
Ein Fahrplan zu digitaler Resilienz im Unternehmen

Kaum eine Branche muss sich mit so vielen Vorschriften, regulatorischen Einschränkungen und Nachweispflichten auseinandersetzen wie die der Finanzdienstleister. Finanzkriminalität – in Form von betrügerischen Handlungen – bleibt dennoch ein hochaktuelles Thema, dem nur mit einer richtigen, ganzheitlichen Nutzung von Daten begegnet werden kann. Das zeigen nicht nur Ereignisse der jüngeren Vergangenheit.
BaFin (Bundesanstalt für Finanzdienstleistungsaufsicht), MaRisk (Mindestanforderungen an das Risikomanagement), BAIT (Bankaufsichtliche Anforderungen an die IT) und Co.: All diese Compliance-Anforderungen gehören zum täglichen Geschäft von Finanzunternehmen (und sind mit den richtigen Insider-Tipps deutlich weniger nervenaufreibend). Trotz dieser und vieler weiterer Sicherheitsmechanismen, welche die Banken selbst, Anleger und Kunden, Geschäftspartner und Mitarbeiter schützen sollen, kommt es immer wieder zu kriminellen Machenschaften in der Finanzwelt.
Denken wir nur an den Fall Wirecard im Sommer 2020 als das deutsche Zahlungsunternehmen durch betrügerische Aktivitäten in die Schlagzeilen geriet. Hinter den Kulissen wurden Umsätze in Bilanzen frei erfunden. Ein klarer Fall von Betrug, Untreue und Marktmanipulation. Den Schaden von mehreren Milliarden Euro tragen die Banken und Investoren, bei denen Wirecard Geld geliehen hat, die Anleger, die dem Fall des Aktienkurses tatenlos zusehen mussten, und auch der Finanzplatz Deutschland, dessen Aufsichtsmechanismen auf dem Prüfstand stehen. Finanzkriminalität kostet alle Beteiligten viel Geld. Laut ACFE (Association of Certified Fraud Examiners) belief sich der durch Betrug verursachten Schaden im Jahr 2020 weltweit auf 3,6 Milliarden US-Dollar. Hinzu kommt ein Imageschaden und Vertrauensverlust bei den Kunden, der vielleicht sogar noch schwerwiegender ist.
Auch wenn es kein einfaches Allheilmittel für den Kampf gegen Betrug und Finanzkriminalität gibt, so stehen doch Daten im Zentrum jeder nachhaltigen Lösung. Hier kommt Splunk ins Spiel. Denn mit Splunk Enterprise lassen sich bekanntermaßen sowohl strukturiere als auch unstrukturierte Daten erfassen, die in der Folge analysiert und für die Erkennung von betrügerischem Verhalten verwendet werden können.
Die vorhandenen Datenquellen können aber noch auf andere Weise zur Betrugserkennung beitragen. Und zwar, wenn die Daten genutzt werden, um die Beziehungen zwischen den Entitäten zu beleuchten, womit eine ganze neue Art von Datensatz entsteht. Das kann man sich wie die Verbindungen in einem sozialen Netzwerk vorstellen. Wer ist besonders beliebt, wo gibt es Überschneidungen, mit wem ist man vermutlich befreundet aufgrund gemeinsamer Freunde und Interessen? Graph-Algorithmen können Verbindungen zwischen Entitäten erkennen und gemeinsam mit der hohen Anzahl heterogener Daten, die in Splunk aufgenommen werden, bietet dies eine ideale Grundlage für ausgefeilte Betrugserkennung.
Die hier vorgestellte Lösung basiert auf Splunk Enterprise oder Splunk Cloud in Kombination mit einigen Apps, die auf Splunkbase zur Verfügung stehen, und mit denen die Graph-Algorithmen angewendet werden können. Zu diesen Apps zählen:
In der 3D Graph Network Topology App findet ihr dann gleich passende Beispiele für Graph-Algorithmen sowie ein Graph Analysis Framework, mit dem sich sofort einige Algorithmen auf eure Daten in Splunk anwenden lassen.
Dazu zählen folgende Graph-Algorithmen:
Anhand von zwei Beispielen möchte ich euch zeigen, wie ihr diese neuen Tools auch für eure Betrugserkennung verwenden könnt. Vorher müssen wir uns allerdings noch mit der Splunk-Suchsprache SPL (Search Processing Language) beschäftigen, um die Daten bestmöglich analysieren zu können.
Nehmen wir an, ihr habt bereits Daten in Splunk erfasst und wollt diese nun mit Graph-Algorithmen analysieren. Ihr müsst nun als erstes definieren, welche Datenquellen ihr verbinden und welche Felder ihr dafür nutzen wollt. Üblicherweise definiert und extrahiert ihr die betreffenden Felder aus den unbearbeiteten Protokolldaten (oder sie werden automatisch extrahiert, wenn eine bekannte Quelle vorliegt). Angenommen ihr habt eine Datenquelle, die Transaktionsaufzeichnungen von einer Menge, die zwischen zwei Entitäten zu einer bestimmten Zeit (_time) transferiert wurde (user_id_from, user_id_to):
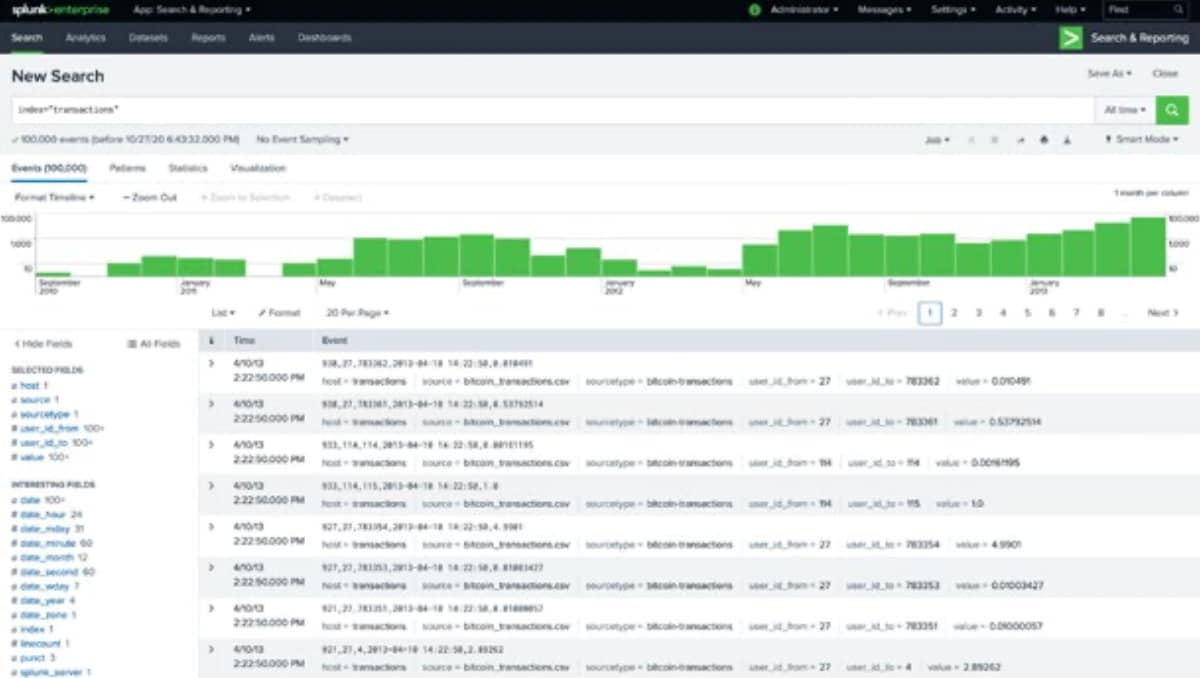
Wir können nun eine sogenannte Edge-List abfragen, welche alle gewünschten Verbindungen enthält. In SPL gibt es ein einfaches Suchmuster, mit dem zum Beispiel die Anzahl der Transaktionen zwischen den Entitäten in einem ausgewählten Zeitraum aggregiert werden können.
... | stats count by user_id_from user_id_to
Die errechneten Ergebnisse erscheinen in der „Statistics“-Registerkarte.
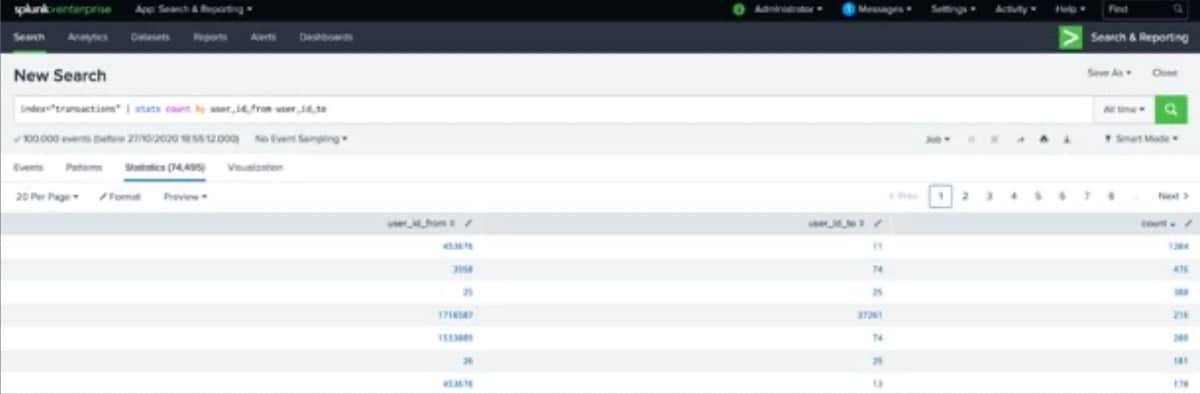
Unter der „Visualization“-Registerkarte lässt sich der Datensatz mithilfe der 3D Graph Network Topology als Graph darstellen.
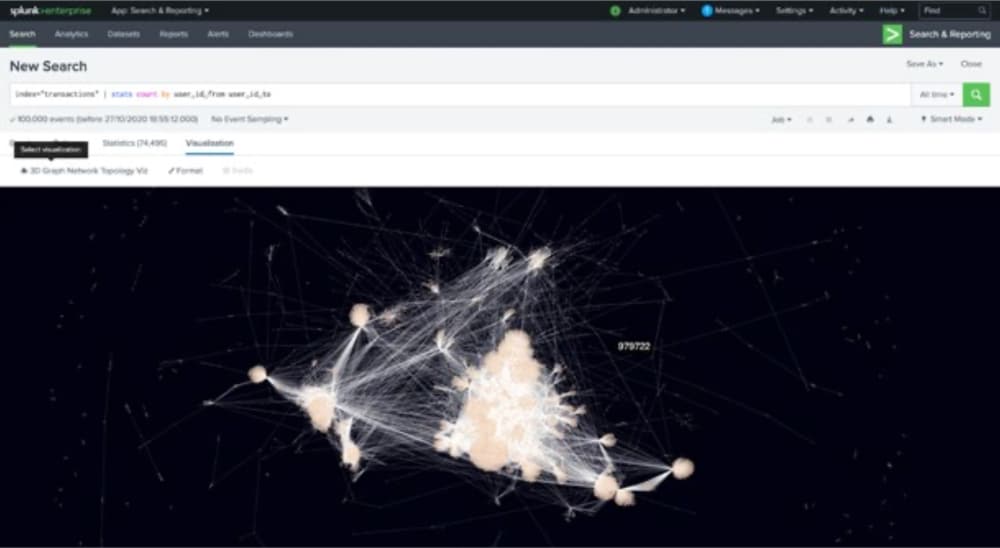
Verdächtige Verhaltensmuster können unter anderem mit der Relevanz des Angreifers beschrieben werden, d. h., wie wichtig bzw. gefährlich ist der Angreifer innerhalb des Netzwerks? Zentralitätsmessungen am Graphen können diese Information zutage fördern.
Es lässt sich die Eigenvektor-Zentralität jeder Entität am Graphen berechnen und so feststellen, welche Entitäten innerhalb des Netzwerks am einflussreichsten und wichtigsten sind. Eine weitere Messgröße stellt die „Betweenness“-Zentralität dar, die berücksichtigt, wie zentral eine Entität in Relation zu den durch sie hindurchfließenden Transaktionen ist. Die Entität nimmt dabei eine Art Vermittlerrolle ein, die gesondert analysiert werden kann.
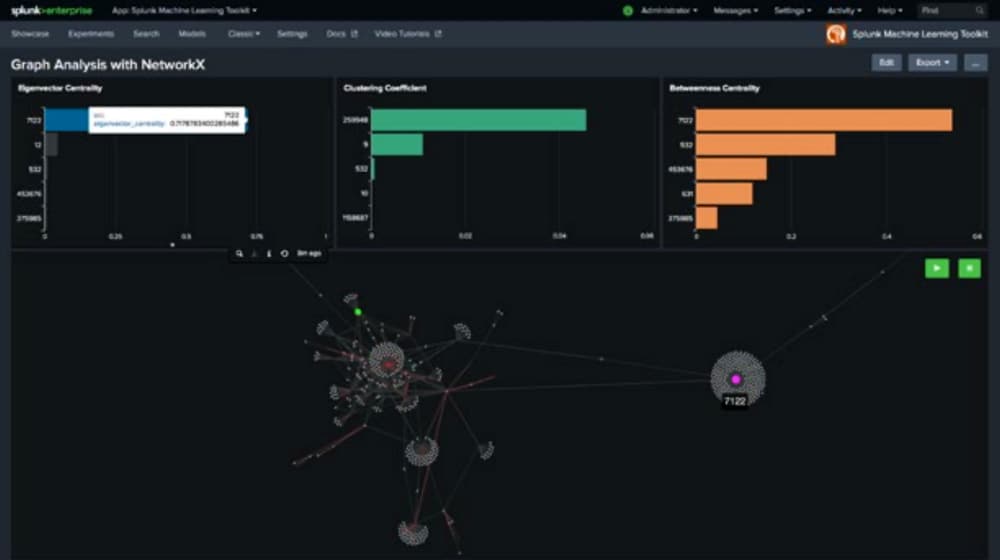
Im Splunk-Dashboard-Beispiel oben sehen wir Bitcoin-Transaktionen, bei denen der pink hervorgehobene Knotenpunkt 7122 auffällt aufgrund seiner hohen Eigenvektor-Zentralität, der hohen „Betweenness“-Zentralität und der wichtigen Verbindung, die er zwischen der linken und der rechten Hälfte darstellt. Die Ergebnisse legen wichtige Muster in großen Datensätzen offen, welche die Betrugserkennung voranbringen und weitere Untersuchungen anstoßen.
Es ist unwahrscheinlich, dass einzelne Angreifer sowohl als Mittelsmänner als auch als Broker zwischen vielen weitere Angreifern agieren. Hier kommt die bereits erwähnte „Betweenness“-Zentralität ins Spiel. Wenn ein einzelner Angreifer identifiziert wurde, sollten wir als nächstes herausfinden, mit wem er in einem bestimmten Zeitraum verbunden ist/war und wie all diese Entitäten wiederum miteinander verbunden sind – man spricht hierbei von einem „Betrugsring“ bzw. „Fraud Ring“.
Eine solche Struktur kann mit einem einfachen Graphen ausfindig gemacht werden. Der Connected Component-Algorithmus ordnet jeder Gruppe verbundener Entitäten eine Nummer, also eine Art Label zu. Der folgende Graph zeigt das Ergebnis der Anwendung des Algorithmus auf einen Datensatz von Finanztransaktionen.
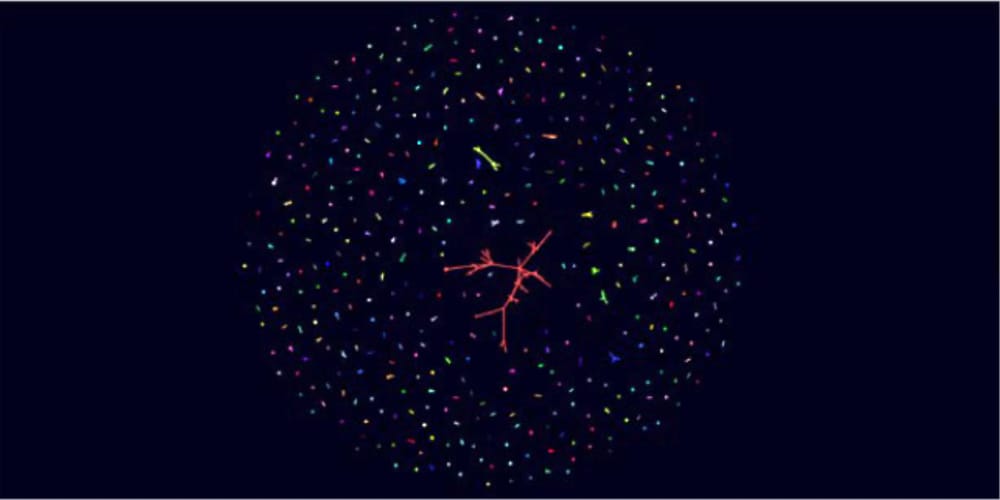
Jede Farbe steht für eine Zusammenhangskomponente einer Geld-Transaktionen zwischen Individuen. Das große, rote Element in der Mitte weist auf einen Betrugsring hin und kann als Ausgangspunkt für weitere Nachforschungen genutzt werden. Mit den Drill-Down-Funktionen von Splunk lassen sich aus diesem Graphen mit Leichtigkeit weitere Daten ableiten. Auch die Daten der anderen Gruppen verbundener Entitäten können weiterverwendet werden, um die Risikobewertung zu verbessern oder Risikomodelle zu erstellen. Natürlich lassen sich diese Daten auch mit den Zentralitätsmessungen des ersten Beispiels kombinieren.
Dieser Ansatz ist allerdings wirkungslos, wenn alle Entitäten miteinander verbunden sind. Hier kann aber zum Beispiel die Label Propagation oder die Louvain-Modularity-Methode weiterhelfen. Der semi-überwachte Machine Learning-Algorithmus markiert bisher unmarkierte Datenpunkte und verbreitet Label auf einer Teilmenge der Daten durch den Graphen. Schauen wir uns an, wie das bei einer Teilmenge der Bitcoin-Transaktionen funktioniert:
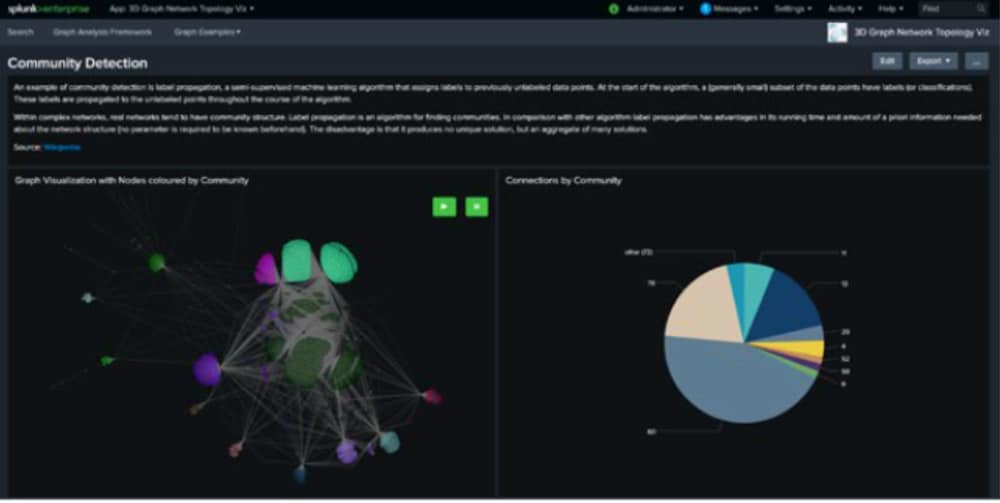
Wir sehen wie Teile des Graphs als Gruppe (Community) mit derselben Farbe markiert und damit offensichtlich stark miteinander verbunden sind. Der Connected Component-Algorithmus ermöglicht wiederum eine andere Perspektive, die in der darunterliegenden Graphstruktur zu erkennen ist. So lassen sich erneut Strukturen ausmachen, die auf die Notwendigkeit weiterer Untersuchungen hindeuten können.
Lasst uns zum Schluss ein Analysebeispiel anwenden, bei dem beide Methoden mithilfe von SPL kombiniert werden:
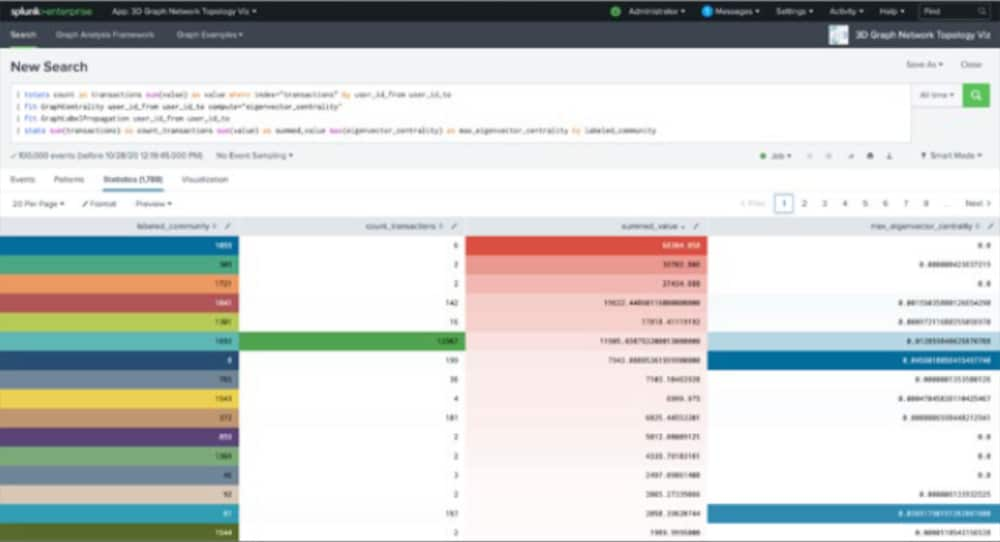
Die Analyseergebnisse ermöglichen es, zwischen der Gesamtzahl der Transaktionen, dem Gesamttransfervolumen und der maximalen Eigenvektor-Zentralität je nach Gruppe zu wechseln. Im obigen Beispiel ist der Gesamtwert in absteigender Reihenfolge sortiert und wir sehen, dass die ersten fünf Gruppen hohe Summen mit nur wenigen Transaktionen übertragen haben. Das muss zunächst nichts heißen, aber die sechste und siebte Zeile mit den Gruppen-Labels 1692 und 8 bzw. 61 zeigen eine hohe Eigenvektor-Zentralität und/oder Transaktionszahlen an. An dieser Stelle können weitere Untersuchungen angestellt werden.
Ich hoffe, dieser Beitrag konnte euch einen guten Einblick und praktische Hilfestellung dazu geben, wie ihr mit der Hilfe von Graph-Algorithmen kriminelle und betrügerische Handlungen im Finanzbereich erkennen und verhindern könnt. Sollte etwas unklar sein oder ihr irgendwelche Fragen haben, zögert bitte nicht, euch direkt mit uns in Verbindung zu setzen.
Happy Splunking!
Philipp
Hinweis: Dieser Blogeintrag basiert auf dem Artikel “Detecting and Preventing Financial Crimes With Graph Algorithms” von Philipp Drieger aus dem E-Book “Bringing the Future Forward Real-world ways data can solve some of today’s biggest challenges”.

Die führenden Unternehmen der Welt vertrauen auf Splunk, einem Unternehmen von Cisco, um ihre digitale Resilienz mit der einheitlichen Sicherheits- und Observability-Plattform, unterstützt durch branchenführende KI, kontinuierlich zu stärken.
Unsere Kunden setzen auf die preisgekrönten Sicherheits- und Observability-Lösungen von Splunk, um die Zuverlässigkeit ihrer komplexen digitalen Umgebungen zu sichern und zu optimieren – in jeder Größenordnung.

Die neuesten Artikel von Splunk, direkt im eigenen Posteingang.
© 2005 - 2026 Splunk LLC All rights reserved.
© 2005 - 2026 Splunk LLC All rights reserved.