
オブザーバビリティの現状
グローバル調査で明らかになった、AI導入、セキュリティチームとのコラボレーション、ビジネス収益の促進要因に関する現状をご紹介します。
DevOpsを成功に導くには、DevOpsの取り組みがどれだけ効果をあげているかを測定する必要があります。適切なDevOpsメトリクスを追跡することで、DevOpsプラクティスの効果を評価できます。
このブログでは、さまざまなDevOpsメトリクスを紹介し、DevOpsメトリクスの重要性、さまざまな目標をサポートする主要なメトリクス、そしてここで取り上げたDevOpsメトリクスのスコアを向上させるためのヒントについても説明します。
Splunk IT Service Intelligence (ITSI)は、顧客に影響が及ぶ前にインシデントを予測して対応するための、AIOps、分析、IT管理ソリューションです。

AIと機械学習を活用して、監視対象のさまざまなソースから収集したデータを相関付け、関連するITサービスやビジネスサービスの状況を1つの画面にリアルタイムで表示します。これにより、アラートのノイズを低減し、障害を未然に防ぐことができます。
DevOpsメトリクスとは、主要なDevOpsプラクティスまたはプロセスのパフォーマンスを測定する際に役立つ次のようなデータです。
これらのメトリクスにより、組織は設定した目標の達成状況を監視できます。また、メトリクスは、DevOpsプロセスにおけるアプリケーションパフォーマンスや従業員の生産性を最大限に高めるのを妨げるボトルネックを特定するのにも役立ちます。これらのメトリクスを活用することで、必要な改善を行い、投資効果を最大限に引き出すことができます。
この記事では、これらのメトリクスを以下のようなカテゴリに分類しています。
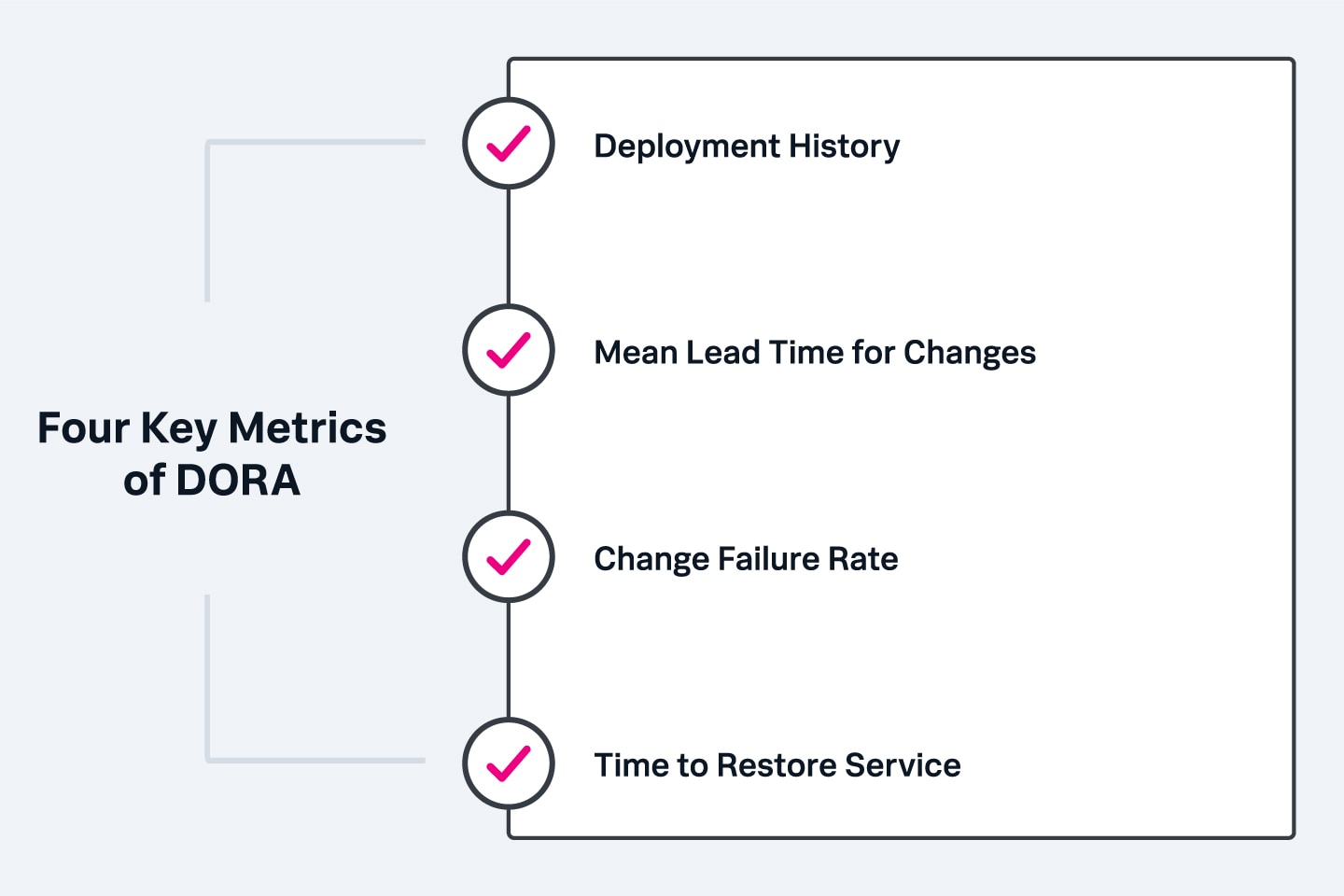
よく知られているDORAというDevOpsメトリクスは、GoogleのDevOps Research and Assessment(DORA)チームによって作成されたものです。DORAは、長年にわたって、高いパフォーマンスを発揮するDevOpsチームの特徴を特定するべく取り組んできました。DORAの4つのメトリクスは、DevOpsの原則とその実用的な応用に関する7年以上に及ぶ研究の成果として定義されたものです。
DORAフレームワークでは、以下の4つの主要なメトリクスを使って、DevOpsの基本特性であるスピードと安定性を測定します。「デプロイの頻度」と「変更の平均リードタイム」でDevOpsのスピードを測定し、「変更の失敗率」と「サービス復旧時間」でDevOpsの安定性を測定します。この4つのDORAメトリクスを併用することにより、DevOpsチームのパフォーマンスを評価するベースラインを確立し、改善領域を探ることができます。
次のセクションでは、この4つの主要なDevOpsメトリクスと、良いスコアとはどのようなものか、そしてそれらを改善する方法について簡単に説明します。
変更の失敗率は、本番環境でただちに修正が必要な問題(サービスの低下や停止)を引き起こしたデプロイの割合を示します。問題への対応に費やす時間が長いと、新しい機能の開発や顧客価値の向上にかけられる時間が減るため、変更の失敗率は低いのが理想です。このメトリクスを算出するには、通常、失敗したデプロイの回数をデプロイの総数で割って、平均割合を求めます。本番環境へのデプロイ前のバグ修正は数に含めません。デプロイの回数と、それらの中で修正プログラムまたはロールバックにつながった回数を数えることで、CFRを算出できます。計算式は次のようになります。
(失敗したデプロイ数 / デプロイの総数) x 100
変更の失敗率のベンチマークは次のように分類されます。
このメトリクスは、以下を把握するための優れた指標となります。
効果的なDevOpsプラクティスに従っている場合、チームのCFRは0〜15%の範囲に収まるはずです。トランクベースのデプロイ、テストの自動化、作業を少しずつ段階的に行うといったプラクティスが、このメトリクスの改善に役立ちます。
デプロイの頻度は、変更を本番環境にデプロイする頻度を示します。通常、パフォーマンスの高いチームは、本番環境へのコードのデプロイをオンデマンドで、または1日に複数回行います。月1回または週1回のデプロイでは、DFは低くなります。
このメトリクスは、チームが次のことを行うのに役立ちます。
デプロイ頻度のベンチマークは次のように分類されます。
デプロイが「成功した」と見なす基準は組織によって異なります。また、組織内でもチームによってデプロイの頻度はさまざまです。
変更のリードタイムは、コミットされたコードが本番前環境で必要なすべてのテストに合格してから本番環境で使用可能になるまでにかかる時間を示します。このメトリクスの計算には、コードをコミットした時間とリリースの開始時間を使用します。
成熟したDevOpsチームのLTは時間単位ですが、パフォーマンスが中~低程度のチームのLTは一般的に数日または数週間となります。トランクベースのデプロイ、「スモールバッチ」での作業、テストの自動化などのプラクティスを取り入れることで、LTを短縮できます。
変更の平均リードタイムのベンチマークは次のように分類されます。
組織独自のプロセス(専門のテストチームを置く、テスト環境を共有するなど)がリードタイムに影響し、チームのパフォーマンスが低く見積もられる場合もあります。
MTTRは、本番環境における全体的な障害またはサービスの部分的な中断から復旧するまでの時間を示します。パフォーマンスの高いチームのMTTRは1時間未満ですが、パフォーマンスの低いチームでは1週間に及ぶことがあります。MTTRは、インシデントが発生した時間と、その解決にかかった時間を考慮して算出できます。
MTTRスコアは、インシデントの発生時にどのくらい迅速にそれを特定し、修正プログラムをデプロイできるかによって決まります。システムとサービスを継続的に監視し、インシデントの発生後すぐに担当者にアラートを送信することで、MTTRスコアを改善することができます。これにより、担当者は迅速に必要な措置を取ることができます。
サービス復旧時間のベンチマークは次のように分類されます。
実質的にすべての業界の組織が、ソフトウェア開発とデリバリーのパフォーマンスを測定、向上させるための手段としてDORAメトリクスを活用できます。たとえば、モバイルゲームを開発している企業であれば、DORAメトリクスを活用し、プレイが切断された場合の対応を把握して最適化することで、顧客の不満を最小限に抑え、収益を維持できます。また、金融機関であれば、DORAメトリクスの活用による生産性向上とダウンタイム低下で節約できたコストをステークホルダーに金額で示すことにより、DevOpsの効果を証明できます。
DORAメトリクスは、組織のソフトウェアデリバリーのパフォーマンスを定量化し、同業他社と比較するための便利なツールです。適切に活用できれば、以下のようなメリットが得られます。
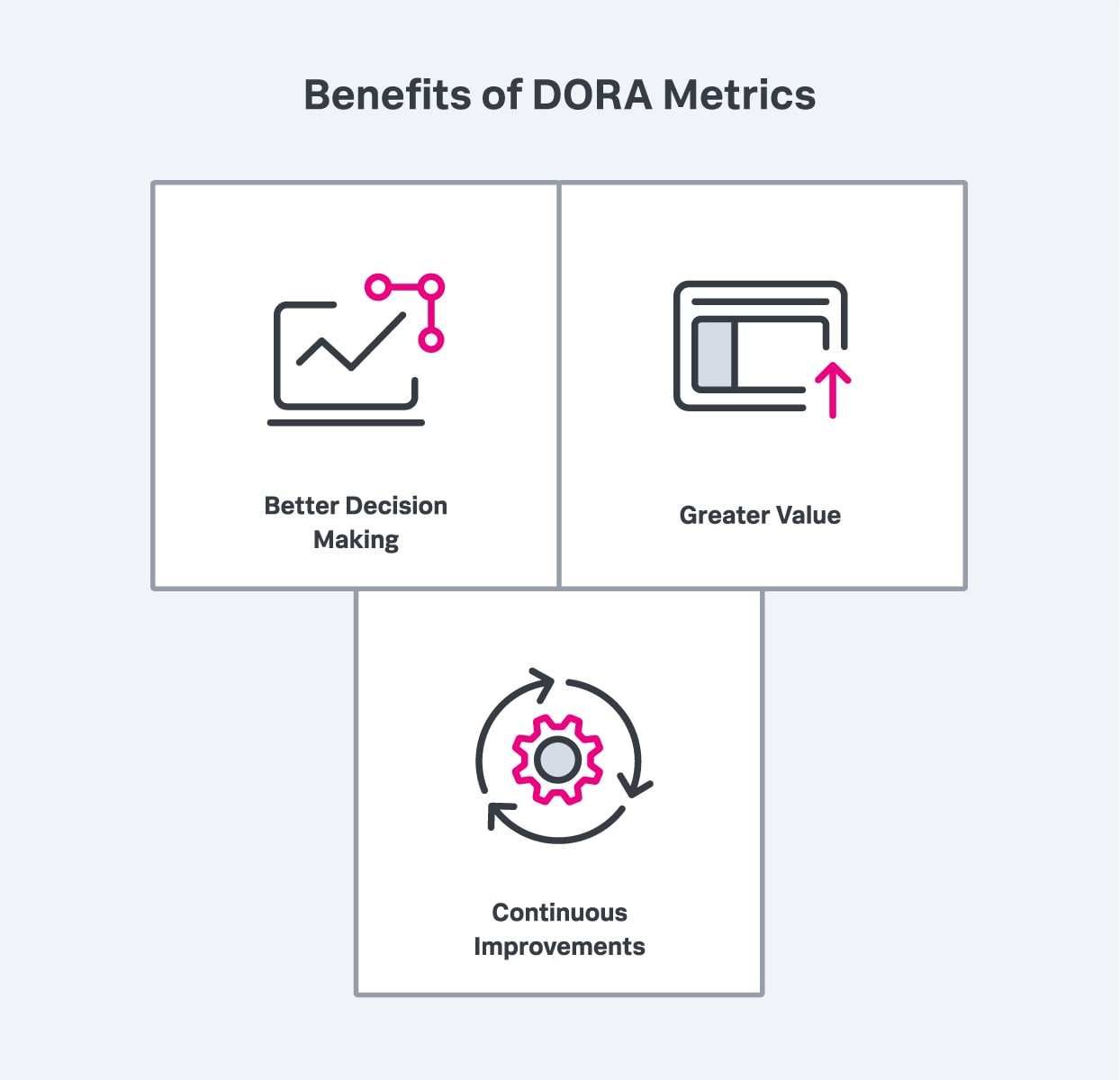
DORAメトリクスは、意思決定の向上、価値の拡大、継続的な改善というメリットをもたらします。
DORAメトリクスは、ソフトウェアデリバリーのパフォーマンスを評価するための出発点を提供する一方で、いくつかの課題ももたらします。メトリクスの考え方は組織によって異なるため、組織全体のパフォーマンスを評価し、他社のパフォーマンスと比較することが困難に感じられることがあります。
また、各メトリクスを測定するには、通常、複数のツールやアプリケーションから情報を収集する必要があります。たとえば、サービス復旧時間を測定するには、PagerDuty、GitHub、Jiraなどからデータを収集しなければならないでしょう。使用するツールがチームによって異なる場合は、データの収集と統合がさらに難しくなります。
DORAのメトリクスは、出発点として最適です。しかし、DevOpsプロセスの成功を測定するのに役立つ重要なDevOpsメトリクスは他にもいくつかあります。次のセクションでは、そのメトリクスについて詳しく見てみましょう。テストとコード品質、デプロイ、継続的インテグレーション、顧客満足度、監視プラクティスのメトリクスに分けて説明します。
このメトリクスは、下位レベルのテストで見逃されて本番環境にリリースされた不具合の数を測定します。チームは、この値をゼロに近づける必要があります。不具合の見逃し率が高い場合は、テストプロセスの自動化と改善を強化する必要があることを示しています。
DevOpsチームは、コードを本番環境にリリースする前に、本番前環境で少なくとも90%の不具合を見つける必要があります。
このメトリクスは、コードの品質を示す優れた指標となります。CIパイプラインで失敗したテストの数を、実行したテストの総数で割ることで測定できます。
CIテストの失敗率が高い場合は、コードにさらなる改善が必要であることを意味するため、開発者にコードをコミットする前に独自の単体テストを実行するよう促します。
コードカバレッジは、自動テストスイートによってテストされたコードの量を示します。一般的に、自動コードカバレッジを高く維持することがDevOpsのベストプラクティスであるとされています。これは、障害の迅速な検出に役立つためです。ただし、テストカバレッジが100%であっても、不要なテストが含まれている可能性があるため、必ずしもコード品質が最高であるわけではありません。
サイクルタイムは、ある1つの製品の工程開始からエンドユーザーに提供する準備が整うまでにかかる時間を測定します。開発チームの場合、サイクルタイムはコードのコミットから本番環境にデプロイされるまでの時間です。
サイクルタイムが長いほど、進行中の作業が多くなり、ワークフローの効率は低下します。サイクルタイムを短縮するには、ワークフローの効率を最適化して改善する必要があります。
デプロイの規模は、実装された機能、ストーリー、バグ修正の数によって決まります。これを測定するには、各デプロイで完了したストーリーポイントの数を使用します。このメトリクスを、デプロイの頻度やサイクルタイムなどの他のメトリクスと組み合わせることで、各デプロイの生産性を把握できます。
デプロイ時間とは、デプロイを完了するのにかかる時間です。このDevOpsメトリクスは、デプロイパイプラインの効率を測定するのに役立ちます。デプロイ時間が非常に長く、デプロイに何時間もかかる場合は、潜在的な問題があることを示しており、リリースチームの生産性を低下させます。
このメトリクスを改善するには、デプロイパイプラインから不要なステップを削除し、並列化の仕組みを導入します。
フローメトリクスは、特定の製品のバリューストリームによって提供される価値の大きさと、価値を提供するフロー全体の速度を測定するためのフレームワークです。従来のパフォーマンスメトリクスでは特定のプロセスやタスクが対象となるのに対して、フローメトリクスでは1つの事業が成果を生むまでの流れ全体が対象になります。これにより、バリューストリームの中で目的の成果達成を妨げる要因がどこにあるかを見つけ出すことができます。
バリューストリームを測定するための主なフローメトリクスは4つあります。
フローメトリクスを使用することで、組織が導入しているソフトウェアデリバリー手法に関係なく、ソフトウェアデリバリープロセス全体を顧客とビジネスの両方の観点で理解できます。これにより、ソフトウェアデリバリーがビジネス成果にどのように影響しているかを明確に把握できます。
このメトリクスは、1日あたりのCIパイプラインの実行回数を示します。パフォーマンスの高いチームは1日あたりのCIの実行回数が多く、通常は開発者1人あたり4~5回です。これは、CI/CDパイプラインでのリリースが頻繁に行われ、信頼性があることを表す適切なプラクティスといえます。
CIは1日に何度も実行できますが、そのすべてが成功するとは限りません。CIの成功率は、成功したCIの総数をCIの総実行回数で割ることで測定できます。CIの成功率は高い方が望ましく、これによりCI/CDプロセスが適切に管理され、開発者が効果的に開発テストを行っていることがわかります。
言うまでもなく、これらすべての目標は顧客満足度の向上です。測定すべきメトリクスは次のとおりです。
顧客から報告されたインシデントやサポートチケットの数は、顧客が製品にどの程度満足しているかを示します。このメトリクスは、リリースに関する顧客からのフィードバックを追跡するのに役立つだけでなく、本番環境における問題の重大度も可視化します。
顧客からのチケットの数が少なければ、現在のアプローチが適切であり、必要な改善はわずかであることを意味します。
アプリケーションの可用性とは、アプリケーションが完全に機能する状態でエンドユーザーが利用できる時間を表します。アプリケーションエラーによりダウンタイムが長引くと、アプリケーションにアクセスしようとするユーザーの不満が高まります。アプリケーションの可用性を向上させるには、次のような戦略を立てる必要があります。
このメトリクスは、ストレスがかかったり、さまざまなユーザー負荷が与えられたりした状況下でのアプリケーションのパフォーマンスを評価します。チームは、本番環境にデプロイする前に、本番環境と同等のデプロイ前環境でこれらのテストを実施する必要があります。
このメトリクスにより、システムの負荷が高いときに失敗する可能性のあるトランザクションや不具合を特定できます。その後、デプロイ前にコードを最適化し、一貫したユーザーエクスペリエンスを提供することができます。
MTTDは、本番環境での障害を検出し、問題として認識するまでにかかる時間です。このメトリクスは、監視システムとアラートシステムの有効性を評価するのに役立ちます。MTTDが短いほど、エンドユーザーに影響を及ぼす前に問題を修正して本番環境にリリースできる可能性が高くなります。MTTDは以下の方法で短縮できます。
このメトリクスは、システムにアクセスしているユーザーの数とリアルタイムで発生しているトランザクションの数を示します。負荷が高い場合、システム障害が発生するリスクが高くなります。そのため、問題が発生した場合に備えて、DevOpsチームをすぐに対応できる状態にしておきます。
DevOpsメトリクスの追跡を自動化すれば、ソフトウェアデリバリーのパフォーマンス改善にすぐに取り組むことができます。エンジニアリングメトリクスを追跡するツールの中には、一般的なDevOpsメトリクスを収集できるものもあります。たとえば以下のツールが該当します。
メトリクス追跡ツールを選定するときは、CI/CDツール、問題追跡ツール、監視ツールなど、他の主要なソフトウェアデリバリーシステムと統合できるかどうかを確認することが重要です。また、メトリクスを見やすい画面でわかりやすく表示する機能があれば、すぐにインサイトを取得して傾向を判断し、データから結論を導き出すことができます。
DevOpsメトリクスは、DevOpsプラクティスの有効性と、それらが組織の目標達成にどのように貢献しているかを評価するためのデータです。4つの主要なDevOpsメトリクスには、変更の失敗率、デプロイの頻度、変更のリードタイム、サービスの平均復旧時間があります。
さらに、デプロイ、テスト、監視、エンドユーザーエクスペリエンスなど、ソフトウェアデリバリーパイプラインの主要なタスクに関連するDevOpsメトリクスが他にもいくつかあります。これらのメトリクスを、組織が導入したDevOpsプロセスと併せて測定することで、ビジネスを確実に成功させることができます。
このブログはこちらの英語ブログの翻訳です。
この記事について誤りがある場合やご提案がございましたら、splunkblogs@cisco.comまでメールでお知らせください。
この記事は必ずしもSplunkの姿勢、戦略、見解を代弁するものではなく、いただいたご連絡に必ず返信をさせていただくものではございません。

© 2005 - 2026 Splunk LLC 無断複写・転載を禁じます。
© 2005 - 2026 Splunk LLC 無断複写・転載を禁じます。

