
Digitale Resilienz zahlt sich aus
Wie resilient ist eure Organisation? In diesem kostenlosen Leitfaden erfahrt ihr, wie ihr eure digitale Resilienz steigern könnt.
U m diese Frage zu beantworten, schauen wir bei Sebastian Walker, Senior Manager Informationssysteme Operations bei Mitsubishi Polyester Film GmbH vorbei, der in diesem Blog-Post von seinen Erfahrungen berichtet.
m diese Frage zu beantworten, schauen wir bei Sebastian Walker, Senior Manager Informationssysteme Operations bei Mitsubishi Polyester Film GmbH vorbei, der in diesem Blog-Post von seinen Erfahrungen berichtet.
Ein Homeoffice Nebeneffekt ist…: Man ist zuhause. Und wer ist meistens auch zuhause? Natürlich die Familie und insbesondere eine sehr neugierige, Splunk-begeisterte 6-jährige Tochter, Zoe (seltsamerweise interessiert sich der Hund nicht so sehr für Splunk).
Zoe malt sehr gerne bei Papa am Schreibtisch, während Papa sich mit den alltäglichen (Reporting-)...Problemen (ähm... ich meine natürlich „Herausforderungen") beschäftigt.
Zoe: Papa, was machen die Anlagen von Mitsubishi eigentlich den ganzen Tag? Nur produzieren oder auch was anderes?
Papa: Oh Zoe.. eine wirklich gute Frage. Was weißt du über OEE, QTE und ATE? Hast du schon mal KPIs ausgewertet?
Zoe: 😵💫
Papa: 😅 OK, wir machen ein buntes Bild (Kindersprache für fancy Chart), das dir das erklärt.
Zoe: Wie? Können wir Splunk benutzen? Das mag ich :-)
Papa: Klar, warum nicht!
*schließt DB Manager und überteuertes Tabellenkalkulationsprogramm*
Was macht man nicht alles, um die kindliche Neugier zu befriedigen… wir brauchen jetzt also einen Chart, das einen komplizierten Sachverhalt kindgerecht veranschaulicht… gute Übung für die Management Reports die nächste Woche fällig sind.
Selbermachen ist angesagt! Keine Erklärung nur Start und Ziel. Ihr füllt die Lücke und postet euren Weg in den Kommentaren:
Start:
Ein Event mit Start und Ende an unterschiedlichen (aufeinander folgenden) Tagen:
| makeresults count=1 | eval TS_START = “2021-06-09 22:03:17” | eval TS_END = “2021-06-10 01:01:00”
Ziel:
Der Event wird genau um Mitternacht in zwei einzelne Events geteilt.
TS_START TS_END 2021-06-10 00:00:00 2021-06-10 01:01:00 2021-06-09 22:03:17 2021-06-10 00:00:00
Euer Lösungsweg:
(Bitte in die Kommentare posten)
Bonus:
Was wenn der Event mehr als 24 Stunden lang ist (die Eventdauer enthält mehrfach Mitternacht)?
Was jetzt folgt ist die Zusammenfassung und das Ergebnis der Zusammenarbeit mit Patrick Hummel, dem Splunk Sales Engineer meines Vertrauens (sowie mehrerer Liter Kakao- bzw. Kaffeekonsum).
Bei der Mitsubishi Polyester Film GmbH werden die Zeiten von Produktionsanlagen lückenlos erfasst. Produktionsbedingt treffen die Start- und Endzeiten einer „Zeitscheibe" leider nicht auf reproduzierbare oder gleichmäßige Zeitpunkte (z. B. immer um 15 Minuten nach der vollen Stunde). Wie im echten Leben dauert es halt so lange, wie es eben dauert. Die Zeiten werden durch die Mitarbeiter in vorher festgelegten Kategorien einsortiert (z. B. Produktion, Rüstzeit oder Wartung). Dadurch erhält man ein lückenloses „Tagebuch”: Was wurde wann an der Anlage gemacht?
Ein kurzes, fiktives Beispiel wie solche Tagebucheinträge aussehen können:
Start |
Ende |
Kategorie |
05:27:43 |
07:11:22 |
Produktion Typ X, Batch 1 |
07:11:22 |
08:27:33 |
Produktion Typ X, Batch 2 |
08:27:33 |
12:18:39 |
Prozessumstellung |
12:18:39 |
16:34:18 |
Anfahrt nach Umstellung |
16:34:18 |
17:45:57 |
Produktion Typ Z, Batch 1 |
… |
|
|
23:12:16 |
01:47:04 |
Produktion Typ Z, Batch n |
Der aufmerksame Beobachter hat bestimmt bereits festgestellt, dass die Zeitscheiben durchaus einen Datumswechsel enthalten können. (Ob das wichtig ist, oder ein Problem darstellt?... Einfach mal weiter lesen!)
Tabellen sind für mich meistens nur hilfreich, wenn wenige Daten darin angezeigt werden oder um ggf. Details nachzuschlagen. Um einen Überblick über die Daten zu bekommen, sind Diagramme das Mittel der Wahl.
Hier will ich ein Säulendiagramm benutzen, um die (tägliche) Verteilung der Kategorien darzustellen. Jede Säule entspricht also einem Intervall (hier ein Tag) im Kalender. Die verschiedenen Farben entsprechen dann jeweils einer Kategorie. Die Höhe der Säulenteile entspricht dann der Summe der Zeit der jeweiligen Kategorie.
In meinem fiktiven Beispiel entspricht eine blaue Säule der „Produktionszeit". Eine rote Säule könnte vielleicht einen Produktionsausfall darstellen und die grünen Säulen sind Wartungsstillstände. Kategorien gibt es bei uns viele. Jede Kategorie hat auch wieder Unterkategorien. Aber für irgendwas muss ja auch Drilldown gut sein!
Erster Versuch aus den Daten ein Diagramm zu generieren:
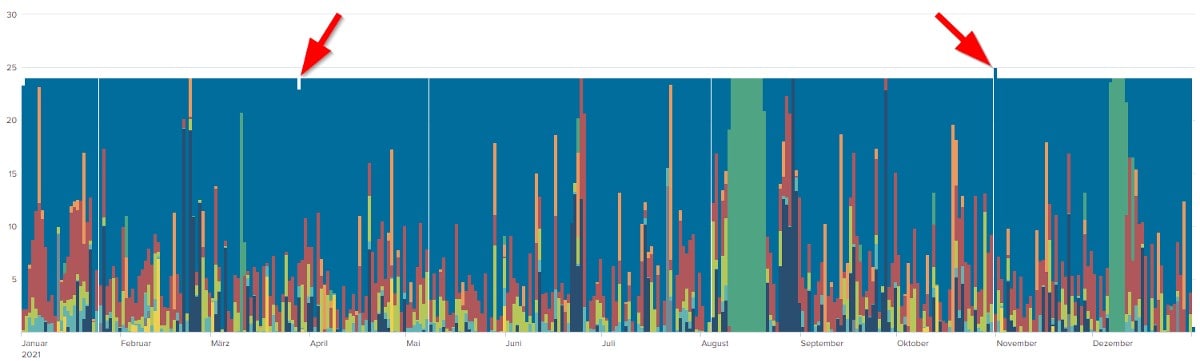
Sieht ja schonmal ganz nett aus.. aber was genau ist das eigentlich?
Auf der Y-Achse kann man ganz klein die (Summe der) Stunden für einen Abschnitt der X-Achse sehen. Die X-Achse entspricht in diesem Bild einem Jahr, unterteilt in Säulen von je einem Tag. Natürlich kann man das mit Splunk auch in anderen Intervallen darstellen (#timechart:span).
Was fällt aber sofort auf? Die Säulen im Diagramm oben sind nicht alle gleich hoch! Die Tage haben mehr oder weniger als 24 Stunden? Ist ein Tag bei Mitsubishi Polyester Film GmbH also anders definiert als im Rest der Welt? Nein, natürlich nicht… Es ist tatsächlich ein Problem der Datenerfassung und -auswertung. (Wir sparen uns an dieser Stelle mal den Blick auf die Rohdaten und ausschweifende Erklärungen wie/warum die Daten auf diese Weise erfasst werden. Weiter unten schauen wir uns das dann trotzdem im SPL-Kontext an.)
Aber wie erklärt man jetzt der Tochter (oder dem Management), dass der Tag in der Auswertung nicht immer genau 24 Stunden hat? Und gibt sich die Tochter mit der Antwort auch zufrieden? Die Antwort kommt in ein paar Zeilen…
Zuerst mal die Erklärung, warum nicht jeder Tag auf 24 Stunden aufsummiert wird:
Jeder Event hat einen Startzeitpunkt und eine Dauer. Die Auswertung ordnet jedem Event einen Startzeitpunkt zu und summiert die angegebene Dauer. Wenn sich ein Event aber über den Datumswechsel erstreckt, dann wird das nicht berücksichtigt. Der Zeitanteil vom zweiten Tag wird einfach dem ersten Tag zugerechnet. Tag 1 bekommt also etwas extra, dafür fehlt dann aber entsprechend etwas an Tag 2.
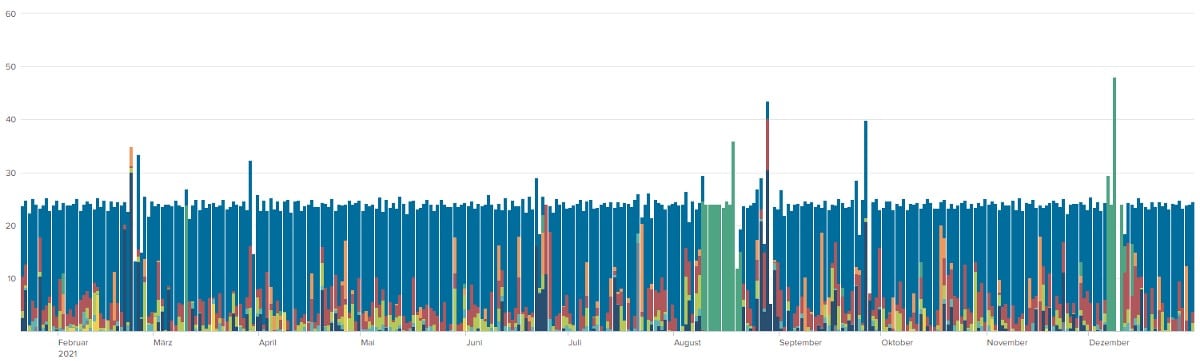
Wie kann ich die Auswertung korrigieren, damit sie mit dieser Art der Zeiterfassung zurechtkommt? Die Events müssen gesplittet werden. Und in meinem Fall genau um Mitternacht. Heißt also: Aus einem Event werden Zwei.
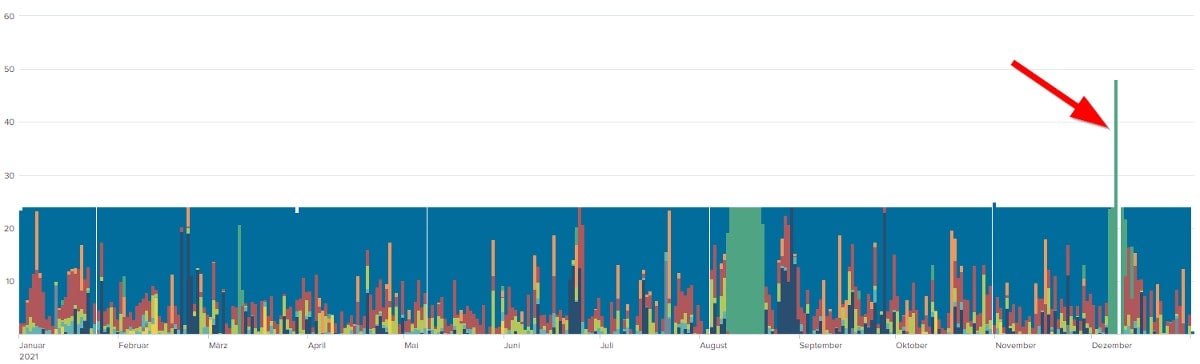
So… sieht schon eher so aus, wie ich es mir vorgestellt habe, ist aber immer noch nicht ganz richtig. Ein Event bzw. eine Zeitscheibe darf bei der Erfassung max. 48 Stunden lang sein.
48 Stunden deswegen, weil dies den Eingabeaufwand bei mehrtägigen Wartungsstillständen reduziert (in der Grafik oben haben die Mitarbeiter, die die Wartung durchführen, 48 Stunden gebucht (grüner Balken))… allerdings scheint die Auswertung das noch nicht zu wissen und gibt deswegen nach wie vor Ausreißer aus. Was ist also zu tun? Mehrtägige Events finden und mehrfach splitten… bis nichts mehr übrig bleibt.
Gesagt, getan - aber leider sind immer noch einige seltsame Ausreißer zu erkennen… doch was genau ist das? Etwas Recherche in den Rohdaten später stellt sich heraus: Glück gehabt, es handelt sich hierbei lediglich um die Zeitumstellung für Sommer-/Winterzeit. Einmal fehlt eine Stunde und einmal gibt es eine Stunde extra… hat also alles seine Richtigkeit.
So, genug bunte Bilder und Text. Kommen wir mal zu meiner Umsetzung mit Splunk.
Im folgenden Abschnitt gehe ich Zeile für Zeile durch meinen Quellcode und erläutere, was ich mir dabei gedacht habe. Wer sich das sparen möchte und lieber gleich den kompletten SPL Code sehen will, muss nur bis ans Ende dieses Posts scrollen.
Bevor wir tief in die Umsetzung mit SPL einsteigen, sollten wir zunächst einen kurzen Blick auf die Rohdaten werfen:
Wir wollen einen Event splitten, wenn der Event über mehrere Tage dauert. Gesplittet wird immer um Mitternacht.
Schauen wir kurz auf die Logik die wir verfolgen wollen: Wenn ein Event über Mitternacht hinweg dauert, muss dieser gesplittet werden.
Wir könnten natürlich den Event in einzelne 1-Sekunden-Scheiben zerlegen. Aber das ist nicht zielführend, da sehr große Zeiträume uns dann an diversen Grenzen in der limits.conf anstoßen lassen. Wir zerschneiden den Event also einfach in Intervalle mit der Restdauer bis Mitternacht. Startet der Event also um 22 Uhr und geht bis 05 Uhr am nächsten Tag, zerschneiden wir den Event in 2h Stücke. Das letzte Stück wird auf die Restzeit gekürzt, fall es nicht in dem Intervall aufgeht. Fall es Events gibt, die über mehrere Tage dauern, zerlegen wir diese zuerst in 24h-Scheiben und danach greift die Logik erneut.
Zuerst sorgen wir mal dafür das Splunk auch weiß wo es die Daten suchen soll. Also definieren wir den Index und den Sourcetype. Da die Betrachtung auf eine von mehreren Anlagen abzielt, legen wir also auch die Anlage schon mal fest. Dann verarbeiten wir das Text-Datum noch in ein Splunk-freundliches Format…
Zeile |
Erklärung |
1 |
Index, sourcetype.. Und Anlage=? .. Das ist die Produktionsanlage. Da es bei uns mehrere gibt, müssen wir natürlich eine aussuchen. |
3,4 |
Mittels eval und strptime erzeugen wir aus dem Text-Datum TS_END bzw. TS_START und dem angegebenen Format einen epoch Timestamp. |

Um zu wissen, ob der Event am gleichen Tag startet und endet, erzeugen wir uns je eine Zahl die Start und Ende-Tag repräsentiert. Liegen Start und Ende am gleichen Tag, müssen wir nichts machen. Nur wenn hier zwei verschiedene Tage ermittelt werden, müssen wir uns den Event vornehmen und splitten. Gut das wir eben grad das Text-Datum in Epoch umgewandelt haben. Jetzt machen wir das einfach wieder rückwärts.
Zeile |
Erklärung |
5,6 |
Mittels eval und strftime erzeugen wir einen String für den ersten und letzten Tag des Events im Format JahrMonatTag. Also zum Beispiel startDay=20220509 und endDay=20220511. Wir erreichen das einfach indem wir als Format nur "%Y%m%d" angeben. Damit wird die Uhrzeit Information einfach weggelassen und ist damit auf Mitternacht gesetzt. Warum braucht man das? Das steht im nächsten Block. |

Zeile |
Erklärung |
7 |
Wir splitten nur Events, deren Start und Ende nicht am gleichen Tag ist. Also setzen wir das Intervall auf 0 wenn startDay=endDay. Wenn startDay und EndDay unterschiedlich sind, dann ziehen wir vom endDay den Start des Events ab (in epoch sind das ja nur Sekunden… dazu wandeln wir mit strptime den endDay einfach in einen epoch Timestamp um). Damit haben wir die Dauer des Events von TS_Start bis Mitternacht (am endDay) als unser Interval ermittelt. Was passiert wenn der Event mehr als 24 Stunden lang ist? .. Dann passiert Zeile 9! |
8 |
Wenn der Event über mehrere Tage geht, dann ist die Dauer zwischen endDay und EventStart größer als ein Tag (ein Tag hat 86400 Sekunden). Jetzt setzen wir das Intervall einfach auf einen Tag. Dann geht der Event zwar noch über Mitternacht.. Aber das splitten wir dann mit ähnlicher Logik im zweiten Schritt. Hier ist das Ergebnis also entweder ein Intervall von 86400 Sekunden oder die Anzahl an Sekunden von Eventstart bis MItternacht (in Zeile 7 ermittelt). |
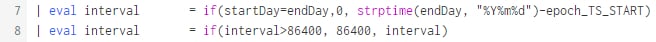
Zeile |
Erklärung |
9 |
Mit eval und mvrange erzeugen wir in jedem Event ein neues Feld namens event_range. mvrange gibt ein Multiwertfeld zurück, das bei epoch_TS_START beginnt und dann in den durch unser Intervall vorgegeben Schritten bis epoch_TS_END geht. |
10 |
Da wir nur für Events die auch gesplittet werden müssen die Intervalle ermitteln, setzen wir das Intervall für alle anderen Events auf 0. Damit existiert das Feld event_range für jedes Event. |
11 |
mvexpand zerlegt jetzt das Feld event_range in einzelne Events. Hätten wir das in Zeile 10 nicht auch für die “normalen” Events erzeugt, dann würden die jetzt verschwinden… |
12 |
Für jedes Event wird jetzt der neue Startzeitpunkt bestimmt. Wenn event_range null ist, dann ist der Startzeitpunkt einfach epoch_TS_START. Für alle anderen Events ist es der Eintrag im Feld event_range. |
13 |
Da wir die Events nicht in n gleich große Teile splitten, sondern das Intervall immer die Anzahl Sekunden von Start bis Mitternacht enthält, ist das Intervall größer als das letzte Zeit-Stück des gesplitteten Events. Wenn also Eventstart+Intervall größer (später) ist das Eventende, dann wird das Intervall entsprechend gekürzt. |
14 |
Nachdem das Intervall korrigiert ist, können wir den Endzeitpunkt der Events ermitteln. Ist event_range null, dann ist es wie in Zeile 12 einfach epoch_TS_END. Für alle anderen Events ist es epoch_TS_START+Intervall. |


Zeile |
Erklärung |
15,16 |
Jetzt überschreiben wir die Felder TS_START und TS_END mit den aktualisierten Zeitinformationen. Das ist wichtig für die zweite Runde, falls es Events gibt die mehrere Tage lang waren. Da wir die Daten wieder aussehen lassen wie am Beginn der Abfrage, können wir den Quellcode kopieren und nur leicht anpassen. |

Zeile |
Erklärung |
17 |
Die Dauer des Events berechnen wir in Sekunden. |
18 |
Damit Splunk die Zeiten im Timechart ohne weiteres nutzt, überschreiben wir _time mit dem Start des Events. Funktioniert ja ohne Probleme, da _time intern auch nur ein epoch Timestamp ist… Wenn man keine Mehrtägigen Events hat, könnte man jetzt schon ein Timechart erzeugen. |
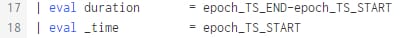
Zeile |
Erklärung |
20-34 |
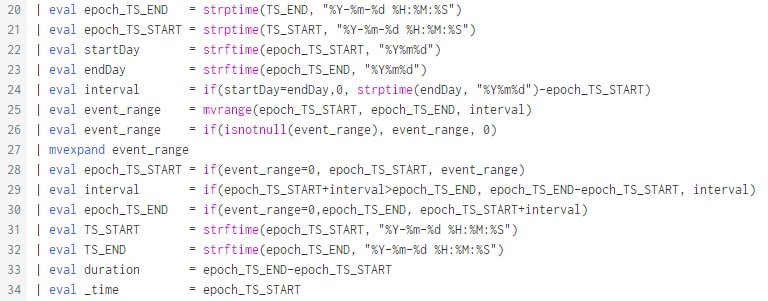
Eigentlich machen wir alles noch einmal. Da aber in Runde zwei nur noch Events existieren die max. 24 Stunden lang sind, müssen wir nicht wie in Zeile 8 das Event auf 86400 Sekunden limitieren. |
Zeile |
Erklärung |
36 |
Good old timechart… natürlich summieren wir die Dauer pro Tag. Mit useother=f und limit=0 kann man noch dafür sorgen, dass auch mehr als 10 Legendeneinträge erzeugt werden, falls "by GRUPPE" mal etwas mehr zurück liefert. |

Und zum Abschluss alles am Stück:
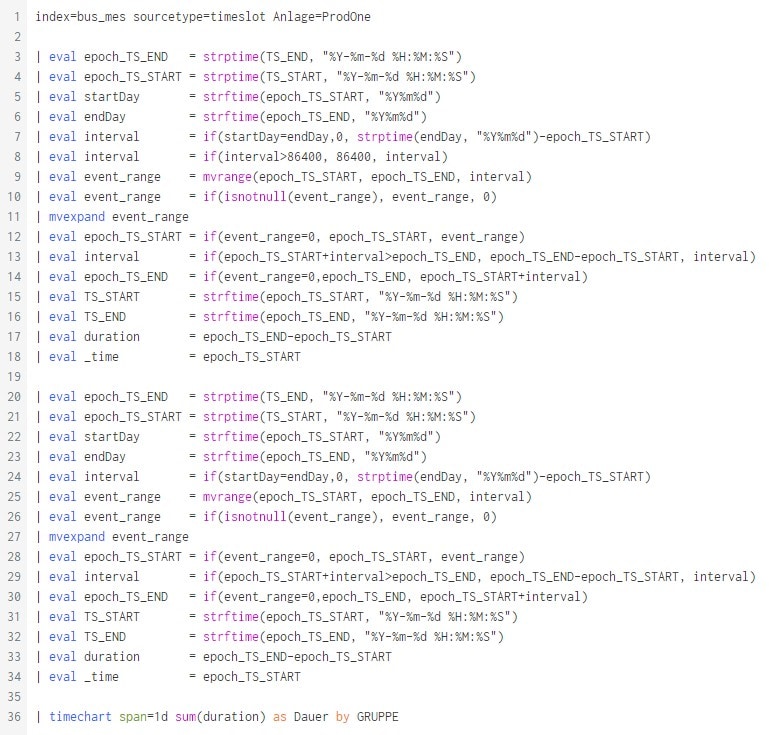
Sieht für Laien vielleicht so aus, ist aber alles keine Raketenwissenschaft und bestimmt haben viele schon vor ähnlichen Problemen gestanden und sie gelöst. Aber es macht immer wieder Spaß mit Splunk eine Fragestellung zu bearbeiten und auf dem Weg zur Lösung viele neue Befehle und Anwendungsmöglichkeiten zu entdecken.
Wie würdet ihr solche Events über mehrere Tag splitten? Oder wie erfasst ihr solche Zeiten, damit es dieses Problem gar nicht erst gibt? Schreibt doch gerne in die Kommentare, wie ihr vorgehen würdet, oder ob ihr noch eine Verbesserung gefunden habt.
#spl:mvrange ; #spl:mvexpand ; #spl:eval ; #spl:strptime ; #spl:strftime ; #split event
SPL als Text(Tabelle) statt als Bild:
1 |
index=bus_mes sourcetype=opus_timeslot Anlage=ProdOne |
2 |
|
3 |
| eval epoch_TS_END = strptime(TS_END, "%Y-%m-%d %H:%M:%S") |
4 |
| eval epoch_TS_START = strptime(TS_START, "%Y-%m-%d %H:%M:%S") |
5 |
| eval startDay = strftime(epoch_TS_START, "%Y%m%d") |
6 |
| eval endDay = strftime(epoch_TS_END, "%Y%m%d") |
7 |
| eval interval = if(startDay=endDay,0, strptime(endDay, "%Y%m%d")-epoch_TS_START) |
8 |
| eval interval = if(interval>=86400, 86400, interval) |
9 |
| eval event_range = mvrange(epoch_TS_START, epoch_TS_END, interval) |
10 |
| eval event_range = if(isnotnull(event_range), event_range, 0) |
11 |
| mvexpand event_range |
12 |
| eval epoch_TS_START = if(event_range=0, epoch_TS_START, event_range) |
13 |
| eval interval = if(epoch_TS_START+interval>epoch_TS_END, epoch_TS_END-epoch_TS_START, interval) |
14 |
| eval epoch_TS_END = if(event_range=0,epoch_TS_END, epoch_TS_START+interval) |
15 |
| eval TS_START = strftime(epoch_TS_START, "%Y-%m-%d %H:%M:%S") |
16 |
| eval TS_END = strftime(epoch_TS_END, "%Y-%m-%d %H:%M:%S") |
17 |
| eval duration = epoch_TS_END-epoch_TS_START |
18 |
| eval _time = epoch_TS_START |
19 |
|
20 |
| eval epoch_TS_END = strptime(TS_END, "%Y-%m-%d %H:%M:%S") |
21 |
| eval epoch_TS_START = strptime(TS_START, "%Y-%m-%d %H:%M:%S") |
22 |
| eval startDay = strftime(epoch_TS_START, "%Y%m%d") |
23 |
| eval endDay = strftime(epoch_TS_END, "%Y%m%d") |
24 |
| eval interval = if(startDay=endDay,0, strptime(endDay, "%Y%m%d")-epoch_TS_START) |
25 |
| eval event_range = mvrange(epoch_TS_START, epoch_TS_END, interval) |
26 |
| eval event_range = if(isnotnull(event_range), event_range, 0) |
27 |
| mvexpand event_range |
28 |
| eval epoch_TS_START = if(event_range=0, epoch_TS_START, event_range) |
29 |
| eval interval = if(epoch_TS_START+interval>epoch_TS_END, epoch_TS_END-epoch_TS_START, interval) |
30 |
| eval epoch_TS_END = if(event_range=0,epoch_TS_END, epoch_TS_START+interval) |
31 |
| eval TS_START = strftime(epoch_TS_START, "%Y-%m-%d %H:%M:%S") |
32 |
| eval TS_END = strftime(epoch_TS_END, "%Y-%m-%d %H:%M:%S") |
33 |
| eval duration = epoch_TS_END-epoch_TS_START |
34 |
| eval _time = epoch_TS_START |
35 |
|
36 |
| timechart span=1d sum(duration) as Dauer by GRUPPE |
Happy Splunking,
Sebastian

Die führenden Unternehmen der Welt vertrauen auf Splunk, einem Unternehmen von Cisco, um ihre digitale Resilienz mit der einheitlichen Sicherheits- und Observability-Plattform, unterstützt durch branchenführende KI, kontinuierlich zu stärken.
Unsere Kunden setzen auf die preisgekrönten Sicherheits- und Observability-Lösungen von Splunk, um die Zuverlässigkeit ihrer komplexen digitalen Umgebungen zu sichern und zu optimieren – in jeder Größenordnung.

Die neuesten Artikel von Splunk, direkt im eigenen Posteingang.
© 2005 - 2026 Splunk LLC All rights reserved.
© 2005 - 2026 Splunk LLC All rights reserved.