
Wege zum Aufbau erfolgreicher Observability-Praktiken

Moderne Software ist unglaublich kompliziert und erzeugt Unmengen von Daten. Am laufenden Band werden Metriken, Logs und Traces von Hunderten von Services erzeugt, selbst für einfache Anwendungen. Eine einzelne Transaktion kann zugehörige Metadaten in der Größenordnung von Kilobytes generieren. Wenn wir das multiplizieren, um auch nur ansatzweise zu berücksichtigen, dass Transaktionen gleichzeitig stattfinden, dann liegen wir bei einigen Megabyte pro Sekunde (oder etwa 300 GB/Tag) an Daten, die für eine spätere Nutzung erfasst und analysiert werden müssen. Und das Volumen nimmt natürlich weiter zu, je mehr Benutzer und Services eure Anwendung umfasst. Es gibt unendlich viele Fragen über euer Unternehmen und für die Antworten braucht ihr Daten: Wie lange bleiben meine Kunden auf meiner Website? Wie wirkt es sich auf die User Experience aus, wenn einer meiner Services langsam arbeitet? Wie weiß ich überhaupt, ob es Probleme gibt? Für all dies braucht ihr Observability, und Observability wiederum benötigt Daten.
Eine Lösung für den Umgang mit diesen Daten besteht darin, sie direkt in euer Observability-System einzuspeisen. Das ist natürlich die einfachste Methode und stellt außerdem sicher, dass nichts übersehen wird. Doch es gibt dabei zweierlei Herausforderungen: Kosten und Können. Bei den meisten Observability-Tools basieren die Kosten auf dem übermittelten Datenvolumen. Je mehr Daten ihr übermittelt, desto höher sind die Kosten. Schlimmer noch ist, dass man bei vielen Anbietern die Datenmenge im Vorhinein schätzen und darüber hinausgehendes Datenvolumen teuer bezahlen muss, falls man sich verschätzt hat. Außerdem sind viele Systeme schlicht nicht in der Lage, große Datenmengen zu verarbeiten. Sie sind gar nicht darauf ausgelegt, die Daten komplett zu erfassen, und arbeiten nach dem Motto: „Ein Großteil der Daten reicht doch auch“. Doch wenn euer Unternehmen wächst und eure Datenströme Hunderte von MB, GB oder sogar TB an Daten pro Sekunde erreichen, dann muss eure Observability-Plattform mithalten können.
 Um diese Probleme zu umgehen, schlagen viele Anbieter vor, dass ihr ein Sampling durchführt, also Stichproben eurer Daten nutzt (oder anders ausgedrückt, einen Teil eurer Daten gar nicht berücksichtigt). Viele der Anbieter verpacken dies als Möglichkeit, Kosten zu sparen. Denn wenn ihr weniger Daten übertragt, habt ihr geringere Kosten für ihre Analyse und Speicherung. Doch die Nicht-Berücksichtigung bestimmer Daten hat ernste Konsequenzen. In vielen Fällen ignorieren Observability-Anbieter, die Sampling propagieren, diese Konsequenzen, da ihre Systeme die von realen Systemen generierten Datenmengen nicht bewältigen können.
Um diese Probleme zu umgehen, schlagen viele Anbieter vor, dass ihr ein Sampling durchführt, also Stichproben eurer Daten nutzt (oder anders ausgedrückt, einen Teil eurer Daten gar nicht berücksichtigt). Viele der Anbieter verpacken dies als Möglichkeit, Kosten zu sparen. Denn wenn ihr weniger Daten übertragt, habt ihr geringere Kosten für ihre Analyse und Speicherung. Doch die Nicht-Berücksichtigung bestimmer Daten hat ernste Konsequenzen. In vielen Fällen ignorieren Observability-Anbieter, die Sampling propagieren, diese Konsequenzen, da ihre Systeme die von realen Systemen generierten Datenmengen nicht bewältigen können.
Das Sampling von Daten kann leicht dazu führen, dass euch kritische Missstände entgehen. Wenn ihr ein System habt, das die meiste Zeit normal arbeitet, bei dem in seltenen Fällen die Latenz aber sprunghaft auf über 5 Sekunden ansteigt, dann kann es sein, dass eure Sampling-Methode dies nicht rechtzeitig oder überhaupt nicht erfasst. Stellt euch einmal vor, dass diese Latenzsprünge nur bei großen Bestellungen auftreten. Und stellt euch dann vor, dass diese Latenzsprünge dazu führen, dass die Kunden diese Bestellungen abbrechen. Jede einzelne abgebrochene Bestellung bedeutet verlorenen Umsatz. Ist eure App unzuverlässig oder langsam, beschweren sich manche Leute gerne auch mal sofort in sozialen Medien, wodurch eure Kosten durch den Reputationsverlust nur noch weiter steigen.
Sampling steht grundsätzlich im Widerspruch zu Observability.
Anbieter, die mit Sampling arbeiten, werden euch verschiedene Behelfslösungen für das Problem der fehlenden Daten nennen. Nichtsdestotrotz stehen Stichproben grundsätzlich im Widerspruch zu Observability: Ihr habt einfach keinen vollständigen Einblick in ein System, wenn ihr absichtlich Teile davon ignoriert.
Ich möchte euch dies anhand eines Beispiels verdeutlichen. Viele Anbieter stichprobenbasierter Observability-Tools werden behaupten, dass die Verwendung von Datenpunkt-Stichproben euch den gleichen Einblick verschafft wie Durchschnittswerte der erfassten Gesamtdaten, aber das ist schlicht falsch. In unserem Beispiel zeigen wir euch die Werte der Metrik „Duration“, die angibt, wie lange der Aufruf eines Auftragsabwicklungsservice dauert. Wie viele andere Services hat auch dieser Auftragsabwicklungsservice manchmal Schwierigkeiten, mit der Nachfrage Schritt zu halten, sodass die Aufrufdauer (und damit auch der Metrikwert) sprunghaft ansteigt.
Die Werte aus den vollständigen Daten werden in der Spalte ganz links angezeigt. Außerdem seht ihr die Analysewerte eines naiven Sampling-Systems, das jeden dritten Datenpunkt heranzieht (wobei zu beachten ist, dass die meisten Anbieter mit Sampling viel weniger als 33% der Ereignisse auswerten) sowie die Ergebnisse der Analyse durch ein „branchenführendes“ Sampling-System, das das zuvor beschriebene naive Sampling einsetzt und zudem alle Transaktionen mit einer Dauer von über 1000ms erfasst:
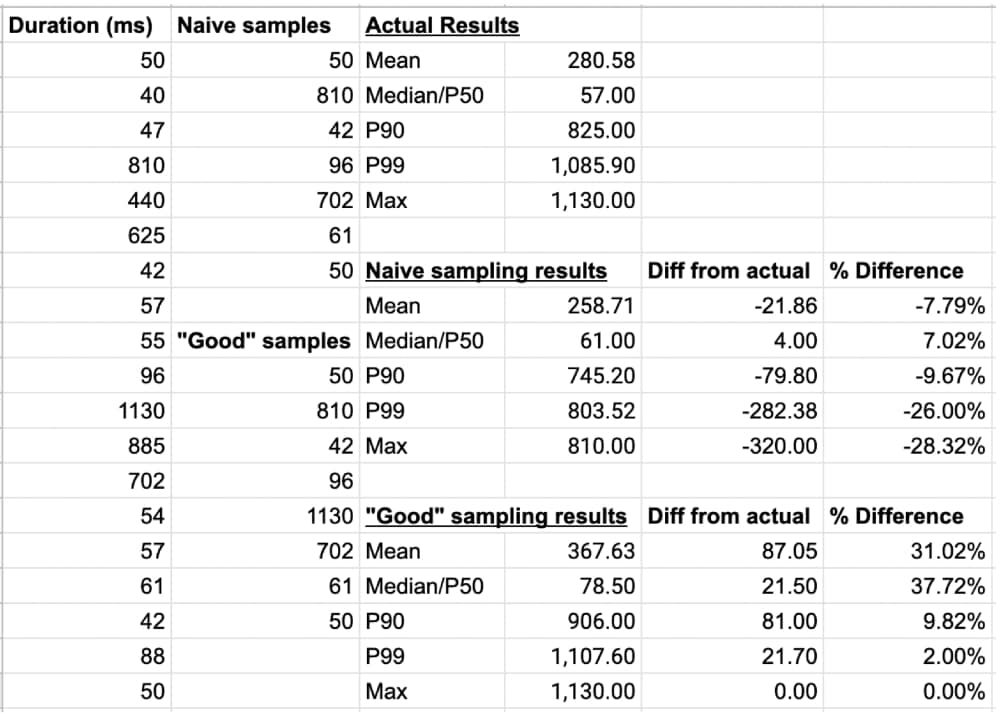
Wie ihr seht, liefern die Sampling-basierten Systeme kein korrektes Bild der Geschehnisse. Beide Systeme zeigen euch nicht den tatsächlichen, wahren Zustand an (und sind dazu auch gar nicht in der Lage). Je nachdem, welche Metrik ihr wählt, liegen die Stichprobensysteme bei „Duration“ um fast 38% daneben! Viele ältere Systeme waren auf Durchschnittswerte ausgelegt, doch angesichts der SLOs und Fehlerbudgets moderner Lösungen sind Durchschnittswerte sowieso nicht mehr wirklich sinnvoll. Perzentile geben euch ein genaueres Bild vom Zustand eurer Services – und die Sampling-Systeme liegen im gezeigten Beispiel offensichtlich falsch.
Wenden wir uns zum Schluss noch kurz dem Aufwand zu, der mit der Instrumentierung eurer Anwendungen für Observability verbunden ist. Wenn ihr kein OpenTelemetry-natives System verwendet, musstet ihr wahrscheinlich einen schwergewichtigen Agent installieren und manuell alle eure Anwendungen instrumentieren, um Metriken, Traces und Logs zu übertragen. Selbst mit einem OpenTelemetry-System wäre noch ein gewisser Entwicklungsaufwand nötig, um die Instrumentierung zu konfigurieren und einzurichten sowie zu überprüfen, dass alle entsprechenden Daten bei eurer Observability-Plattform ankommen.
 Wenn ihr Sampling einsetzt, habt ihr diesen ganzen Aufwand umsonst betrieben. Mit einem Observability-Tool, das Stichproben verwendet, schmälert ihr den Wert eurer Observability-Plattform und erhaltet auch nicht die volle Rendite aus eurer ursprünglichen Investition in die Instrumentierung von Anwendungen. Warum solltet ihr Zeit und Geld in die Entwicklung von Systemen investieren, die all diese Daten ausgeben können, nur um dann die Hälfte dieser Daten einfach wegfallen zu lassen? Das macht schlicht keinen Sinn, und Kosten lassen sich damit ganz sicher auch nicht einsparen. Ganz im Gegenteil: Es führt dazu, dass ihr wichtige Erkenntnisse zu dem Zeitpunkt verpasst, an dem sie am wichtigsten wären.
Wenn ihr Sampling einsetzt, habt ihr diesen ganzen Aufwand umsonst betrieben. Mit einem Observability-Tool, das Stichproben verwendet, schmälert ihr den Wert eurer Observability-Plattform und erhaltet auch nicht die volle Rendite aus eurer ursprünglichen Investition in die Instrumentierung von Anwendungen. Warum solltet ihr Zeit und Geld in die Entwicklung von Systemen investieren, die all diese Daten ausgeben können, nur um dann die Hälfte dieser Daten einfach wegfallen zu lassen? Das macht schlicht keinen Sinn, und Kosten lassen sich damit ganz sicher auch nicht einsparen. Ganz im Gegenteil: Es führt dazu, dass ihr wichtige Erkenntnisse zu dem Zeitpunkt verpasst, an dem sie am wichtigsten wären.
Wenn ihr ein System möchtet, das keine Daten aussortiert und auf Skalierung ausgelegt ist, dann schaut euch Splunk Observability Cloud an. Startet am besten gleich heute mit der kostenlosen Testversion von Splunk Observability Cloud.
Wenn ihr euch allgemein über Observability informieren möchtet, dann kann ich euch das E-Book Observability: Ein Leitfaden für Einsteiger empfehlen (jetzt in aktualisierter 2021 Version!).
*Dieser Artikel wurde aus dem Englischen übersetzt und editiert. Den Originalblogpost findet ihr hier: The Hidden Cost of Sampling in Observability.
----------------------------------------------------
Thanks!
Splunk

Die führenden Unternehmen der Welt vertrauen auf Splunk, einem Unternehmen von Cisco, um ihre digitale Resilienz mit der einheitlichen Sicherheits- und Observability-Plattform, unterstützt durch branchenführende KI, kontinuierlich zu stärken.
Unsere Kunden setzen auf die preisgekrönten Sicherheits- und Observability-Lösungen von Splunk, um die Zuverlässigkeit ihrer komplexen digitalen Umgebungen zu sichern und zu optimieren – in jeder Größenordnung.

Die neuesten Artikel von Splunk, direkt im eigenen Posteingang.
© 2005 - 2026 Splunk LLC All rights reserved.
© 2005 - 2026 Splunk LLC All rights reserved.