
Ein Fahrplan zu digitaler Resilienz im Unternehmen

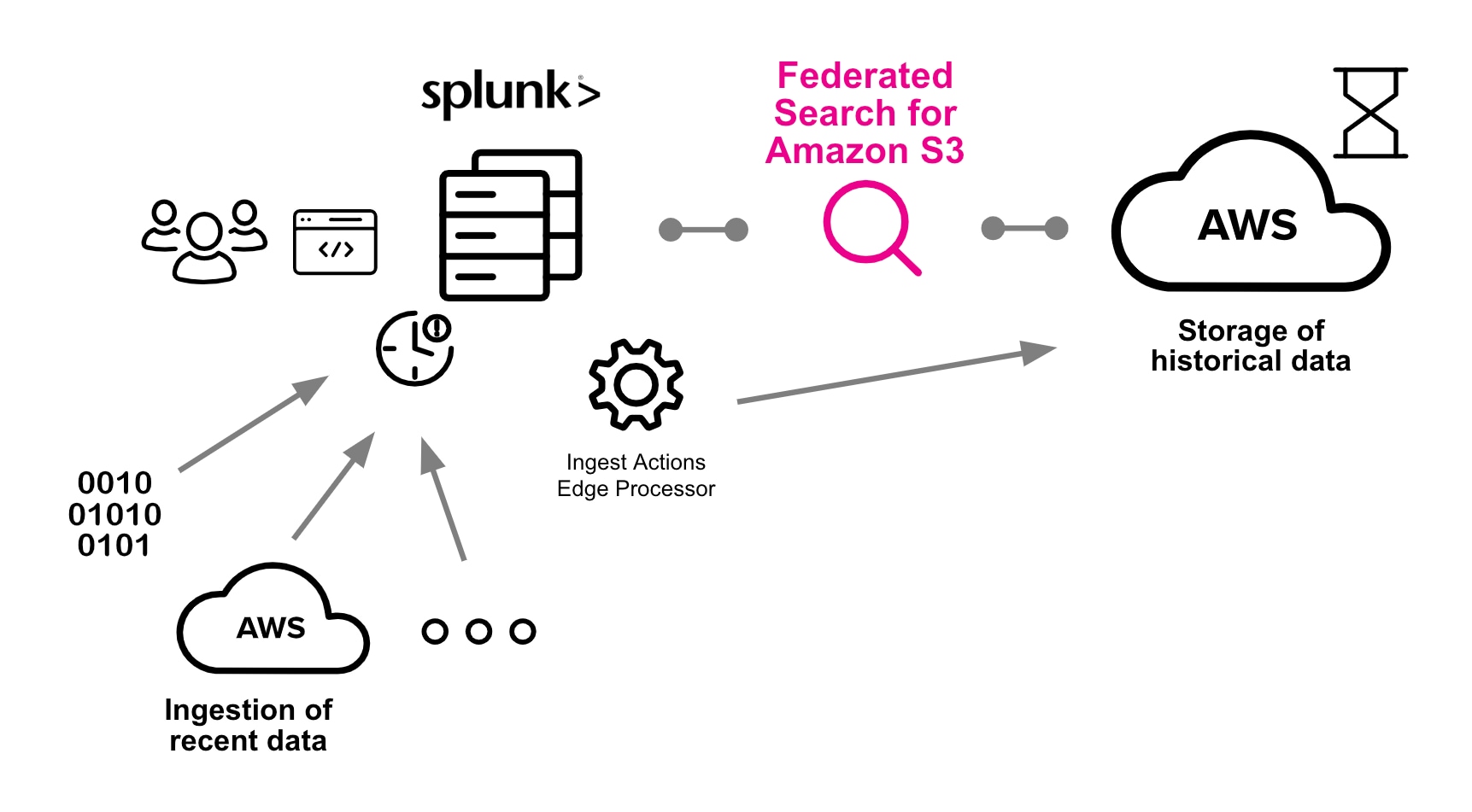
Wir freuen uns, euch mitteilen zu können, dass die föderierte Suche für Amazon S3 jetzt allgemein verfügbar ist. Dieses neue Feature ermöglicht Kunden, Daten in ihren Amazon S3-Buckets direkt von der Splunk Cloud Platform aus zu durchsuchen, ohne sie in die Plattform aufnehmen zu müssen.
Unternehmen sind in hohem Maß auf Cloud-Objektspeicherservices als De-Facto-Ziel für ihre neuen Daten angewiesen, um von den Vorteilen hinsichtlich Kosten, Compliance, Sicherheit, Skalierbarkeit und Verwaltbarkeit zu profitieren, die Cloud-Plattformen bieten. Amazon S3 ist mit über 280 Billionen Objekten weltweit einer der größten heute verfügbaren Services. Allerdings sind Datenbewegungen mit das größte Problem bei der Nutzung von Cloud-Speicherlösungen, da sie bei dem Versuch, diese Daten zu durchsuchen, zu Latenz und Kosten für den ausgehenden Netzwerkverkehr führen können.
Zur Lösung dieses Problems können Splunk-Benutzer jetzt gespeicherte Daten in ihren Amazon S3-Buckets direkt von ihrem Splunk Cloud Platform Stack aus durchsuchen. Dies ist ideal für Untersuchungen, für die bedarfsabhängig Zugriff auf historische, archivierte oder geringwertige Daten notwendig ist. Zudem könnt ihr weiterhin SPL-Suchen durchführen, Dashboards und Berichte erstellen sowie Daten zwischen Amazon S3 und Splunk korrelieren.
Hier ist zu beachten, dass im Fall von Daten, die Echtzeitsuchen und eine hohe Zugriffshäufigkeit erfordern, weiterhin mit Splunk Search auf indizierte Daten zugegriffen werden sollte.
Die föderierte Suche für Amazon S3 wird über eine Integration mit dem AWS-Glue-Datenkatalog unterstützt, der das Schema und die Metadaten bereitstellt, die zum Lesen kompatibler Datensets aus Amazon S3 erforderlich sind. Tabellen im AWS-Glue-Datenkatalog stellen das nötige Schema bereit, das die Splunk Cloud Platform für die Interpretation der in Amazon S3 gespeicherten Daten benötigt. Dies erlaubt Splunk zudem die Suche in beliebten Datenformaten wie JSON, CSV, Parquet, XML, ORC und mehr!
Dank dieser Integration können Splunk-Administratoren und -Benutzer von folgenden Use Cases profitieren:
Die föderierte Suche für Amazon S3 ist für Splunk Cloud Platform Stacks verfügbar, die auf AWS gehostet und unter Version 9.0.2305 ausgeführt werden. Für den Zugriff auf die föderierte Suche für Amazon S3 benötigt ihr eine Data Scan Units-Lizenz für euren Splunk Cloud Platform Stack. Weitere Informationen dazu erhaltet ihr von eurem Splunk-Vertriebsmitarbeiter.
Falls ihr mehr über die föderierte Suche für Amazon S3 erfahren möchtet, seht euch die Dokumentation und die Release Notes an, stöbert in den Splunk Validated Architectures und nehmt an unserem Webinar über das nahtlose Durchsuchen eurer Daten mit Splunk und AWS teil.
*Dieser Artikel wurde aus dem Englischen übersetzt und editiert. Den Originalblogpost findet ihr hier.

Die führenden Unternehmen der Welt vertrauen auf Splunk, einem Unternehmen von Cisco, um ihre digitale Resilienz mit der einheitlichen Sicherheits- und Observability-Plattform, unterstützt durch branchenführende KI, kontinuierlich zu stärken.
Unsere Kunden setzen auf die preisgekrönten Sicherheits- und Observability-Lösungen von Splunk, um die Zuverlässigkeit ihrer komplexen digitalen Umgebungen zu sichern und zu optimieren – in jeder Größenordnung.

Die neuesten Artikel von Splunk, direkt im eigenen Posteingang.
© 2005 - 2026 Splunk LLC All rights reserved.
© 2005 - 2026 Splunk LLC All rights reserved.