
データ管理の新たなルール
データ管理の新たなルールを取り入れて、データの複雑さを軽減し、サイバーセキュリティとオブザーバビリティを向上させる方法をご紹介します。

このブログ記事はパート1からの続きです。まだお読みになっていない方は、そちらからご覧ください。
2部構成のブログシリーズのパート2では、AWS WAFログをサーチするためのSplunk Federated Search for Amazon S3の設定方法をご説明します。パート1では、Splunkの設定前に行う必要のあるAWSの設定について説明しました。その手順を完了したものとして、続きの手順をご案内します。
Splunk統合サーチの設定は大きく2つに分けられます。
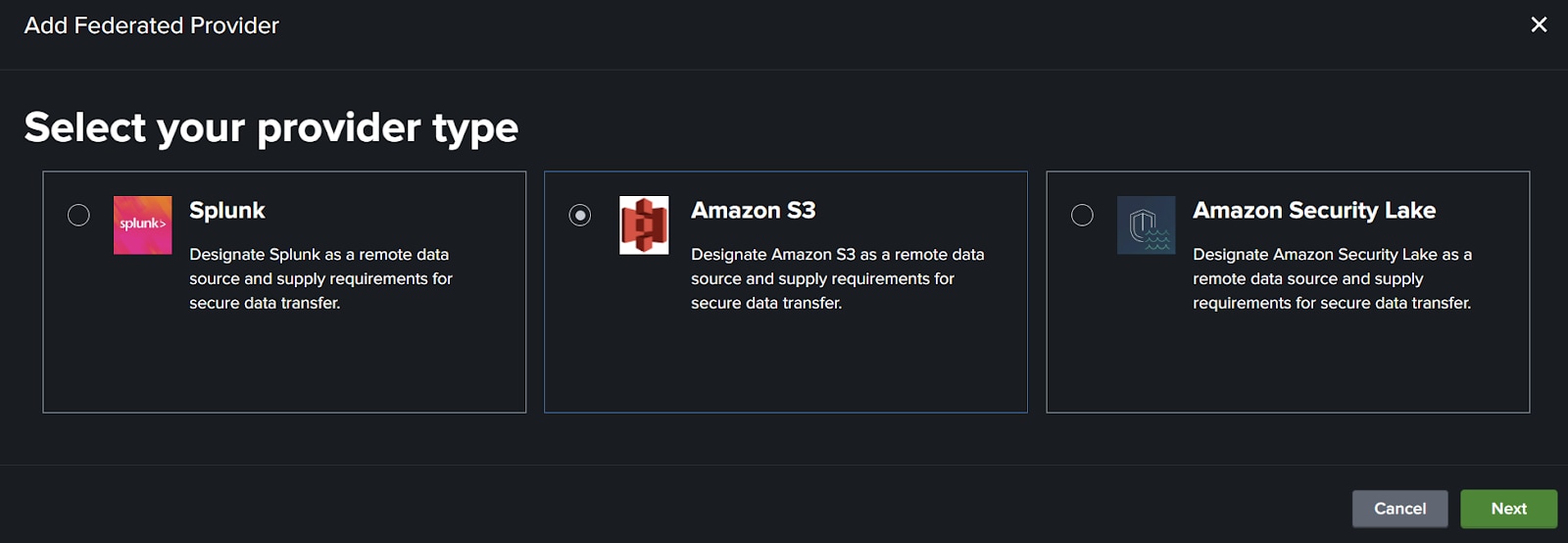
4. 次のページで以下の項目を入力します。
データを入力した画面の例を次に示します。
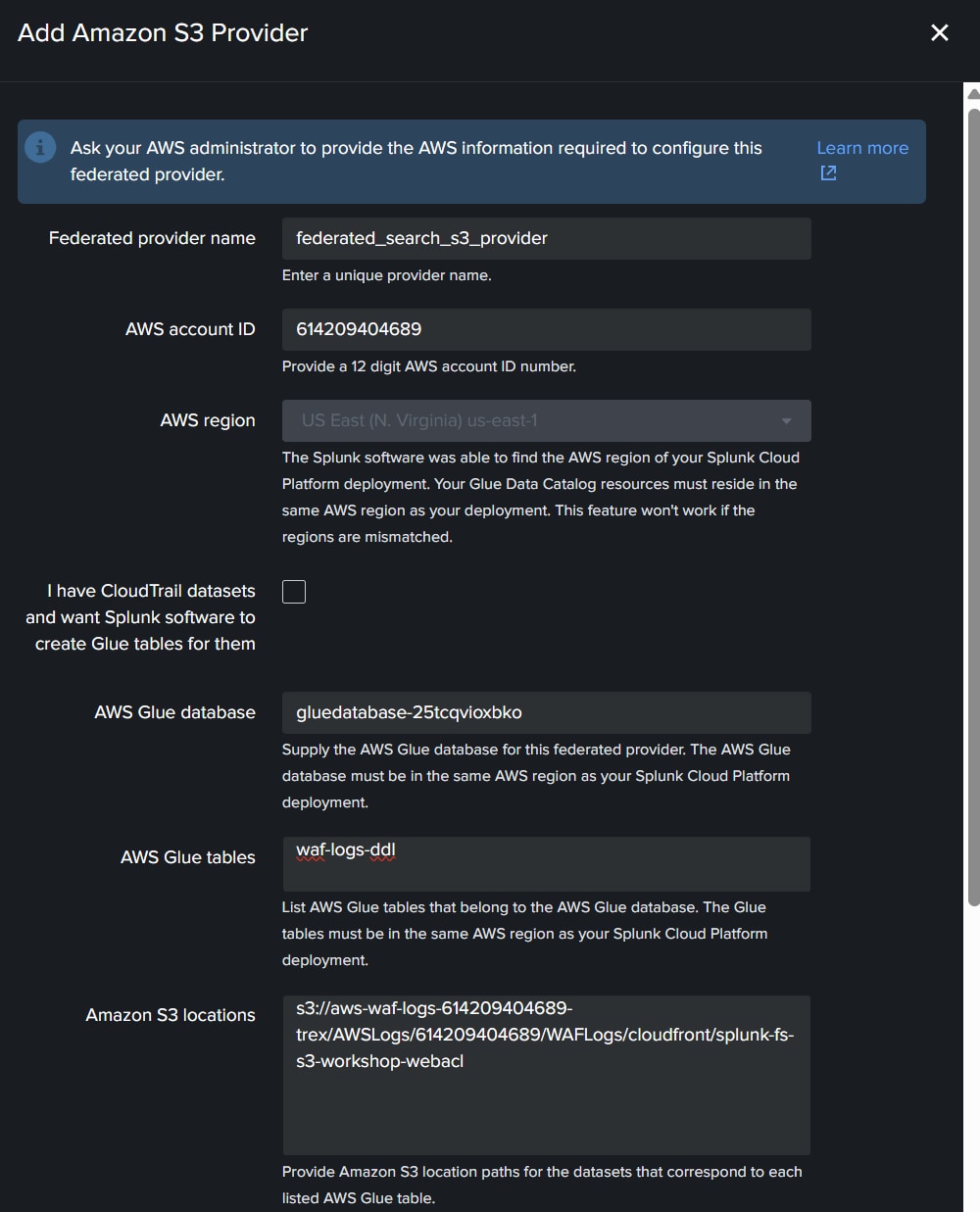
5. すべての設定を入力したら、[Generate Policy]ボタンをクリックします。
6. [Glue Data Catalog resource policy]に表示されたポリシーをコピーします。
7. Glueのタブに戻り、左側のメニューで[Catalog Settings]セクションを選択します。
警告:ここにポリシーがすでに入力されている場合は、十分に注意してポリシーを結合してください。
8. Splunkからコピーしたポリシーを貼り付けるか、既存のポリシーに結合して、[保存]をクリックします。
9. Splunkの統合プロバイダー画面に戻り、S3バケットポリシーを展開して、コピーします。
10. AWS WAFログを設定するために開いていたS3バケットのタブに移動します。最上位のフォルダーに戻り、[アクセス許可]タブを選択します。
警告:ここにもS3バケットのポリシーがすでに入力されていることがあります。十分に注意して、Splunkからコピーしたポリシーを既存のポリシーに結合してください。
11. S3バケットポリシーを貼り付けるか、既存のポリシーに結合します。入力内容を確認して[保存]をクリックし、Splunkの画面に戻ります。
12. Splunkの権限の設定が完了したので、両方の同意ボタンにチェックマークを付けて、[Save]をクリックします。
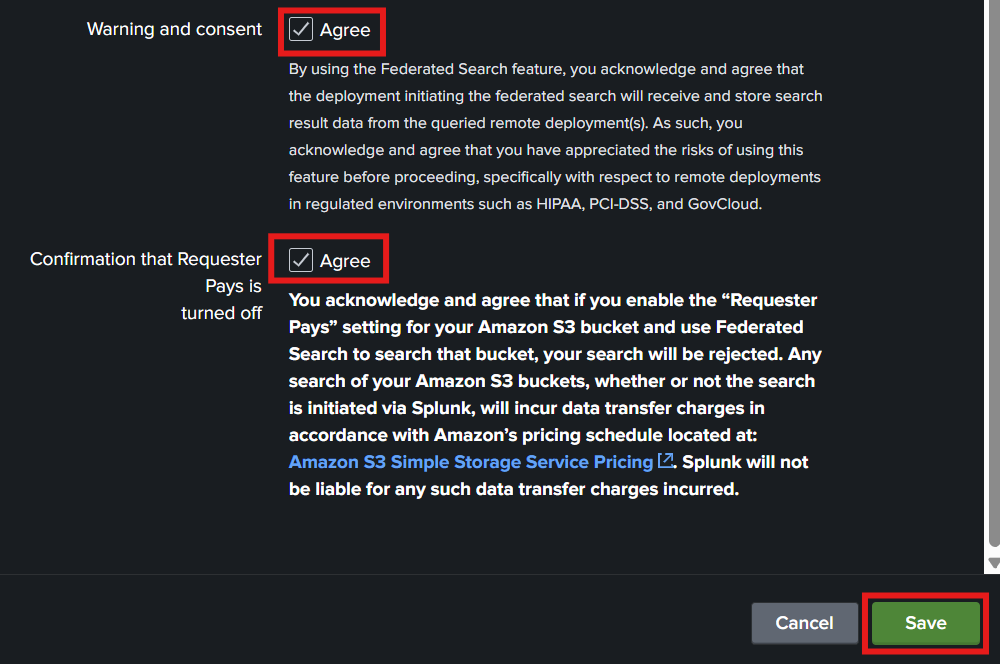
これで、統合プロバイダーの作成は完了です。続いて、AWS WAFログの統合インデックスを作成します。
フィールドを入力した画面の例を次に示します。
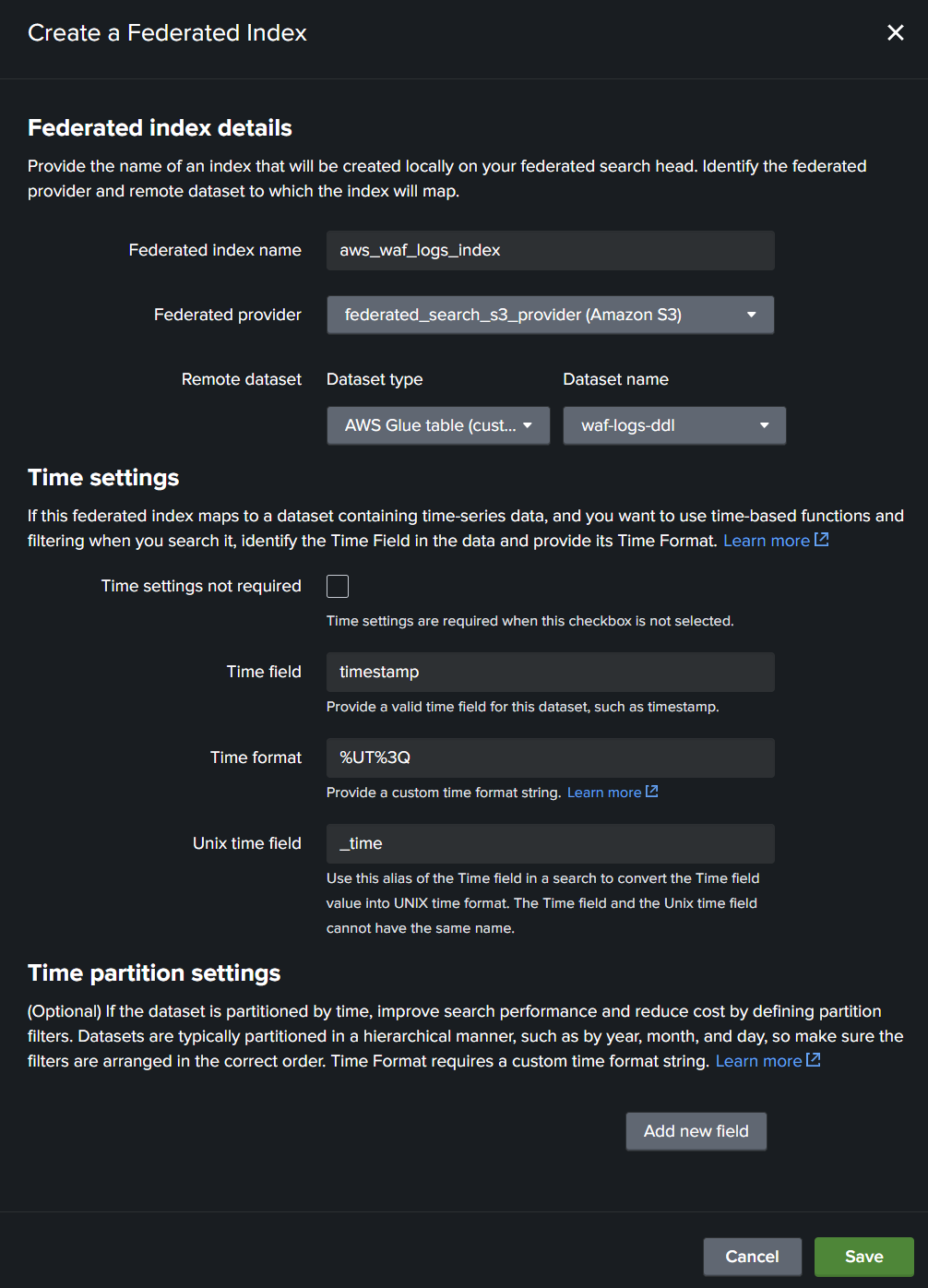
入力内容を確認して、[Save]をクリックします。
これで、統合プロバイダーと統合インデックスの作成が完了しました。統合サーチが正しく機能するかどうか確認してみましょう!
| sdselect * from federated:aws_waf_logs_index limit 100
注:権限が正しく反映されるまでに1~2分かかることがあります。1~2分待てば、次のような結果が表示されるはずです。
これで完成です!SplunkとAWS間の接続を設定して、AWS WAFログをインプレースサーチできるようになりました。
ブログ記事を終える前に、「それで、どう使えばいいの?」という疑問に簡単にお答えしましょう。
統合サーチについてSplunkユーザーと話をすると、最大の課題は、私が「ラーニングパスのフェーズ3」と呼んでいる部分であることがよくあります。
統合サーチが何に役立つかを考えるときは、そもそもこの機能が何のために存在するのか、その主な理由を押さえておくことが大切です。
統合サーチは、データ分析によるリアルタイムの脅威ハンティングのために作られたのではありません。稀にまたはアドホックで実行するデータサーチで使うことを目的としています。
統合サーチの一般的なユースケースをご紹介する前に、統合サーチの課金モデルについて簡単にご説明します。
Splunk統合サーチでは、「スキャンデータ単位」と呼ばれる課金モデルが採用されています。これはSplunk独自の課金モデルというわけではなく、この市場で広く使用されています。基本的には、一定のデータ量を事前に購入し、所定のテラバイト数を使い切ったら追加購入が必要になる仕組みです(プリペイド携帯プランのようなものです)。
データに対してサーチを実行するたびに、Amazon S3バケット内でスキャンしたデータ量に基づいて、事前購入したデータ量が消費されます。課金対象が、返されたデータではなく、スキャンしたデータであることに注意してください。つまり、S3バケット全体を対象とする非効率なサーチを実行すると、ライセンスを大量に消費することになります。このブログ記事では、サーチを効率的に行う方法やサーチの最適化については扱いません(パート1で触れたコースで取り上げる予定です!)。
ライセンスモデルについて理解したところで、本題の「どう使えばいいのか」の例となるユースケースをご紹介しましょう。
統合サーチの一般的なユースケースの中で、「どう使えばいいのか」を深く理解するために特に役立つユースケースが3つあります。
ユースケース1:フォレンジック調査
脅威ハンティングとフォレンジック調査の違いを考えてみましょう。脅威ハンティングでは、フラグを立てるべき異常な行動を継続的に追跡します。そして、脅威ハンティングで見つかった脅威を調べるのが、フォレンジック調査です。
フォレンジック調査では、通常、対象を特定の時点に絞り込みます。たとえば、今週、今月、今日などです。このタイプのサーチでは、対象が非常に具体的で限定されているため、統合サーチが効果的です。これはインプレースサーチに適した2つの主要な条件を満たしています。
これにより、特定時点までのデータ(とライセンス)を使用して、非常に効率的にサーチできます。
ユースケース2:履歴分析
統合サーチを使って、過去のデータに関する統計を生成できます。たとえば、Amazon S3に非常に長い期間データを保存している場合、そのデータのサブセットを時系列で抽出してレポートを作成し、特定の情報の傾向を把握できます。
これもまた素晴らしく効率的な方法です。そのデータをずっとデータプラットフォームに保持していたわけではないにもかかわらず、このようなことが可能です。ユースケース1で説明したようなランダムなサーチではないかもしれませんが、データのサブセットに対して低頻度で実行するため、依然として非常に効率的です。
ユースケース3:データの補強
これも一般的で優れたユースケースです。たとえば、履歴目的でAmazon S3に大量のデータセットを保存していて、そのデータを週次や月次のレポートに詳細として補足したいことがあるかもしれません。
その場合は、統合サーチが最適です。サーチを実行して、返された結果を既存のレポートやサーチ結果に追加したり、レポートや分析に追加データとして組み込んで傾向などを示したりできます。
このブログのパート1とパート2で説明した内容の要点は以下のとおりです。
このブログがお役に立てば幸いです。また次のブログでお会いしましょう!
このブログはこちらの英語ブログの翻訳、森本 寛之によるレビューです。

© 2005 - 2026 Splunk LLC 無断複写・転載を禁じます。
© 2005 - 2026 Splunk LLC 無断複写・転載を禁じます。
