
Ein Fahrplan zu digitaler Resilienz im Unternehmen
Schon George Washington, der erste Präsident der Vereinigten Staaten von Amerika, wusste: „If it is on the internet, it must be true and you can’t question it.“ – Wenn etwas im Internet steht, muss es wahr sein (oder war es Albert Einstein, der das sagte?). Was natürlich nur ein Scherz sein soll, kommt allerdings der Realität allzu oft bedrohlich nahe. Soziale Medien vernetzen uns in einer noch nie dagewesenen Weise. Sie starten ganze Bewegungen und stellen für viele Menschen die Nachrichtenquelle Nummer 1 dar. Und genau darin liegt die Gefahr.
Fake News, das Schlagwort der letzten Jahre: Was einst die Standard-Antwort von Donald Trump auf unbequeme Wahrheiten war, hat sich (vielleicht auch gerade wegen „the Donald“) zu einem handfesten Problem entwickelt. Denn Studien zeigen, dass Fake News zum Beispiel auf Twitter 70 % häufiger retweeted werden und das Publikum 6-mal schneller erreichen als seriöse, wahrheitsgemäße Meldungen. Das kann ernste – ja sogar tödliche – Folgen haben, wenn beispielsweise falsche Informationen zu Covid-19 die Runde machen oder durch gezieltes Streuen von Fake News Einfluss auf demokratische Wahlen genommen wird.
Eine große Rolle bei dieser Art der missbräuchlichen Nutzung von Social Media spielen sogenannte Bots, also automatisierte Accounts, die menschliche Accounts imitieren und die Sozialen Medien mit Falschinformationen überrennen. Auf Twitter allein schätzt man die Anzahl der Bots auf 48 Millionen – was 15 % aller Accounts ausmachen würde! In seinem (sehr empfehlenswerten) Buch „Das Internet muss weg“ beschreibt Blogger Schlecky Silberstein Untersuchungen der Oxford University und der Corvinus-Universität in Budapest zum Tweet-Verhalten der Engländer während des Brexit-Wahlkampfs. Dabei wurden 1,8 Millionen Tweets mit entsprechenden Hashtags (z. B. #vote-leave oder #remain) analysiert – 15 % davon waren gegen den Brexit, 35 % neutral und 50 % konnten dem pro-Brexit-Lager zugeordnet werden. Was aber viel interessanter ist: Gerade mal 1 % der analysierten Twitter-Nutzerprofile waren für ganze 30 % aller Tweets verantwortlich. Ein Schelm, wer Böses dabei denkt.
Eine andere Studie von sadbottrue.com stellte fest, dass gerade mal 10 % der aktivsten Brexit-Retweeter echte Menschen waren (20 von 200). Es ist also von entscheidender Bedeutung, diese Bots zu identifizieren und zu verstehen, wie sie bei der Verbreitung von Falschinformationen vorgehen.
Bots werden mithilfe von Machine Learning trainiert. Dabei werden Algorithmen verwendet, die dank der wachsenden Zahl an Daten in den Sozialen Medien immer besser werden. Zwar bemühen sich Soziale Netzwerke den Bots mit Moderatoren und Fact Checkern entgegenzutreten, doch alleine die schiere Anzahl und Schnelligkeit der Bots macht das auf manuellem Wege nahezu unmöglich. Will man mit diesen Methoden Schritt halten, muss man selbst auf die Kraft der Daten zurückgreifen und den Bots mit Algorithmen und automatisierten Maßnahmen begegnen.
Splunk kann Unternehmen, die Social-Media-Bereiche moderieren müssen, als KI-getriebene Data-to-Everything Plattform bei der Bekämpfung von Bots unterstützen, indem Social-Media-Daten in Echtzeit verarbeitet und zudem – im Falle von Twitter – die vom sozialen Netzwerk bereitgestellten Daten zur Bot-Bekämpfung genutzt werden. Mit dem Splunk Machine Learning Toolkit (MLTK) lassen sich so Modelle erstellen, die Bots erkennen. In der Folge kann eine automatisierte Reaktion den Vorfall entweder an einen Mitarbeiter oder an die Plattform selbst weiterleiten.
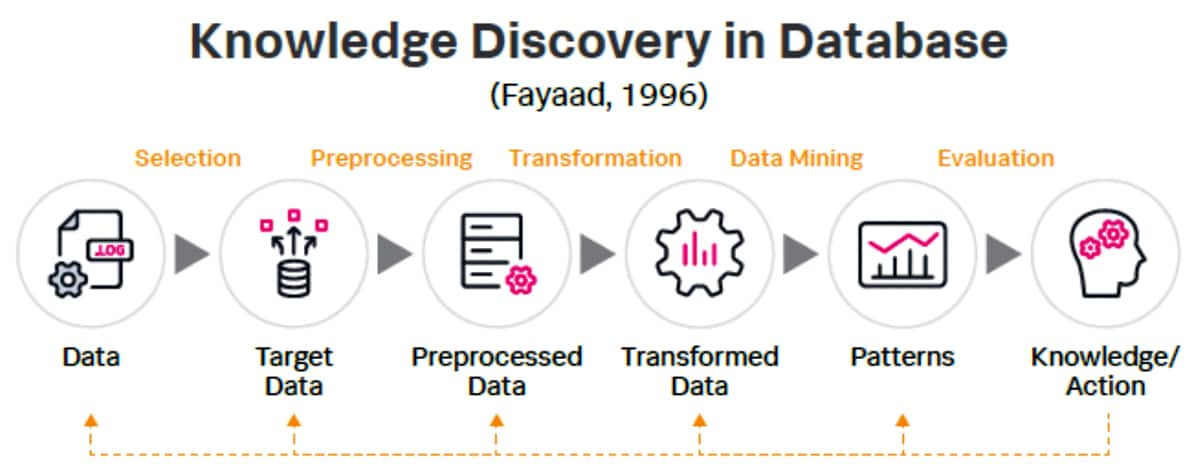
Der Methode von Splunk liegt das „Knowledge Discovery in Database“-Prinzip von Fayaad (1996) zugrunde.
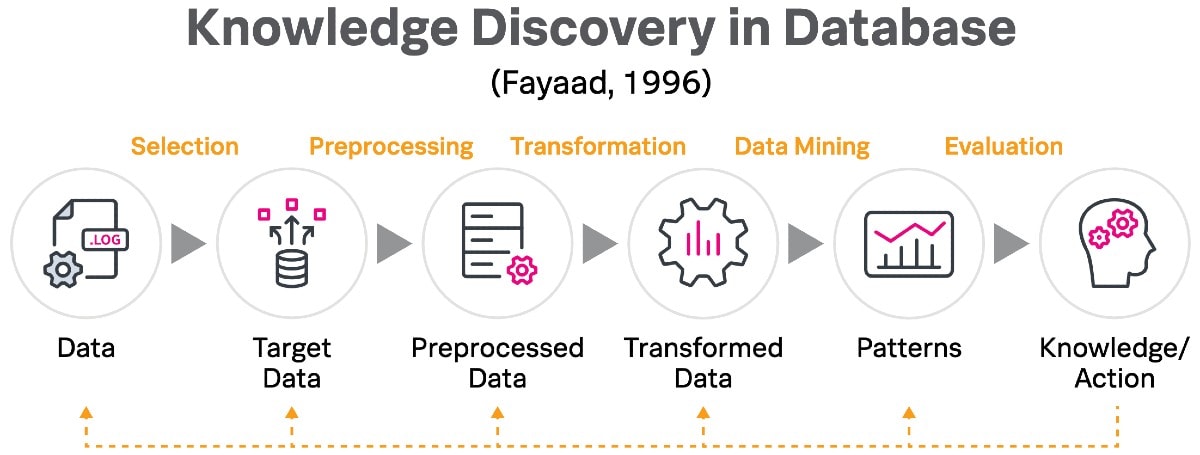
Eine solche Dekonstruktion der Lösung ermöglicht eine logische Schritt-für-Schritt-Implementierung und zeigt, wie Splunk in einzigartiger Weise als End-to-End-Plattform für die Extraktion und Anwendung von Wissen während des Data-Mining-Prozesses dient.
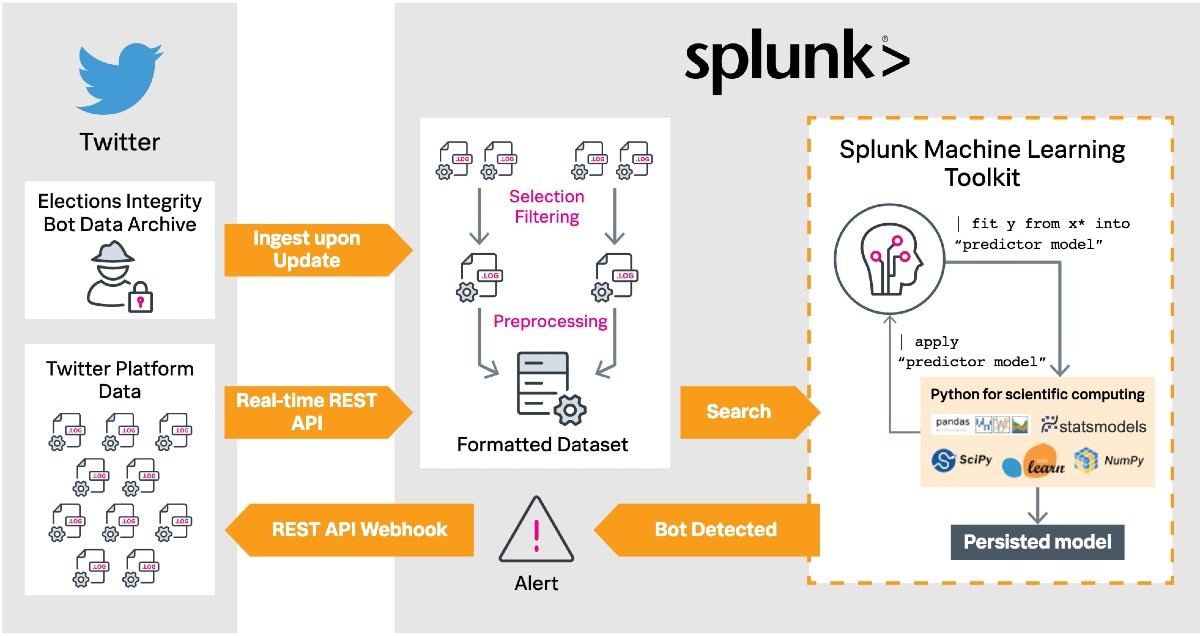
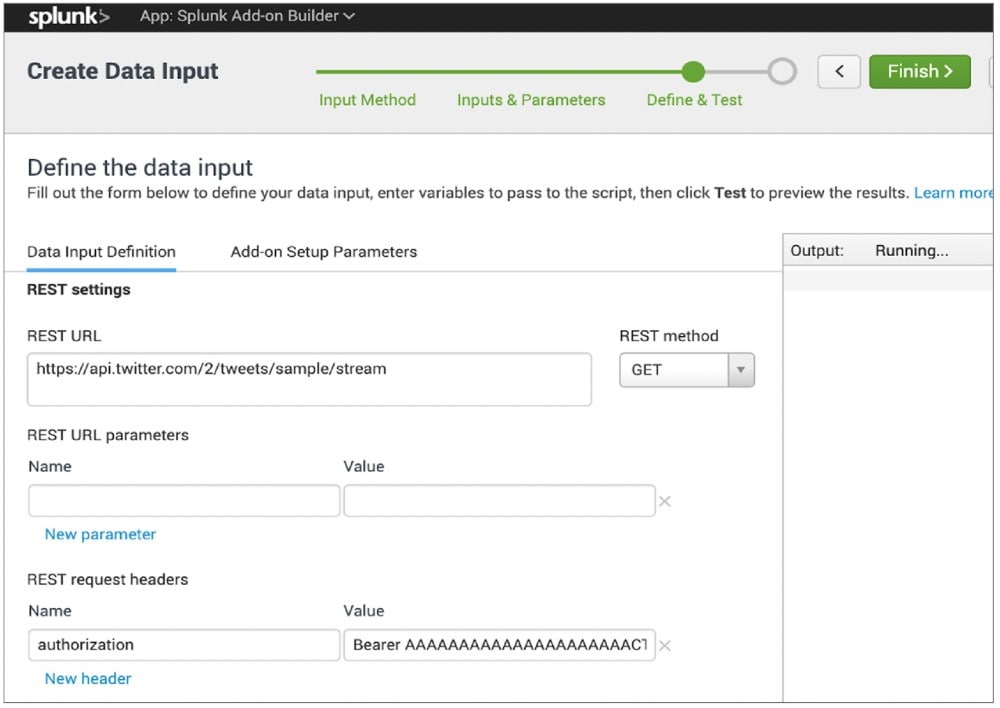
In einem ersten Schritt geht es um die Auswahl des Datensets, anhand dessen ein Modell zur Erkennung der Bots entwickelt wird. Da wir uns in diesem Beispiel auf Twitter konzentrieren, nutzen wir die Echtzeit-Datenerfassung. Die meisten Posts auf Twitter sind nicht geschützt und lassen sich öffentlich einsehen, weshalb sie über verschiedene Schnittstellen erfasst werden können. Dabei kann zwischen der Erfassung einer Auswahl aus allen Tweets (Sample API) und nach Keywords gefilterten Tweets (Filter API) unterschieden werden. Der Ablauf bleibt derselbe. Ihr müsst einen Entwickler-Account (developer.twitter.com) beantragen und könnt anschließend Anwendungen über das Entwicklerportal erstellen. Der Splunk Add-On Builder ist die einfachste Möglichkeit mit der REST-API (Representational State Transfer) Daten zu erfassen. Die App ist unter anderem auf Splunkbase verfügbar.
Die App ermöglicht euch die Erstellung eines Add-Ons bevor ihr einen neuen REST-API-Daten-Input konfigurieren müsst. Unter „Inputs & Parameters“ kann der Quellentyp (Source Type) sowie der gewünschte Display- und Input-Name festgelegt werden, vor der Häufigkeit des Abrufs des API-Inputs. Damit wird ein Echtzeit-Datenfluss in Splunk generiert. Hier wird auch der REST-Call definiert, indem die URL der gewünschten API zusammen mit den gewählten Parametern und Headern eingegeben wird. Das folgende Beispiel verwendet die Sample-API, sodass nur der Autorisierungsheader mit einem Wert für „Bearer“ erforderlich ist, zusammen mit dem Bearer-Token bei „Keys and Tokens“ im Twitter-Entwicklerportal.
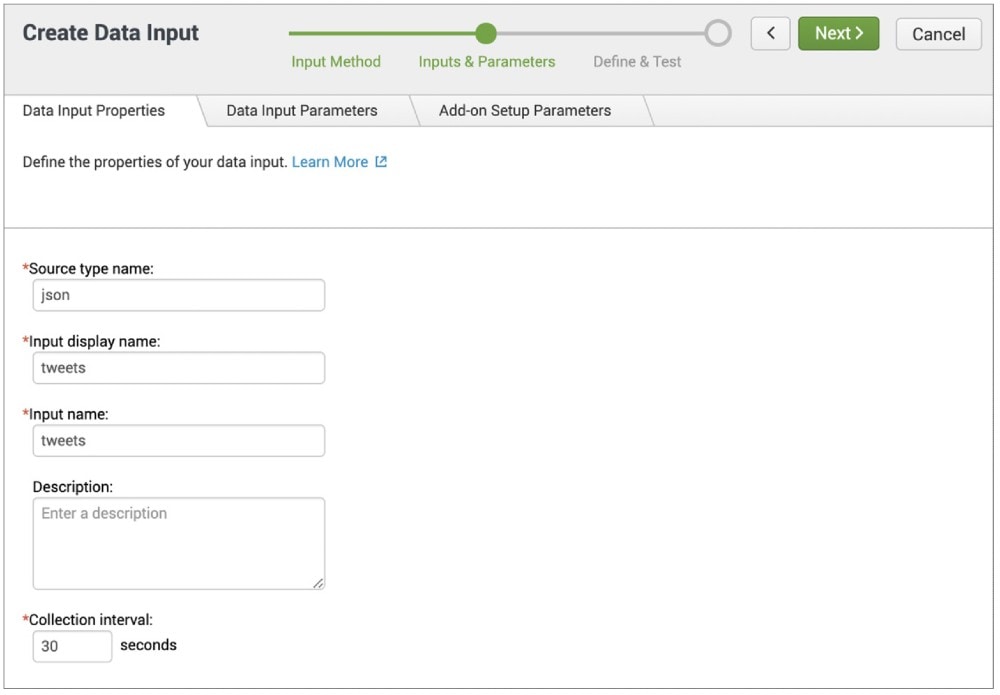
In einem letzten Schritt wird das neu erstellte Add-On vom Splunk-Startbildschirm aus aufgerufen und ein Input konfiguriert, wobei festgelegt wird, in welchem Index die Daten liegen sollen und wie oft der Input die gesammelten Daten abfragen soll. Anschließend können Social-Media-Daten im JSON-Format sowohl mit dem Inhalt des Posts als auch mit Account-Informationen in Echtzeit zu Splunk übertragen werden.
Um bösartige Bots zu erkennen, müssen die Daten mit bereits bestätigten Bots abgeglichen werden. Unter Add Data > Upload workflow können direkt Daten von Twitter, die das Unternehmen im Rahmen der Election-Integrity-Initiative zur Verfügung stellt, hinzugefügt werden.
Wer jemals eine datenwissenschaftliche Untersuchung durchgeführt hat, weiß: die meiste Arbeit liegt in der Organisation der gesammelten Daten. Splunk vereinfacht und beschleunigt diesen Teil des Prozesses erheblich.
Beginnt mit der Suche nach Gemeinsamkeiten im Inhalt der Felder (Fields) der Datensätze. Die Feldnamen mögen sich unterscheiden, sie enthalten aber beide den Text des Tweets sowie die Metadaten zum Account. Dadurch werden Informationen, die nicht von einem der Datensätze abgedeckt werden oder aus einem der Datensätze erstellt werden können, effizient eliminiert und ihr könnt den Datensatz mit dem Befehl „outputlookup“ in Lookups verkleinern.
Ihr könnt auch neue Felder mithilfe von berechneten Feldern (Calculated Fields) – Felder, die zu Events zur Suchzeit hinzugefügt werden und Berechnungen mit den Werten von zwei oder mehr in diesen Events vorhandenen Feldern durchführen – konstruieren. Damit lassen sich Aspekte eines einzelnen Felds analysieren, z.B. die Anzahl der Hashtags, sowie Parameter, welche das Verhältnis zwischen mehreren Feldern in den Fokus rücken, z.B. das Verhältnis von Followern zu Accounts, denen gefolgt wird.
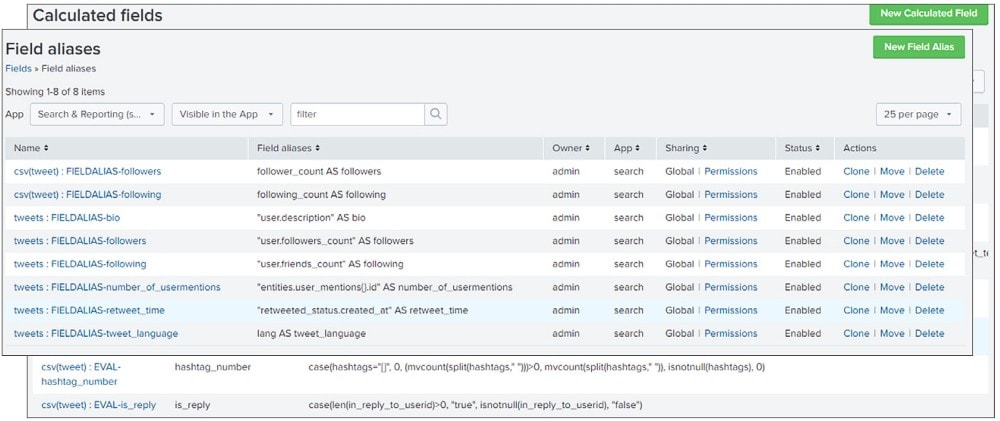
Im Anschluss müsst ihr die beiden Datensätze in einen zusammenhängenden, universell formatierten Trainingsdatensatz transformieren. Das gelingt, indem ihr Feldaliase/-tags (Field Aliases/Tags) verwendet, um dauerhaft referenzierbare standardisierte Namen für die Felder zu erzeugen, und/oder indem ihr Felder mit dem SPL-Befehl „rename“ umbenennt und die Ergebnisse in einem aktualisierten Lookup ausgebt, das beide Datensätze abdeckt.
Machine Learning und Data Mining teilen sich den ablaufenden Prozess und das gewünschte Ergebnis. Während sich Machine Learning jedoch durch die Automatisierung auszeichnet, bezeichnet Data Mining den Prozess der Analyse eines Datensatzes, um versteckte Muster zu identifizieren. Dazu muss zunächst ermittelt werden, welche Data Mining-Methode (oder Machine Learning-Methode) geeignet ist. Wenn wir feststellen wollen, ob ein Beitrag von einem Bot oder von einem Menschen stammt, benötigen wir eine binäre Klassifizierung.
Das Splunk Machine Learning Toolkit bietet die Algorithmen, die wir für diesen Prozess benötigen. Es ist mit sci-kit learn-Algorithmen vorinstalliert und ermöglicht den Import von benutzerdefinierten Algorithmen, welche die Python for Scientific Computing-Bibliothek nutzen und zusätzliche ML-spezifische Befehle bieten, welche die SPL-Befehlsbasis erweitern, sowie ein Experiment Management Framework, das eine Schnittstelle für die Modellversionierung und -abfolge darstellt.
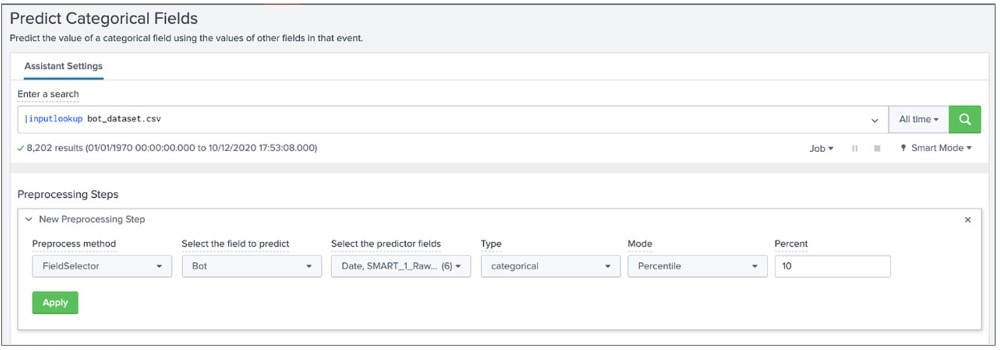
Mit dem Toolkit und durch Analysen und weiteres Filtern lässt sich ein optimierter Datensatz für die Modellierung erstellen. Der Workflow „Predict Categorial Fields“ bietet eine Benutzeroberfläche zur Durchführung von Vorverarbeitungsprozessen – dazu zählt die Verbesserung der Datenqualität durch Skalierung numerischer Werte oder Reduzierung der Felder auf eine bestimmte Anzahl unkorrelierter Dimensionen über die Principal Component Analysis. Die nützlichste Funktion stellt allerdings der FieldSelector-Algorithmus dar, der die scikit-learn GenericUnivariateSelect verwendet, um die besten Prädiktorfelder (Predictor Fields) auszuwählen und die weniger nützlichen, die zu einer Überanpassung führen und die Qualität des Modells beeinträchtigen könnten, reduziert.
Eine weitere Option in diesem Stadium wäre die Nutzung von NLP Text Analytics, einer Splunkbase-Anwendung, die das MLTK um Funktionen des Natural Language Processings erweitert. Damit könnt ihr Muster innerhalb des Datensatzes ausfindig machen, wie z. B. die Häufigkeit bestimmter Sprachausdrücke und gezeigter Stimmungen, die dabei helfen könnten, Bot und Mensch zu unterscheiden und das Erkennungsmodell zu trainieren.
Im letzten Schritt müssen die ausgewählten Machine Learning-Algorithmen auf die vorverarbeiteten Daten angewendet werden. Hierfür bietet das MLTK eine Reihe von sofort einsatzbereiten Klassifizierungsalgorithmen an, z. B. für logistische Regression (Logistic Regression), Random Forest und Support-Vektor-Maschinen (Support Vector Machines). Wählt einen Algorithmus und ein Prediction-Field aus.
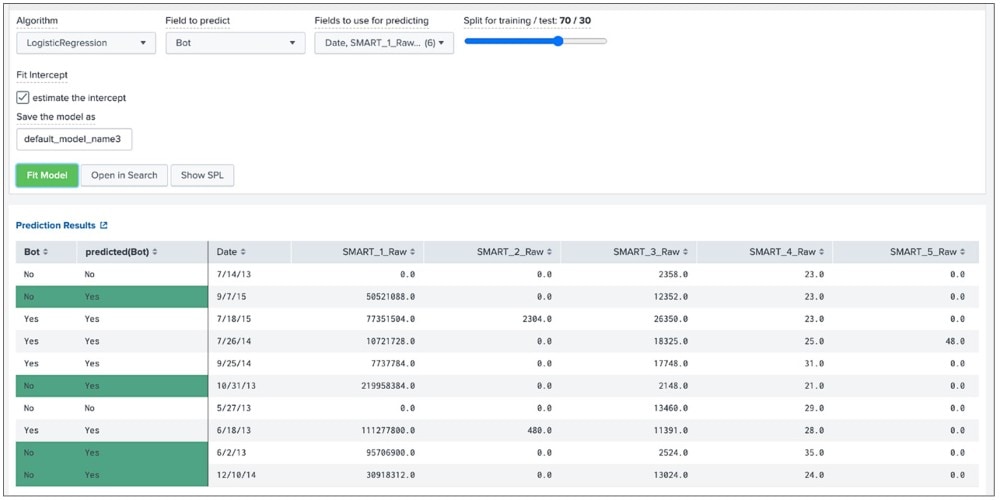
Mit der Anpassung des Modelles verändern sich auch die Werte Genauigkeit (Accuracy), Recall und Präzision (Precision). In der Abbildung unten beträgt der Wert 0,84. Dass bedeutet, dass 84 % der Klassifizierungsvorhersagen richtig sind. Eine Annäherung an 100 ist zwar theoretisch möglich, sorgt aber nicht selten für eine Überanpassung an das Trainings-Datenset. In der Folge ist die Leistung dann bei neuen, unbekannten Daten mangelhaft.

Die Optimierung dieser Modelle ist ein stetiger Prozess, der mit der zunehmenden Datenmenge, die in Splunk verarbeitet wird, voranschreitet.
Hierfür können wir die MLTK-Befehle verwenden, welche die Basis-Splunk Processing Language (SPL) erweitern, insbesondere „|apply“, um das aktuelle Modell auf die neuen Daten anzuwenden. Vorgespeicherte Suchen können nach einem bestimmten Zeitplan durchgeführt werden. Bei einem verdächtigen Bot wird eine Warnmeldung ausgegeben, z.B. über Splunk On-Call.
Die massive Bedrohung durch automatisierte Bots, die Falschinformationen in Sozialen Medien verbreiten, kann überwältigend erscheinen. Hoffentlich hilft euch dieser Blog ein wenig dabei gemeinsam gegen die Bots, diese Lösung zu implementieren und zu unserem laufenden Kampf gegen gefährliche Fehlinformationen beizutragen, indem ihr genau die Technologie, die solche Bots erst ermöglicht, gegen sie einsetzt.
Happy Splunking,
Philipp
Hinweis: Dieser Blogeintrag basiert auf dem Artikel “Real-Time Social Media Bot Moderation Solutions That Could Save Democracy” von Rupert Truman aus dem E-Book “Bringing the Future Forward Real-world ways data can solve some of today’s biggest challenges”.

Die führenden Unternehmen der Welt vertrauen auf Splunk, einem Unternehmen von Cisco, um ihre digitale Resilienz mit der einheitlichen Sicherheits- und Observability-Plattform, unterstützt durch branchenführende KI, kontinuierlich zu stärken.
Unsere Kunden setzen auf die preisgekrönten Sicherheits- und Observability-Lösungen von Splunk, um die Zuverlässigkeit ihrer komplexen digitalen Umgebungen zu sichern und zu optimieren – in jeder Größenordnung.

Die neuesten Artikel von Splunk, direkt im eigenen Posteingang.
© 2005 - 2026 Splunk LLC All rights reserved.
© 2005 - 2026 Splunk LLC All rights reserved.