
Wege zum Aufbau erfolgreicher Observability-Praktiken

 Im Gespräch mit aktuellen oder potenziellen Splunk-Kunden hören wir oft folgende Frage: „Warum brauche ich Splunk, wenn ich doch auch einfach AWS Cloudwatch, Azure Monitor oder GCP Cloud Operations Suite (früher Stackdriver) für mein Cloud-Monitoring verwenden kann?“ Das ist in der Tat eine gute Frage!
Im Gespräch mit aktuellen oder potenziellen Splunk-Kunden hören wir oft folgende Frage: „Warum brauche ich Splunk, wenn ich doch auch einfach AWS Cloudwatch, Azure Monitor oder GCP Cloud Operations Suite (früher Stackdriver) für mein Cloud-Monitoring verwenden kann?“ Das ist in der Tat eine gute Frage!
Kunden nehmen von Cloud-Anbietern bereitgestellte Monitoring-Tools häufig als „günstiger“, „einfacher“ oder „besser integriert“ wahr und neigen daher eher dazu, ganz auf diese Tools zu setzen – besonders in der Anfangsphase ihrer Cloud-Reise. Diesem Ansatz begegnen wir ständig, müssen allerdings immer wieder feststellen, dass er nicht empfehlenswert ist.
In diesem Blog zeigen wir euch, warum Splunk mehr leistet. Wir geben euch einen Gesamtüberblick und untermauern diesen mit fünf Erkenntnissen (und konkreten Beispielen), die ihr nur mit Cloud-Anbieter-Tools nie erhalten würdet!
Also, warum braucht ihr Splunk und nicht nur die Monitoring-Lösung eures Cloud-Anbieters?
Die einfachste Antwort lautet: Monitoring-Lösungen von Cloud-Anbietern „füttern“ häufig nur ein weiteres Datensilo, in dem Daten abgeschottet, nur für eine kleine Benutzergruppe verfügbar und nicht mit anderen Datenquellen korrelierbar sind. Darüber hinaus sind die Features und Funktionen der einzelnen Monitoring-Lösungen von Cloud-Anbietern begrenzt. Man könnte fast meinen, Amazon, Microsoft und Google begnügen sich bei Funktionalität und Nutzbarkeit mit der Einstellung „gerade ausreichend genug“.
Und dieses Problem ist auch nicht neu: Seit Jahren ist Splunk praktisch die Standardlösung, mit der man Daten frei verfügbar und korrelierbar macht. Nehmen wir beispielsweise VMWare. Den meisten VMWare-Administratoren genügt wahrscheinlich VSphere für das Monitoring, die Verwaltung und das Troubleshooting der VMWare-Plattform. Doch wie steht es mit Anwendern, deren Anwendung auf einer virtuellen VMWare-Maschine ausgeführt wird? Es ist ziemlich unwahrscheinlich, dass sie sich bei VSphere anmelden, wenn etwas mit ihrer Anwendung nicht in Ordnung ist. Dabei ist es gut möglich, dass ihre Anwendungsprobleme durch ein unerwartetes VMotion-Ereignis oder eine ressourcenfressende VM verursacht werden. Dasselbe gilt für Datenbanken oder Netzwerk-, Speicher- und andere Technologien. Solange ihr Daten nicht aus verschiedenen Systemen an einem Ort zusammenführen könnt, bleibt es immer schwierig, Incidents zu korrelieren oder zu untersuchen und die wahre Ursache zu ermitteln.
Falls euch dieser Gesamtüberblick noch nicht überzeugt, möchte ich ihn mit fünf konkreten Beispielen untermauern – nämlich mit Erkenntnissen, die das Monitoring-Tool eurer Cloud-Plattform kaum liefern dürfte.
Die meisten Unternehmen verwalten mehrere Cloud-Accounts und stellen Ressourcen in mehreren Regionen bereit, haben ihre Infrastruktur aber leider nur auf der Rechnung voll im Blick – ihr wisst sicherlich, was ich meine. Es ist wirklich mühsam, sich in der Konsole des Cloud-Anbieters von Account zu Account und von Region zu Region durchzukämpfen, um sich Einblick in die Infrastruktur zu verschaffen. Mit Splunk könnt ihr jedoch über Accounts und Regionen hinweg Fragen zu kritischer Infrastruktur beantworten, wie z. B.:
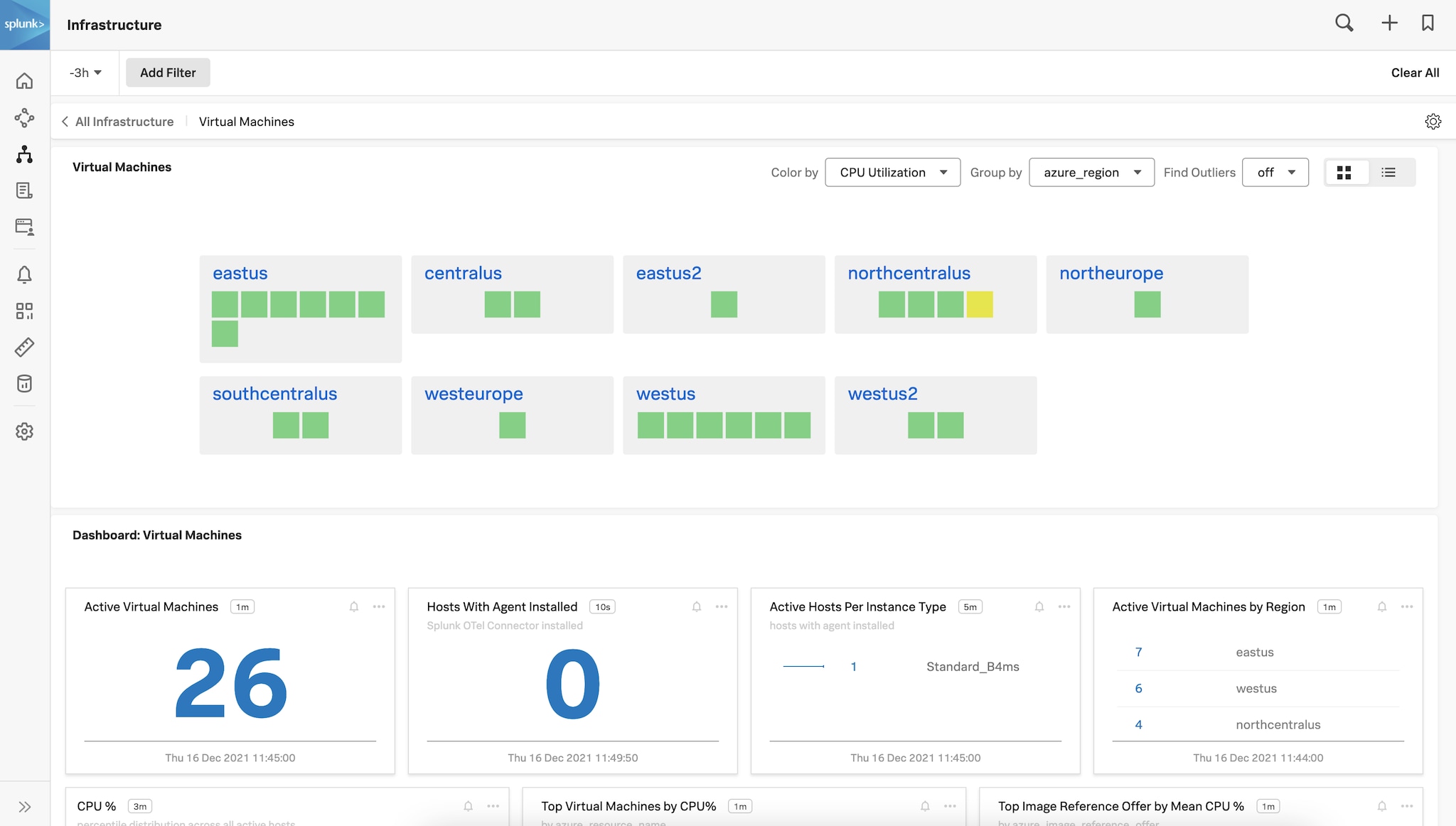
Abbildung 1: Account-übergreifender Überblick über alle Azure-VMs, geordnet nach Region
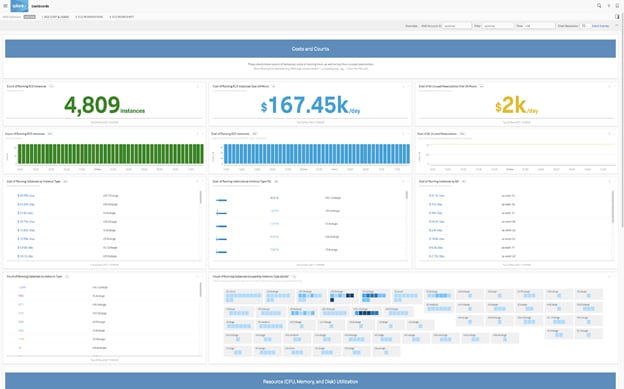
Abbildung 2: Ein Splunk-Dashboard zur AWS EC2-Kostenanalyse
Die meisten Unternehmen verlagern Workloads in die Cloud, doch diese Workloads sind weiterhin von lokalen und externen Systemen abhängig. Tatsächlich gehören die Workloads, die lokal bleiben, in der Regel zu den wichtigsten, geschäftskritischsten Systemen eines Unternehmens. Die Migration von Workloads in die Cloud erfolgt häufig in mehreren Phasen, wobei weniger wichtige Komponenten zuerst verlagert werden, doch in den meisten Fällen sind sie nur im Zusammenspiel mit externen Services funktionsfähig.
Stellt euch vor, bei einer solchen Anwendung wäre Troubleshooting notwendig. Wahrscheinlich habt ihr genau das sogar schon erlebt. Lasst mich raten, wie das ablief: Das Cloud Operations-Team verwendete die Monitoring-Lösung eines bestimmten Cloud-Anbieters, und diese meldete „alles in Ordnung“, und die IT Operations-Teams arbeiteten mit ihren Monitoring-Tools, die ebenfalls zu dem Ergebnis kamen, dass „alles in Ordnung“ sei.
Bei Splunk haben wir folgende Erfahrung gemacht: Wenn Unternehmen solche komplexen Probleme lösen können, dann liegt das daran, dass sie ihre Monitoring- und Untersuchungsprozesse in einer zentralen Plattform zusammengelegt haben. Dabei dienen Splunk-Suchen, -Dashboards und -Visualisierungen als „universelle Sprache“, mit der Teams Incidents sichten, isolieren und untersuchen können.
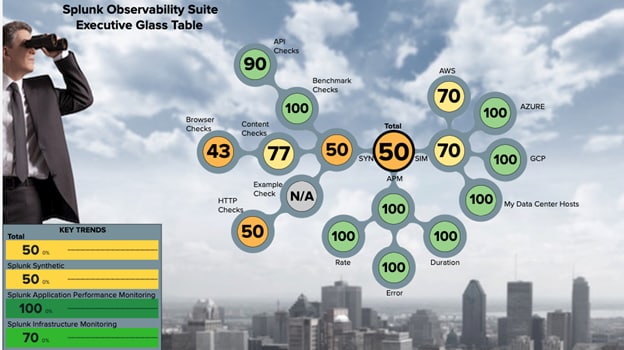
Abbildung 3: Werte für den Servicezustand eines Multi-Cloud-Systems, dargestellt in einer Executive Glass Table in Splunk Observability
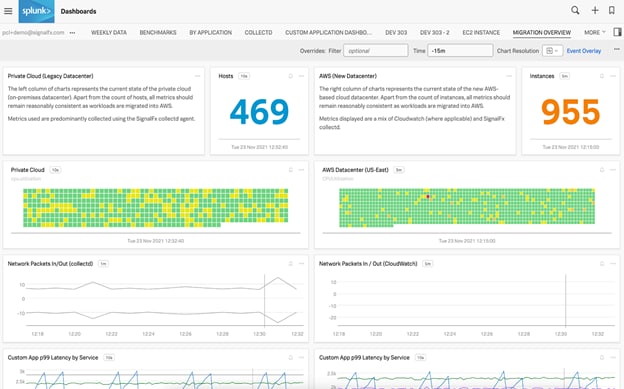
Abbildung 4: Ein Splunk-Dashboard mit Metriken zu Hosts in einer Private Cloud sowie AWS-Instanzen
Cloud-Anbieter beschränken (verständlicherweise) die Art und Granularität der Monitoring-Daten, auf die ihr Zugriff habt. AWS Cloudwatch-Metriken werden beispielsweise standardmäßig in einem Intervall von fünf Minuten erfasst. Die Granularität kann bestenfalls auf einmal pro Minute erhöht werden, aber dann ist Schluss. Angenommen, euer Cloud-Anbieter wäre ein Babysitter, der auf eure Kinder aufpassen soll. Würdet ihr beruhigt ausgehen, wenn ihr wüsstet, dass der Babysitter ständig am Handy hängt und nur alle fünf Minuten nach den Kindern schaut? Wohl kaum! In fünf Minuten kann viel passieren.
Ganz abgesehen von der Granularität gibt es wahrscheinlich noch mehr Telemetriedaten zu einem Gerät, die ihr gerne erfassen würdet, die aber nicht in den Metriken eures Cloud-Anbieters enthalten sind. Leider muss AWS hier gleich noch einmal als Negativbeispiel herhalten: EBS-Speicher wird nach der Gesamtgröße der zugeordneten Speicher-Volumes abgerechnet, unabhängig davon, wie viel Speicherplatz tatsächlich genutzt wird. Also könnten wir doch versuchen, Cloud-Kosten einzusparen, indem wir Cloudwatch zum Visualisieren und Überwachen der prozentualen Speicherbelegung für jedes EBS-Volume verwenden, oder? Ganz falsch! Ihr könnt zwar leicht erkennen, wie groß das Volume ist, doch es gibt keine Kennzahl, die die Belegung anzeigt – ein großer Schwachpunkt.
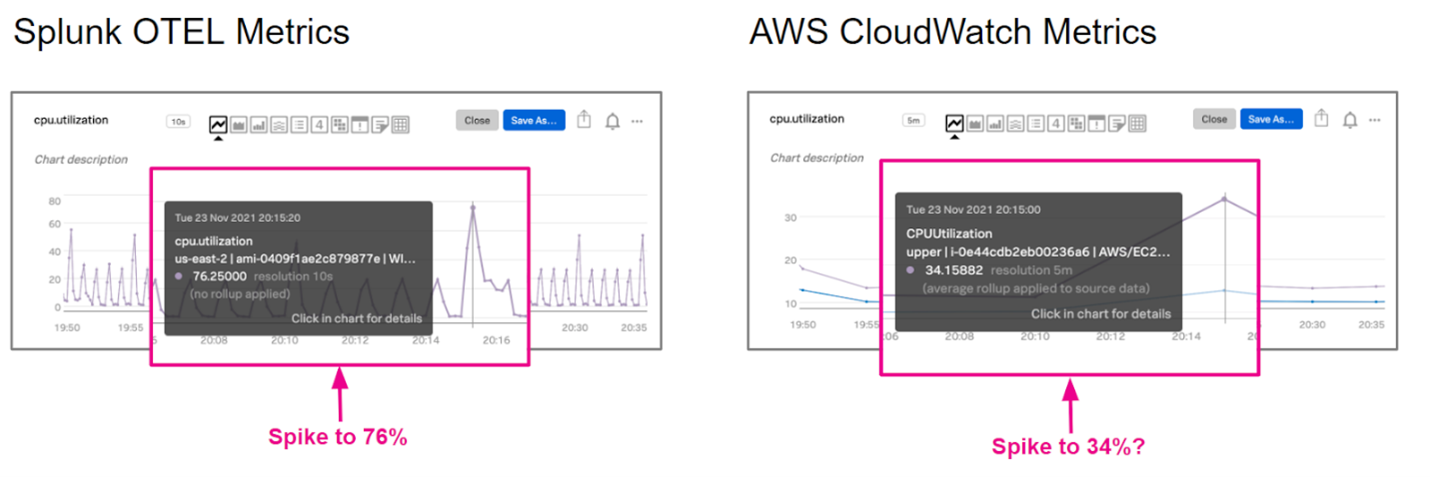
Abbildung 5: Splunk Open Telemetry (OTEL)-Metriken im Vergleich mit AWS CloudWatch-Metriken
Da Splunk diesen Bereich absolut dominiert, sage ich es jetzt einfach ganz direkt: Wenn ihr das Monitoring-Tool eures Cloud-Anbieters zum Durchsuchen und Analysieren von Logs verwendet, ist die Enttäuschung nicht weit. Einfache Datenerfassungen, einfache Suchen und einfache Einblicke sind zwar möglich, aber für tiefgreifende Untersuchungen – auch umgebungsweit – braucht es fortgeschrittene Datenerfassungs-, Parsing- und Suchfunktionen, die nur Splunk bietet. Auch hier möchte ich euch ein paar konkrete Beispiele nennen.
Nehmen wir an, ihr möchtet feststellen, ob eine kürzlich erfolgte Code-Bereitstellung neue Probleme in der Umgebung verursacht. Ein sinnvolles Analyseverfahren wäre die Suche nach neuen Stacktraces. Das kann sich jedoch schwierig gestalten, denn wie lässt sich feststellen, ob ein Stacktrace mit einem anderen identisch ist? Mit unserer cleveren Suchsprache SPL ist das ganz einfach.
Nehmen wir weiter an, ihr möchtet feststellen, ob Daten in einem S3-Bucket aus Versehen als öffentlich konfiguriert wurden. Ohne Splunk gar nicht so einfach! Doch mit SPL können wir S3-Zugriffslogs erfassen, sie mit Geolokalisierungsdaten anreichern und mit S3-Bucketnamen auf einer Karte darstellen. Wow!
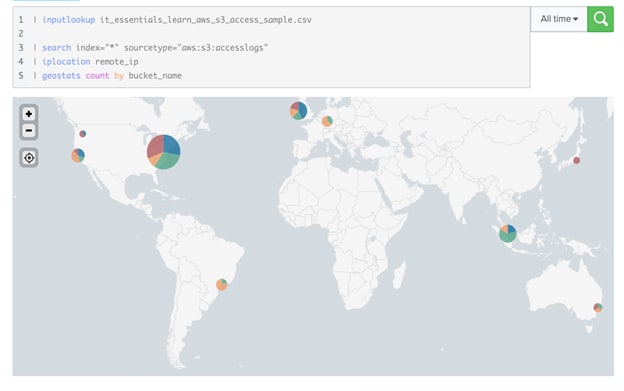
Abbildung 6: Suche und Darstellung der AWS S3-Geolokalisierung in einem Splunk-Dashboard

Abbildung 7: Stacktrace-Suchdetails in Splunk

Abbildung 8: Erkennung von Stacktraces und zugehörigen Trends in Splunk
Es dürfte euch nicht überraschen, dass die Erfassung der Daten nur der erste Schritt ist. Den eigentlichen Mehrwert bringt die Verwertung der Daten. Während Cloud-Anbieter euch die Erfassung von Daten aus ihren Services recht einfach machen und oftmals domänenspezifische Dashboards bereitstellen, ist für die Korrelation und Anzeige von Daten über verschiedene Services hinweg sehr viel manueller Aufwand erforderlich. Dazu kommt, dass jede Anwendung und die ihr zugrunde liegende Architektur einzigartig sind, sodass es wirklich mühsam sein kann, aussagekräftige Visualisierungen zu erstellen, die viele verschiedene Datenquellen einbeziehen.
Splunk Infrastructure Monitoring (SIM) und Splunk Application Performance Monitoring (APM) bieten Out-of-the-Box-Workflows für eure wichtigen Daten, ganz unabhängig von der Quelle. Dies ermöglicht eine sofortige Nutzung mit kontextbasierten Drilldowns, verbessert den ROI und ermöglicht euch, eure Daten optimal auszuwerten. Zudem könnt ihr die sofort einsatzbereiten Dashboards als Vorlage nutzen, um die Darstellung leichter und schneller von einem domänenspezifischen Dashboard zu einer durchgängigen, viele Korrelationen umfassenden End-to-End-Sicht eurer missionskritischen Services weiterzuentwickeln. Diagramme und andere Visualisierungen können problemlos aus separaten Dashboards kopiert und in individuell zugeschnittene, aussagekräftige Dashboards eingefügt werden. Diese Dashboards können dann für andere freigegeben und zur besseren Zusammenarbeit in teambasierte Sammlungen aufgenommen werden.
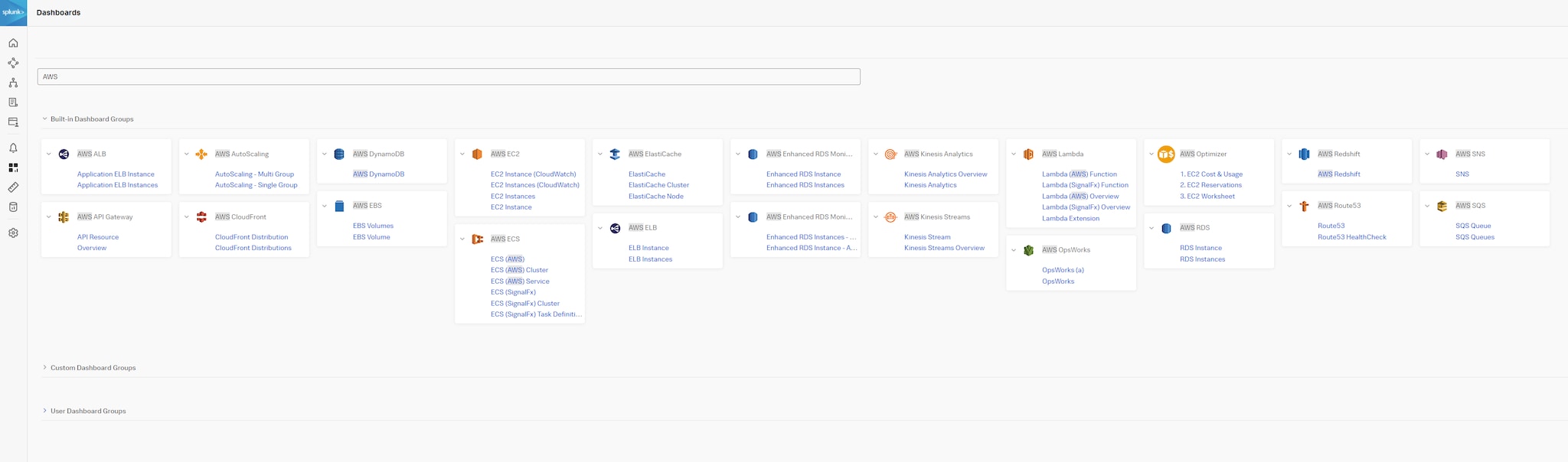
Abbildung 9: Integrierte Dashboard-Gruppen zu AWS in Splunk Observability Cloud
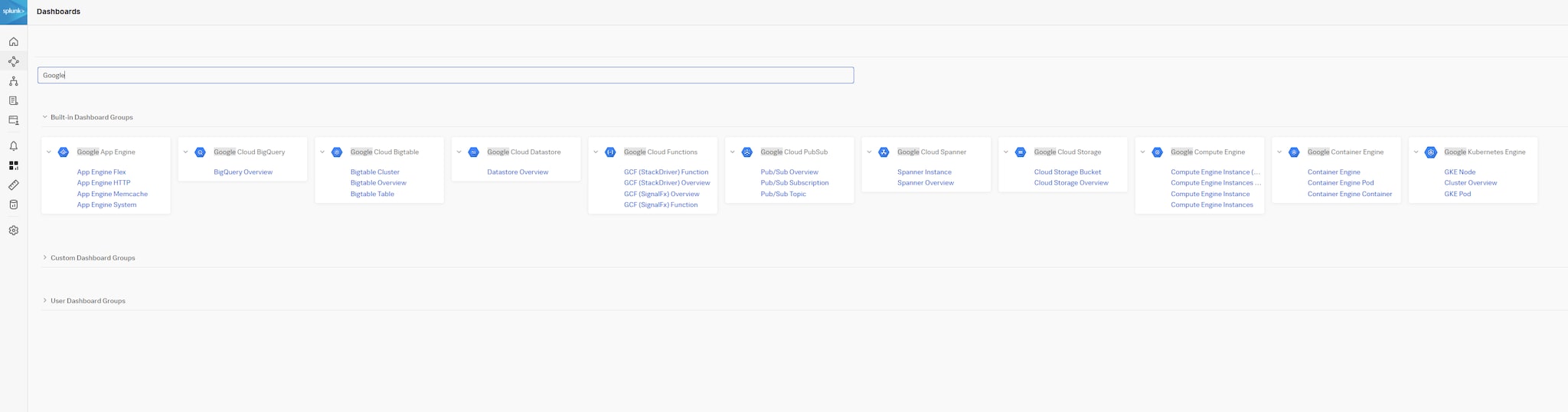
Abbildung 10: Integrierte Dashboard-Gruppen zu Google Cloud Platform in Splunk Observability Cloud
Abbildung 11: Integrierte Dashboard-Gruppen zu Azure in Splunk Observability Cloud
Cloud-Anbieter zielen in erster Linie darauf ab, Infrastruktur, Plattformen und Software-as-a-Service bereitzustellen. Die Bereitstellung von effektivem Monitoring für diese Infrastruktur hat für sie eher untergeordnete Bedeutung. Wir beobachten das seit Jahren immer wieder, wenn neue Technologien aufkommen, und warum sollten Cloud-Anbieter hier die große Ausnahme darstellen? Das primäre Ziel von Splunk ist, alle Arten von Maschinendaten effektiv zu erfassen, zu durchsuchen, zu analysieren und zu überwachen, damit ihr Daten in Taten verwandeln könnt.
Wenn ihr mehr darüber erfahren möchtet, wie Splunk eure IT-, CloudOps- und DevOps-Teams bei der proaktiven Beobachtung und Analyse eurer dynamisch wachsenden Cloud-Umgebung unterstützen kann, besucht unsere Splunk Observability Cloud-Seite.
*Dieser Artikel wurde aus dem Englischen übersetzt und editiert. Den Originalblogpost findet ihr hier.

Die führenden Unternehmen der Welt vertrauen auf Splunk, einem Unternehmen von Cisco, um ihre digitale Resilienz mit der einheitlichen Sicherheits- und Observability-Plattform, unterstützt durch branchenführende KI, kontinuierlich zu stärken.
Unsere Kunden setzen auf die preisgekrönten Sicherheits- und Observability-Lösungen von Splunk, um die Zuverlässigkeit ihrer komplexen digitalen Umgebungen zu sichern und zu optimieren – in jeder Größenordnung.

Die neuesten Artikel von Splunk, direkt im eigenen Posteingang.
© 2005 - 2026 Splunk LLC All rights reserved.
© 2005 - 2026 Splunk LLC All rights reserved.