
Digitale Resilienz zahlt sich aus
Wie resilient ist eure Organisation? In diesem kostenlosen Leitfaden erfahrt ihr, wie ihr eure digitale Resilienz steigern könnt.
Anwendungsentwickler und Service-Verantwortliche moderner Unternehmenssoftware sind bei der Behebung von Fehlern und Produktionsproblemen darauf angewiesen, schwache Performance über mehrere Netzwerke, Betriebssysteme, Server, Konfigurationen und Abhängigkeiten von Drittanbietern hinweg identifizieren zu können. Sofern der Code selbst das eigentliche Problem darstellt, hilft das Code Profiling mögliche „Service-Bottlenecks“ schneller ausfindig zu machen. Indem innerhalb einer Laufzeitumgebung regelmäßig CPU Snapshots bzw. Call Stacks erstellt werden. Dadurch lassen sich nicht nur langsame Spans aus Transaction Traces in einen besseren Kontext stellen. Auch die Visualisierung von Bottlenecks durch Flamegraphs wird ermöglicht, um die Performance-Entwicklung von Services über einen bestimmten Zeitraum hinweg abzubilden. Die Vorteile, die sich daraus ergeben sprechen für sich. Ein Großteil aller Code-Profiling-Produkte verursacht jedoch einen beträchtlichen Mehraufwand was die Performance betrifft. Weshalb es für deren Ein- oder Abschalten am Ende doch wieder Techniker braucht. Das Ergebnis: ein Kompromiss zwischen Anwendungsleistung und verfügbaren Daten.
Genau deshalb sind wir besonders stolz, heute die Beta-Version von AlwaysOn Profiling als Teil von Splunk APM vorstellen zu können. AlwaysOn ist zunächst für Java-basierte Anwendungen verfügbar und bietet in Verbindung mit nicht geprüften Trace-Daten eine kontinuierliche Sichtbarkeit der Performance auf Code-Ebene. Und dass bei minimalem Overhead. In Kombination mit Splunk Synthetic Monitoring, Splunk RUM, Infrastructure Monitoring, Log Observer und Splunk On-Call liefert AlwaysOn Profiling Technikern deutlich mehr Kontext, um Performance-Probleme schneller erkennen und etwaige Fehler innerhalb von Produktionsumgebungen zügiger beheben zu können.
Der AlwaysOn Profiler von Splunk APM ermöglicht die kontinuierliche Überwachung der Code-Performance und gibt sofort Auskunft darüber, wo genau Performance-Engpässe auftreten. Wie sich etwaige Probleme innerhalb der Produktion mit Hilfe von AlwaysOn identifizieren lassen, zeigen wir anhand von zwei konkreten Beispielen:
1. Workflow: Anzeige des gemeinsamen Codes in den langsamsten Traces
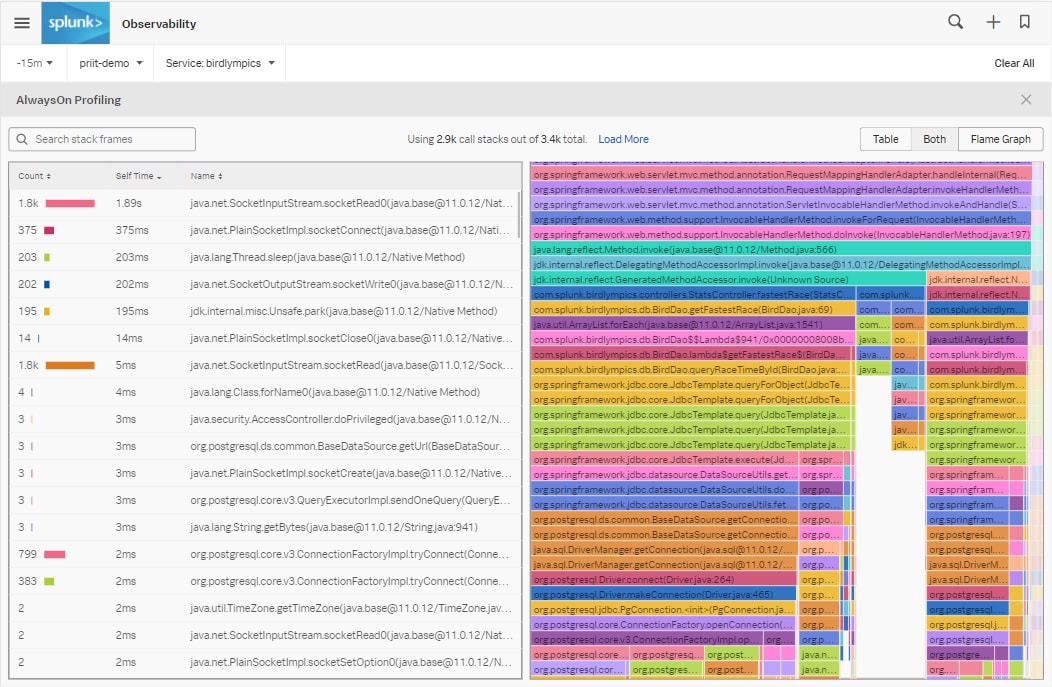
Für die Lösung von Problemen in der Produktion durchforsten Techniker häufig die Beispiel-Traces und suchen nach gemeinsamen Attributen in den langsamsten Spans. Demgegenüber sind die Call Stacks von AlwaysOn mit den Trace-Daten verknüpft und geben Aufschluss darüber, welcher Code bei jedem Trace konkret ausgeführt wird.
Mit APM könnt ihr die Latenzzeiten in eurer Produktionsumgebung bequem einsehen.
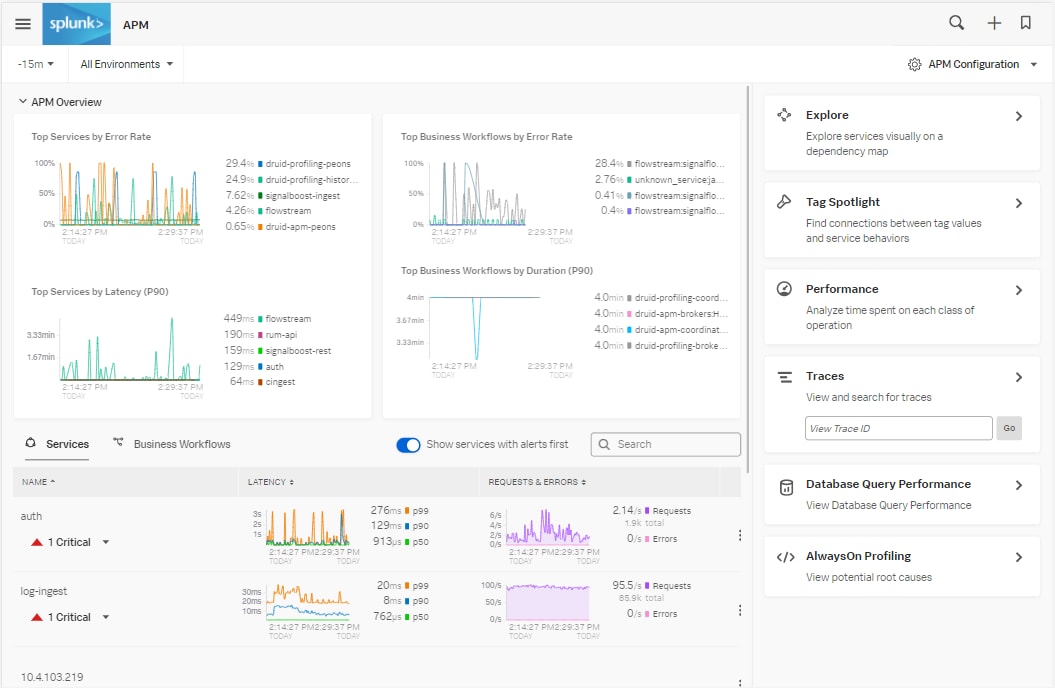
Per Klick auf einen beliebigen Dienst gelangt ihr direkt zu den Service Maps. Diese liefern euch zusätzlichen Kontext zu etwaigen Bottlenecks innerhalb einzelner Services und wovon diese abhängig sind.
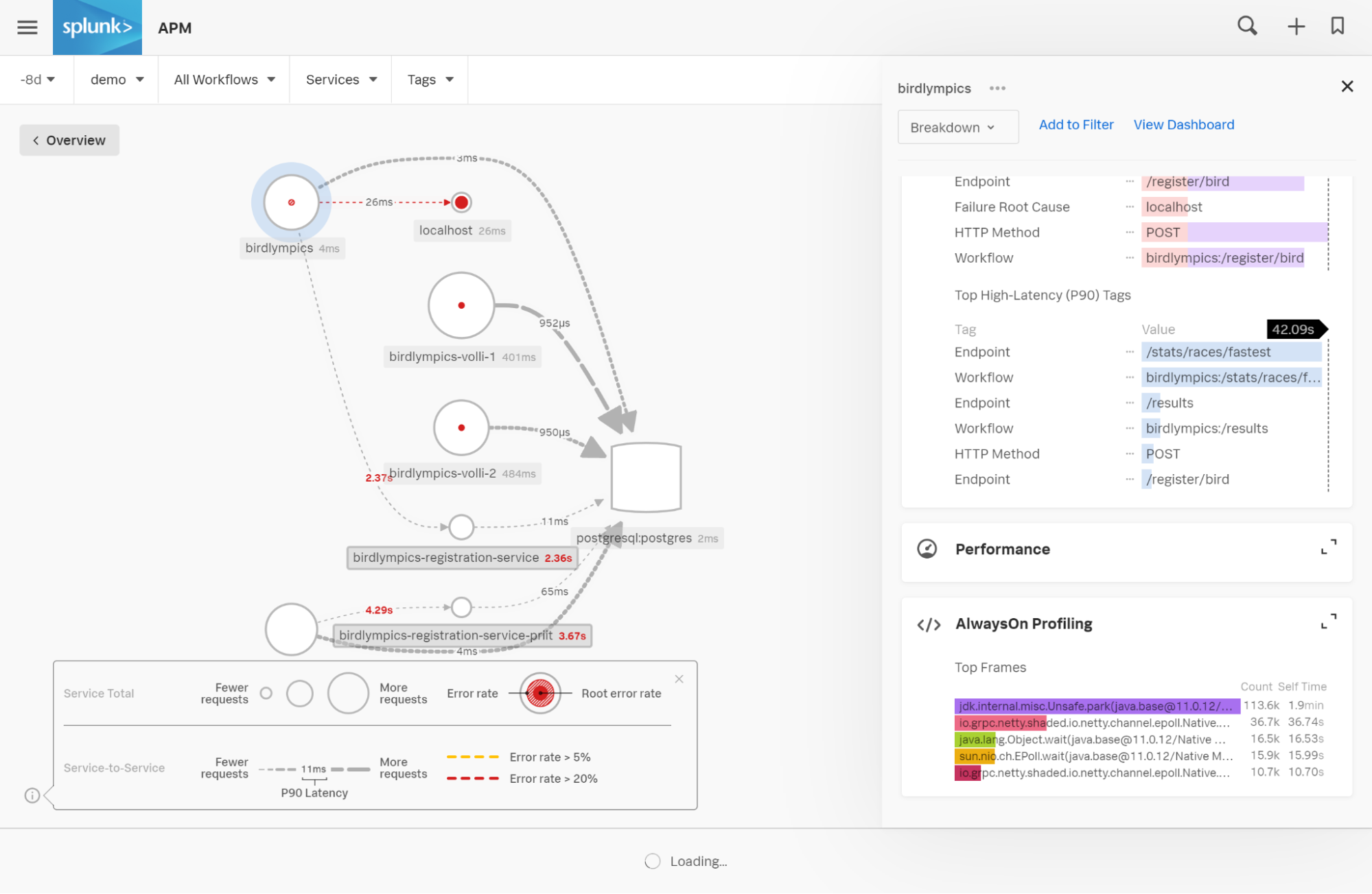
Von hier aus könnt ihr dann beispielhafte Traces genauer untersuchen.
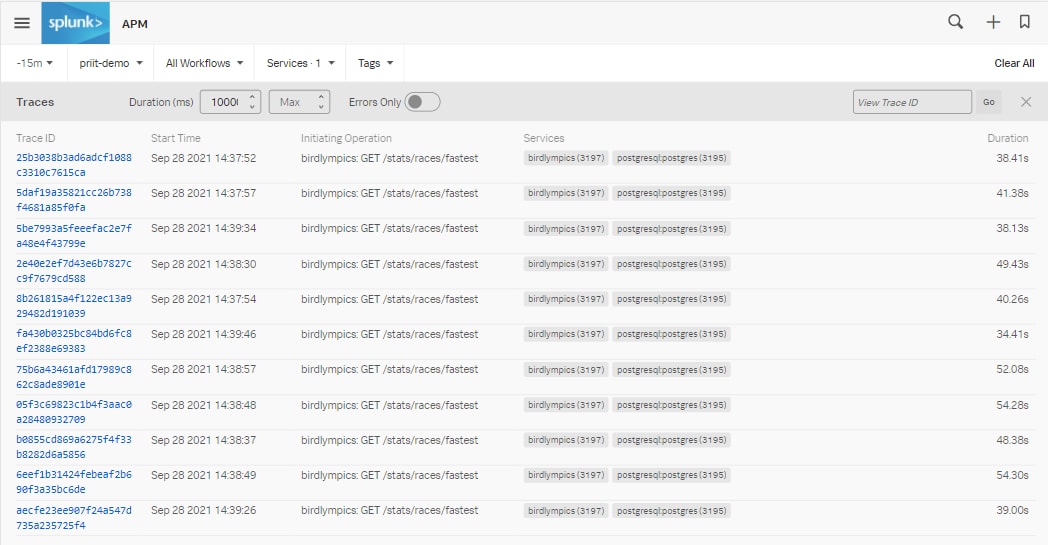
Hinweis: Wir haben die Filterresultate für „min“ auf 10.000 bzw. auf zehn Sekunden beschränkt, um den Fokus auf die langsamsten Traces zu legen. Ebenso könnt ihr hier ablesen, wie die Anfragen für /stats/races/fastest alle 40+ Sekunden wiederholt beantwortet werden.
Per Klick in eine dieser Long Traces öffnet sich die folgende Übersicht:
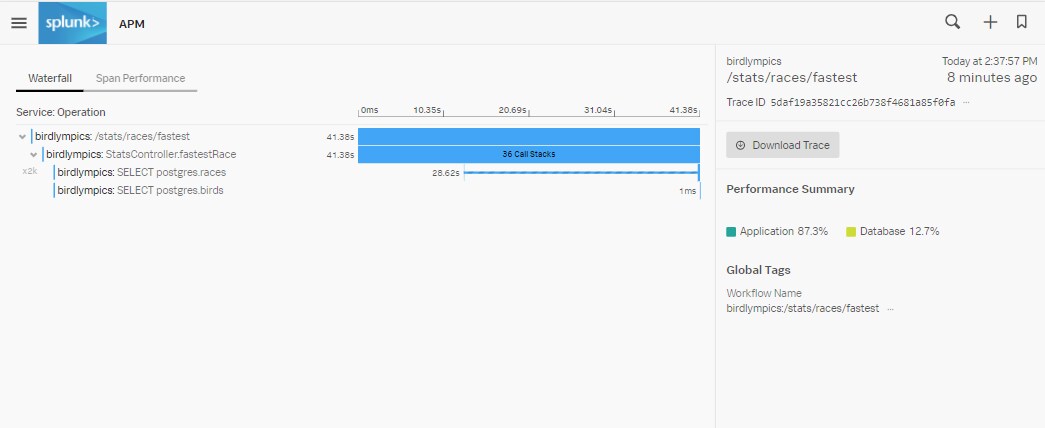
Hier können wir sehen, dass während der Ausführung der „StatsController.fastestRace- Operation“ insgesamt 36 Call Stacks registriert wurden. Da der Java-Agent fortlaufend Call Stacks sammelt, sind bei zunehmender Länge der Spans auch umso mehr Call Stacks vorhanden. Beim Öffnen eines einzelnen Span, werden auf der linken Seite die Metadaten und auf der rechten Seite die Call Stacks angezeigt, die der Agent bisher gesammelt hat. Über die Buttons „Previous“ und „Next“ kann zwischen den einzelnen Call Stacks hin- und hergeblättert werden:
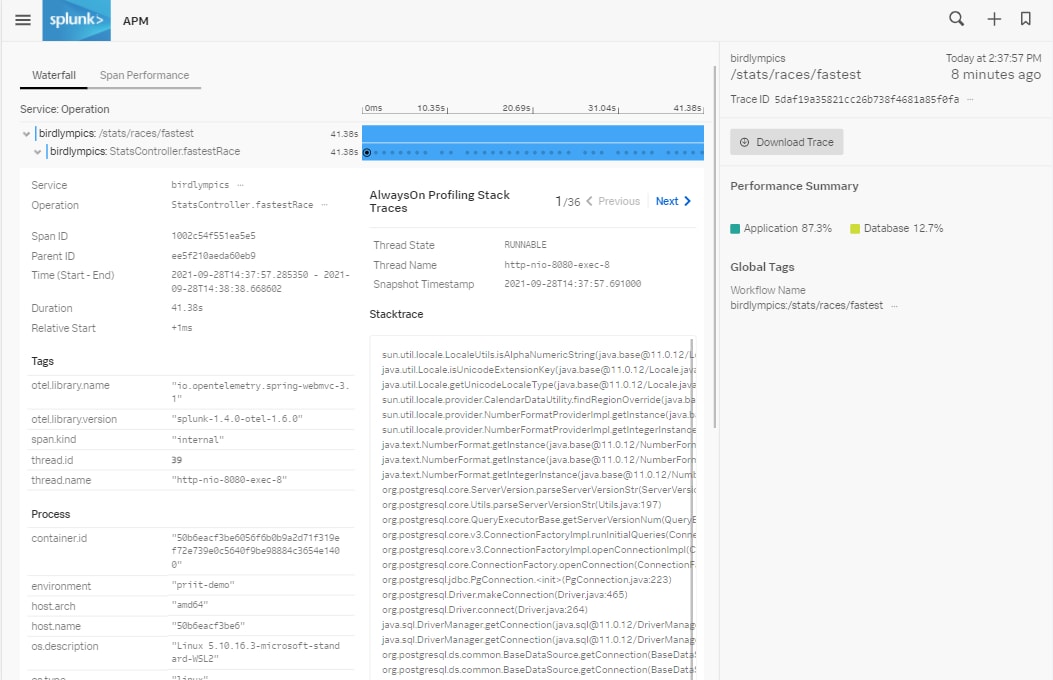
Werden hier mehrere aufeinanderfolgende Call Stacks angezeigt, die auf ein und dieselbe Codezeile verweisen, brauchen diese entweder überdurchschnittlich lange für die Ausführung. Oder müssen gleich mehrfach hintereinander durchgeführt werden. In der Regel ein deutlicher Hinweis auf ein möglichen Performance Bottleneck.
2. Workflow: Betrachtung der aggregierten Performance von Diensten im Zeitverlauf
Bevor ihr jedoch mit der Optimierung eures Codes beginnt, sollte euch klar sein, welcher Teil des Quellcodes die Performance am stärksten beeinträchtigt. Und wie lässt sich am besten herausfinden, welcher Teil des Quellcodes tatsächlich das größte Nadelöhr darstellt? An dieser Stelle hilft die Zusammenführung der gesamten Call Stacks in Form von Flamegraphs.
Beim Blick auf eure Service Map beachtet den Code-Profiling-Zusatz im Panel auf der rechten Seite. Dort werden automatisch die fünf wichtigsten Frames aller Call Stacks angezeigt, die in dem von euch festgelegten Zeitraum gesammelt wurden. Bereits hier findet ihr mögliche Hinweise auf bestehende Bottlenecks im Code.
Per Klick auf dieses Feature werdet ihr zu einem Flame Graph weitergeleitet, der alle innerhalb eines festgelegten Zeitraums gesammelten Call Stack visuell zusammenfasst. Umso größer dabei der horizontale Balken, desto häufiger ist auch die betreffende Codezeile in den gesammelten Call Stacks zu finden.
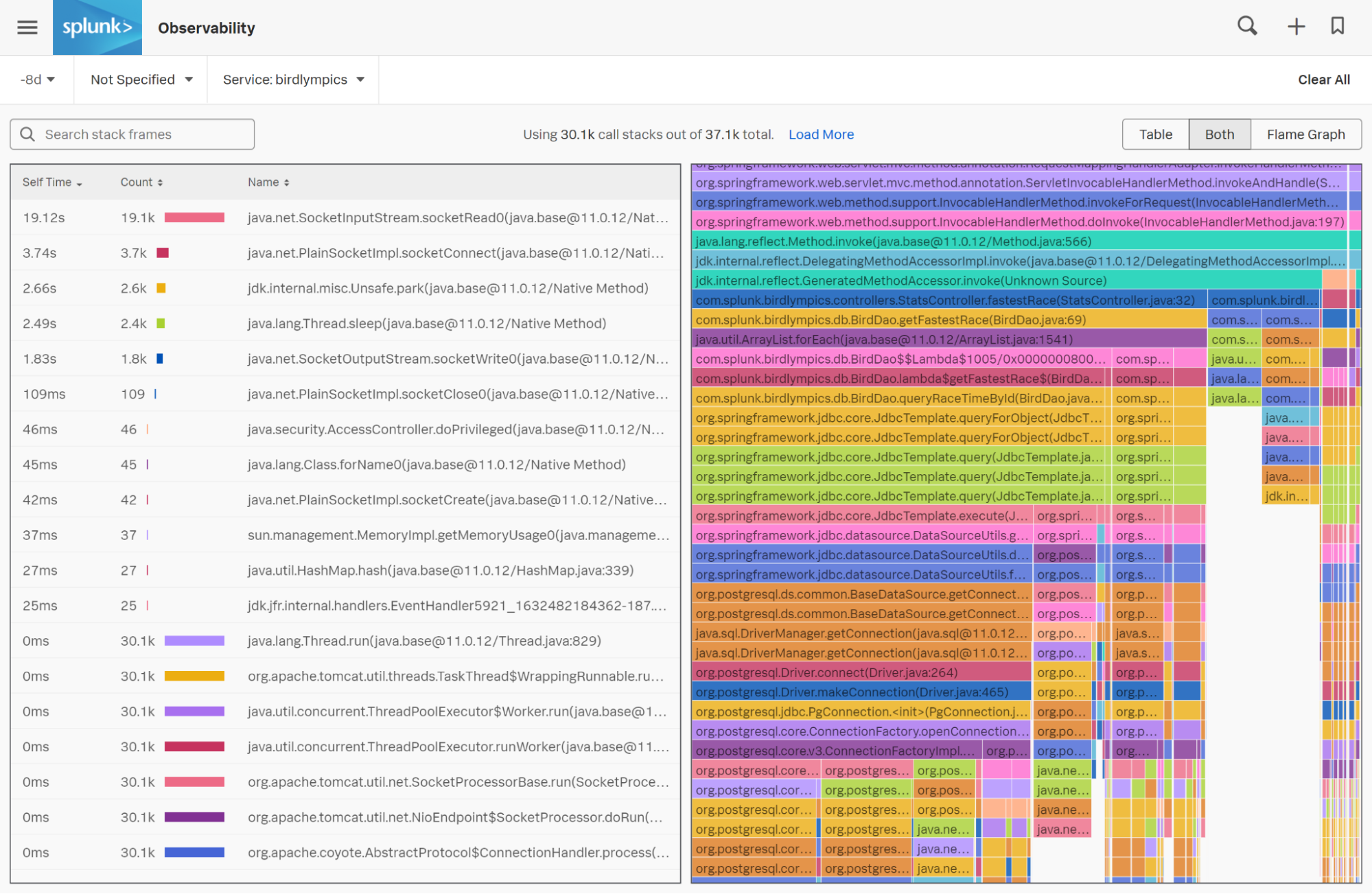
Beim Betrachten des Flamegraphs von oben nach unten solltet ihr euch vor allem auf die größeren „Säulen“ fokussieren. Denn diese geben Auskunft über jene Codezeilen an, die am meisten CPU beanspruchen. Über den Filter in der oberen linken Ecke könnt ihr eure eigenen Code-Klassen im Flamegraph gezielt hervorheben.
In jedem horizontalen Balken des Flamegraphs werden sowohl der Name der Klasse als auch die Zeilennummern eures Codes abgebildet. Darüber hinaus weisen euch Flame Graphs auch auf Bottlenecks hin, die für etwaige Verzögerungen verantwortlich sind. Zuguterletzt führt euch die Fehlersuche zurück zum Quellcode selbst, um das aufgetretene Problem zu beheben.
Im Gegensatz zu dedizierten Code-Profiling-Lösungen ist der AlwaysOn Profiler von Splunk in der Lage, gesammelte Call Stacks mit Spans zu verknüpfen, die zum Zeitpunkt der Sammlung von Call Stacks aktiv ausgeführt werden. Dadurch lassen sich die die Daten zu Hintergrund-Threads besser von aktiven Threads trennen, die eingehende Service-Anfragen bedienen. Auf diese Weise reduziert sich der Zeitaufwand für die gesamte Analyse von Profildaten erheblich.
Durch den Einsatz von AlwaysOn Profiler von Splunk erfolgt die gesamte Datenerfassung zudem vollautomatisch und mit deutlich geringerem Aufwand. Und anstatt den Profiler bei einem Vorfall innerhalb der Produktion jedes Mal manuell einschalten zu müssen, benötigen die Benutzer nur noch einen von Splunk bereitgestellten Open Telemetry Agent einzusetzen, der im Hintergrund kontinuierlich Daten sammelt.
Mit dem „AlwaysOn“ Profiling können Teams, die Splunk APM einsetzen, jetzt Beides auf einmal analysieren und optimieren: sowohl die Intra-Service-Performance von Code-lastigen Monolithen, als auch die Inter-Service-Performance von Micro-Service-basierten Architekturen. Immer mit dem Ziel, mögliche Bottlenecks zu beseitigen und die Service Performance in jeder Phase der Cloud-Migration erfolgreich zu optimieren.
Am besten ihr meldet euch noch heute für die Preview an, um direkt loslegen zu können.
Allen Konversationen auf der #splunkconf21 folgen!
*Dieser Artikel wurde aus dem Englischen übersetzt und editiert. Den Originalblogpost findet ihr hier: Announcing the Preview of Splunk APM’s AlwaysOn Profiling.
----------------------------------------------------
Thanks!
Splunk

Die führenden Unternehmen der Welt vertrauen auf Splunk, einem Unternehmen von Cisco, um ihre digitale Resilienz mit der einheitlichen Sicherheits- und Observability-Plattform, unterstützt durch branchenführende KI, kontinuierlich zu stärken.
Unsere Kunden setzen auf die preisgekrönten Sicherheits- und Observability-Lösungen von Splunk, um die Zuverlässigkeit ihrer komplexen digitalen Umgebungen zu sichern und zu optimieren – in jeder Größenordnung.

Die neuesten Artikel von Splunk, direkt im eigenen Posteingang.
© 2005 - 2026 Splunk LLC All rights reserved.
© 2005 - 2026 Splunk LLC All rights reserved.