument eine Frage erstellt. Das Retriever-System hatte eine Genauigkeit von 94 %. Wenn wir uns das gefundene Top-1-Dokument ansehen, so ist es in 70 % der Fälle das Dokument, zu dem die Frage gestellt wurde, und in 88 % der Fälle enthält es die Antwort auf die gestellte Frage. Bei diesem Bewertungsansatz gibt es ein gewisses Maß an Verzerrung, da die Fragen auf der Grundlage der Dokumente aus dem Datenkorpus erstellt werden. Wir werden dies bei unserer künftigen Arbeit berücksichtigen.
Wir hoffen, dieser kleine Einblick in unsere Arbeit beim Entwickeln eines KI-Assistenten hat euch gefallen. In Zukunft müssen wir noch viel mehr Themen untersuchen: beispielsweise die Integration von Daten aus Kundenumgebungen und die Unterstützung anderer Programmiersprachen, die wir bei Splunk nutzen, wie etwa SignalFlow. Aufgrund aktueller Beschränkungen kann in Splunkbase nur die Version „codet5-small“ von Splunk AI Assistant bereitgestellt werden. Wir arbeiten jedoch daran, unserer Kundschaft den Assistenten in vollem Umfang bereitstellen zu können.
Bei Fragen könnt ihr uns gerne kontaktieren. Wir freuen uns auf eure Beiträge!
Diese Blogbeitrag wurde von Julien Veron Vialard, Robert Riachi, Abe Starosta und Om Rajyaguru gemeinsam verfasst.
Julien Veron Vialard ist Senior Applied Scientist bei Splunk. Er ist damit betraut, Sprachmodelle für die Codegenerierung, die Beantwortung von Fragen und die Erkennung benannter Entitäten (Named Entity Recognition) zu trainieren und bereitzustellen. Er hat Erfahrung in wissenschaftlicher Arbeit und der Zusammenarbeit mit Produktteams. Im Juni 2021 erhielt er seinen Master in der Fachrichtung Computational und Mathematical Engineering von der Stanford University, wo sich seine Forschung auf Convolutional Neural Nets (CNNs) für die medizinische Bildgebung konzentrierte. Vor seinem Studium in Stanford absolvierte Julien Praktika bei Handelsunternehmen.
Robert Riachi ist Applied Scientist bei Splunk und arbeitet im Bereich Training und Bereitstellung von LLMs für dialogorientierte Agents und die Codegenerierung. Vor seiner Zeit bei Splunk erstellte er generative ML-Modelle bei Bloomberg und schloss sein Doppelstudium in Informatik und Statistik an der University of Waterloo mit dem Bachelor of Mathematics ab.
Abraham „Abe“ Starosta ist Senior Applied Scientist bei Splunk, wo er an der Verarbeitung natürlicher Sprache und der Anomalieerkennung arbeitet. Bevor er zu Splunk kam, war er NLP-Ingenieur bei wachstumsstarken Technologie-Startups wie Primer und Livongo. 2014 absolvierte er dann ein Praktikum bei Splunk. Er erwarb seinen Bachelor- und Masterabschluss in Informatik in Stanford, wo der Schwerpunkt seiner Forschung auf schwacher Überwachung und Multi-Task Learning lag.
Om Rajyaguru ist Applied Scientist bei Splunk und arbeitet hauptsächlich an Fragestellungen im Zusammenhang mit dem Clustering von Zeitreihen sowie an Methoden zur Optimierung und Bewertung von LLMs für Codegenerierungsaufgaben. Im Juni 2022 schloss er sein Bachelorstudium im Bereich angewandte Mathematik und Statistik ab, bei dem sein Schwerpunkt auf multimodalem Lernen und Low-Rank-Approximationsverfahren für tiefe neuronale Netze lag.
Ein besonderer Dank geht an Vedant Dharnidharka (Director of Engineering – Machine Learning) und das gesamte ML-Team für ihre Anregungen, Hilfe und Ideen.
*Dieser Blog wurde übersetzt und editiert. Den englischen Originalblog findet ihr hier.

Die führenden Unternehmen der Welt vertrauen auf Splunk, einem Unternehmen von Cisco, um ihre digitale Resilienz mit der einheitlichen Sicherheits- und Observability-Plattform, unterstützt durch branchenführende KI, kontinuierlich zu stärken.
Unsere Kunden setzen auf die preisgekrönten Sicherheits- und Observability-Lösungen von Splunk, um die Zuverlässigkeit ihrer komplexen digitalen Umgebungen zu sichern und zu optimieren – in jeder Größenordnung.

Die neuesten Artikel von Splunk, direkt im eigenen Posteingang.
© 2005 - 2026 Splunk LLC All rights reserved.
© 2005 - 2026 Splunk LLC All rights reserved.