
オブザーバビリティの現状
グローバル調査で明らかになった、AI導入、セキュリティチームとのコラボレーション、ビジネス収益の促進要因に関する現状をご紹介します。
カスタムメトリクスの活用 - OpenTelemetryとSplunkオブザーバビリティプラットフォームでNASを監視する
私は、Splunkでの役割上、今日のIT環境を支える複雑なプラットフォームの構築と運用に関する課題について、多くのお客様から話を聞きますが、その内容はほぼ同じです。簡単に言えば、いつ、どの問題が発生したのかを把握するのが難しく、複数の問題が同時に発生することもあり、問題がもたらす影響を定量化できないために優先順位を判断できず、トラブルシューティングや修理を行う適切なチームのアサインが遅れるというものです。状況を明確に可視化して把握し、アラートの量や誤検知を減らして、適切な情報を適切なチームにすばやく提供することは、監視の領域では以前から課題になっていました。しかし今日のデジタルプラットフォームは絶えず変化し、革新的なテクノロジーを取り入れながら進化を続けるため、その難易度が増しています。そのため、プラットフォームを可視化する手段として、オブザーバビリティとその実践のアプローチが非常に重要になっています。
もう1つよく挙げられる課題が、大量に発生するテレメトリデータの処理です。テレメトリデータには、オブザーバビリティの3つの柱であるメトリクス、トレース、ログが含まれます。今日のプラットフォームでは膨大な量のデータが生成され、それを収集できます。しかし、オブザーバビリティの観点でテレメトリデータから価値を最大限に引き出そうとしてデータの収集、処理、分析を行う中で、多くの問題を生み出しています。
こうした議論でよく話題に上るのが、メトリクスです。共通の標準的なメトリクスを取り込めば、プラットフォーム(通常はバックエンドのインフラやアプリケーション)に関する状態を把握できます。さらにカスタムメトリクスを使用すれば、プラットフォームの機能や動作、パフォーマンスなどの詳細な情報や全体像を把握することもできます。全体像がわかれば、SREやDevOpsエンジニア、開発者などの関係者が問題をすばやく理解して原因を究明できるようになります。カスタムメトリクスを活用すれば、多くのお客様が、問題が発生しているかどうかや、発生した問題がプラットフォームにどのような影響を与えるかをもっと明確に把握して、問題への対応を迅速化できるはずです。
オブザーバビリティはもともとエンジニアリング領域の概念であり、実は40年以上の歴史があります。オブザーバビリティの目的は、システムの要素を観測してその状態をすばやく通知し、修正が必要な問題があるかどうかを判断できるようにすることです。その点が従来の監視とは異なり、今日のデジタルプラットフォームで重要とされる理由です。
オブザーバビリティは、監視の新たな呼び名ではなく、今日の複雑なプラットフォームを管理するための新たなアプローチです。そして、このアプローチに基づいてデジタルプラットフォームを管理および運用するには、重要なメトリクスを選定し、カスタムメトリクスを作成できる必要があります。
必要なメトリクスの種類は多岐にわたります。プラットフォームのタイプ、必要な情報、可視化されていない領域、テクノロジースタックの構成、ハイブリッドプラットフォームかどうかなど、必要なメトリクスはさまざまな要因によって決まります。メトリクスは、過去の問題を追跡するために観測して再発を防いだり、プラットフォームやテクノロジースタックの他の部分を可視化してすべてのコンポーネントを漏れなく把握したりするためにも使われます。
カスタムメトリクスを収集すれば、実にさまざまなことが可能です。英国全土をバイクで走るチャリティ活動でOpenTelemetryを使ってデータを収集した同僚のブログ(英語)をぜひチェックしてみてください。メトリクスの収集でOpenTelemetryを使う方法については後ほど詳しく説明します。
今日のチームが直面しているもう1つの課題は、ツールが無秩序に増えていることです。この問題は、監視の領域では数年前から顕在化しており、新しい話題ではありません。しかし、今日の大規模で複雑なプラットフォームと、テクノロジーの急速な進化が相まって、問題がさらに悪化しています。たとえば、新たなテクノロジーを導入すればツールが増えます。さらに、新しいテクノロジーを簡単に観測するためのツールが増えることになります。そのテクノロジー自体にオブザーバビリティツールが付属している場合もあるでしょう。
ツールが増えることの問題点は、多くのツールが他の領域との関連付けやコンテキスト化ができずに特定の領域のみを可視化し、プラットフォーム全体の状態を把握できないことにあります。そしてさらに問題なのが、ツールが増えても可視化できない領域が残ることです。この問題は、開発者が必要に応じて必要な領域だけを可視化するための監視ツールを自身で手軽に作成するという、監視のDIYアプローチとも関係しています。このアプローチでは、必要な領域をすばやく可視化できるメリットがある一方で、データを相関付けできない、ツールが増える、可視化できない領域が残るという問題が増え、全体像の把握をさらに困難にします。しかも、こうしたDIYツールは通常、作成した開発者のみが使用でき、SREやDevOpsエンジニアなど、プラットフォームの管理や運用に関わる他の関係者は利用できないという難点もあります。
今日の複雑なプラットフォームでオブザーバビリティを実現するうえでさらに頭を悩ませている問題が、収集するメトリクスを完全にコントロールすることです。最新のプラットフォームでは、基盤となるテクノロジーの種類が爆発的に増加し、膨大な量のメトリクスが生成されます。従来のインフラでもコンテナやマイクロサービスが導入され、その数が増え続けているため、メトリクスも大幅に増加しています。そのため、オブザーバビリティソリューションを選定する際には、収集できるメトリクスの種類だけでなく、その収集方法も重要な評価ポイントになります。
また、今日では、組織の構成も劇的に変化しています。プラットフォームがコンテナやマイクロサービスによって小さなコンポーネントに分割されるようになり、それに伴ってエンジニアリングチームも各コンポーネントを担当する多数の小規模なチームに分かれるようになっています(これらのチームは一般にトライブやスクラムと呼ばれます)。その結果、チームごとにオブザーバビリティデータや監視データを管理し、監視および観察する対象と収集方法を決めています。中央のチームが監視ツールを選択して他の小規模なチームに提供するといった従来の「集中型」の監視アプローチはもはや機能しません。今日必要なのは、収集するデータを完全にコントロールし、組織と各チームの目標に合わせて収集方法を標準化すること、そして、それらを必要に応じてすばやく変更できるようにすることです。
従来のアプローチでは、基本的に、プラットフォームの監視に必要だと思われる主なメトリクスをベンダーが決め、独自の重い監視エージェントにその収集ロジックを組み込んでプラットフォームにインストールし、さまざまな手法で監視データを抽出およびサンプリングしていました。この戦略の背後には、拡張性を確保し、問題の発生を検知するために「必要十分な」データを提供するという考え方があります。このアプローチは、モノリシックアーキテクチャの時代には有効であったかもしれませんが、今日のマイクロサービスを取り入れた大規模で複雑なマルチテクノロジー環境では通用しません。
今日の環境で従来のアプローチを採用すると、可視化できない領域が生じ、問題の特定、問題の影響の定量化、影響に基づく優先順位の判断が難しくなります。また、データがサンプリングされれば、一部のデータが欠落することになり、収集対象のデータとその収集方法を完全にコントロールできず、トラブルシューティングが困難になることもあります。さらに、ベンダーのアプローチに従ってデータ収集を標準化すると、後で別のベンダーに変更するときに移行が困難になったり、ベンダーのエージェントでサポートされないテクノロジーがある場合に、それを補完する別のオブザーバビリティツールが必要になったりします。
Splunkのソリューションでは、今日の複雑なプラットフォームでオブザーバビリティを実現するために、テレメトリデータの収集にOpenTelemetryを使用しています。この業界標準のオープンソースのアプローチでは、ベンダーに依存しないデータ収集と処理が可能で、プラットフォームから収集するデータとその収集方法を組織が完全にコントロールできます。そのため、テレメトリデータの収集と、組織のプラットフォームに合わせた「標準」のメトリクスなどについて、独自の基準を構築できます。
OpenTelemetryなら、メトリクスの構築について組織全体で共通の言語を確立することもできます。Splunkプラットフォームに組み込まれたOpenTelemetryを使えば、カスタムメトリクスを簡単に作成、収集、送信できます。オブザーバビリティ実現のためにOpenTelemetryが必要である理由については、こちらのブログ記事をご覧ください。
理論を理解したら、次は実践です。今日のホームネットワークによく見られるように、私も自宅のネットワークにNASを接続して、写真や動画、音楽などのさまざまなメディアを保存しています。そして、多くのNASデバイスがそうであるように、私のNASでも、メディアファイルのインデックスサービスなど、多数のバックグラウンドプロセスが動作しています。
ある日、私はこれらのプロセスの処理がときどき遅くなったり停滞したりすることに気付きました。この時、NASのメモリー使用率が100%に達しており、他のアプリケーションを起動または使用できなくなっていました。これらの情報は、NASドライブのパフォーマンスを監視し、問題(特にインデックスサービスの問題)を早期に検出するために重要なメトリクスです。そこで私は、以下のアプローチを使って、NASからこれらの情報を収集し、Splunkオブザーバビリティプラットフォームに送信することにしました。
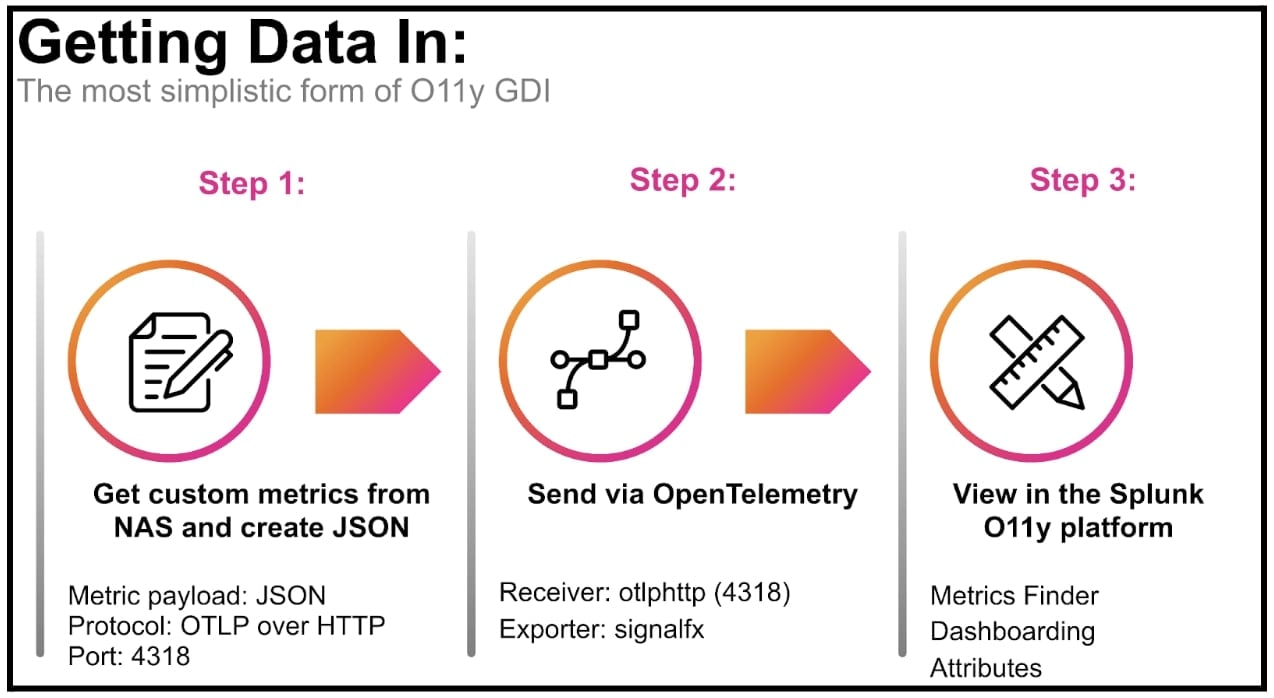
まずは、NASデバイスからメトリクスを収集してJSONファイルを作成し、そのデータをOpenTelemetry Collectorを介してSplunkオブザーバビリティプラットフォームに送信できるようにします。JSON自体がOpenTelemetryのプロトコルと仕様に従っていれば、作業がさらに楽になります。プロトコルの詳細については、こちらを参照してください。
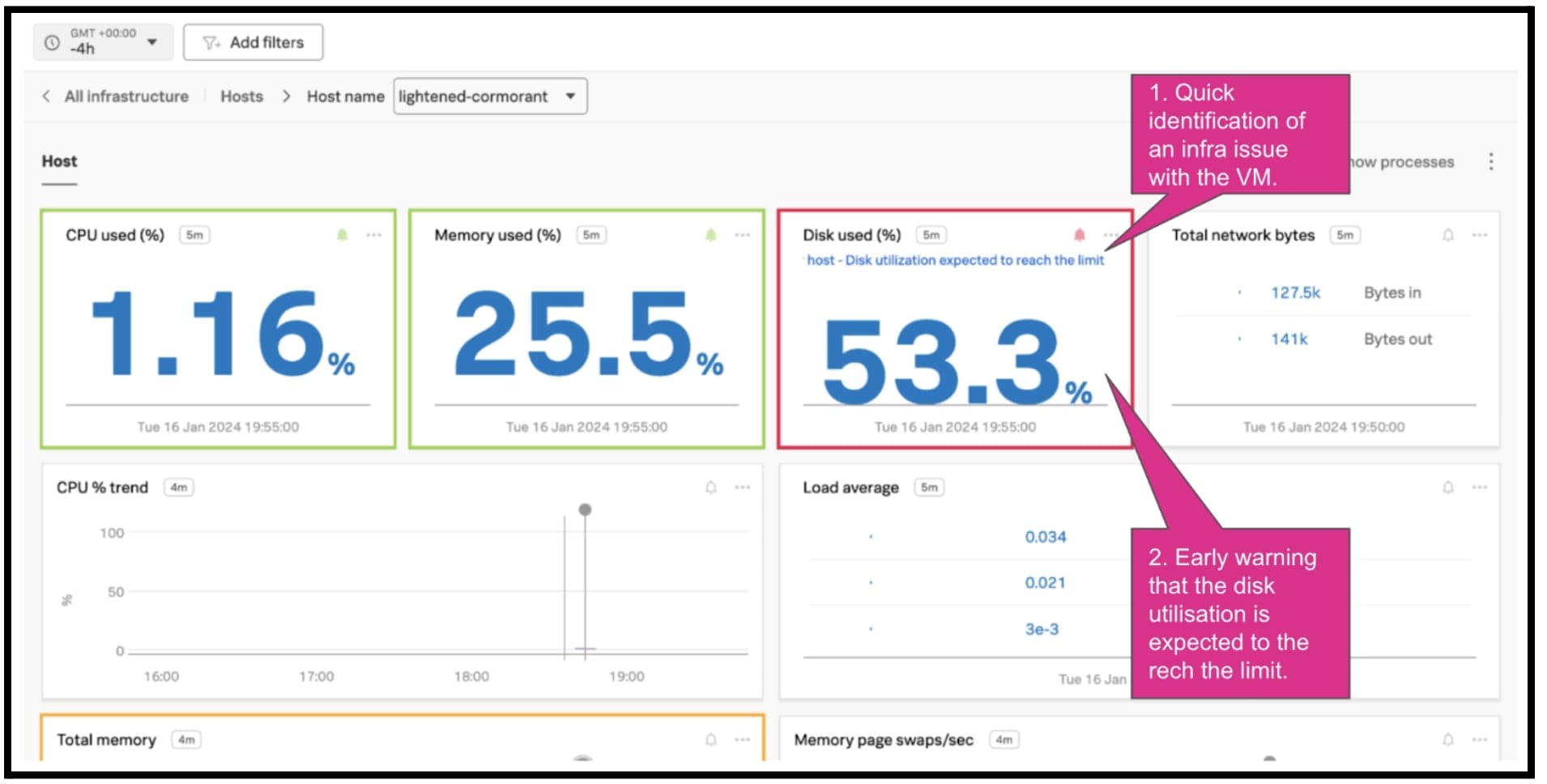
OpenTelemetry Collectorをダウンロードし、小さいVMにインストールしてから、Splunkオブザーバビリティプラットフォームのテナントの認証済みトークンを使ってSplunkとの通信を確立します。OpenTelemetry Collectorのデフォルト設定により、VM自体の観測と監視が自動的に開始され、そのデータをSplunkオブザーバビリティプラットフォームのUIで簡単に確認できます(下図参照)。
すると、さっそく問題が発生しているのがわかります。VMのディスク領域の問題で、ディスク使用率がもうすぐしきい値に達するという警告が出ています。この問題は、VMの設定ファイルを変更すれば解決します。NASのメモリー監視については、簡単なスクリプトを作成しました。このスクリプトではまず、NASドライブに接続し、メモリーに関するメトリクスを収集する一般的なLinuxコマンドを実行して主要なメトリクスを収集します。その後、メトリクスごとにJSONファイルを作成し、OpenTelemetry Collector経由でSplunkオブザーバビリティプラットフォームに送信します。スクリプトによって作成されたJSONファイルの例を次の図に示します。
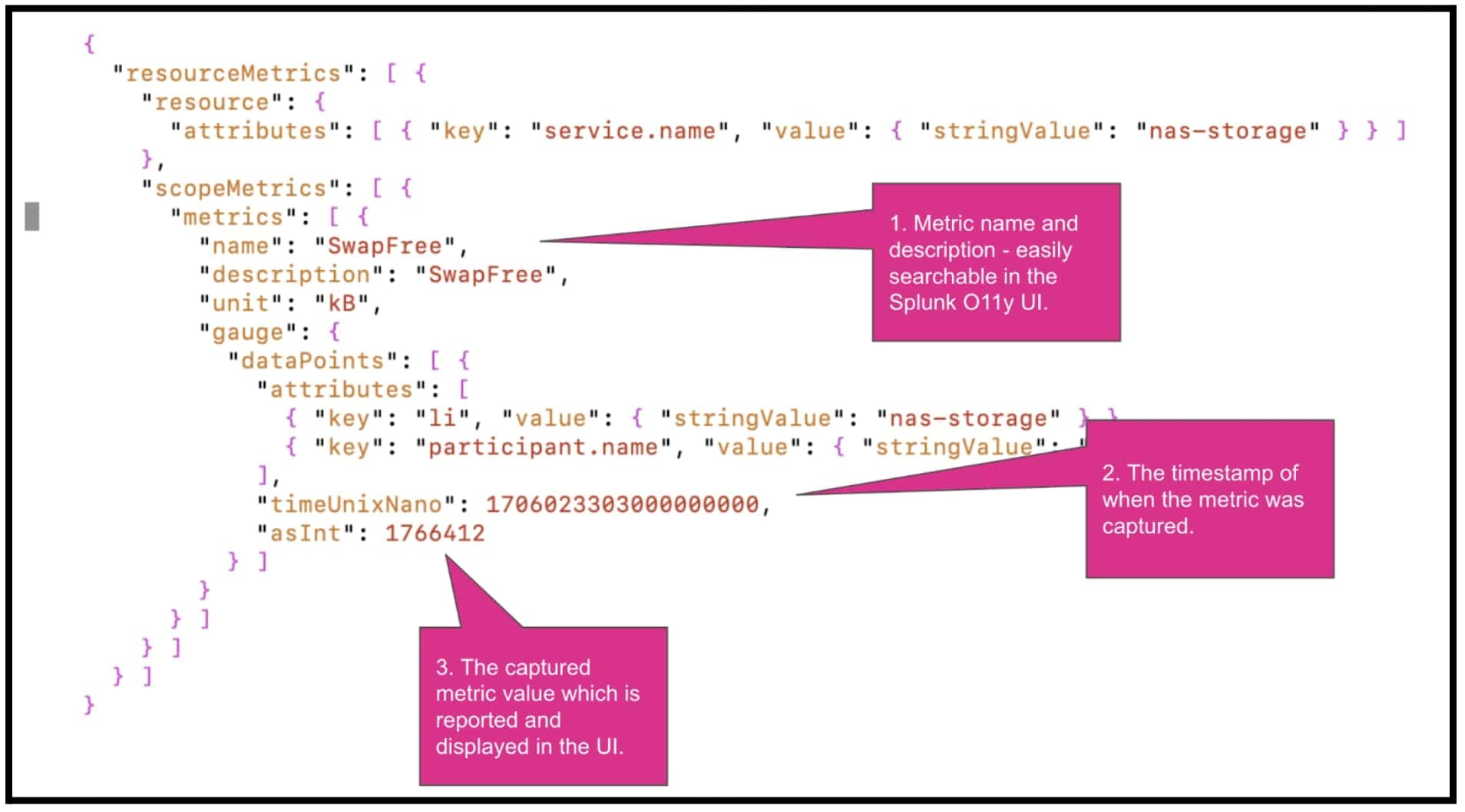
JSONファイルを作成したら、OpenTelemetry Collectorに送信するだけでデータがSplunkのテナントに送信されます。次の図に示すように、コマンドラインでcurlコマンドを使用して、JSONファイルを送信します。この方法なら、メトリクスを収集してプラットフォームに送信する頻度を完全にコントロールできます。

ステップ1でメトリクスデータのJSONファイルを作成したときに、私はサービス名を「nas-storage」と定義しました。Splunkのテナントに送信したメトリクスはすべてこのサービスに含まれるため、次の図に示すように、UIでこのサービス名を使ってメトリクスをすばやくサーチできます。
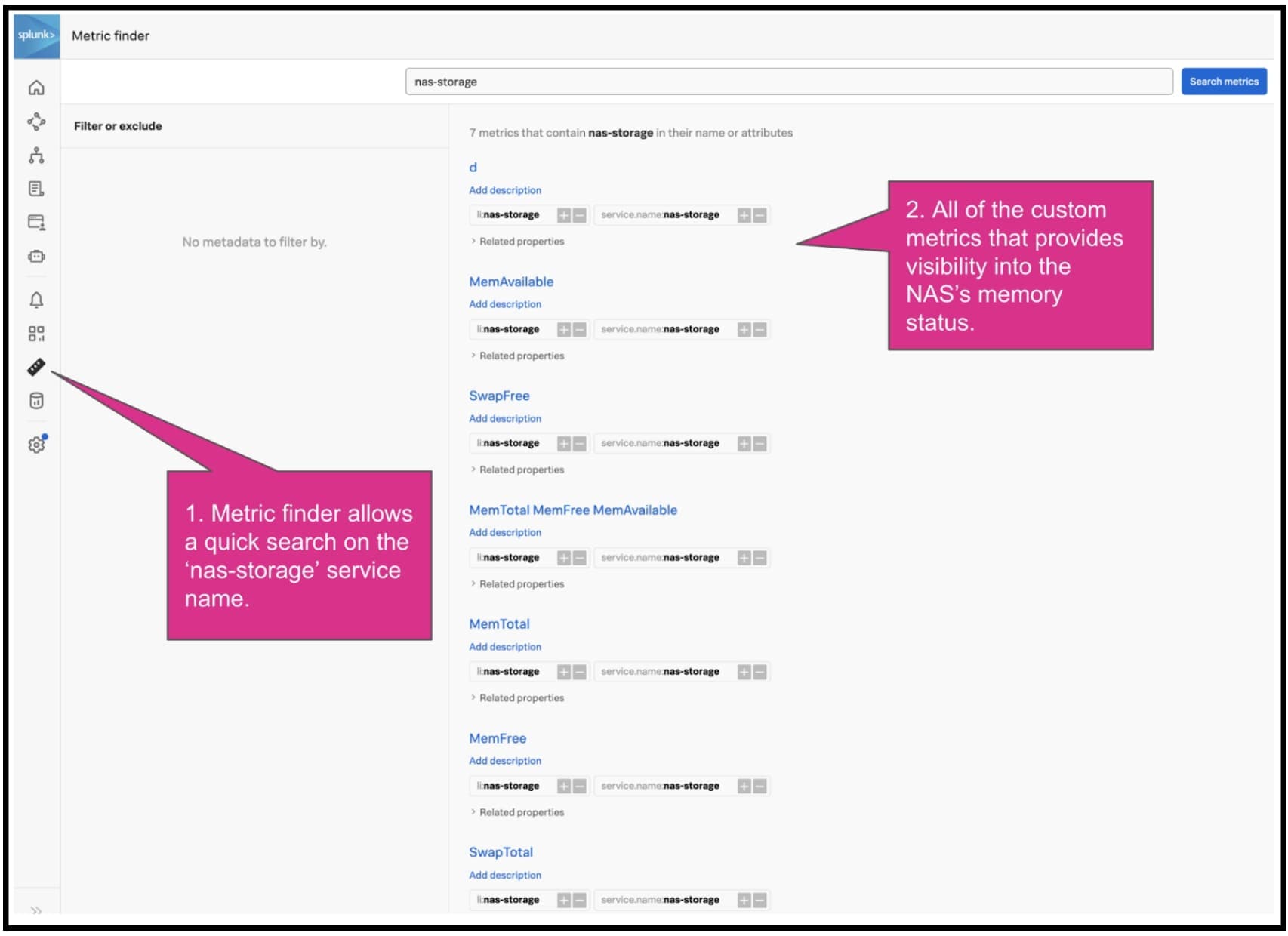
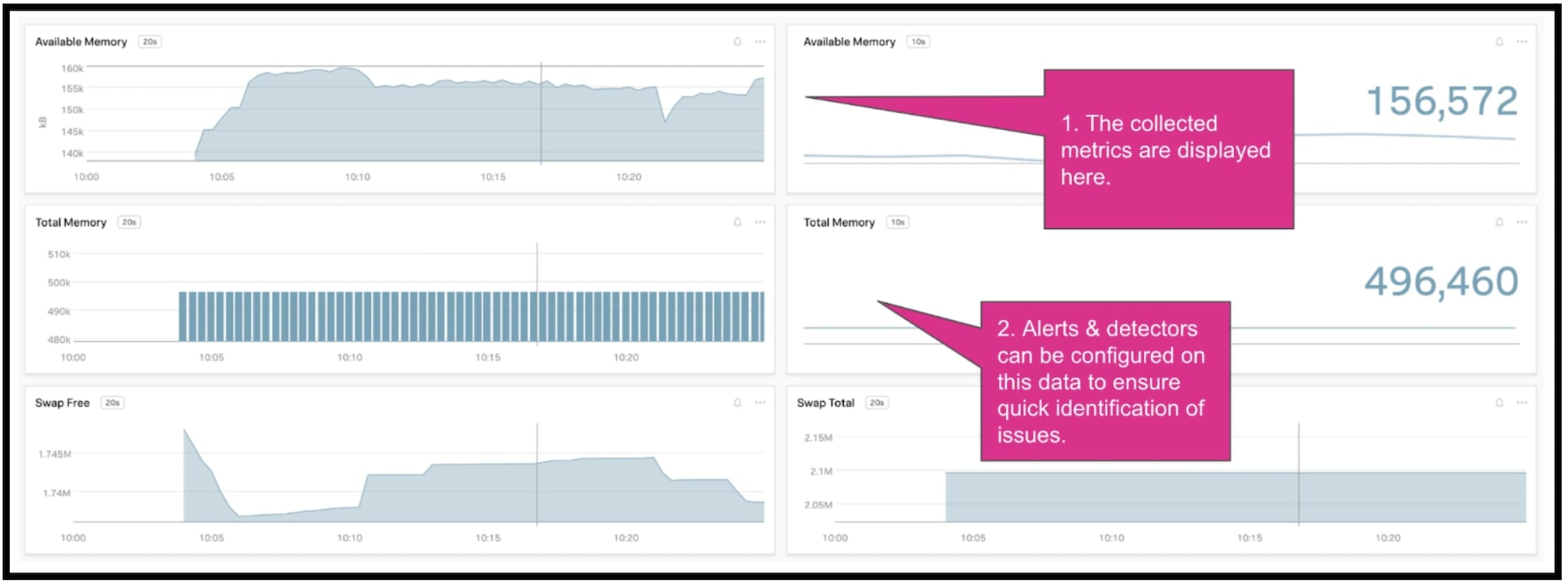
これで、カスタムメトリクスを使ってNASの状況を可視化し、パフォーマンスを監視できるようになりました。監視している間は、パフォーマンスの急激な悪化、外れ値、障害を簡単に検出できます。ここからさらにディテクターとアラートを作成して、問題が発生したときに自動的に通知し、修復作業を実行するように設定することもできます。
今日(と将来)の複雑なプラットフォームを適切に管理するには、カスタムメトリクスを活用し、すべてのメトリクスの収集方法とオブザーバビリティプラットフォームへの送信方法を完全にコントロールすることが重要です。
無料トライアル版で、Splunkオブザーバビリティプラットフォームをぜひ実際に試してみてください。関連する詳細については、以下の情報をご覧ください。
このブログ記事を執筆するにあたって貴重な意見を提供してくれたSplunkのOpenTelemetry SMEであるJohn Murdochに感謝します。

© 2005 - 2026 Splunk LLC 無断複写・転載を禁じます。
© 2005 - 2026 Splunk LLC 無断複写・転載を禁じます。
