盲点と推測を排除し、監視ツールの切り替えの手間を省きましょう。Splunk Observability CloudとAI Assistantを使えば、1つのソリューションですべてのメトリクス、ログ、トレースを自動的に相関付けることができます。

オブザーバビリティの現状
グローバル調査で明らかになった、AI導入、セキュリティチームとのコラボレーション、ビジネス収益の促進要因に関する現状をご紹介します。
Kubernetesはコンテナ化されたマイクロサービスのオーケストレーションを行うための標準システムですが、監視に関するいくつかの課題があります。もっとも、Kubernetesの監視が必須である理由や、基本的な監視方法、およびKubernetes環境から監視データを収集する手段についてはすでに説明しました。
そこで、このチュートリアルでは、Splunk Observability Cloudを使用してKubernetesの主要なテレメトリデータを収集および可視化する方法を、Splunk Infrastructure MonitoringとOpenTelemetryに焦点を当てて詳しく説明します。Splunkは、Kubernetes環境をリアルタイムで可視化し、迅速な問題の特定、トラブルシューティング、対応を可能にします。
ではさっそく始めましょう。
Splunk Infrastructure Monitoringは、環境内のあらゆるレイヤーとの統合を通じて、アプリケーションに対するエンドツーエンドのオブザーバビリティを実現します。そしてその対象には、Kubernetesベースのアプリケーションも含まれます。OpenTelemetry Collector for KubernetesのSplunkディストリビューションを使用すると、OpenTelemetry Collectorを簡単にデプロイして、テレメトリデータを受信、処理、エクスポートできるようになります。
Kubernetes環境での動作は以下のとおりです。
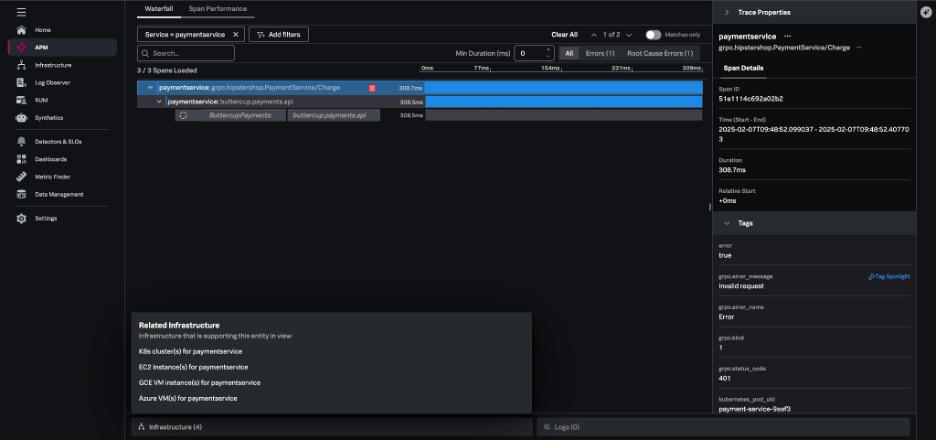
また、Splunk Application Performance Monitoring (APM)では、マイクロサービスのインスタントトラブルシューティングも利用できます。この機能は、関連コンテンツを使用してスタック全体でメトリクスとトレースを関連付けることで、送信されたアラートからその問題の根本原因へとユーザーをガイドします。
次に、Kubernetesのメトリクスを収集する方法をいくつか見てみましょう。
クラウドプロバイダーによって管理されているKubernetesクラスターで基本的な監視を実行する場合は、アマゾン ウェブ サービス(AWS)、Azure、GCPなどのサービスをSplunk Infrastructure Monitoringと直接連携させることでデータを収集できます。これは比較的シンプルな方法で、エージェントをインストールすることなく、Kubernetesメトリクスを収集できます。
ただし、以下のような欠点があります。
Prometheusは、Kubernetesメトリクスの可視化を考える際に第一の選択肢となるソフトウェアです。Prometheusレシーバーを使用すると、OpenTelemetry CollectorのSplunkディストリビューションは、テレメトリをPrometheus形式で公開している任意のソースからメトリクスを収集できます。そのため、Splunk Observability Cloudへのメトリクスの送信が極めて簡単になります。
また、OpenTelemetry Collectorを使用すれば、Prometheus形式のメトリクスをOpenTelemetryの該当する形式に自動で変換できます。
OpenTelemetry CollectorのSplunkディストリビューションは、テレメトリデータを受信して処理し、Splunkにエクスポートするための統一された方法を提供します。
Collectorをデプロイして設定すると、そのCollectorが、環境内で実行されているサービスからテレメトリデータを動的に検出して収集します。Kubernetes環境内では、DaemonSetによってCollectorが展開され(Kubernetesクラスター内の各ノードに1つのコピーが配置されます)、各エージェントのインスタンスが、同じノード上で実行されているサービスを監視します。
さらに、OpenTelemetry CollectorのSplunkディストリビューションは、メトリクスを報告する間隔がデフォルトで1秒に設定されているため、Kubernetes環境のエフェメラルで動的な特性にとりわけ適しています。
Collector for Kubernetesのインストールは、Helm 3.0クライアントを使って以下の3つの手順に従うだけで完了します。
では、順番に説明しましょう。まず、以下のコマンドを使用して、Splunk OpenTelemetry Collector for KubernetesのHelmチャートのリポジトリを追加します。
$ helm repo add splunk-otel-collector-chart https://signalfx.github.io/splunk-otel-collector-chart
以下のコマンドを使用して、リポジトリを最新の状態にします。
$ helm repo update
Kubernetesクラスターで以下のコマンドを実行してSplunk OpenTelemetry Collector for Kubernetesをインストールします。設定値はそれぞれのニーズに合わせて変更してください。
$ helm install splunk-otel-collector --set="splunkObservability.accessToken=<ACCESS_TOKEN>,clusterName=<CLUSTER_NAME>,splunkObservability.realm=<REALM>,gateway.enabled=false,splunkObservability.profilingEnabled=true,environment=<ENV>,operator.enabled=true,certmanager.enabled=true,agent.discovery.enabled=true" splunk-otel-collector-chart/splunk-otel-collector
最後に、cert-managerがデプロイされている場合は、certmanager.enabled=trueを上記のコマンドから必ず削除してください。これは、cert-managerの2つのインスタンスを同じノードで実行できないためです。
上記のCollectorのインストールコマンドにより、自動検出とゼロコードインストルメンテーションが利用可能になります。自動検出を有効にすると、Collectorがメトリックとトレースを自動的に識別して収集するため、手動での設定は不要です。また、自動検出はKubernetes環境内のサードパーティサービスでも利用できます。これには、Kubernetes環境で実行されているデータベースやWebサーバーも含まれます。
さらに、Java、Node.js、および.NETのバックエンドアプリケーションのゼロコードインストルメンテーションにより、実行中のアプリケーションからデータを取得することができます。以下の作業は不要です。
Collectorのインストールコマンドが正常に実行されると、Splunk Infrastructure MonitoringのKubernetes Navigator内でKubernetesデータを数秒で検索できるようになります。また、サポートされているアプリケーションのデータが、Splunk APMに表示されるようになります。
Splunk Infrastructure Monitoringのナビゲーターはリソースのコレクションであり、サービスのさまざまなインスタンス全体のメトリクスとログを監視し、パフォーマンスの異常値を簡単に検出するのに役立ちます。ナビゲーターは、システムインフラをリアルタイムで確認できるビューを備えており、重要な健全性メトリクスに関するアラートをわかりやすく通知したり、見やすい画面で可視化したりできます。
ナビゲーター内のチャートには、OpenTelemetry Collectorからエクスポートされたメトリクスが表示され、以下のような環境内の要素をすばやく掘り下げて分析できます。
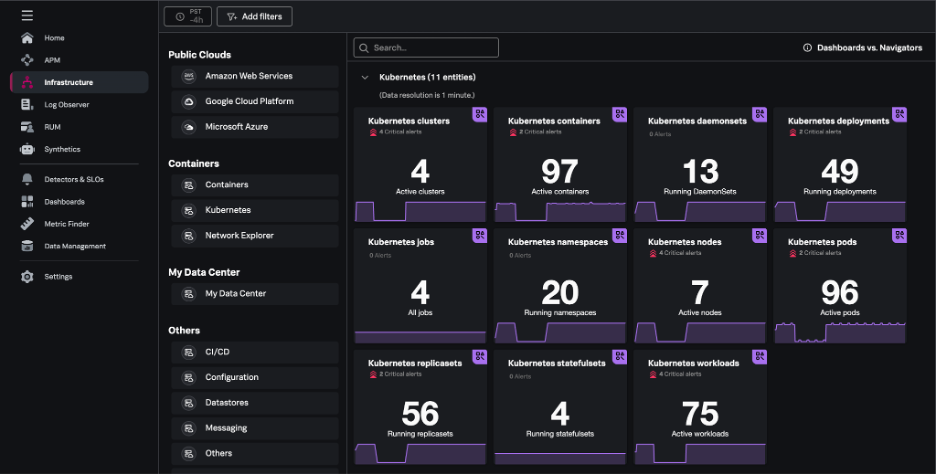
Splunk Observability Cloudでは、[Infrastructure]ページの[Kubernetes]セクションで、Kubernetes Navigatorのサマリーカードを確認できます。
Kubernetes Navigatorでは、Kubernetes環境の重要な要素ごとにナビゲーターが用意されています。用意されているナビゲーターは、クラスター、コンテナ、Pod、ノード、デプロイメント、ジョブ、ネームスペース、ワークロード、サービス、リソース、DaemonSet、ReplicaSet、StatefulSetなどです。
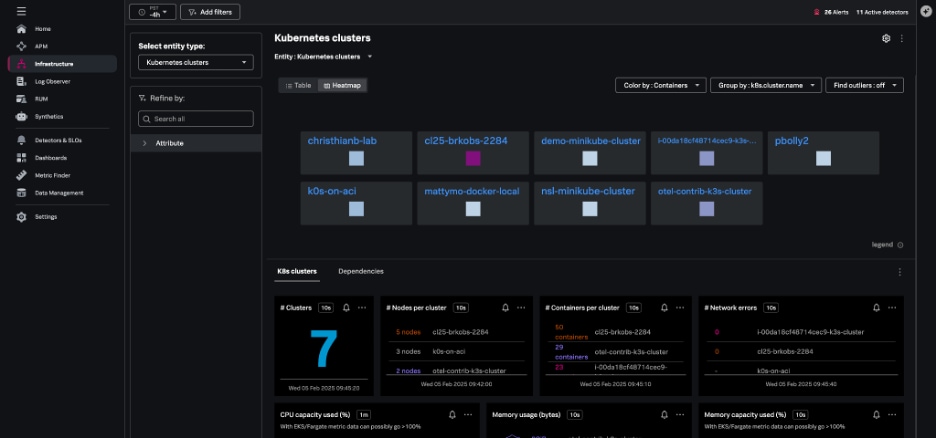
Kubernetesクラスターナビゲーターは、Splunk Infrastructure Monitoringで監視しているすべてのKubernetesクラスターを対象に、クラスターごとのデータを提供します。これには、以下のデータが含まれます。
クラスターは、テーブル形式またはヒートマップ形式で表示できます。
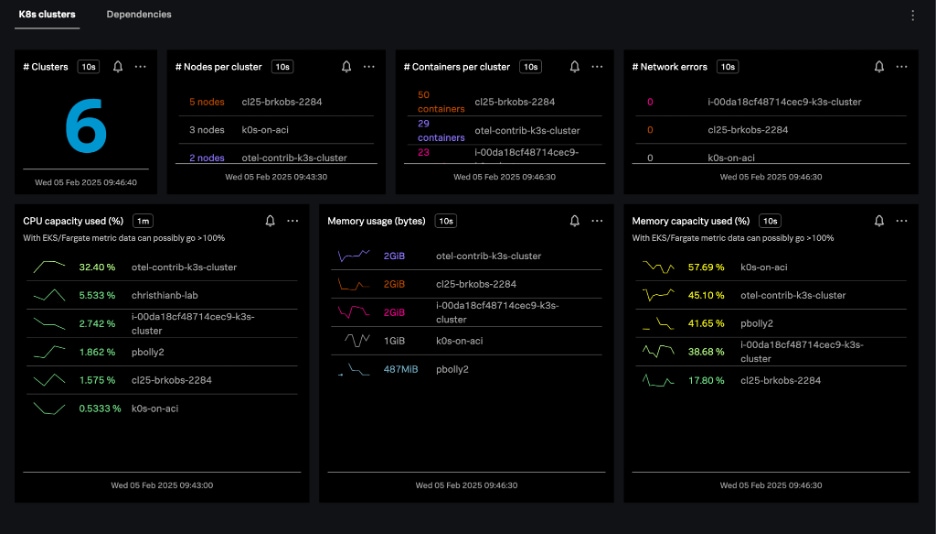
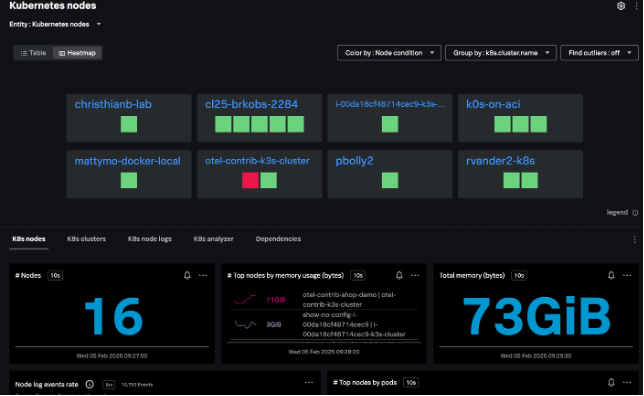
Kubernetesノードナビゲーターは、すべてのノードを対象に、ノード数、Pod、ノードイベント、および集約されたシステムメトリクス(CPU、ディスク、メモリー、ネットワーク)に関する情報を提供します。
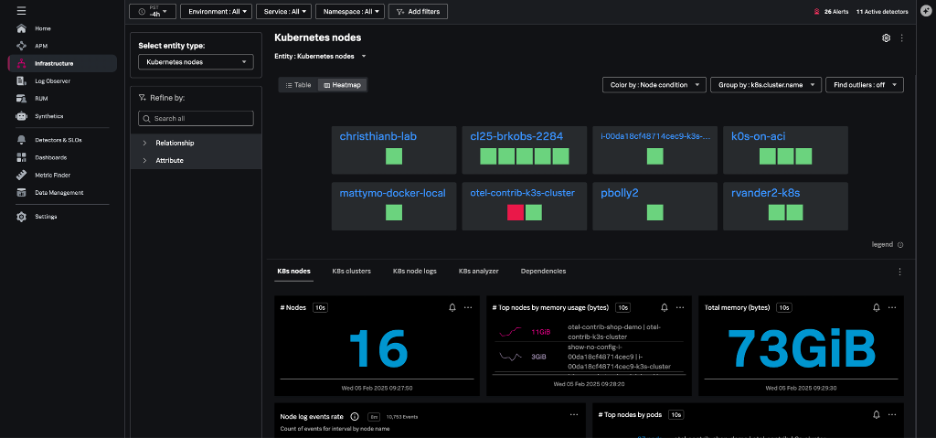
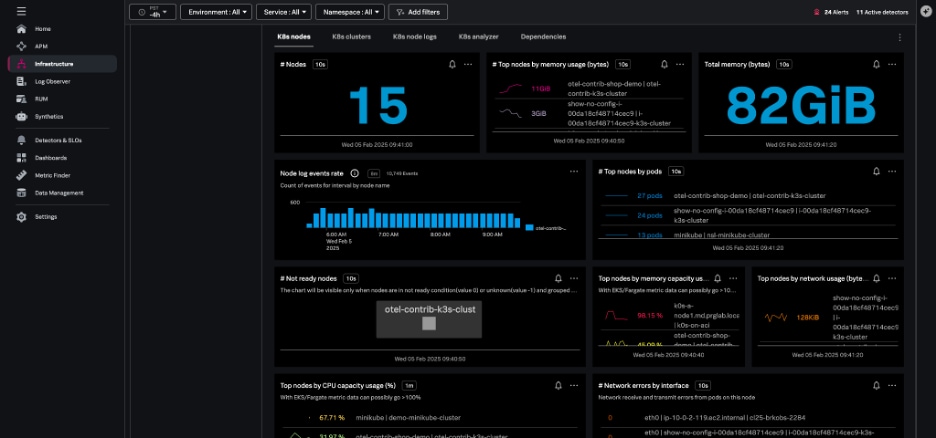
また、クラスターごとのグループとしてではなく、すべてのノードをまとめて表示することもできます。これにより、Kubernetesクラスターの基盤となるインフラの健全性を評価できます。
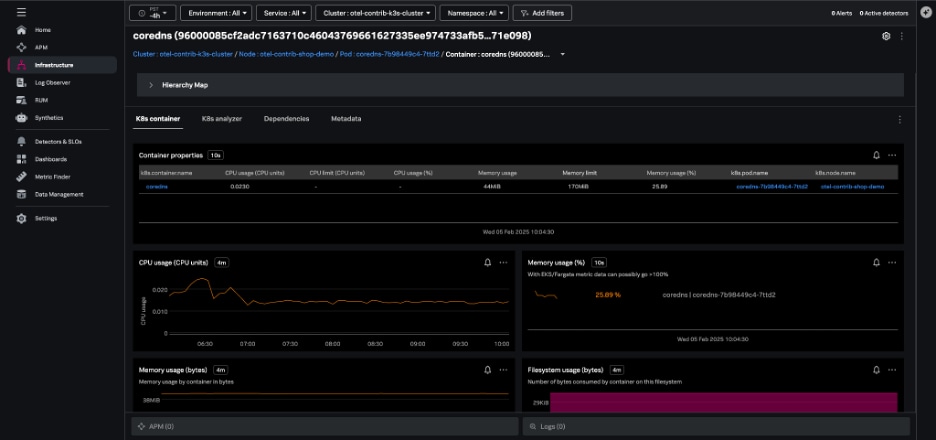
ノードビューでは、階層マップでノード内の各Podが強調表示され、ノードチャートでノードの状態、ワークロード、ネットワーク、およびリソースの使用状況に関する情報が提供されます。このノードビューで個々のPodを選択すると、特定のPodやコンテナにすばやく移動できます。
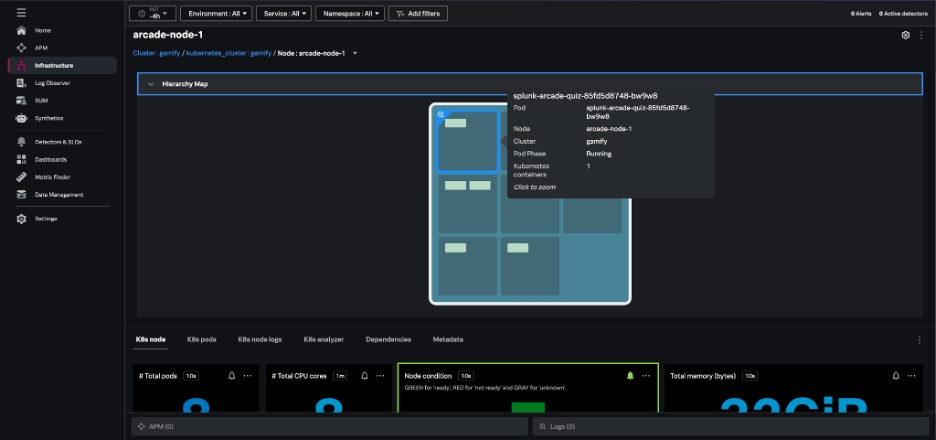
ノードヒートマップとノード階層マップは、Node Ready、Memory Pressure、PID Pressure、Disk Pressure、Network Unavailable、Out of Diskのいずれかの条件に従って色分けされます。
Kubernetes Podナビゲーターを使用すると、ノードナビゲーターと同じ動的フィルタリングやグループ化機能を使用して、特定のPodまたはすべてのPodのアクティビティを追跡できます。
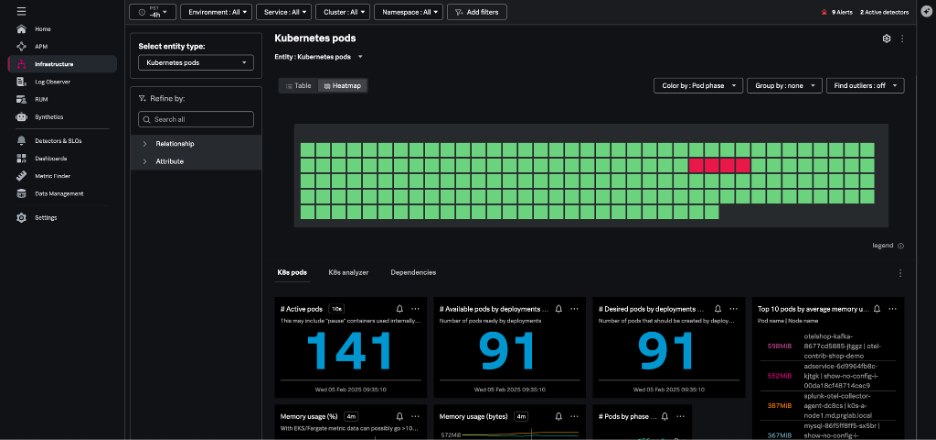
このビューでは、どのPodからでも以下の操作を実行できます。
Kubernetesコンテナナビゲーターには、自社の環境からSplunkにデータを送っている各コンテナが表示されます。
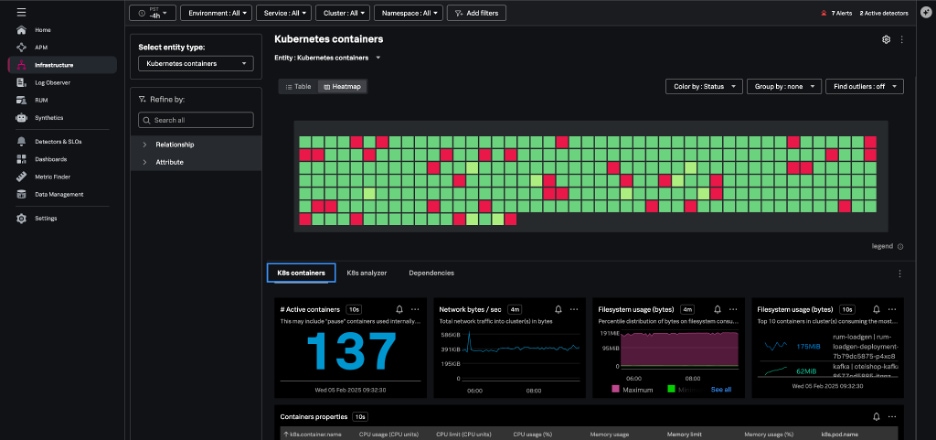
Podビューからここに移動すると、単一のポッドのコンテナのみが表示されますが、Kubernetes関連のディメンションでグループ化やフィルタリングを実行し、特定のコンテナ群を詳しく調べることもできます。
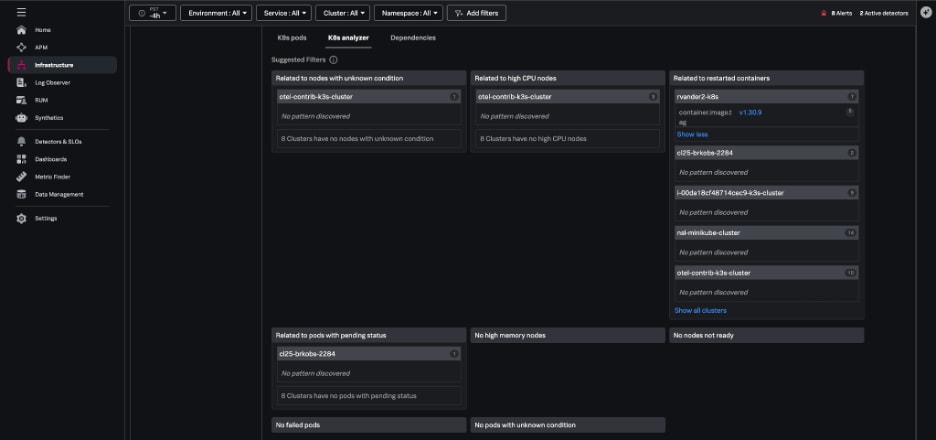
問題が発生すると、[K8s analyzer]タブがAIドリブンなインサイトを活用して、異常な状態のインスタンス(準備が完了していないノードなど)を強調表示して、問題のトラブルシューティングを支援します。Kubernetes Analyzerは、以下のような関連する潜在的な問題や原因を特定します。
Splunk Observability Cloudでは、AutoDetectのアラートとディテクターがデフォルトで自動作成されるため、Kubernetesインフラでよく見られる影響の大きな異常をすばやく検出できます。このディテクターは、以下のような一般的なKubernetesの問題に対してアラートを生成します。
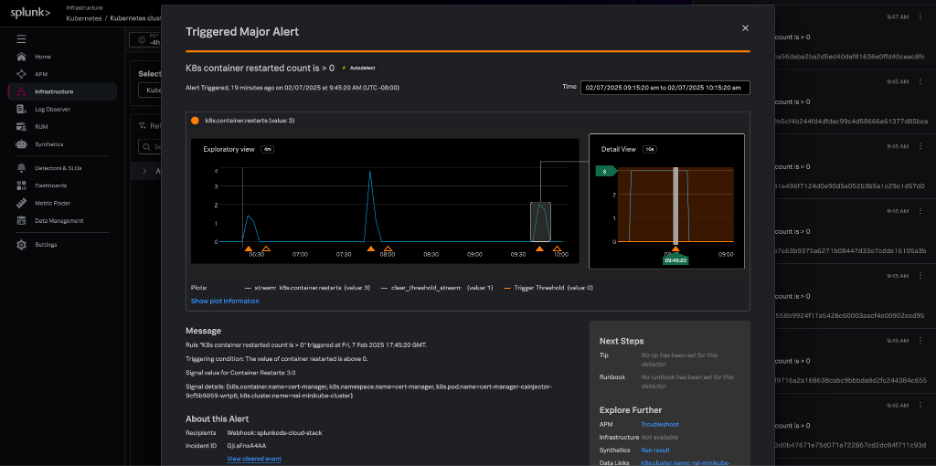
これらのアラートは、Kubernetesナビゲーターのコンテキストに合わせて表示されます。また、ランブック、Splunk Application Performance Monitoring、Splunk Infrastructure Monitoringなどのリソースにある関連コンテンツへのリンクが表示され、迅速なトラブルシューティングを支援します。
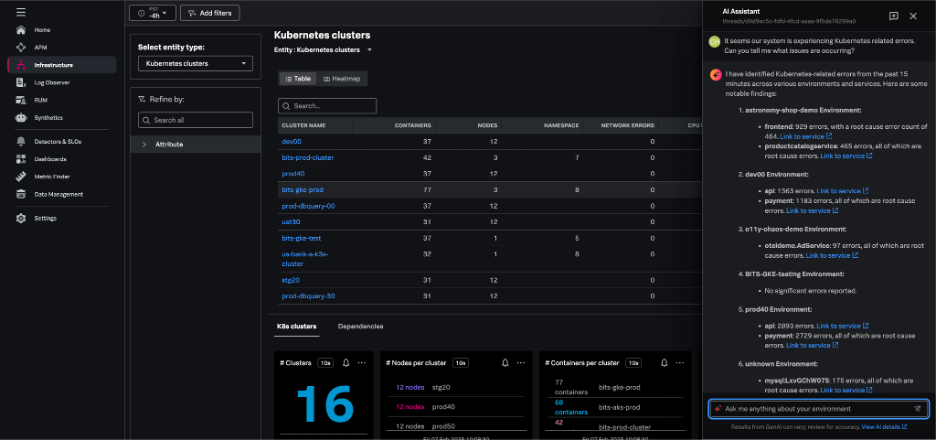
Splunk Observability CloudのAI Assistantを使用すると、エンジニアリングチームのあらゆるメンバーが、コンテキストに応じたトラブルシューティングを簡単に実行し、根本原因と解決策をすばやく特定することができます。
ユーザーは自然言語を使用して、環境のあらゆる部分の健全性に関して、AI Assistantに一般的な質問や具体的な質問をすることができます。すると、AI Assistantがドメイン固有のデータを分析し、トラブルシューティングをステップバイステップでサポートするため、平均解決時間(MTTR)が短縮されます。
Splunk Infrastructure Monitoringをまだ利用しておらず、この記事に関心を持たれた方は、14日間の無料トライアル版をお試しになるか、Splunkのエキスパートにお問い合わせください。

盲点と推測を排除し、監視ツールの切り替えの手間を省きましょう。Splunk Observability CloudとAI Assistantを使えば、1つのソリューションですべてのメトリクス、ログ、トレースを自動的に相関付けることができます。

© 2005 - 2026 Splunk LLC 無断複写・転載を禁じます。
© 2005 - 2026 Splunk LLC 無断複写・転載を禁じます。
