
AIでセキュリティ分析をレベルアップ
AIが脅威の調査と対応の効果向上にどのように役立つかについてご紹介します。

Observability CloudのAI Assistant (2024年6月執筆時点ではプライベートプレビュー版1を提供、現在は一般提供)は、オブザーバビリティ(可観測性)のデータソースとワークフローを自然言語で操作するためのインターフェイスを提供します。SignalFlowは、Splunk Observability Cloudの中核をなす分析エンジンであり、リアルタイムのデータ処理とメトリクスの分析を目的として設計されています。また、プログラミング言語やライブラリなどのコンポーネントも備わっています。これにより、大量の受信データストリームに適用できる分析処理をコーディングし、メトリクス、チャート、ディテクターの形でインサイトを提示することが可能になります。関連するブログ記事では、AI Assistantの設計思想とアーキテクチャの概要、特にエージェントを用いた設計パターンをオブザーバビリティの分野にどのように適用したかについて詳しく説明しています。このブログでは、大規模言語モデル(LLM)を使用してSignalFlowプログラムを生成する際の課題と方法について重点的に取り上げます。
SignalFlowはPythonの文法をモデルとしており、データの取得、出力、そしてアラートを生成するための組み込み関数を備えています。まず、簡単なSignalFlowプログラムの例を見てみましょう。
data('cpu.utilization',
filter=filter('host','example-host')).mean(over='5m').publish()
このプログラムはまず、「cpu.utilization」メトリクスのフィルタリングされたデータポイントのセットを取得し、「host」ディメンションが「example-host」と一致するデータポイントのみが処理対象となるようにします。次に、ストリーム内のデータポイントの平均を計算し、5分間のローリングウィンドウの平均を算出します。最後に、publishブロックによって分析システムに結果を出力するよう指示しています。なお、Function Callingとメソッドチェーンは、Pythonでの動作と同様です。
生成AIにおける課題の中でも、特に困難なのがコード生成です。なぜなら、たった1文字の誤りでも構文エラーを引き起こす可能性があるからです。SignalFlowのようなニッチな言語のコード生成は、さらに大きな挑戦を強いられます。その理由として、SignalFlowに関する知識を持つモデル(オープンソースかクローズドソースかを問わず)が非常に少ない、あるいはSignalFlowの知識を持っていたとしても、Pythonに関する情報が混入することで、その知識が劣化してしまう場合があることが挙げられます。したがって、コードを生成するためにファインチューニングされたモデルであっても、品質の高いSignalFlowのコードを生成するには、さらなるカスタマイズが必要となります。
特定のタスクに合わせてLLMの生成を調整する手段として、追加の例を使用してモデルの性能を強化する方法があります。これは通常、入力と出力(質問と回答、文章とその翻訳など)のペアの形式になります。プロンプトには、入力と出力との一般的な関係性を記述し、可能であれば例もいくつか含めます。この際に使用できる検索拡張生成(RAG)という洗練された手法があり、これによって、入力内容に応じた適切な例をプロンプトに含めることができます。一般的な実装では、ユーザーのプロンプトを基にデータソースに対してセマンティック検索を通じて類似度を評価し、取得した中から関連性の高い例をいくつか選んでプロンプトに含めます。このアプローチは、コンテキストと関連性の高い情報を提供することによってモデルの応答を強化します。これに加え、ファインチューニングを行うことでモデルをさらに強化します。ファインチューニングは、追加の例でモデルをトレーニングし、内部の重みを調整して目的のタスクへの習熟度を高めます。RAGは入力トークン数の増加により計算コストが高くなる可能性があります(例がプロンプトに追加されるため)。一方、ファインチューニングは初期段階で多大な労力を要するものの、タスク固有の知識をモデル自体に組み込むことで長期的なメリットが得られます。RAGとファインチューニング、いずれの場合も大規模かつ多様で高品質な例のセットが必要となります。
ユーザーの環境に関する質問(例:「“example-host”の過去5分間の平均CPU使用率は?」)を解釈するために、まずすべきことは英語の質問とそれに関連するSignalFlowプログラムの両者を組み合わせたデータセットを厳選することでした。これは、次の図に示す多段階のプロセスによって実現しました。つまり、データの収集と前処理、SignalFlowプログラムの分解、タスクの指示と質問の生成、品質のスコアリング、そして最終的な質問と回答のペアの作成です。
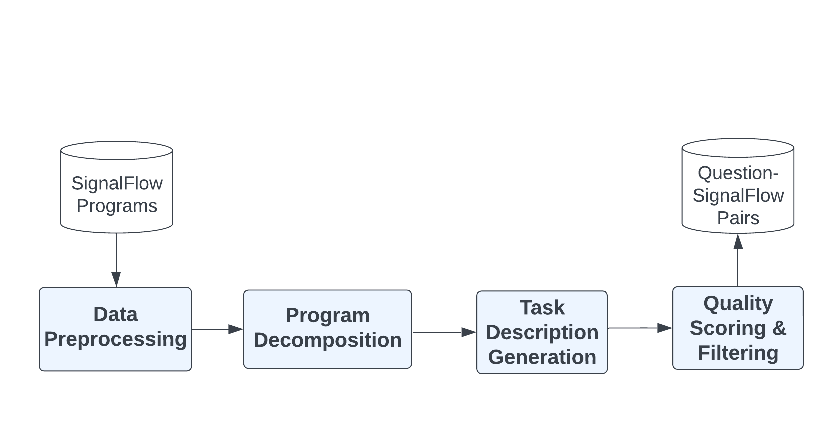
図1:データのキュレーションの手順
この手順により、各例が、カジュアルな質問、詳細なタスク指示、SignalFlowプログラムで構成される、数万例からなる厳選されたデータセットが作成されました。
自然言語からSignalFlowモデルを作り上げるには、上記で作成したデータセットを中心に構築していく必要があります。この基本構成要素となるのは、SignalFlow生成を担当するエージェント(サブLLM)のプロンプトを渡す機能、ユーザー固有のメトリクスとメタデータを取得するためのメカニズム、プログラム検証機能(検証失敗時のエラーメッセージ表示を含む)です。現在の実装では、データセットはRAGを介してエージェントのワークフローに取り込まれます。
ユーザーからの質問を受け取ると、オーケストレーターLLMは、回答を提供するためにメトリクス検索が必要かどうかを判断します(ユーザーがメトリクス名を指定していない場合がこれに該当します)。適切なツールを呼び出してメトリクス名とそのメタデータを取得しますが、その際には、ユーザーの質問から検索語句を抽出する必要があります。それから、最初のユーザーの質問、メトリクス名、メトリクスメタデータをSignalFlow生成サブLLMに渡します。ワークフローを以下に示します。
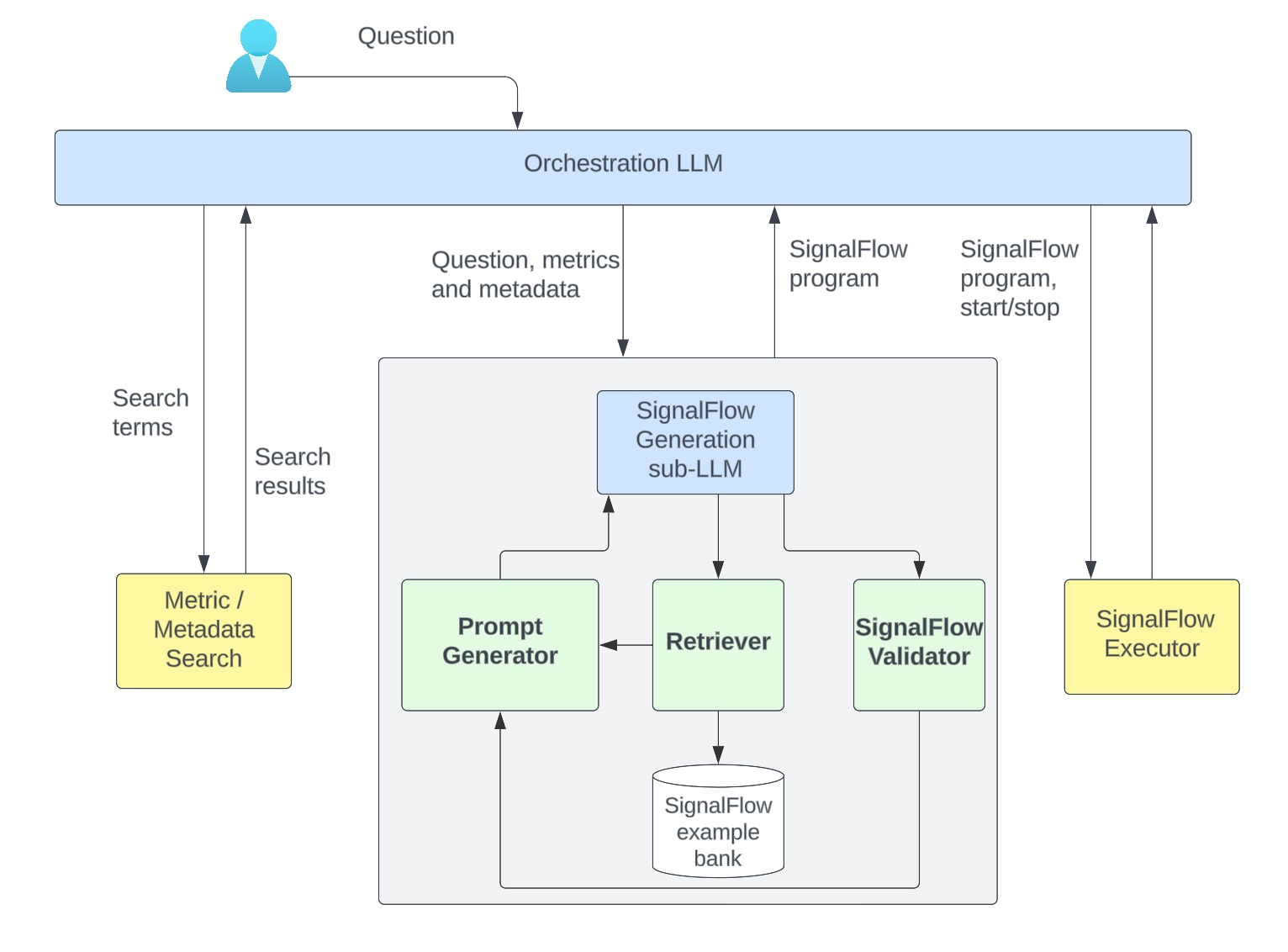
図2:SignalFlow生成プロセスの全体的なフレームワーク
SignalFlow生成サブLLMは、質問を受けてからSignalFlowプログラムを生成するまでの全工程の調整を担います。その特徴は、自然言語による質問とメタデータコンテキストを受け取り、質問に答えられる完全なSignalFlowプログラムを生成する点にあります(提供されたメタデータコンテキストは、必要に応じてプログラム内で使用されます)。システムプロンプトには、SignalFlowプログラムの重要なコンセプトと構成要素に関する説明と例が含まれています。主なコンポーネントは次のとおりです。
生成されたSignalFlowプログラムの正確性を評価することは容易ではありません。なぜなら、与えられた質問に対して複数の正解(プログラム)が存在する可能性があるためです。したがって、サブLLMのパフォーマンスの全体像を把握するには、いくつかの評価メトリクスを使用します。
SplunkのサブLLMベースアプローチによるモデルは、いずれの指標についても、主流のSignalFlow対応モデルの性能を大幅に上回っています。さらに、私たちのアプローチは、一貫して高い構文品質を持つSignalFlowプログラムを生成するという点においても優れた性能を示しています(1,000個のプログラムで99%以上の検証成功率)。これは構文検証のフィードバックループが功を奏していると言えます。この実証テストの結果は、Splunk社内の事例証拠とも一致しています。他のLLMベースのチャットボットが有効な支援とならない状況で、AI Assistantが中程度の複雑さを持つ正確なSignalFlowプログラムを生成できた事例が多数確認されています。
SignalFlowプログラムを作成可能な生成AIの構築には、さまざまな側面において技術的改善が求められました。高品質な質問とプログラムのペアの厳選、RAGと検証ツールにより生成されたコードの意味および構文の正確性の確保、半自動化された評価ツールの作成などです。SignalFlow生成サブLLMを通じて、Observability CloudのAI Assistantの機能向上を図るとともに、将来の機能強化の基盤も築くことができました。今後の展望としては、RAG技術の強化、評価パイプラインの改善、ユーザーフィードバックの統合を通じて、SignalFlow生成機能を強化する方法を探っていくことを予定しています。
オブザーバビリティテクノロジーの最前線に立つSplunkは、こうした進歩を支える強固なプラットフォームを提供し、監視と分析における継続的なイノベーションとユーザーエクスペリエンスの向上を約束します。これからも、お客様からのフィードバックと進化するテクノロジーを原動力に、AI Assistantの改良を続けていきます。
1 Observability CloudのAI Assistantは、Splunkに事前に承認を得た一部のプライベートプレビュー参加者にご利用いただけます(2024年6月執筆時点)。
2 LLMの「self-reflection(自己反省)」機能については、現在も研究と議論が続けられています。「Reflexion: Language Agents with Verbal Reinforcement Learning」や「Large Language Models Can Self-Improve」といった論文では、自己反省の考え方を支持する見解が示されています。当社では、LLMにスコアリングを行わせ、そのスコアの低いものを除外する方法を選択しました。これは、生成されたデータを高品質として手動でラベル付けするための後続の選定作業において、LLMに実行させた自己反省の結果が役立つことが実証されたためであり、前述の議論のいずれかの立場を支持しているわけではありません。自己反省の機能は、英語の質問とSignalFlowプログラムのペアからなるデータセットを生成するという特定のタスクにおいて、生成されたペアを除外するための便利な方法として使用されたものであり、その他のペアをデータセットに含めることを正当性する根拠としているわけではありません。
このブログ記事の共同執筆者をご紹介します。
協力者への謝辞:


© 2005 - 2026 Splunk LLC 無断複写・転載を禁じます。
© 2005 - 2026 Splunk LLC 無断複写・転載を禁じます。
