
データ管理の新たなルール
データ管理の新たなルールを取り入れて、データの複雑さを軽減し、サイバーセキュリティとオブザーバビリティを向上させる方法をご紹介します。

エンジニアリングチームやデータサイエンスチームにとって、Splunkはしばしば、信頼できる確実な情報源として機能します。そこにはセキュリティ、運用、ビジネスアプリケーションに関するリアルタイムデータが豊富に蓄積されています。しかし、主要な課題は、この貴重なデータを高度なAIや自動化サービスと連携して、具体的なアクションを促進することです。アマゾン ウェブ サービス(AWS)との新たな2つの統合は、この課題の解決を目的としています。この統合によって、Splunkデータを保存場所に置いたまま活用するためのシームレスなワークフローを構築することで、作業の煩雑さを解消し、価値実現までの時間を短縮できます。
このブログ記事では、別個でありながら互いに補完し合う、次の2つの統合についてご説明します。
エンジニアリングチームの目標は、従来のリアクティブなトラブルシューティングからプロアクティブなアプローチへとシフトして、オペレーショナルエクセレンスを実現することです。そのためには、データだけでなく、そのデータに基づいて自律的に行動するためのインテリジェンスが必要です。SplunkとAWS DevOps Agentの組み込みの統合は、この課題に対処するために設計されています。これにより、Splunkが提供する豊富なオブザーバビリティデータを自動化されたアクションへと変換できます。
効果的な自動化を実現するには、高品質で一元管理されたデータソースが不可欠です。Splunkはその確保を担います。AWSサービスやアプリケーションログ、CI/CDパイプラインなど多様なソースからデータを取り込み、正規化するのです。これにより、一元化されたデータプレーンが構築され、Splunkのデータを活用して複雑な運用パターンを特定できるようになります。
AWS DevOps Agentは、熟練した運用エンジニアのように思考し、行動する自律的なAIチームメンバーとして作動します。Splunk Model Context Protocol (MCP)サーバーを通じてSplunk環境に直接接続できるため、既存のワークフローを変更する必要はありません。その統合アーキテクチャは、以下のように、インテリジェンスをシームレスに実行するために設計されています。
サービスの遅延が急増するなど、重大なインシデントが発生した場合、どのように対応したらよいでしょうか。ここでは、従来の対応方法と最新のエージェント型AIを活用した解決方法という、2つの対照的なシナリオをご紹介します。
従来の対応:パニックが起こります。オンコールエンジニアのもとにアラートが届き、進行中の作業が中断されます。オンコールエンジニアは急いでワークステーションに駆け付け、Splunkにログインし、最も関連性の高いクエリーを思い出そうと記憶をフル回転させます。そして、膨大なメトリクスやログ、最近のデプロイに関するデータを一つひとつ手作業で精査し、全体像を把握しようとします。それぞれのクエリーは仮説であり、得られる結果は手がかりとなりますが、このプロセスには非常に時間がかかるうえ、高度な専門知識と相関関係を見抜く鋭い洞察力が求められます。干し草の山から針を探すような探索を続けるなかで、貴重な時間が分単位、時には時間単位で刻々と失われ、その間にもサービスの状況は悪化し続けます。
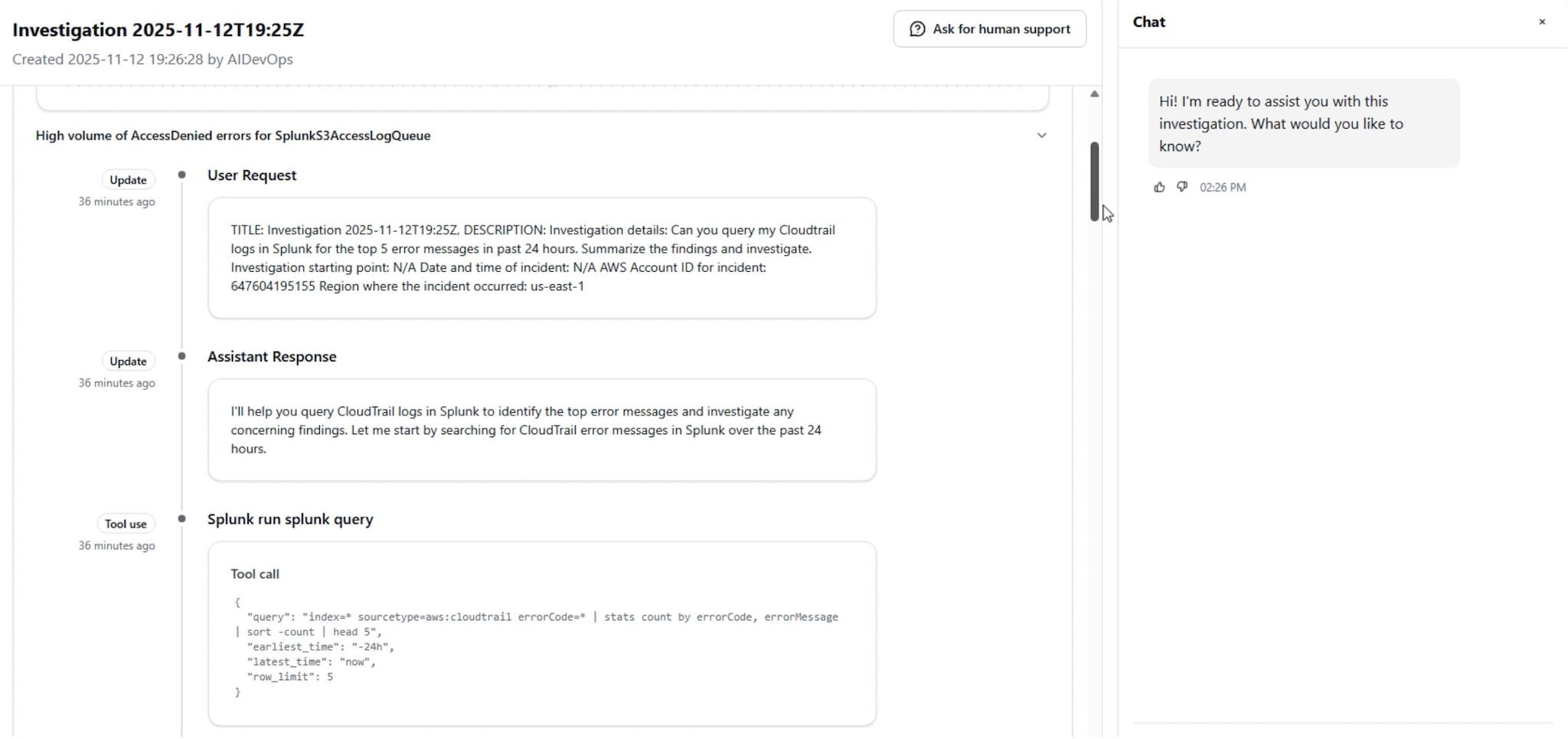
エージェント型AIによる対応:同じように遅延が急増すると、アラームが即座にAWS DevOps Agentを起動します。このエージェントは単なる監視ツールではなく、インテリジェントなチームメンバーとして機能します。サービスの複雑な依存関係やトポロジーをすでに深く理解しているため、すぐに行動を開始します。Splunkに対して適切なクエリーを自動で実行し、インシデントが発生した時間帯におけるデプロイの記録を起点に、相関するイベントを探します。具体的には、エラーログの急増、構成変更、下流の依存関係、サービスエラーなどです。
瞬く間に、エージェントは膨大なデータを処理します。そして、分析により明確な相関関係が浮き彫りになります。それは、遅延の急増が最近実施されたデプロイのタイミングと完全に一致しているということです。そのデプロイでは重要なデータベース接続パラメータがわずかに変更されています。根本原因が特定されました。ただし、それを実現したのは人間の直感ではなく、迅速かつデータドリブンな分析です。
エージェントは原因を特定するだけで終わらず、的確な対応策も策定します。たとえば、「サービス[service_name]のデプロイ[commit_hash]をロールバックしてください」といった実行可能な推奨アクションがオンコールエンジニアに提示されます。エンジニアは内容をすばやく確認して1回承認するだけで、このアクションを実行できます。かつては手作業で何時間もかかり、ストレスの多かったインシデント対応も、わずか数分で完了します。その結果、エンジニアはトラブル対応ではなく、イノベーションにより多くの時間を割けるようになります。
この統合は、単なるスピードの向上にとどまらず、運用のあり方を根本から変革します。「常時稼働」のAIエージェントがSplunkのデータに対して継続的にクエリーを実行し、インシデントをプロアクティブに検出して防ぐことで、先を見越した運用を実現します。さらに、専門知識の民主化により、複雑なクエリースキルを持たなくても、チームの誰もがSplunkから深いインサイトを得られるようになります。その結果、平均解決時間(MTTR)の短縮や早期の検出が可能となり、サービスの信頼性が向上し、ビジネスレジリエンスが大幅に強化されます。
AWS DevOps AgentがSplunk MCPをネイティブにサポートしているため、この統合の設定はわかりやすく簡単です。
AWS DevOps AgentをSplunkと連携することで、各チームが継続的かつ実用的なインテリジェンスを活用して、能力を強化できるのです。
AIを効果的に活用するためには、コンテキストが不可欠です。Splunk AI ToolkitとAWS SageMakerは、シームレスな統合を通じて、リアルタイムの運用データとビジネスコンテキストを結び付けます。それは、AIドリブンの意思決定を、セキュリティ、IT、ビジネス運用全体にわたってより迅速かつ適切に行えるようにするためです。この統合によって、Splunkを活用したデータ準備からSageMakerによるモデルのデプロイまで、一連のワークフローが効率化され、高度なAIが利用しやすくなるとともに、価値実現までの時間が短縮されます。
たとえば、データサイエンティストがストリーミング取引データをリアルタイムで分析する必要があるとします。目的は不正リスクを検出することです。しかも顧客体験を損なうことなく行わなければなりません。すでにSplunk AI Toolkit (旧称Splunk MLTK)を利用している場合、SageMakerとの連携は簡単です。Splunkが特徴量を抽出してSageMakerにストリーミングすると、SageMakerはリスクスコアを即座に算出し、Splunkの検索結果にネイティブに組み込んで返します。データサイエンティストはさらに、過去のコンテキストを付与し、不正対策チーム向けにアラートをトリガーすることで、脅威が拡大する前に阻止できるようにします。
この統合は、カスタマーサクセスチームのユースケースにも役立ちます。たとえば、このチームはSplunkを活用してアプリの利用ログや顧客のフィードバックを前処理し、そのデータをもとにSageMakerで感情分析モデルを構築して顧客離れを予測します。さらに、SageMakerで作成したモデルをAI Toolkitに登録し、予測結果をSplunkダッシュボードにフィードバックすることで、リアルタイムの顧客インサイトが得られます。カスタムETLは必要なく、ビジネスの俊敏性をただちに獲得できます。
SplunkとAWSのパートナーシップの主眼は、シンプルさと効果です。その統合はシームレスで、業務を妨げることなく既存のワークフローに直接組み込まれ、Splunk導入環境のインテリジェンスをさらに強化します。これにより、セキュリティ、IT、オブザーバビリティのいずれのチームも、企業全体の状況を一元的に把握できる充実したビューを活用し、協力して業務を進めることができます。
組織が成長するなかでも、SplunkとAWS間で安全かつリアルタイムなデータフローを構築すれば、AIイニシアチブを安心して拡大できます。また、通常業務を妨げることなく、高度な分析や機械学習モデルをきわめて重要なデータに適用できます。その結果、運用効率の向上やイノベーションの加速、さらには変化に先んじて対応できるデジタルレジリエンスが実現します。
SplunkとAWSは、AI主導の変革を支える基盤を提供し、インサイトの獲得やセキュリティの自動化、ビジネスの俊敏性向上を支援します。このパートナーシップは、信頼性の高いデータ、エンタープライズ向けのワークフロー、そしてエージェント型の自動化を実現することで、データから意思決定、インサイトからアクションへとつながるプロセスを加速させます。
AIによる成果を加速させる準備はできていますか?SplunkとAWSを組み合わせることで強力な力を引き出し、そのインテリジェンス、スピード、レジリエンスを活かして、チームが変化の激しい世界で成功をつかめるよう支援しましょう。

© 2005 - 2026 Splunk LLC 無断複写・転載を禁じます。
© 2005 - 2026 Splunk LLC 無断複写・転載を禁じます。
