
AIでセキュリティ分析をレベルアップ
AIが脅威の調査と対応の効果向上にどのように役立つかについてご紹介します。
最近、Splunkは、Huggingfaceからダウンロード可能な、時系列分析のためのオープンソース基盤モデル「Cisco Time Series Model」をリリースしました。Cisco Time Series Modelは、企業が機械データを理解し、予測し、活用する方法を大きく変革することが期待されています。このモデルは、オブザーバビリティやセキュリティデータの複雑なニーズに特化して設計されており、時系列分析に新たな精度、適応性、使いやすさをもたらします。本ブログ記事では、Splunk App for Data Science and Deep Learning (DSDL) を活用し、Splunk上のデータとシームレスに統合されるこのモデルの利用方法についてご紹介します。
時系列モデリングにおける主要な課題の一つは、長期的な過去のパターンを理解する必要性と、タイムリーで詳細なイベントを検出する能力とのバランスを取ることです。Cisco Time Series Modelは、革新的なマルチレゾリューションアプローチでこの課題に対応しています。このモデルは、異なる粒度でデータを処理します。低解像度では広範な過去のトレンドを捉え、高解像度では詳細かつリアルタイムのインサイトを提供します。この機能により、ユーザーは異なる時間スケールで発生する重要な異常やパターンを見逃すことなく、より正確な予測や異常検知が可能になります。
通常、Cisco Time Series Modelは1分間隔で記録された入力時系列データを処理します。たとえば、1か月分の履歴データをこの粒度で集めると43,200のデータポイントとなり、多くの時系列モデルの典型的なコンテキストウィンドウを超えるボリュームになります。この課題に対して、モデルは直近512個のデータポイントを1分間隔のまま保持し、それより過去の履歴データは1時間単位に集約することで、重要な情報を損なうことなく入力長を大幅に削減します。さらに、実験では5分間隔の入力データにも柔軟に対応できることが示されています。このマルチレゾリューションアプローチによって、モデルは長期間にわたる予測も実現します。たとえば、標準的な128ステップの予測ウィンドウを用いると、豊富な過去データを活用しながら最大10時間先まで信頼性の高い予測が可能となります。
Splunk App for Data Science and Deep Learning(DSDL)は、Splunkのサーチヘッドとお客様管理のコンテナ環境をつなぐ橋渡しの役割を果たし、高度なディープラーニングモデルのトレーニングや推論、大規模言語モデル(LLM)との統合を実現します。このアーキテクチャにより、DSDLはTSFMモデルをSplunkの検索環境内でシームレスに展開・活用するための理想的なプラットフォームとなっています。
最新ビルドでは、Cisco Time Series Modelが完全に統合されており、Splunk環境内のあらゆる時系列データに対して、その高性能な予測機能を活用できるようになりました。最新のDSDLをインストールした後は、DSDL内のコンテナ管理ページから Golden Transformers GPU(5.2.2)コンテナを簡単に起動でき、高度な時系列分析をすぐにご利用いただけます。
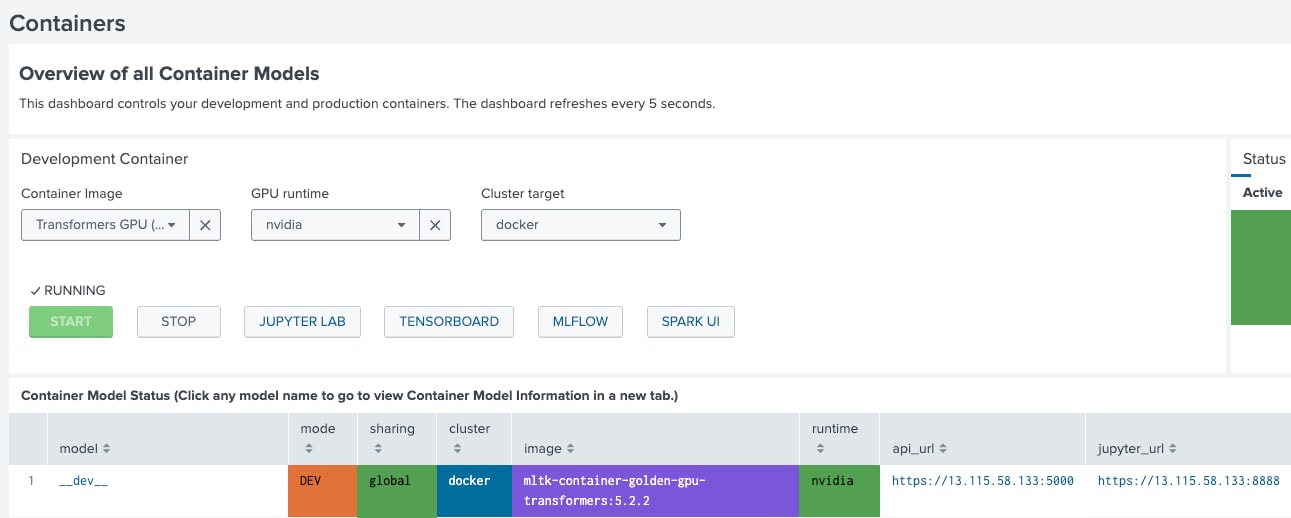
このコンテナイメージには、予測用の新しいノートブックが追加されています。JupyterLabのリンクをクリックし、notebooks/tsfm_forecast.ipynbに移動することで、このノートブックを閲覧できます。
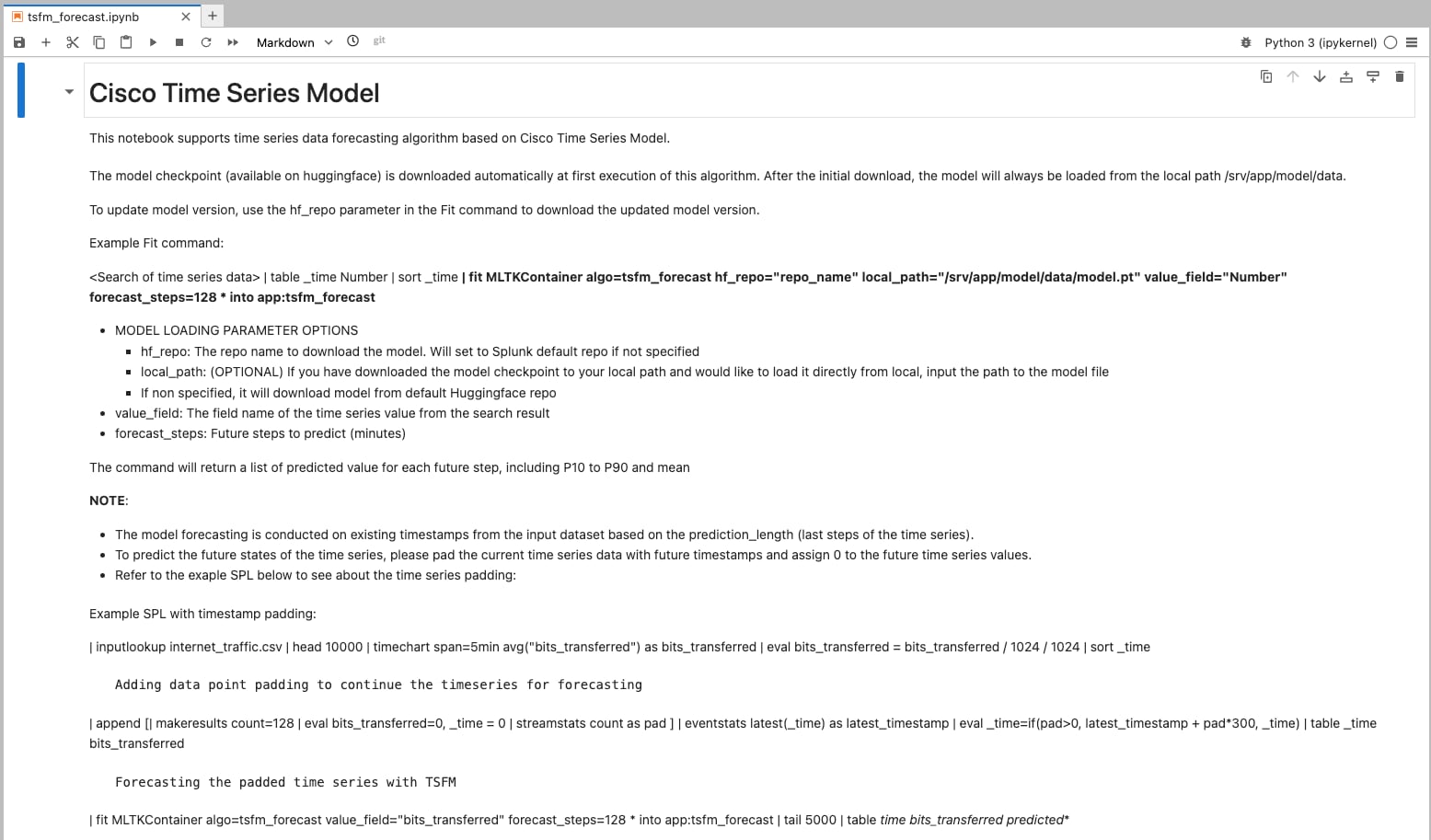
この新しいノートブックにより、Splunkユーザーは検索バーからFitコマンドを使って直接予測を実行できるようになります。ノートブック内には詳細な説明が記載されており、Fitコマンドの効果的な活用方法や、さまざまなパラメータを適用してユースケースに合わせる手順が分かりやすく案内されています。
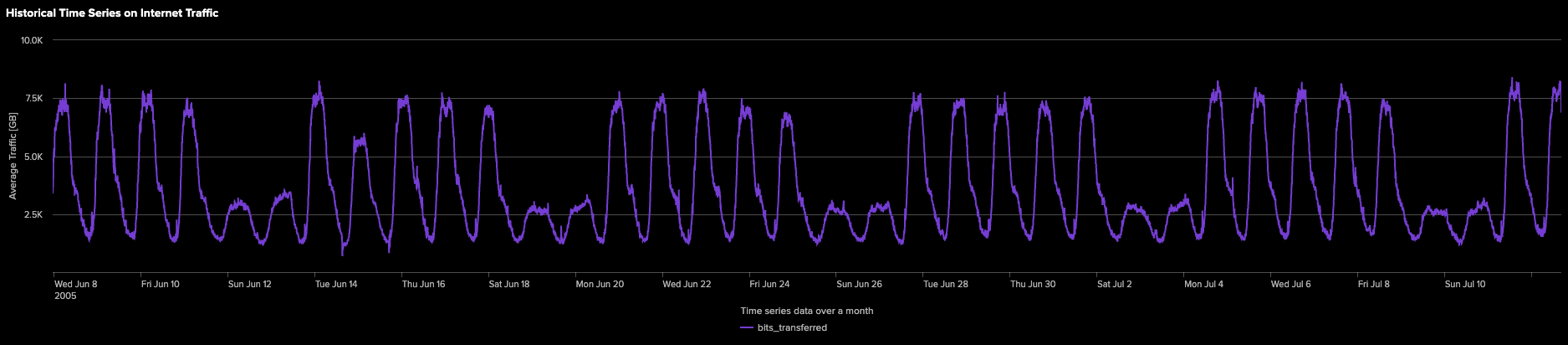
DSDLを通じて予測機能を効果的に紹介するために、Splunk AI Toolkitに含まれているinternet_traffic.csvデータセットを利用します。以下のSplunk検索クエリは、1か月間のインターネットトラフィック(GB)の平均値を5分間隔で集計します。
| inputlookup internet_traffic.csv
| head 10000
| timechart span=5min avg("bits_transferred") as bits_transferred
| eval bits_transferred = bits_transferred / 8 / 1024 / 1024
集計されたインターネットトラフィックデータは時系列として表現されており、以下の折れ線グラフに示されています。
モデルの精度を評価するために、以下のSPLコマンドを使用します。このコマンドは、これまでの履歴データすべてを活用し、時系列の最後の128ステップを予測するように設計されています。続いて、この128ステップ期間における予測値を実際の値と直接比較することで、モデルのパフォーマンスを明確に測定します。
| inputlookup internet_traffic.csv
| head 10000
| timechart span=5min avg("bits_transferred") as bits_transferred
| eval bits_transferred = bits_transferred / 8 / 1024 / 1024
| fit MLTKContainer algo=tsfm_forecast value_field="bits_transferred" forecast_steps=128 * into app:tsfm_forecast
| tail 800
| table _time bits_transferred predicted_p50
評価の中心となるのはSPLコマンドであり、ここでFitコマンドがtsfm_forecastアルゴリズムを呼び出します。このコマンド内では、予測対象のフィールドとしてbits_transferredを明示的に指定し、forecast_stepsを128に設定しています。
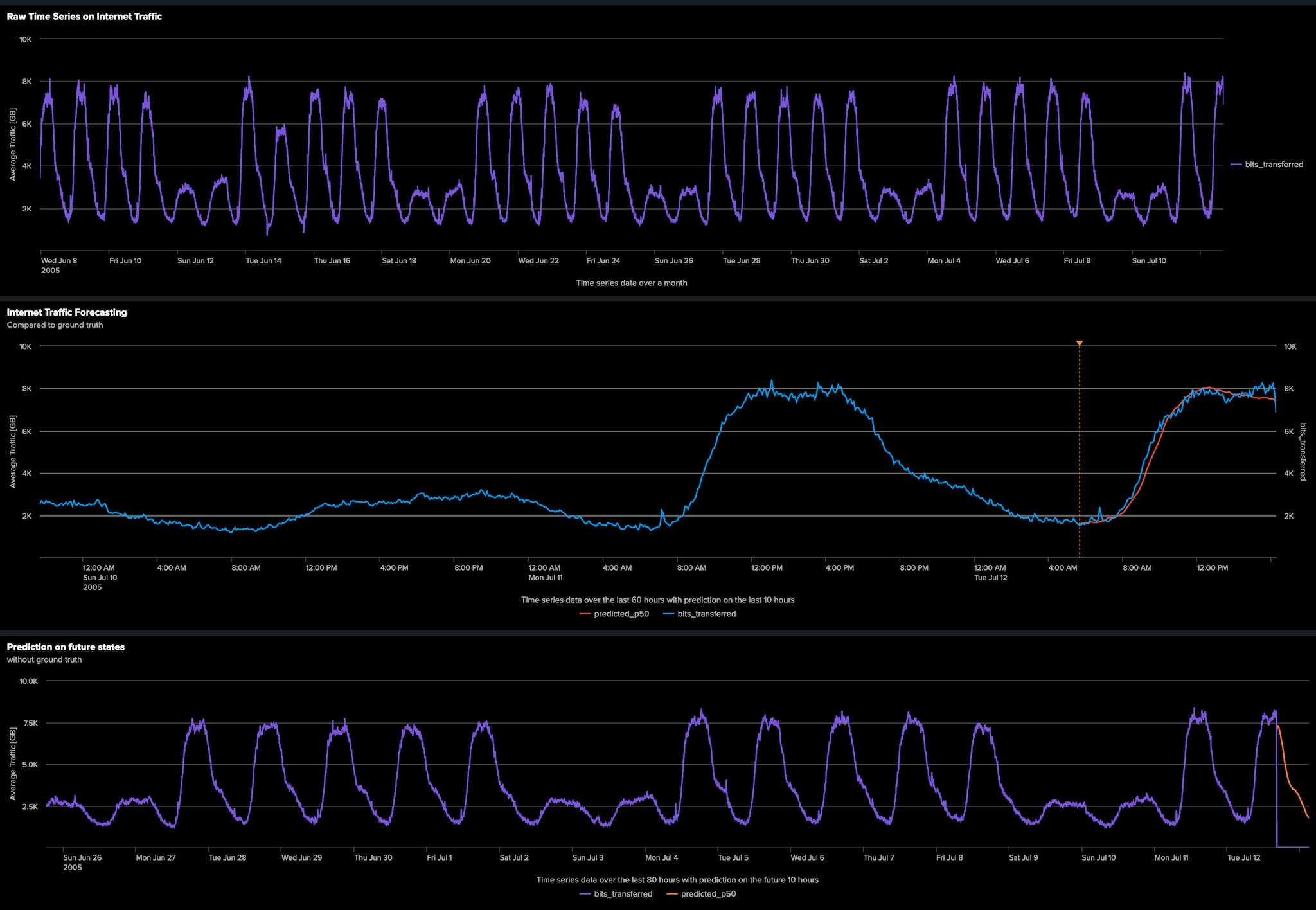
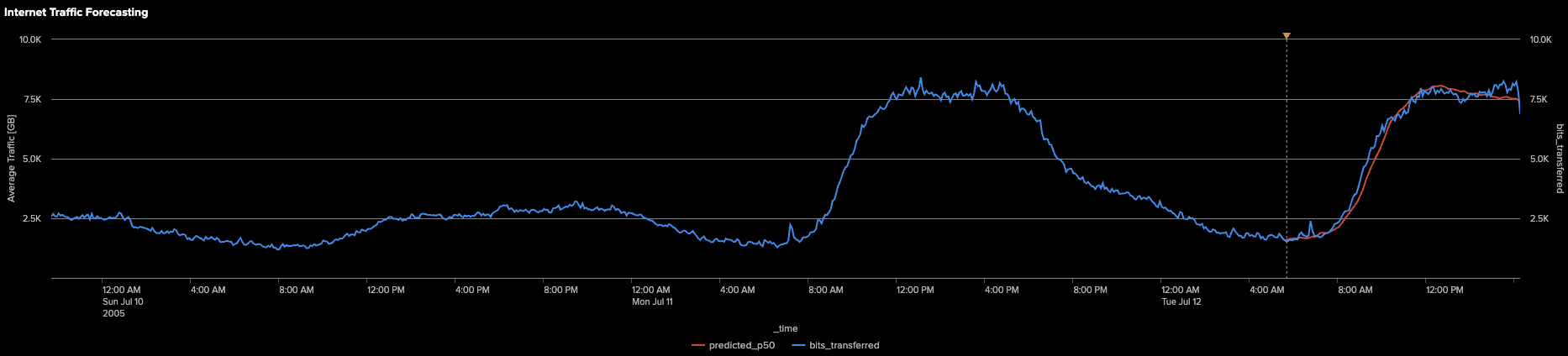
このコマンドの実行後、時系列データの最後の800ステップに注目して可視化を行います。下のグラフでは、実際の値(bits_transferred)と、モデルが生成した平均予測値(predicted_p50)が視覚的に比較されています。
下のグラフは、予測エリアを拡大して表示しています。
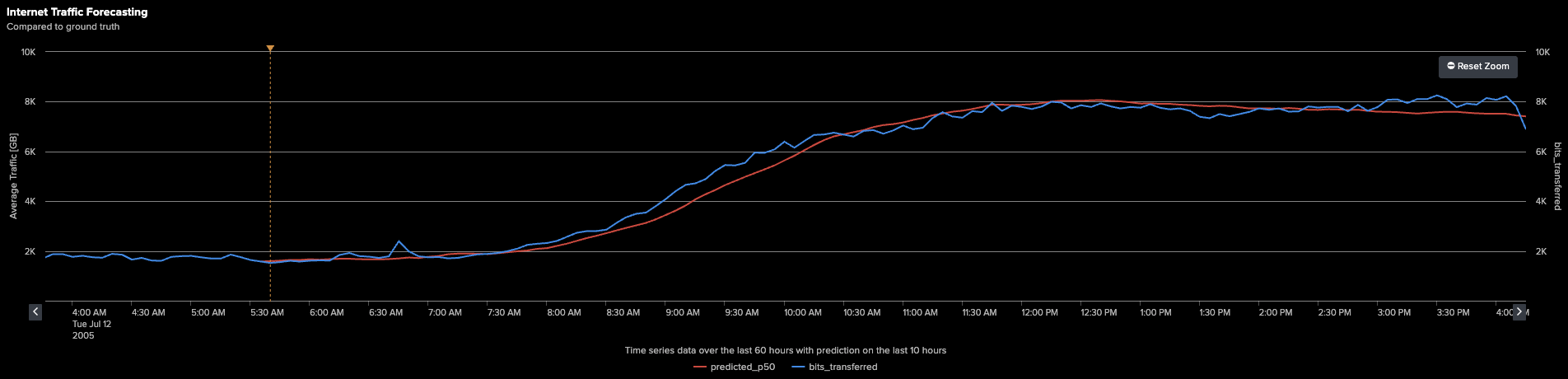
グラフが示すように、モデル(オレンジ色の線)は、時系列データの過去の履歴を活用して、最後の128ステップを効果的に予測しました。モデルは、実際値(青色の線)の全体的なトレンドや大きなピークをしっかりと捉えており、堅牢な予測性能を示しています。
ただし、特に将来のステップを予測する場合、予測モデルは本質的により滑らかなカーブを生成する傾向があることに注意が必要です。これは、モデルが生データに含まれる細かな変動や「ノイズ」をすべて再現しようとするのではなく、基礎となるパターンや全体の方向性を把握して投影するためです。この平滑化は予測において一般的かつ望ましい特性であり、個々の瞬間的なデータポイントを完全に再現しなくても、全体の流れを理解し、戦略的な意思決定を支援するのに役立ちます。
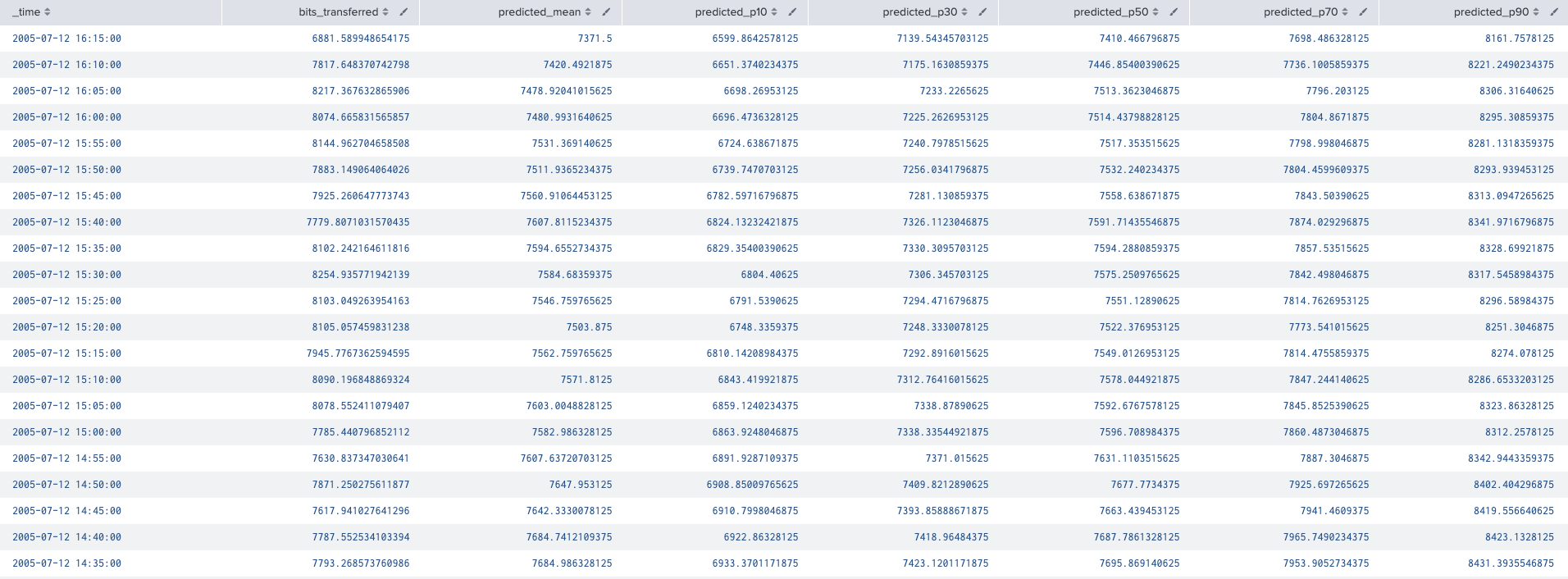
また、平均予測値だけでなく、Fitコマンドは包括的な信頼区間も提供します。P10、P30、P70、P90といった予測値が出力されるため、予測の不確実性をより明確に把握でき、より適切な意思決定が可能となります。これらの詳細な予測を示すFitコマンドの生データ出力は、以下に示されています。
モデルの性能を十分に検証した上で、次は将来の予測にモデルを適用してみましょう。時系列データの今後のタイムスタンプに対する予測を生成するためには、既存のSPLコマンドを少し修正する必要があります。以下のSPLコマンドは、その実践例を示しています。
| inputlookup internet_traffic.csv | head 10000 | timechart span=5min avg("bits_transferred") as bits_transferred | eval bits_transferred = bits_transferred / 8 / 1024 / 1024 | sort _time
```
Adding data point padding to continue the timeseries for forecasting
```
| append [| makeresults count=128 | eval bits_transferred=0, _time = 0 | streamstats count as pad ]
| eventstats latest(_time) as latest_timestamp
| eval _time=if(pad>0, latest_timestamp + pad*300, _time)
| table _time bits_transferred
```
Forecasting the padded time series
```
| fit MLTKContainer algo=tsfm_forecast value_field="bits_transferred" forecast_steps=128 * into app:tsfm_forecast
| tail 5000
| table _time bits_transferred predicted_p50
このSPLコマンドの最初の部分は、これまでの例とほぼ同じです。しかし、将来予測を有効にするためには、時系列データを拡張する重要なステップが含まれています。元のデータには将来のタイムスタンプが含まれていないため、appendコマンドを使用して128行の新しい行をテーブルに追加し、それぞれに前回記録されたタイムスタンプから300秒(5分)ずつ増加させたタイムスタンプを割り当てることで、将来予測のためのプレースホルダーを作成しています。
続いて、Fitコマンドを再実行します。今回は、全履歴時系列データを活用して、新たに追加された128個の未来のタイムスタンプに対する値を予測します。モデルが長期間にわたって捉えたトレンドを包括的に把握できるよう、下のグラフでは直近5000ステップを可視化しています。
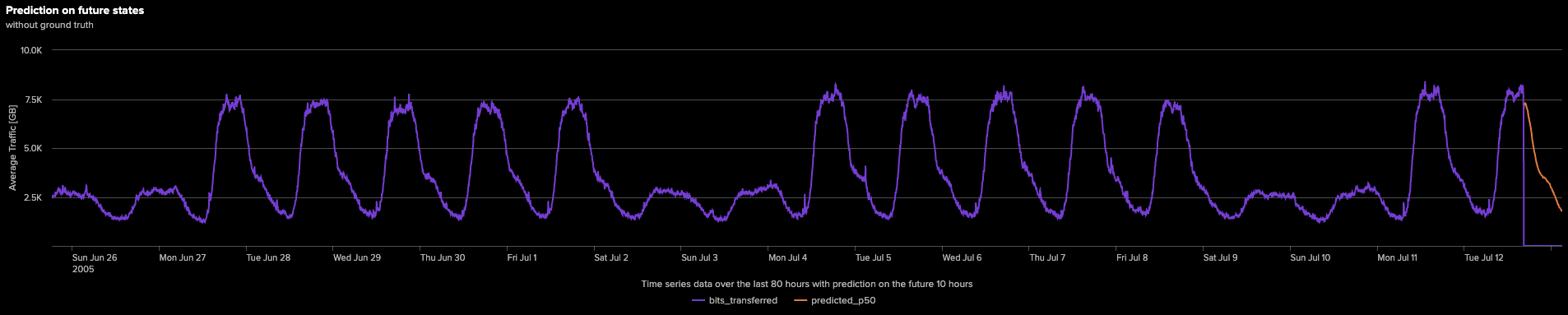
下のグラフは、予測エリアを拡大して表示しています。
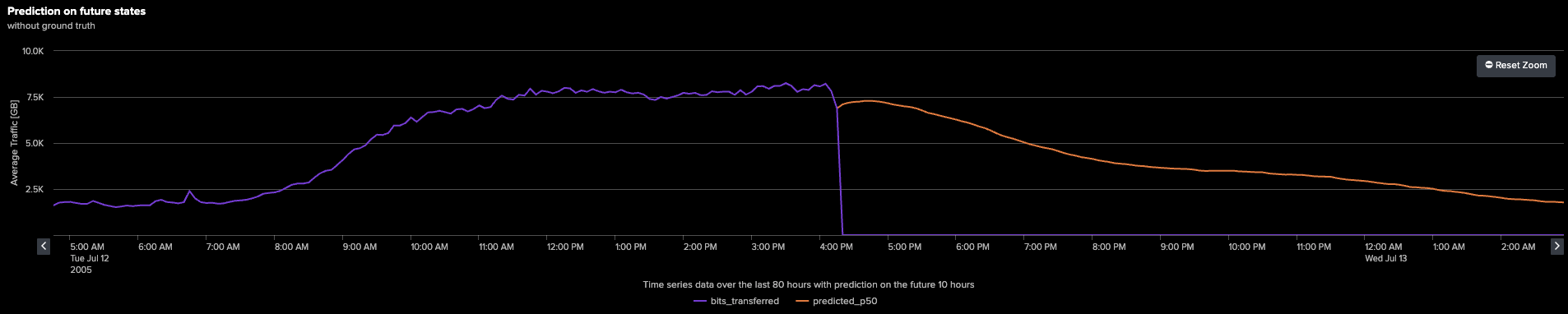
グラフに示されているように、時系列の末尾に伸びているオレンジ色の線は、モデルによる将来予測の結果を表しています。モデルはこれまでのトレンドを巧みに捉え、それを先へと投影することで、今後10時間分の明確な予測を提示します。こうした予測は、IT監視の強化やリソース計画の最適化、さらにはセキュリティの予兆検知など、さまざまな分野で大きな価値をもたらします。
Cisco Time Series Modelは、ゼロショット予測機能とSplunk DSDLを通じたシームレスな統合により、IT運用やオブザーバビリティ領域で大きな価値を発揮します。これには、将来のリソース使用量を予測してプロアクティブなキャパシティプランニングを強化することや、パフォーマンストレンドの予測によるSLA管理の改善、システムの通常動作を予測することでセキュリティ分析を強化することなどが含まれます。モデルはメトリクスの長期的なコンテキストや根本的なトレンドを的確に捉え、なめらかで解釈しやすい予測を提供します。このアプローチは、戦略的な計画や全体的な動向の把握に非常に有用ですが、モデルは本質的に予測を平滑化する傾向があり、生データに含まれる瞬間的な「ノイズ」や短期的な変動をすべて再現することを目的としていません。そのため、チームは重要な変化や持続的なパターンに集中することができます。
このモデルの活用例については、Githubのクックブックもぜひご覧ください。
Huaibo & Philipp

© 2005 - 2026 Splunk LLC 無断複写・転載を禁じます。
© 2005 - 2026 Splunk LLC 無断複写・転載を禁じます。
