
オブザーバビリティの現状
グローバル調査で明らかになった、AI導入、セキュリティチームとのコラボレーション、ビジネス収益の促進要因に関する現状をご紹介します。
このブログ記事は、Akshit Groverとの共同執筆です。
データベースは今日のアプリケーションを支える柱です。そのため、データベースクエリーのパフォーマンスがわずかでも低下すると、エンドユーザーのエクスペリエンスに深刻な影響を直接及ぼす可能性があります。ほとんどのインシデントでは、根本原因を特定するために、アプリケーションチームとデータベースチームの密接な連携が欠かせません。しかし、ツールがばらばらで、データがサイロ化し、各チームの縄張り意識が強いと、解決が遅れ、コストのかかるビジネスダウンタイムの発生につながりがちです。
Splunkは、Splunk Observability CloudへのDatabase Monitoringの追加を発表しました。OpenTelemetryをベースとするSplunk Database Monitoringは、時間のかかる非効率なクエリーの検出と対処、アプリケーションの問題と特定のクエリーとの相関付けによる根本原因分析の迅速化、AIからの提案を活用した修復作業の効率化に役立ちます。
この初回リリースでサポートされるのはMicrosoft SQL ServerとOracle Databaseのみですが、今後、他のエンジンのサポートも追加される予定です。
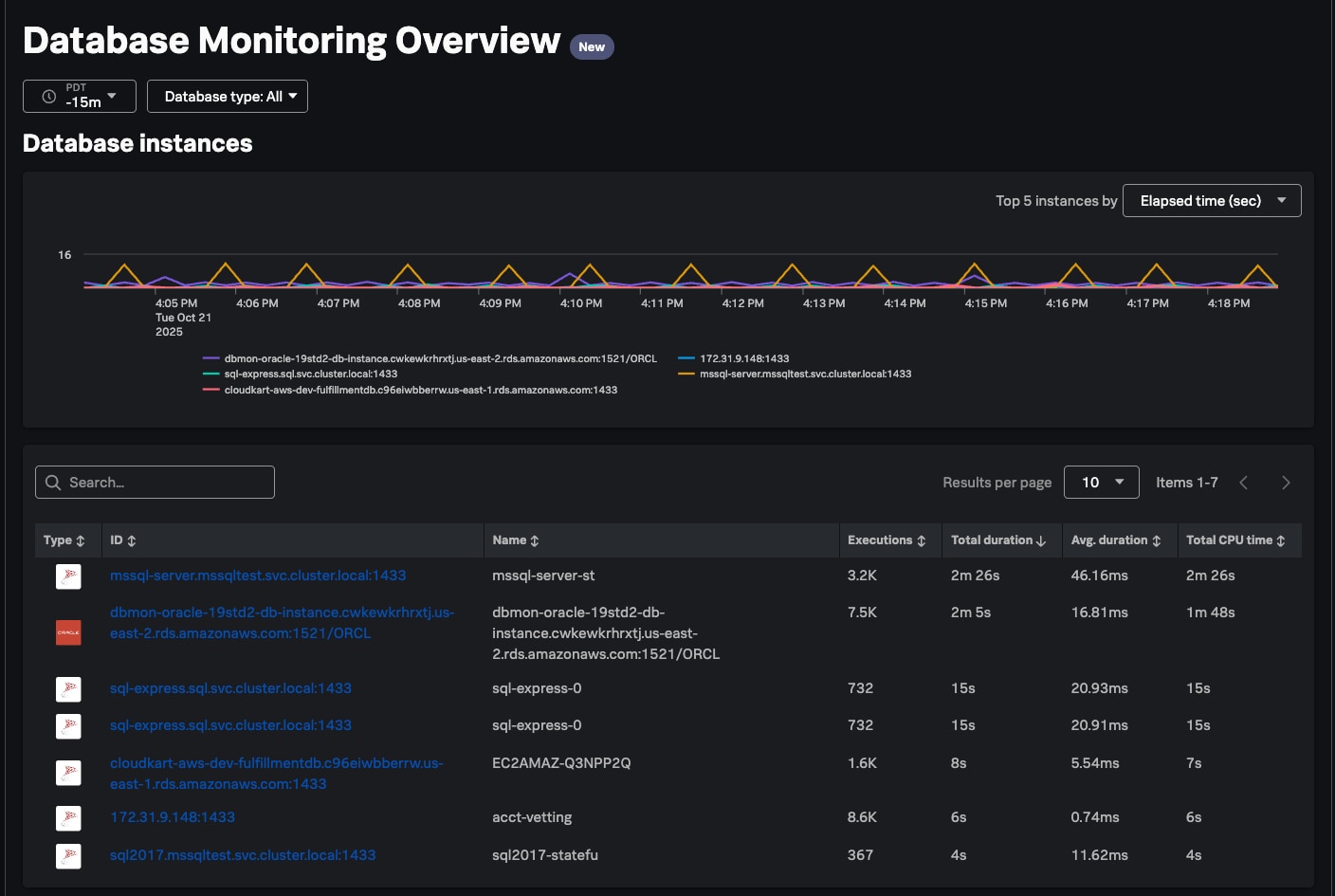
今日の組織は、ハイブリッドかつマルチクラウドの環境で、SQL Server、Oracle、RDBMS、NoSQL、グラフデータベースなど、複数のデータベースエンジンを運用しています。エンジンごとに、出力されるメトリクス、実行計画のフォーマット、ダッシュボードが異なるため、「クエリーとサーバーのどちらに問題があるか?」や「どのサービスが問題の影響を受けるか?」といった基本的な疑問を解消するだけでも、複数のツールを頻繁に切り替えなければなりません。その結果、トリアージに時間がかかり、チーム間で責任のなすりつけ合いが発生し、MTTRが長引くことになります。
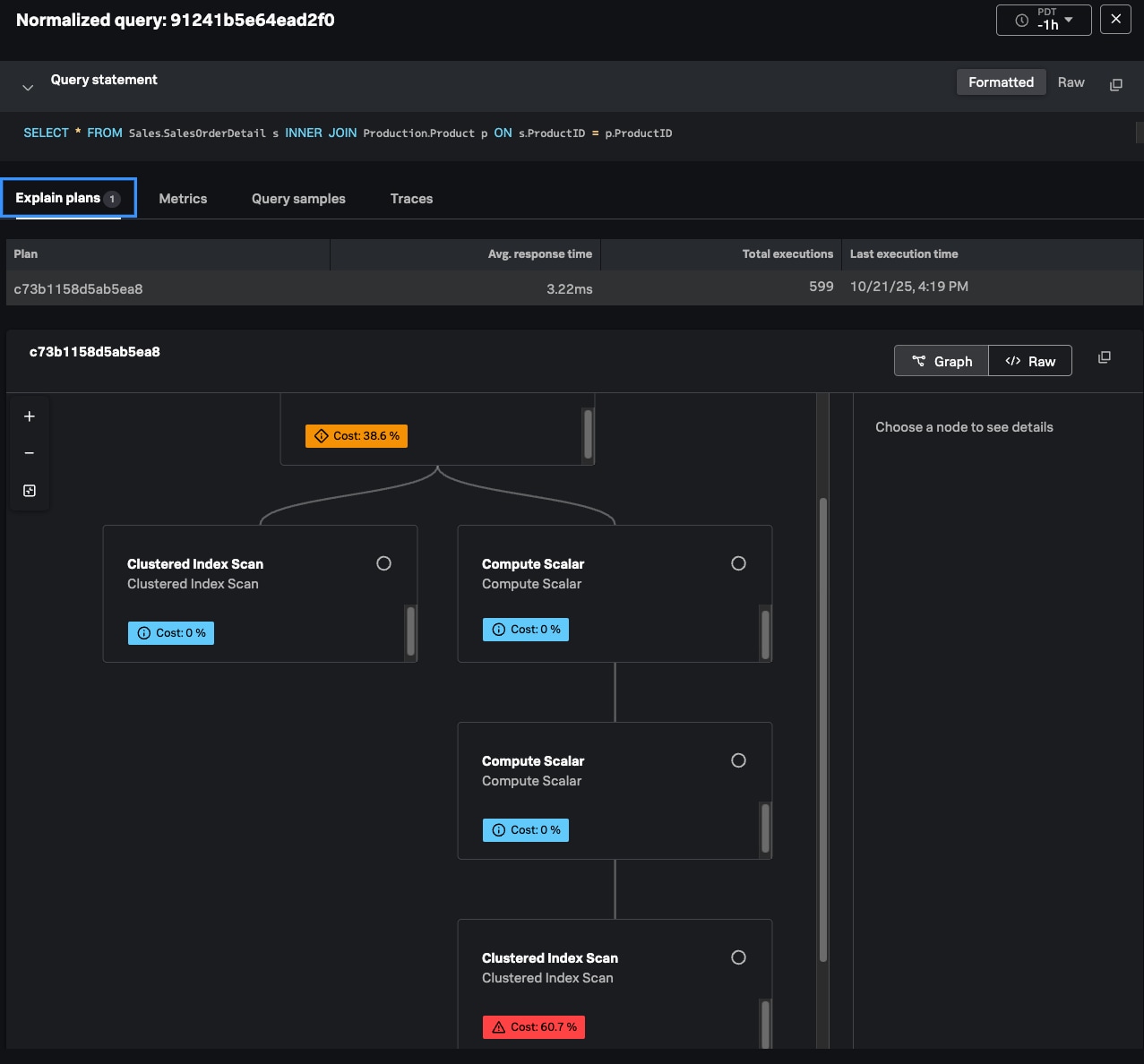
Splunk Database Monitoringは、すべてのデータベースエンジンと環境をまたいで情報を統合的に表示することで、こうした分断を解消します。インスタンスをすばやく比較して、ホットスポットを特定し、修正の優先順位を判断して、大規模に対策を実行できます。任意のデータベースインスタンスについて、すべてのクエリーと、それぞれの待ち状態、待ち時間、実行時間、実行回数、CPU時間などの豊富なメトリクスを確認できます。詳細な実行計画では、データベースエンジンが各クエリーをどのように実行したかがわかるため、パフォーマンスのボトルネックや非効率なプロセスをピンポイントで特定できます。
例:
ビジネスクリティカルなアプリケーションを担当するSREのもとに、あるデータベースインスタンスのCPU使用率が高いことを示すアラートが届いたとします。まずは、クエリーのリスト表示で、クエリーをCPU時間順に並べ替えて、問題のあるクエリーを特定します。そのクエリーをクリックして詳細を表示すると、実行計画から、最もコストが高いクエリーはIndex Scan演算子のものだとわかりました。そのクエリーはインデックスを使用しているものの、シークではなくインデックス全体のスキャンを実行しています。これは、結果セットが大きいか、述語が不適切であることを示唆しています。これらのインサイトに基づいてクエリーを見直し、最適化すれば、パフォーマンスを向上させることができます。
Database Monitoringでは、任意のデータベースインスタンスについて、クエリーのパフォーマンスと効率を把握できます。
アプリケーションのインシデントにデータベースが関係する場合、SREチーム、アプリケーションチーム、DBAチームの間に壁があると、あらゆる作業に時間がかかります。APMがあれば、処理に時間がかかっているエンドポイントやデータベーススパンはわかるかもしれませんが、クエリーレベルで可視化できないと、データベースがブラックボックスのままになりがちです。一方、データベースチームは、処理の遅いクエリーやリソース使用率の急増は認識できますが、その原因になっているアプリケーションやビジネスワークフローは把握できません。その結果、チーム間で責任を押し付け合い、解決が遅れ、アラートが何度も繰り返されることになります。
Splunk Database Monitoringは、チーム間の溝を埋めます。クエリーの詳細分析とAPMデータを相関付けて、データベースの動作がサービスやビジネスワークフローに与える影響を正確に把握できます。SREチームやアプリケーションチームは、処理時間の長いAPMトレースから問題のあるクエリーに直接移動できます。また、データベースチームは、リソースを大量に消費しているクエリーから関連するAPMトレースに移動して、負荷をかけているアプリケーションやサービスを特定できます。
例:
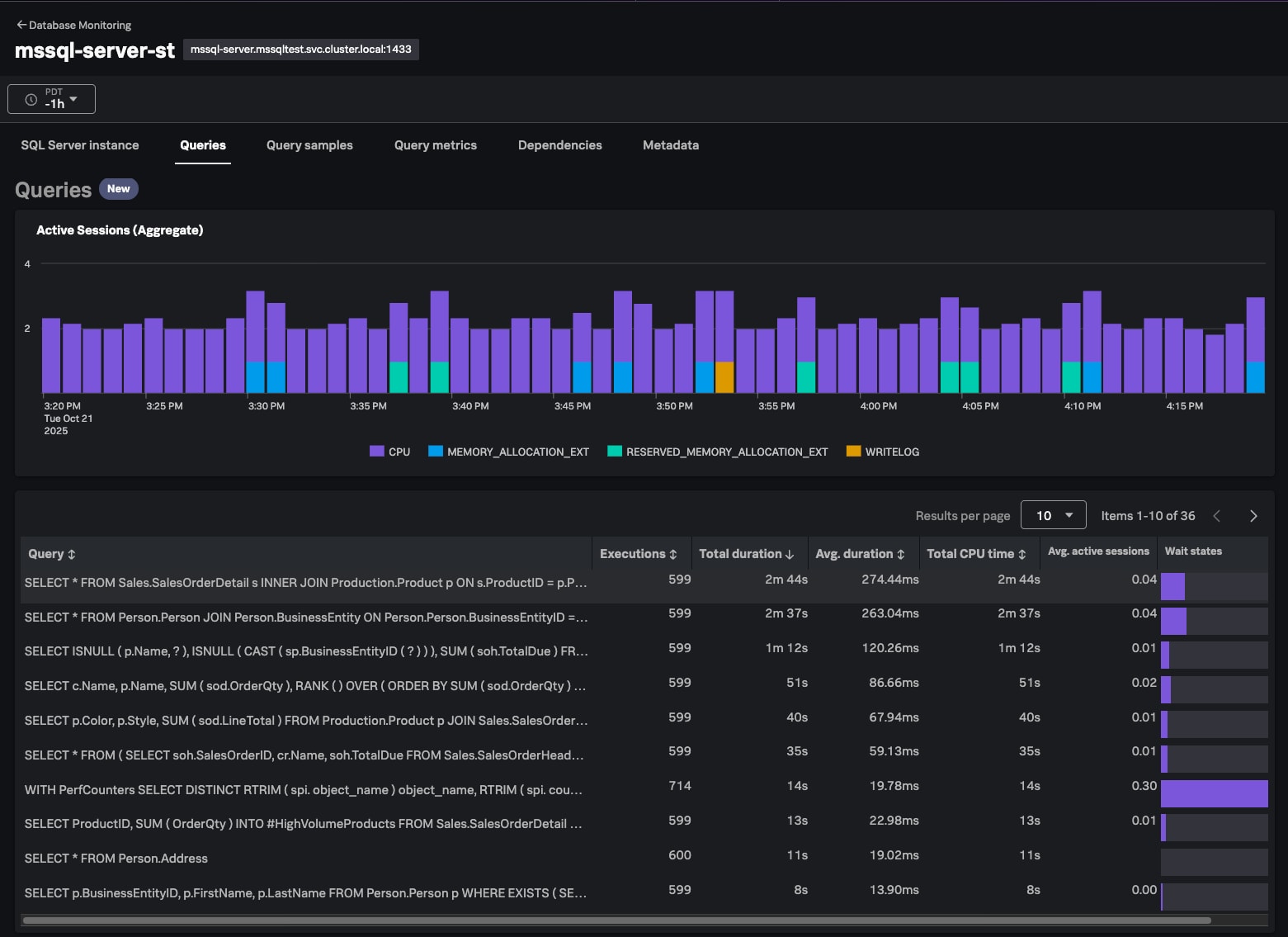
アプリケーションのパフォーマンスが突然低下したとします。Splunk APMで、その原因となっている処理時間の長いデータベーススパンを特定しました。ここでツールを切り替える必要はありません。そのスパンをクリックすれば、APMのページ内でクエリーの詳細に直接移動できます。メトリクスを見ると、「PAGELATCH_*」の待ち時間が異常に長いことがわかりました。これは、クエリーでディスクからデータを取得するのに時間がかかりすぎていることを示します。最新の実行計画をドリルダウンして詳しく調べると、テーブルのフルスキャンが発生しており、I/Oに高い負荷がかかっているようです。このインサイトに基づいて、インデックスを追加し、パフォーマンスを改善して、インシデントをクローズしました。これらの作業もすべて、Splunk Observability Cloud内で完結します。
Database Monitoringでは、詳細な実行計画が表示されるため、パフォーマンスのボトルネックをピンポイントで特定できます。
時間のかかる非効率なクエリーを特定しても、その修正には手間がかかりがちで、リスクを伴うこともあります。開発者は、クエリーの目的、パラメーター、実行計画の詳細を理解するために、複数のツールを行き来しながら、従来のSQLまたはORMで生成されたSQLを何時間もかけて解読することになります。インシデント発生という重圧の下で、クリーンで最適化されたクエリーに書き直すのは時間がかかる作業であり、後で問題が再発することも珍しくありません。
Splunk Database Monitoringでは、AIによる要約と提案を活用して、このプロセスを効率化できます。AIによる要約では、長くて複雑なクエリーがわかりやすく説明され、主要な入力や、非効率の原因と考えられる箇所が強調されます。AIによる提案では、インデックスの変更、クエリーの書き換え、SQLのヒントなど、最適化のための解決策が示され、さらに、すぐに実行できるコードも提案されるため、修復作業を迅速化できます。
例:
あるクエリーで、non-SARGableな(インデックスを利用できない)述語が原因で処理に時間がかかっていることがわかりました。具体的には、WHERE句で使われている次の関数です。
WHERE SUBSTRING(name, 1, 2) = 'HA'
この関数では、インデックスの使用が妨げられます。そのため、データベースエンジンは、すべての行を取得し、関数を適用してから、結果をフィルタリングする必要があり、結果として応答時間が長くなります。SplunkのAI機能を使えば、このクエリーをSARGableな形式に自動的に書き換えることができます。
WHERE name LIKE 'HA%'
最適化後の関数では、インデックスが効率的に使われます。このように、最小限の手間でパフォーマンスを改善できます。
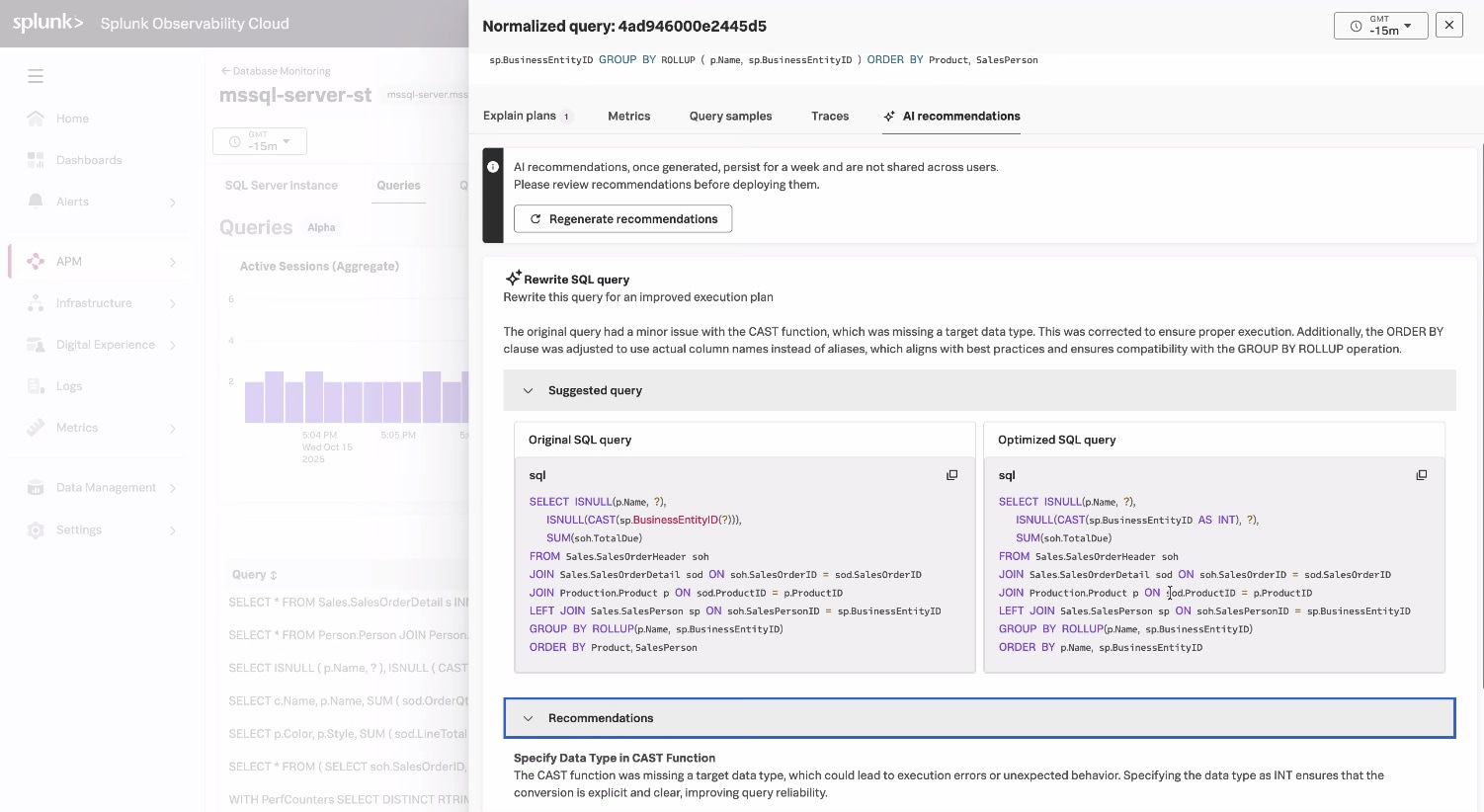
Database Monitoringでは、AIからの提案を活用して開発者の時間を節約できます。
Splunk Database Monitoringは、データベース環境全体を包括的に可視化し、根本原因分析を迅速化し、AIによって最適化を支援します。これにより、SREチーム、アプリケーションチーム、データベースチームは、円滑に連携してパフォーマンスの問題を解決し、MTTRを短縮できます。
詳しくは、Splunkのドキュメントをご覧いただくか、デモをお申し込みください。

© 2005 - 2026 Splunk LLC 無断複写・転載を禁じます。
© 2005 - 2026 Splunk LLC 無断複写・転載を禁じます。
