
Ein Fahrplan zu digitaler Resilienz im Unternehmen
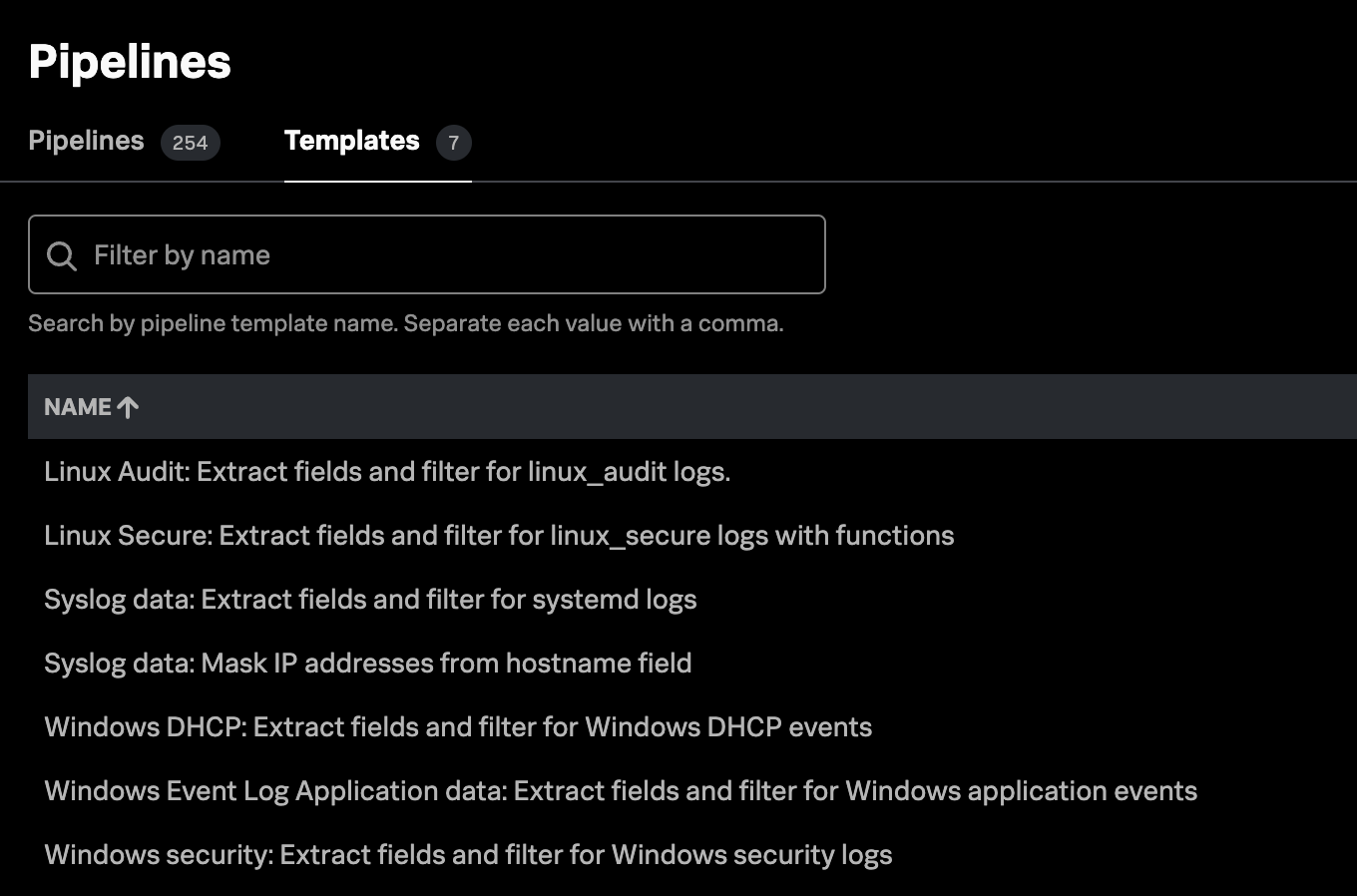
Die meisten von euch haben die News wahrscheinlich schon gelesen und wissen: Edge Processor ist jetzt allgemein verfügbar. Mithilfe von Edge Processor, unserem einfach zu bedienenden Datenaufbereitungstool für Filterung, Umwandlung und Routing direkt am Edge, können Datenadmins für Splunk-Umgebungen unnötige Daten entfernen, sensible Felder maskieren und um Informationen anreichern sowie Daten nach bestimmten Bedingungen weiterleiten. Edge Processor wird über die Splunk Cloud Platform verwaltet, arbeitet aber direkt am Edge der Kundenumgebung, sodass die Datenkosten kontrollierbar bleiben und die Daten effektiv für die weitere Verwendung aufbereitet werden können.
Zum offiziellen Start von Edge Processor können wir außerdem die gute Nachricht bekannt geben, dass nun auch das SPL2-Profil für Edge Processor allgemein verfügbar ist. SPL2 für Edge Processor umfasst die spezielle Untergruppe leistungsstarker Befehle und -Funktionen, die ihr für Umwandlungen und zur Regelung des Datenverhaltens in Edge Processor braucht. d
In Edge Processor habt ihr zwei Möglichkeiten, eure Verarbeitungspipelines zu definieren. Bei der ersten Möglichkeit, die bestens geeignet ist, wenn ihr Pipelines schnell und einfach erstellen wollt, verwendet ihr die praktischen Point-and-Click-Funktionen im SPL2 Pipeline Editor. Über diesen Editor gelangt ihr auch direkt ins Fenster des SPL2 Code Editors, wo ihr eure Pipelines extrem flexibel gestalten könnt. Damit haben Datenadmins die Möglichkeit, SPL2 in einem Code Editor so zur Pipeline-Gestaltung zu verwenden, wie es versierte SPL-Fachleute gewohnt sind.
Dies ist vor allem deswegen interessant, weil ihr SPL-Syntax-Muster dann auch zur Umwandlung von Daten in Bewegung verwenden könnt. Sehen wir uns das genauer an.
SPL2 ist Splunks Datensuch- und -aufbereitungssprache der nächsten Generation. Sie ist der Ausgangspunkt für eine Vielzahl von Szenarien der Datenhandhabung und wird in Zukunft für eine ganze Reihe von Produkten verfügbar sein. Ihr könnt mit SPL2 Pipelines erstellen, die Daten in Bewegung verarbeiten können, Datenschemata erstellen und prüfen und habt dazu Inline-Tools und die Dokumentation zur Verfügung. SPL2 ist als einheitliches Sprachmodell nach dem Motto „Learn once, use anywhere“ konzipiert, das bei sämtlichen Splunk-Funktionen greift, und zwar auf eine Weise, die heutigen SPL-Usern bereits vertraut ist.
SPL2 übernimmt von SPL das, was daran so großartig ist (die Syntax, die am häufigsten verwendeten Befehle, die einfachen Untersuchungsmöglichkeiten, die fließende Struktur), und macht es auch auf Streaming-Laufzeiten anwendbar – also nicht nur auf Daten im Ruhezustand (etwa per splunkd). Datenadmins, Entwicklerinnen und Entwickler und überhaupt alle, die mit SPL vertraut sind, aber nicht mit der Konfiguration komplexer Regeln bei props and transforms, können ihr SPL-Wissen also übertragen und es per Edge Processor direkt auf Daten in Bewegung anwenden.
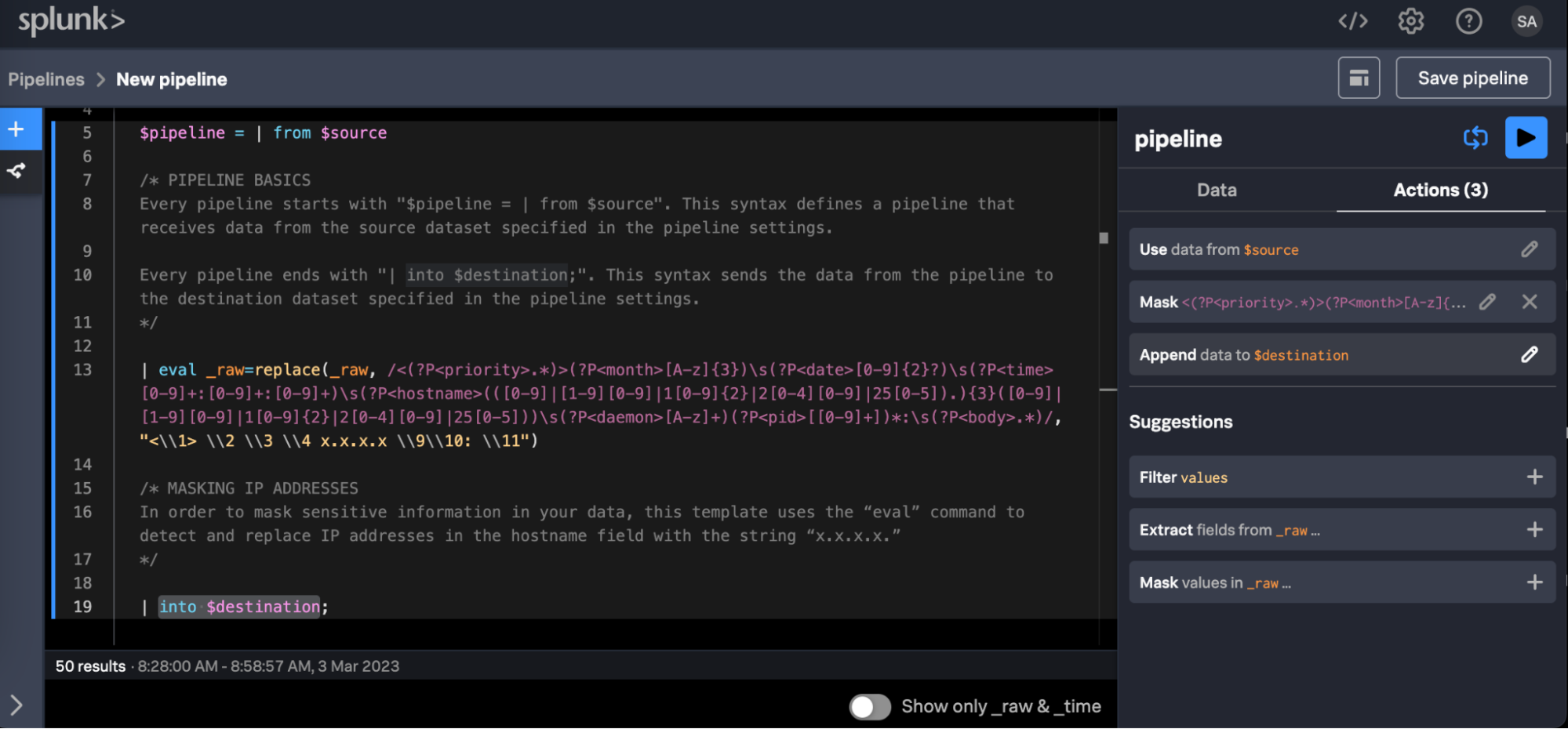 Muster einer SPL2-Pipeline, die IP-Adressen aus dem Feld hostname der Syslog-Daten ausblendet.
Muster einer SPL2-Pipeline, die IP-Adressen aus dem Feld hostname der Syslog-Daten ausblendet.
Etliche Splunk-Produkte verwenden bereits heute SPL2 implizit und ohne dass das auf Anhieb sichtbar wäre, um Datenaufbereitung, -verarbeitung, -suche etc. zu steuern. Nach und nach wollen wir SPL2 für das gesamte Splunk-Portfolio verfügbar machen und die einheitliche Plattform auch einheitlich mit SPL2 unterstützen.
Wenn ihr euch mit SPL auskennt, wird euch sicher freuen, dass SPL2 eine Reihe neuer Funktionen mitbringt, mit denen ihr die Anforderungen an die Aufbereitung von Daten in Bewegung noch eleganter erfüllen könnt. Hierzu gehören die folgenden:
SPL2 unterstützt eine Vielzahl von Datenoperationen. Das SPL2-Profil für Edge Processor stellt eine Teilmenge von SPL2 dar, die über das Produkt Edge Processor verfügbar ist. Ein Beispiel: Edge Processor ist zunächst dazu gedacht, den geregelten Datenausgang, die Maskierung sensibler Daten, die Anreicherung von Feldern und die Vorbereitung von Daten zur Verwendung am richtigen Ort zu erleichtern. SPL2-Befehle und Evaluation-Funktionen, die dies unterstützen, sind im Profil für Edge Processor erfasst, sodass sich eine bruchlose User Experience ergibt. In der Dokumentation erfahrt ihr mehr über SPL2-Profile, dort gibt es auch Schnellreferenzen zur Kompatibilität nach Produkt für SPL2-Befehle und Evaluation-Funktionen.
Die Pipelines in Edge Processor sind logische Konstrukte, die Daten aus einer Quelle einlesen, diverse Operationen daran ausführen und die Daten dann auf ein Ziel schreiben. Alle Pipelines sind vollständig SPL2-definiert (entweder durch direkte Bearbeitung im Code Editor für Edge Processor oder durch die indirekte Erstellung über die GUI). SPL2-Pipelines definieren einen ganzen Satz von Transformationen, die sich meist auf ähnliche Datentypen beziehen.
Alle Pipelines müssen sich an diese Syntax halten:
$pipeline = from $source | <processing logic> | into $destination;
Nehmen wir die folgende Edge-Processor-Pipeline, die in SPL2 definiert ist:
$pipeline = from $source | rex field=_raw /user_id=(?P<user_id>[a-zA-Z0-9]+)/ | into $destination;
Zerlegen wir nun diese SPL2-Pipeline in ihre Komponenten:
$pipeline_part_1 = from $source | where … | rex field=_raw /fieldA… fieldB… fieldC…
$pipeline = from $pipeline_part_1 | eval … | into $destination;
Wie ihr wahrscheinlich gemerkt habt, gibt es ein paar Unterschiede zwischen dieser SPL2 und der SPL, die ihr kennt. Der erste ist, dass SPL2 nicht nur einzelne Ausdrücke, sondern auch Ausdruckszuweisungen zulässt. Ihr könnt ganze Suchläufe benennen, als Variablen behandeln, miteinander verknüpfen und das Ganze als eine Einheit von der Leine lassen. SPL2 unterstützt auch das Schreiben in Datasets, nicht nur das Lesen aus Datasets (und mit einer etwas anderen Syntax). Datasets können ganz unterschiedliche Dinge sein: Indizes, S3-Buckets, Forwarder, Views usw. – ihr werdet wahrscheinlich die meiste Zeit in einen Splunk-Index schreiben. In der Dokumentation findet ihr mehr zu den Unterschieden zwischen SPL2 und SPL.
Was aber, wenn eure Pipeline nicht auf einen einzigen Quelltyp beschränkt ist? In solchen Fällen könnt ihr stattdessen aus einem speziellen Dataset namens all_data_ready (der sämtliche Edge-Processor-Eingangsdaten enthält) lesen und darauf nach Bedarf beliebige Sourcetype-Logiken anwenden:
$pipeline = from $all_data_ready | where sourcetype=”WMI:WinEventLog:*” | rex field=_raw /user_id=(?P<user_id>[a-zA-Z0-9]+)/ | into $destination;
Mittlerweile ist euch vermutlich auch klar, dass SPL2 nicht nur aus Befehlen und Funktionen besteht, sondern ein Kernkonzept mitbringt, das eine ganze Menge von Szenarien leistungsstarker Datenverarbeitung möglich macht. Edge Processor liefert sogar out of the box einsatzfertige SPL2-Pipeline-Vorlagen für eine Reihe von Use Cases zur Aufbereitung vorliegender Daten mit:
Hier lassen wir diese Vorlagen aber beiseite und sehen uns stattdessen ein paar Beispiele an, die zeigen, wie SPL2 die Datenaufbereitung einfacher macht.
Ich möchte die Komponenten komplexer, mehrstufiger Pipelines logisch trennen.
SPL2 ermöglicht eine Pipeline-Definition in mehreren Stufen, was Organisation, Debugging und logische Trennung deutlich erleichtert. Wenn ihr die Anweisungszuweisungen später im SPL2-Modul als Variablen einsetzt, könnt ihr eure Datenaufbereitungsregeln modular zusammenzustellen.
$capture_and_filter = from $all_data_ready | where sourcetype=”WinEventLog:*”
$extract_fields = from $capture_and_filter | rex field = _raw /^(?P<dhcp_id>.*?),(?P<date>.*?),(?P<time>.*?),(?P<description>.*?),(?P<ip>.*?),(?P<nt_host>.*?),(?P<mac>.*?),(?P<msdhcp_user>.*?),(?P<transaction_id>.*?),(?P<qresult>.*?),(?P<probation_time>.*?),(?P<correlation_id>.*?),(?P<dhc_id>.*?),(?P<vendorclass_hex>.*?),(?P<vendorclass_ascii>.*?),(?P<userclass_hex>.*?),(?P<userclass_ascii>.*?),(?P<relay_agent_information>.*?),(?P<dns_reg_error>.*?)/
$indexed_fields = from $extract_fields | eval dest_ip = ip, raw_mac = mac, signature_id = msdhcp_id, user = msdhcp_user
$quarantine_logic = from $indexed_fields | eval quarantine_info = case(qresult==0, "NoQuarantine", qresult == 1, "Quarantine", qresult == 2, "Drop Packet", qresult == 3, "Probation", qresult == 6, "No Quarantine Information")
$pipeline = from $quarantine_logic | into $destination
Wie ihr seht, haben wir in dieser Pipeline vier „Stufen“ der Verarbeitung definiert: mit $capture_and_filter, $extract_fields, $indexed_fields und $quarantine_logic, wobei jede Stufe in die nächste überleitet – und natürlich mit $pipeline, das alles zum Ziel führt. Wenn $pipeline ausgeführt wird, werden im Hintergrund alle Stufen verkettet, sodass die Pipeline wie erwartet abläuft, während zugleich ein gewisses Maß an logischer Segmentierung und an Lesbarkeit erhalten bleibt.
Ich habe ein komplexes verschachteltes JSON-Event; das möchte ich unkompliziert in ein mehrwertiges Feld umwandeln und daraus dann mehrere Events extrahieren.
Wenn ihr schon einmal mit JSON in Splunk gearbeitet habt, dann wisst ihr, dass das … nun ja, knifflig sein kann. Es ist eine schier endlose Kombination diverser mvindexes, mvzips, evals, mvexpands und splits, und vielleicht braucht ihr sogar SEDCMD in der props.conf.
Seit SPL2 ist das jetzt einfacher denn je: mit den Befehlen expand() und flatten(). Sie werden oft zusammen verwendet, um zunächst ein Feld zu erweitern (expand), das ein Array von Werten enthält, und eine separate Ergebniszeile für jedes Objekt im Array zu erzeugen; und um danach die Schlüssel-Wert-Paare im Objekt in separate Felder eines Events zu reduzieren (flatten). Das lässt sich so oft wie nötig wiederholen.
Nehmen wir als Beispiel das folgende JSON, das als einzelnes Event übergeben wird, und nehmen wir an, dass es durch ein Dataset namens $json_data dargestellt wird. Wir wollen den Zeitstempel zum Zeitpunkt der Indizierung erstellen (der noch fehlt) und jede verschachtelte Zeilenfolge in ein eigenes Event extrahieren:
{
"key": "Email",
"value": "john.doe@bar.com"
},
{
"key": "ProjectCode",
"value": "ABCD"
},
{
"key": "Owner",
"value": "John Doe"
},
{
"key": "Email",
"value": "jane.doe@foo.com"
},
{
"key": "ProjectCode",
"value": "EFGH"
},
{
"key": "Owner",
"value": "Jane Doe"
}
}
Von Haus aus und ohne weitere Vorbereitung bekommen wir ein einzelnes Event mit den Feldern im JSON-Body.
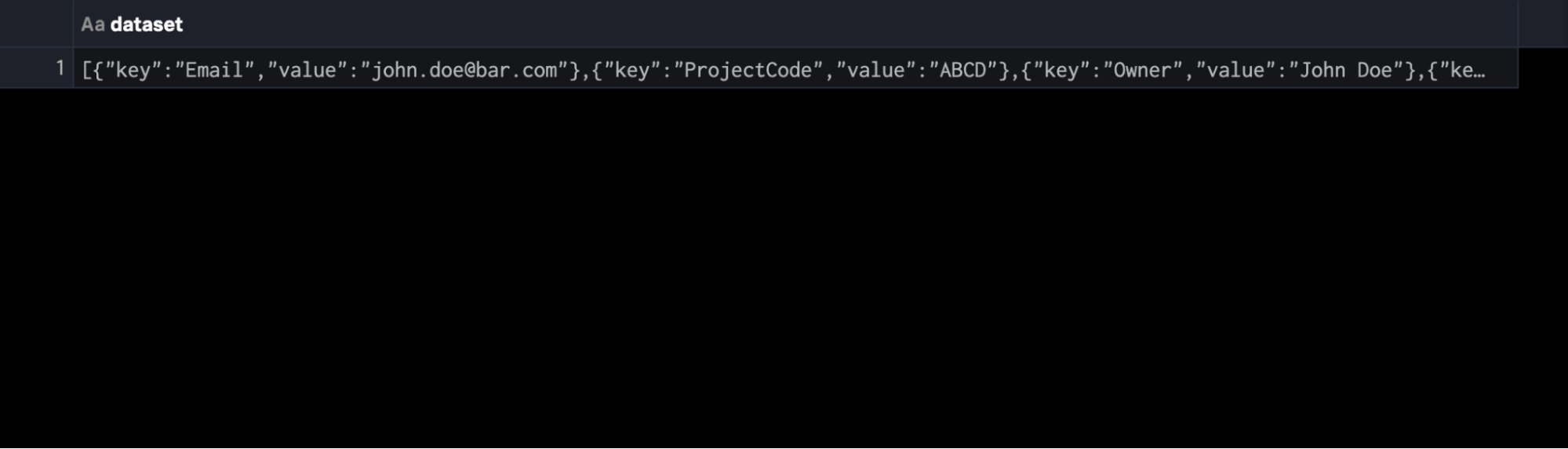
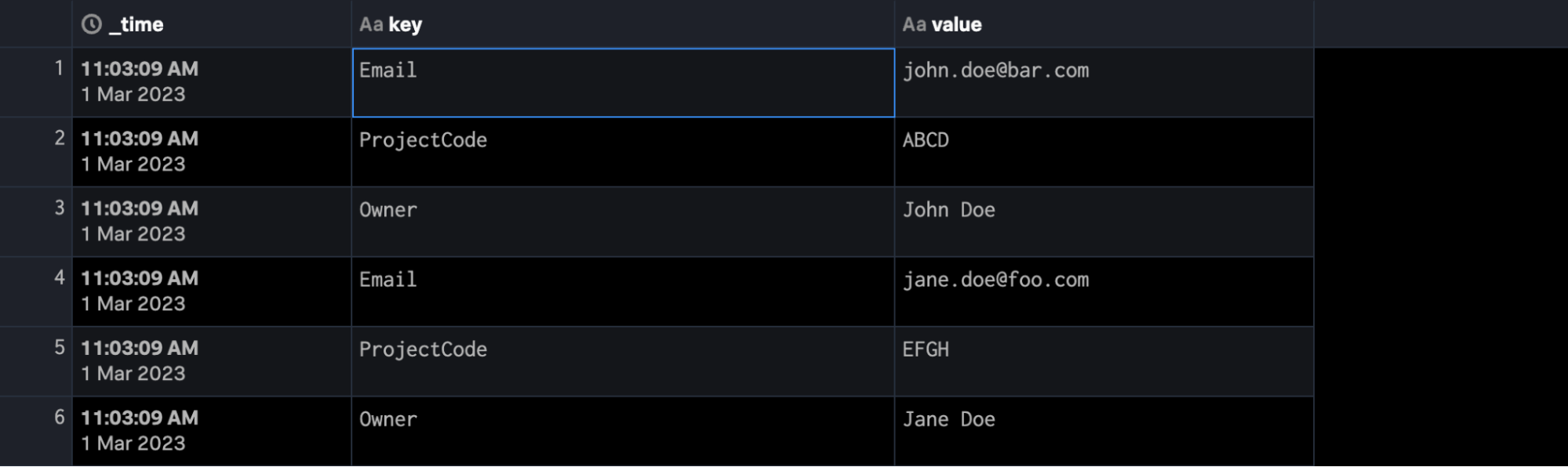
Wir können aber das folgende SPL2 schreiben, sodass wir dieses JSON einfach reduzieren und mit einem Zeitstempel versehen:
$pipeline = FROM $json_data as json_dataset | eval _time = now() | expand json_dataset | flatten json_dataset | into $destination
Dies sollte dazu führen, dass dieses JSON-Event in mehrere Events mit Feldern extrahiert wird. Etwa so:
SPL2 für Edge Processor ist extrem leistungsstark. Dieser Blog-Beitrag kann allenfalls an der Oberfläche der Möglichkeiten kratzen. Wenn ihr daran interessiert seid, mehr über SPL2 oder das SPL2-Profil für Edge Processor zu erfahren, dann macht einfach mit! Wendet euch an euer Account-Team, das euch verbinden kann, oder startet selbst eine Diskussion in der Splunk-Usergroup auf Slack.
*Dieser Artikel wurde aus dem Englischen übersetzt und editiert. Den Originalblogpost findet ihr hier.

Die führenden Unternehmen der Welt vertrauen auf Splunk, einem Unternehmen von Cisco, um ihre digitale Resilienz mit der einheitlichen Sicherheits- und Observability-Plattform, unterstützt durch branchenführende KI, kontinuierlich zu stärken.
Unsere Kunden setzen auf die preisgekrönten Sicherheits- und Observability-Lösungen von Splunk, um die Zuverlässigkeit ihrer komplexen digitalen Umgebungen zu sichern und zu optimieren – in jeder Größenordnung.

© 2005 - 2026 Splunk LLC All rights reserved.
© 2005 - 2026 Splunk LLC All rights reserved.