意思決定においてデータが重要であることは言うまでもないでしょう。だからこそ、Splunkにデータを取り込む際は一定の基準に従うことも重要になってきます。基準を定めておけば、ログが適切な形式に整えられ、ソースデータに関する詳細を理解するためのドキュメントを用意できます。そこで、このブログ記事では、Splunkのセキュリティセンターオブエクセレンスが取り入れている基準とベストプラクティスをいくつかご紹介します。組織の状況やユースケースはそれぞれ異なるため、そのすべてを採用する必要はありませんが、現在のデータ取り込みプロセスを改善するために役立つはずです。
調査とメタデータ
データを取り込む前に、データの詳細と用途を理解しておくことが重要です。Splunkのセキュリティセンターオブエクセレンスでは、新しいデータオンボーディングリクエストがあると、リクエスト者に質問票への入力を求めます。チケットのトリアージは常に、必要な情報がすべて揃ってから行います。
質問内容の一部と、その質問が必要な理由を以下に示します。
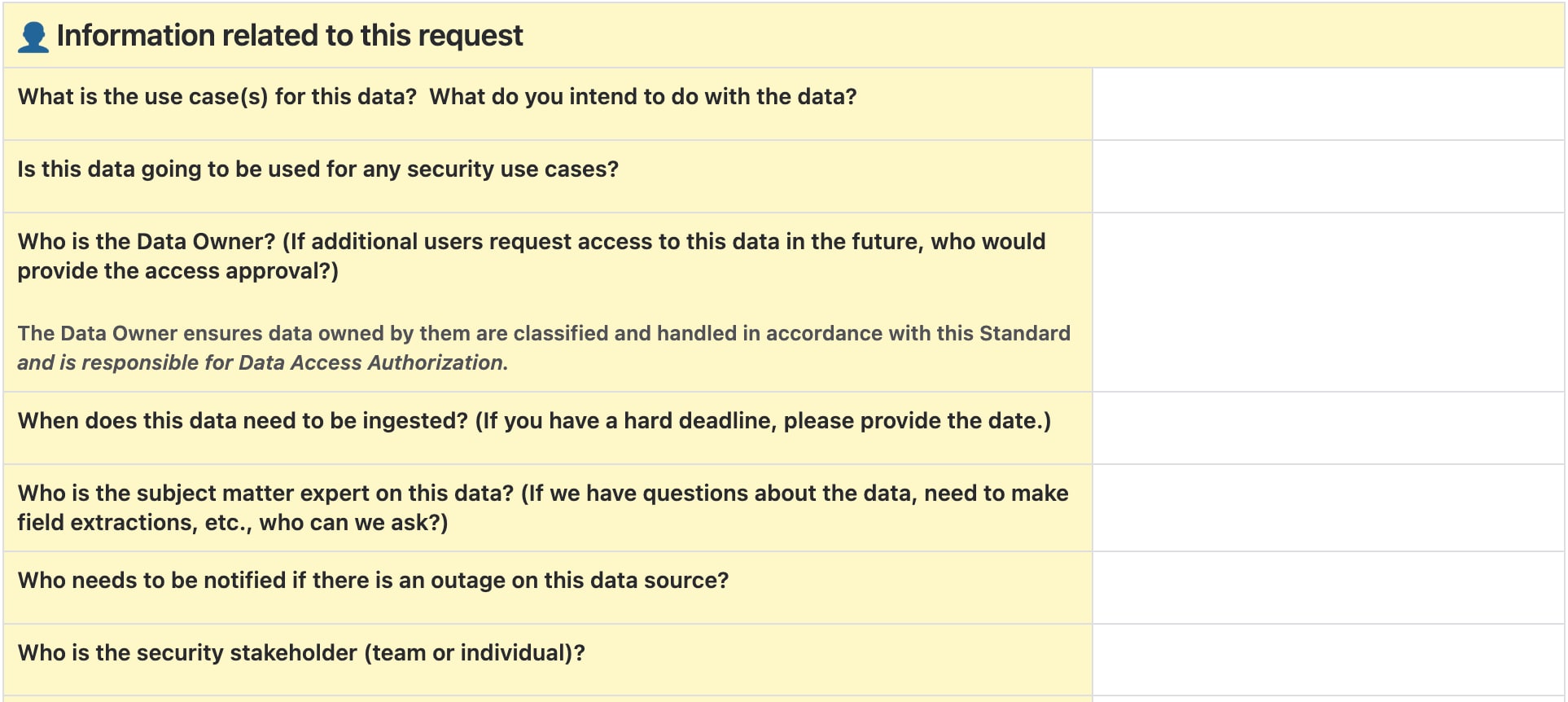
- データに関する情報
- このデータはどのアプリケーション/サービス/アプライアンスで生成されますか?
- このデータはどのホストで生成されますか?
- このデータにはホスト上のどのパスでアクセスできますか?
- このデータはどのような形式ですか?
以上は、データのソースについて知るための質問です。
- データのサンプルをJIRAチケットに添付してください。
- このデータはどのような方法でSplunkに送信できますか?
- 利用可能なSplunkテクノロジーアドオンはありますか?
以上は、データを取り込むための最適な方法を判断するための質問です。これは、データの変換方法と拡張性に大きく左右されます。
- インデックス前に取り除く必要のある機密データは含まれていますか?
- 個人情報や、その他の機密性の高いデータは含まれますか?含まれる場合は、どのようなデータか説明してください。
- このデータはどのデータ分類に該当しますか?
- このデータにアクセスできるのは誰ですか?
以上の情報は、データの扱いとデータアクセスを適切に設定するために必要です。
- データの保存
- このデータの送信先となる既存のインデックスはありますか?または、新しいインデックスが必要ですか?
- このデータはどのくらいの期間保持する必要がありますか?
- いつ以降のデータを取り込む必要がありますか?
- ソースからSplunkにどのくらいの頻度でデータを送信する必要がありますか?
これらの情報はいずれも重要ですが、既存のポリシーやニーズに基づいて、Splunk管理者の判断で変更される場合があります。多くのチームや組織は、インデックスの命名規則、デフォルトの保持期間、新しいインデックスを作成する条件などについて基準を定めています。また、一部のアドオンでは、開始日を指定して過去のデータを取り込むことができるため、オンボーディング日以前のデータを取り込むこともできます。
たとえば、私たちのチームでは、以下の5つの条件のいずれかに該当する場合に新しいインデックスを作成します。
- 通常とは異なるアクセス方法が必要な場合。たとえば、医療情報や財務情報など、機密性の高い情報が含まれる場合が該当します。
- 通常とは異なる保持期間を設定する必要がある場合。私たちのSplunk環境では、デフォルトでデータが13カ月間保持されますが、要件によっては、アーカイブデータをさらに長期間保持することもあります。
- データが既存のインデックスと無関係である場合。私たちのチームではツールに基づいてインデックスを作成していますが、組織によっては、プロジェクトやチームごとなど、他の条件に基づいてインデックスを作成している場合もあるでしょう。
- 環境のタイプが異なる場合(ステージング環境、本番環境など)。本番環境のデータは、障害発生時の修正の優先度が高くなるため、私たちは専用のインデックスに保存して、アラートをすばやく生成できるようにしています。
- バケットサイズが大きすぎてサーチの遅延を引き起こす可能性がある場合。この状況は、保持期間が短ければ発生する可能性は低くなりますが、取り込むデータがあまりにも大量または詳細である場合は発生する可能性が高くなります。
- 追加情報
- このデータのユースケースはどのようなものですか?このデータを使って何をする予定ですか?
- データ所有者は誰ですか?
- データ所有者には、データが内部ポリシーに従って正しく分類および処理されるようにする責任があります。私たちの環境では、ユーザーのアクセスを承認および管理する責任も担います。
- このデータのSME (サブジェクトマターエキスパート)は誰ですか?
- このデータでは障害を監視する必要がありますか?
- このデータソースで障害が発生したときに誰に通知する必要がありますか?
- データをどのレベルで監視する必要がありますか?(インデックス、ソースタイプ、ソース、ホストなど)
- アラートはどの方法で通知する必要がありますか?(メール、Splunk On-Call、メッセージングプラットフォームなど)
- このデータで障害が発生したときの影響や緊急性はどの程度ですか?
- チケットのトリアージ方法
- チケットを受け取ったら、質問票を確認して、必要な情報がすべて記入されているかどうかをチェックします。
- データオンボーディングリクエストの各チケットには受け入れ基準が自動的に追加されます(チケットの説明欄と、要件を満たしているか確認するチェックリストの両方に追加)。また、リクエストの詳細がわかるように質問票に記入するよう求めるコメントも自動的に追加されます。
- 質問票で足りない情報がある場合は、リクエスト者に連絡して情報を提供してもらいます。
- 必要に応じて、リクエスト者と直接会って話すこともあります。リクエストをより深く理解するには、テキストだけのコミュニケーションよりも、直接話す方が効果的かつ効率的な場合もあります。
- すべての情報が揃い、私たちのチームが対応する必要のあるユースケースだと判断したら、チケットをトリアージし、エンジニアが対応します。
- 私たちのチームでは、データオンボーディングのポリシー、プロセス、手順に関するドキュメントを作成しています。これらのドキュメントには、チームが対応すべき案件と対応が不要な案件がまとめられています。
プロセス
リクエストが承認されると、まず開発環境にデータを送信します。本番環境のインデクサークラスターに保存するのは検証済みのデータのみです。開発環境で、データの取り込みに関するあらゆる側面をテストし、すべてのテストに合格してから本番環境に移行します。
データ取り込みの設定時のテスト項目
データの取り込みで常に考慮すべきは「Great 8」です。これは、すべてのデータソースに定義すべき8つの設定のことです。どれもデータ解析で重要な役割を果たします。これらの項目を一般的な設定やデフォルトのままにするのではなく、ソースに合わせて設定することが、パフォーマンスの向上につながります。
この設定はprops.confで行います。
- SHOULD_LINEMERGE
- Splunkでの複数行イベントの処理方法を定義します。true (デフォルト)に設定すると、BREAK_ONLY_BEFOREなどの分割ルールを区切りとして、複数行が1つのイベントにまとめられます。trueに設定すると柔軟性が向上しますが、パフォーマンスが低下する可能性があります。falseに設定すると、LINE_BREAKERを区切りとして、各行が個別のイベントに分けられます。
- LINE_BREAKER
- データを個々のイベントに分割するための区切りを正規表現で指定します。デフォルトでは改行(([\r\n]+))ごとに新しいイベントが作成されますが、区切りは非常に柔軟に設定できます。
- LINE_BREAKERとSHOULD_LINEMERGE = falseを組み合わせれば、複数行イベントを効率的に作成できます。
- EVENT_BREAKER_ENABLE
- この設定はユニバーサルフォワーダーにのみ適用されます。イベントをインデクサークラスターに均等に割り振るかどうかを指定します。この設定は大規模なデータで特に役立ちます。デフォルトはfalseですが、適切なEVENT_BREAKER設定とともにtrueに設定するのが一般的です。
- EVENT_BREAKER
- この設定も正規表現で指定します。ユニバーサルフォワーダーにのみ適用される設定で、EVENT_BREAKER_ENABLEがtrueの場合に、インデクサーに送信するイベントの分割方法を定義します。キャプチャグループを指定し、最初のキャプチャグループがイベントの終了位置を示すため、フォワーダーは次のイベントの開始位置から、必要に応じて別のインデクサーに振り分けることができます。通常、この設定はLINE_BREAKERと同じにします。
- TRUNCATE
- イベントの最大長をバイト単位で指定します。イベントの中でこの長さを超える部分のテキストは切り捨てられます。デフォルト値は10000で、一般的に安全な値です。スタックトレースなど、かなり長いイベントがある場合は、もっと高い値に設定した方が安全でしょう。0に設定すると、1つのイベントとして許容されるテキストの長さが無制限になるため、通常はお勧めしません。この設定を増やすことが頻繁にある場合は、データの品質が低い可能性があります。その場合は、データをより小さい単位でイベントに分割すると改善するかもしれません。イベントが極端に大きいと、ブラウザでの処理で問題が起きたり、Splunkで結果を表示できなくなったりする可能性があります。SHOULD_LINEMERGEをfalseに設定したうえで、複数行イベントが1つのSplunkイベントにまとめられる場合、TRUNCATEによる制限は、イベント内の各行ではなく、イベント全体に適用される点に注意してください。この場合、TRUNCATEの上限に達しやすくなります。
- TIME_PREFIX
- この設定も正規表現で指定します。データの中で、この正規表現に一致するテキストの直後にあるタイムスタンプが_timeに使用されます。デフォルトは空の文字列です。この場合、最初に見つかったタイムスタンプが抽出されます。
- MAX_TIMESTAMP_LOOKAHEAD
- タイムスタンプとして抽出する文字数を数値で指定します。TIME_PREFIXを設定していない場合、この値は行の先頭からの文字数を示します。TIME_PREFIXを設定した場合は、一致する正規表現の末尾からの文字数を示します。デフォルトは128文字です。
- TIME_FORMAT
- 人間が読める形式の日時がデータに含まれる場合は、この設定で時間変数を使って日時の形式を定義すると、Splunkでタイムスタンプがエポック値として抽出されます。デフォルトは空です。そのため、データのタイムスタンプがすでにエポック値である場合、設定は不要です。
- TZ
- この設定はGreat 8には含まれませんが、イベントの適切なタイムゾーンを手動で設定するために役立つので、ここで取り上げます。イベントのタイムスタンプにタイムゾーンが含まれない場合、またはフォワーダーのタイムゾーンが異なる場合に使用します。TZを設定した場合、Splunkでは、フォワーダーのタイムゾーンではなく、TZで定義したタイムゾーンが使用されます。設定しなかった場合は、デフォルトでフォワーダーのタイムゾーンが使用されます。
その他、確認および設定したい項目には以下のものがあります。
- データ解析(Great 8以外)
- ホスト名が正しく設定されているか確認する。Splunkフォワーダーでは、デフォルトで、IPアドレスまたはマシンのホスト名のいずれかが使用されます。ホスト名は、データがsyslogを経由するなど、何らかの理由で変更される場合があります。デフォルトのホスト名はsystem/local/inputs.confファイルで設定できますが、props.confとtransforms.confで、イベントデータに基づいてホスト名を設定することもできます。
- データの形式を確認する。KV_MODEまたはINDEXED_EXTRACTIONSを使えば、JSONやXMLなどのデータタイプを解析できます。ただし、同じソースタイプにこの両方を設定することはできません。
- 通常は、必要なディスク容量が少なくて済むため、INDEXED_EXTRACTIONSよりもKV_MODEを使用することをお勧めします。INDEXED_EXTRACTIONSは、データをtstatsサーチで使用するなど、フィールドをインデックス時に解析する必要がある場合にのみ使用します。
- ただし、KV_MODE=jsonに設定すると、解析が制限されることに注意してください。私が把握している限り、この制限はデフォルトで10240文字に設定されています。この設定は、limits.confの[kv]スタンザ内のmaxcharsで定義されています。
- つまり、フィールドの抽出で抽出されないデータがある場合は、以下の設定を確認します。
- maxchars - ここで定義した文字数を1つのイベントの最大長としてフィールドの抽出が行われます。イベントがこの制限を超える場合、最大文字数を超えたテキストについてはフィールドの抽出が行われません。イベントのサイズが非常に大きい場合は、この設定を使って処理対象となるテキストを制限することで、パフォーマンスを向上させることができます。
- limit - この設定も[kv]スタンザ内にあり、抽出されてフィールドピッカーで利用可能なフィールドの最大数を定義します。デフォルトは100です。それよりも多くのフィールドが必要な場合は値を上げます。0に設定するとすべてのフィールドが抽出されますが、パフォーマンスが低下する可能性があります。
- extraction_cutoff - フィールド抽出の上限をバイト単位で設定します。[spath]スタンザで設定し、spathコマンドと自動kv抽出の両方に適用されます。デフォルトは5000バイトです。
自動kvに問題があり、どの制限の設定が影響しているかわからない場合は、代替手段として、サーチバーでspathコマンドを使用する方法もあります。ただし、その場合でも、このスタンザで設定された制限は適用されます。
- ナレッジオブジェクトの設定と更新
- 共通情報モデル(CIM)は、異なるソースタイプのデータを正規化するために不可欠です。スタンドアロンAppとしてSplunk環境にインストールでき、事前設定済みのデータモデルが多数含まれています。新しいデータを取り込むときは、フィールド名やタグ付けなどをできるだけCIMに合わせることをお勧めします。
- マクロは重要です。インデックスのマクロを設定すると、ソースタイプやインデックスが変更されたときに、それが使われているすべてのナレッジオブジェクトで設定を変更しなくても、マクロで設定を変更するだけで済むため、非常に便利です。マクロはデータモデルで多用されているため、新しいインデックスや関連するインデックスに合わせてマクロを更新することが重要です。
- イベントタイプとタグもデータモデルとCIMで重要な役割を果たします。これらを設定することで、新しいインデックスの正規化を効率的に行うことができます。
データ取り込み後のチェック
- ドキュメント
- すべてのデータについてデータフロー図を作成し、ホスト名、転送プロトコル、認証情報など、データが通過するすべてのコンポーネントの情報を記載します。データフロー図は、データに問題があったときに、その発生箇所を調査するために非常に役立ちます。
- ランブックなどの補足ドキュメントを作成し、データフロー図と関連付けることが重要です。これらのドキュメントに、認証情報のローテーション、エラーメッセージの修復、データに関する質問票で収集した情報、設定に関する有用な情報など、さまざまな状況への対処に役立つ情報を詳しく記載します。
- 監視
- 関連情報を含む静的ルックアップを使用して、データ障害を監視します。ルックアップには、監視対象のインデックス、ソースタイプ、ソース、ホスト、想定されるデータの受信頻度、問題が発生した場合の連絡先を記載します。また、週末にデータを受信することがない場合や、定期的なメンテナンス期間がある場合など、特定の時間枠を除外するためのフィルターも含めます。その他、障害発生時の修復の優先度や、データの機密レベルなども記載します。
- 想定した頻度でデータがインデックスされていない場合は、データ障害の可能性を示すアラートをトリガーします。
- 障害発生以外に、イベント数の急激な増減や、処理の遅延(データは受信していてもインデックス時刻とタイムスタンプのずれが大きい状況)も監視します。
- 障害の原因が上流にあるのかローカルにあるのかを判断するために、アラートはSOARを介して送信されます。SOARの分析結果は、上流の問題の場合(認証情報の期限切れなど)はそのデータの連絡先に、Splunk内の問題の場合(ファイルパスの変更など)はSplunk管理チームに通知されます。アラートには、既知の問題とその修復手順を記したランブックも含めます。
- アクセス
- ロールベースアクセス制御(RBAC)のベストプラクティスについてはここでは説明しませんが、データにアクセスできること、およびアクセス権がポリシーに沿って付与されていることをユーザー自身に確認してもらうことが重要です。
- データ所有者にも、データが正しいことを確認してもらい、リクエストが問題なく完了したことを承認してもらいましょう。
実践のヒント
データオンボーディングで特に重要なことの1つは、すべてのリクエストに対応できるように準備しておくことです。特にリクエストを頻繁に受け取る場合、プロセスを効率化することは必須です。そうしないと、バックログがたまる一方です。
データ取り込みの効率を向上させるために私たちが行っている対策がいくつかあります。これらが役立つかどうかは組織によって異なりますが、私たちの組織ではうまく機能しています。
- すべてのデータオンボーディングで使用するprops.confのテンプレートを作成します。そこには、少なくともGreat 8の設定を含めます。テンプレートを用意しておけば、ファイルの作成時間を節約できるだけでなく、設定漏れを防ぐこともできます。
私たちが使用しているGreat 8のデフォルト設定は以下のとおりです。
SHOULD_LINEMERGE = False
LINEBREAKER = ([\r\n]+)
EVENT_BREAKER_ENABLE = True
EVENT_BREAKER = ([\r\n]+)
TRUNCATE = 10000
TIME_PREFIX = ^
MAX_TIMESTAMP_LOOKAHEAD = 35
TIME_FORMAT = %F %T.%3N %:z
これらの設定、特に時間に関するオプションはカスタマイズすることが多いですが、出発点として非常に役立ちます。
- 独自のスクリプトを使用する場合は、フォワーダー上のアプリケーションでも、HTTPイベントコレクター(HEC)経由での送信でも、ログの形式を標準化します。たとえば、私たちのチームは、HECからの取り込みで常に使用する独自のPython SDKを作成しました。このSDKでは、標準の形式に沿ったログが生成されるため、どのデータセットで問題が発生してもトラブルシューティングを円滑に行うことができます。また、SDKが基盤を提供してくれるため、スクリプトを効率的に作成できるというメリットもあります。
- できるだけ自動化します。データオンボーディングプロセスの中で自動化できる部分があるならば、自動化すべきです。これにより、初期作業は増えるかもしれませんが、その後のリクエスト処理にかかる時間を短縮するとともに、人的ミスが生じるリスクを減らすことができます。
- データリクエストを受け取ったときに常に使用する質問票を用意します。この質問票には、必要なすべての詳細を確認するための質問を含めます。「調査とメタデータ」セクションで紹介した質問を参考にするのもよいでしょう。事前に質問と回答例を用意しておくことで、データの処理について何度も確認を取る手間を省くことができます。
まとめ
Splunk環境にデータを適切に取り込むことは、特に重要なプロセスの1つです。Splunkのセキュリティセンターオブエクセレンスとして、私たちは、Splunk社内で効率性、拡張性、セキュリティに優れたソリューションを構築し、そこで得られた知見をお客様やユーザーと共有することに取り組んでいます。私たちの解決策があらゆるユースケースに最適であるとは限りませんが、お客様独自のプロセスを構築または改善する際の新しいアイデアや設計のヒントになれば幸いです。
このブログはこちらの英語ブログの翻訳、山村 悟史によるレビューです。



