
Ein Fahrplan zu digitaler Resilienz im Unternehmen

Man muss schon sagen: Splunk ist eine fantastische Plattform. Mit Splunk können Daten aus Logs, Metriken und Traces aus jeder Menge verschiedener Datenquellen aufgenommen, gespeichert, durchsucht und analysiert werden. Das heißt aber noch lange nicht, dass wir sämtliche Daten ignorieren sollten, die nicht in diese Kategorien fallen – z. B. Bild- und Videodaten!
Bilder, Audio und andere von Maschinen lesbare „binäre“ Datenquellen enthalten in vielen Fällen mit großer Wahrscheinlichkeit wertvolle Informationen. Wir müssen nur eine Möglichkeit finden, diese Daten in sinnvoller Form verfügbar zu machen.
Das klingt vielleicht nach einer schwierigen Aufgabe, aber Jahrzehnte der Forschung und Entwicklung haben eine Reihe von Systemen und Services hervorgebracht, die diese Art von Daten aufnehmen und sinnvoll interpretieren können. In diesem Blog möchte ich euch einen solchen Ansatz vorstellen, mit dem durch Machine Learning gewonnene Bildmetadaten für Splunk verfügbar gemacht werden können.
Rekognition ist ein AWS-Service für computergestütztes Sehen (Computer Vision). Mit diesem Service könnt ihr aus Bild- bzw. Videodaten (bzw. dem entsprechenden Datenstrom), die in AWS S3 gespeichert sind, verschiedene Arten von Metadaten generieren. Ihr könnt damit beispielsweise Gesichter in einem Bild erkennen und beurteilen, ob die Person glücklich oder verärgert aussieht. Ihr könntet auch das Auftreten einer bekannten Persönlichkeit in einem Video nachverfolgen oder bestimmte Objekte in einer Szene erkennen und identifizieren.
Der geschäftliche Nutzen solcher Daten entsteht dadurch, dass sie Kontext für Bild- oder Video-basierte Datenquellen erzeugen. Mit der Erkennung benutzerdefinierter Label könntet ihr beispielsweise einen kamerabasierten Qualitätssicherungsprozess für eine Fertigungslinie implementieren, bei dem Daten direkt an Splunk gestreamt werden. Durch das Monitoring eines Kamera-Feeds könntet ihr Muster im Fußgängerverkehr analysieren und damit in einem Logistikszenario die Effizienz steigern oder ihr könntet in großem Umfang Inhalte analysieren, die in eure Web-App hochgeladen werden. Und dann gibt es natürlich auch noch ein paar „wildere“ Ideen für die Nutzung: Denkbar wären hier beispielsweise Systeme, die Wildtiere mithilfe öffentlicher Webkameras erkennen und verfolgen.
Heute habe ich allerdings ein viel einfacheres Ziel: Ich versuche mithilfe von Computer Vision herauszufinden, was hinter Shelly Kornbloom, dem „VP for Marketing Special Ops and Catering“ der Splunk T-Shirt Company steckt.

Zusammen mit einigen sehr talentierten Kollegen habe ich ein paar Spaßprojekte auf Basis oben genannter Daten erstellt. Vielleicht habt ihr auf der .conf19 unsere „Splunk Your Face“-Fotokabine gesehen, in der Fotos der Teilnehmer gemacht wurden. Daraus wurden dann sehr kreative Statistiken über die teilnehmenden Splunker erstellt, wie etwa „Wie bärtig sind die Teilnehmer im Durchschnitt?“. Dieses Jahr habe ich eine Woche lang meine Gefühlslage bei der Arbeit mit meiner Laptopkamera erfasst, um festzustellen, wann ich glücklich, traurig oder verwirrt aussah – dadurch bekam ich einen ganz guten Eindruck von meiner mentalen Verfassung während COVID-19.
Die Datenpipeline zu Splunk, die die Verarbeitung und Aufnahme von Bildmetadaten unterstützt, lässt sich auffallend einfach einrichten, wenn man ein bisschen Erfahrung mit AWS und Boto, dem AWS Python-SDK, mitbringt.
Bei meinen eigenen Projekten habe ich ein einfaches, lokales Python-Skript dazu verwendet, Bilder einer lokalen Kamera zu erfassen und sie in einen sicheren S3-Bucket hochzuladen. Für im Bucket abgelegte Dateien wird dann eine Lambda-Funktion ausgelöst, die einen Verweis auf jedes der Bilder an den Rekognition-Service übermittelt.
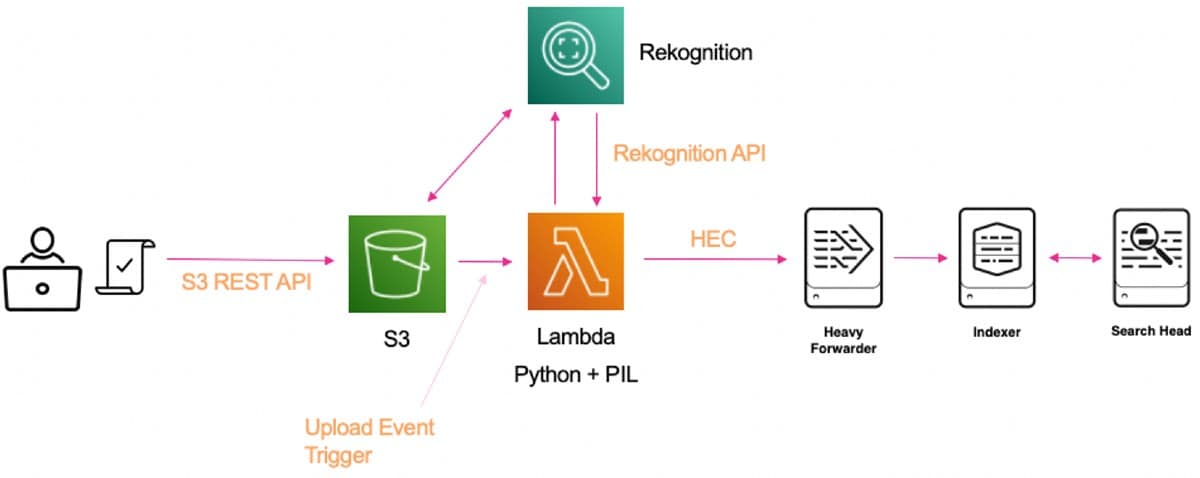
Wenn die Antwort von Rekognition wieder bei unserer Lambda-Funktion eintrifft (praktischerweise in Form eines JSON-Objekts), können wir sie über den HTTP Event Collector (HEC) an Splunk weiterleiten.
Die von der Recognition Face API zurückgegebenen Daten enthalten eine ganze Menge Metadaten über den Bildinhalt. Die folgenden Beispiele zeigen einige Ausschnitte aus Dashboards, die wir für die Analyse der von unserem System verarbeiteten Bilder erstellt haben.
Der DetectLabels API-Endpunkt liefert uns alle weiteren Label, die der Algorithmus auf das betreffende Bild anwenden kann. In diesem Fall haben wir die Wordcloud-App verwendet, um unsere Label mit relativen Schriftgrößen und -farben anzuzeigen, wobei Größe und Farbe in Bezug dazu stehen, wie sicher wir uns bei dem jeweiligen Label sind. Wir können diese Label in unserem Dashboard neben dem zugehörigen Bild darstellen:

Die DetectFaces API haben wir verwendet, um Gesichter in unseren Testbildern zu erkennen, das Alter der Person zu schätzen und die Emotionen zu erfassen, die das jeweilige Gesicht widerspiegelt. Also, was denkt Shelly wirklich?
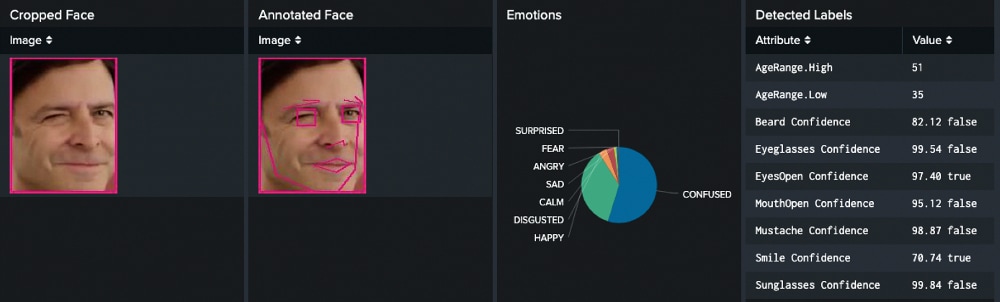
Ich glaube, unser Bild von Shelly sagt viel über seine Motivation aus. Denn obwohl seine entschlossene Zuversicht deutlich sichtbar ist, lässt sich unter der Oberfläche auch ein gehöriges Maß an Verwirrung erkennen. Ich denke, das passt ganz gut!
Und damit können wir jetzt Bilder in einen S3-Bucket aufnehmen und ihre Metadaten in Splunk durchsuchen und referenzieren. Bei den Projekten, an denen ich beteiligt war, sind wir noch ein bisschen weiter gegangen und haben ein paar Veränderungen vorgenommen:
Ich hoffe, dieses Beispiel hat euch ein paar Anregungen für eigene Projekte gegeben. Ich wollte euch zeigen, dass wir uns nicht auf „klassische“ Maschinendaten und traditionelle Datenquellen beschränken müssen. Denn Splunks Data-to-Everything Plattform bietet wirklich unbegrenzte Möglichkeiten!
Viel Spaß beim Splunken,
Josh
*Dieser Artikel wurde aus dem Englischen übersetzt und editiert. Den Originalblogpost findet ihr hier: A Picture is Worth a Thousand Logs.

Die führenden Unternehmen der Welt vertrauen auf Splunk, einem Unternehmen von Cisco, um ihre digitale Resilienz mit der einheitlichen Sicherheits- und Observability-Plattform, unterstützt durch branchenführende KI, kontinuierlich zu stärken.
Unsere Kunden setzen auf die preisgekrönten Sicherheits- und Observability-Lösungen von Splunk, um die Zuverlässigkeit ihrer komplexen digitalen Umgebungen zu sichern und zu optimieren – in jeder Größenordnung.

Die neuesten Artikel von Splunk, direkt im eigenen Posteingang.
© 2005 - 2026 Splunk LLC All rights reserved.
© 2005 - 2026 Splunk LLC All rights reserved.