
Wege zum Aufbau erfolgreicher Observability-Praktiken
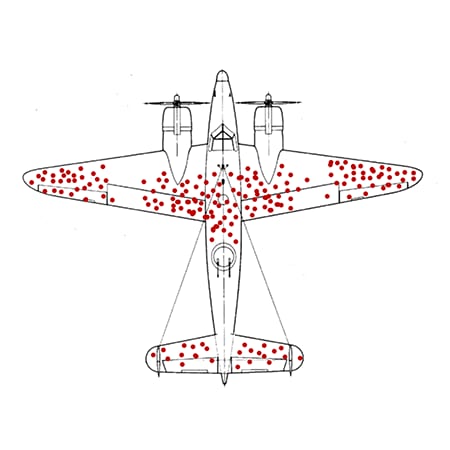
Im Zweiten Weltkrieg sollte ein Team um den Mathematiker Abraham Wald anhand der Muster aus Einschusslöchern bei zurückgekehrten Flugzeuge bestimmen, wo die Flugzeugpanzerung verstärkt werden sollte. Zunächst kam man zu dem naheliegenden Schluss, dass die Einschusslöcher die Problemstellen der Flugzeuge kennzeichneten. Wald wies jedoch darauf hin, dass die Problembereiche genau nicht in den Bereichen der Einschusslöcher liegen konnten, da diese Flugzeuge es ja schafften zurückzukehren. Er erkannte, dass die nicht zurückgekehrten Flugzeuge unbekannte Daten darstellten, die darauf hinwiesen, dass es andere Problembereiche geben musste. Daraus schloss er, dass die Einschussmuster der zurückgekehrten Flugzeuge genau die Bereiche zeigten, die unproblematisch waren.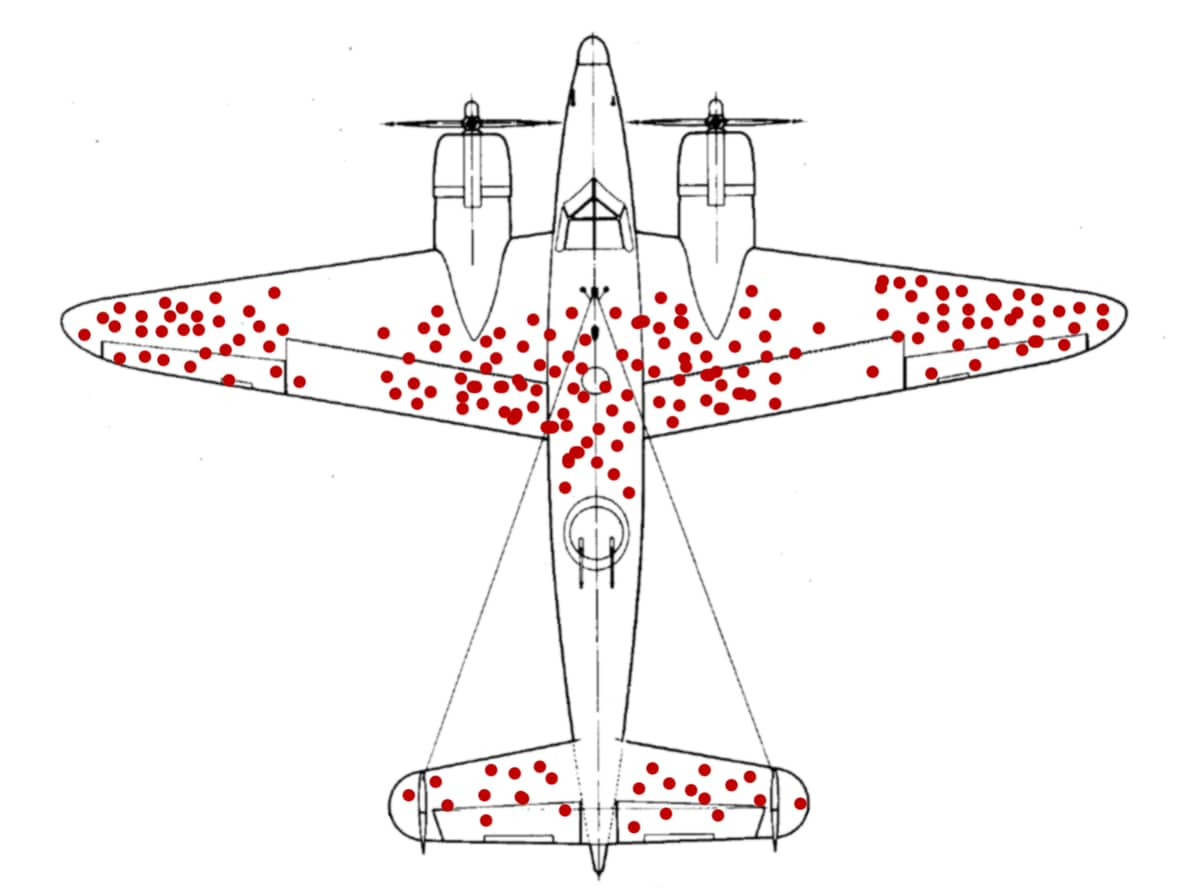
McGeddon – eigenes Werk, CC BY-SA 4.0, https://commons.wikimedia.org/w/index.php?curid=53081927
Beim immer wichtiger werdenden Thema Observability werden wir oftmals aufgefordert, genau dies zu tun: Wir sollen unseren möglichen Reaktionen allein die übrig bleibenden Daten zu Grunde legen. Wenn wir Monitoring jedoch nur für die uns bekannten Dinge in unserer Umgebung einsetzen, stolpern wir direkt in die Falle der kognitiven Verzerrung (Survivorship Bias). Tools bieten neue Ansichten und Informationen, die für die Orchestrierung, Microservices und hybride Clouds nützlich sind. Doch genügt das? Bekommen wir so die Informationen, die wir wirklich brauchen?
Um es mit den Worten von Sir Arthur Conan Doyles Detektivfigur Sherlock Holmes zu sagen: „Sie sehen, aber Sie beobachten nicht“ (Ein Skandal in Böhmen). Willkommen bei Survivorship Bias (auf deutsch auch oft als „Überlebensirrtum“ bezeichnet), einer Art von kognitiver Verzerrung, bei der Schlussfolgerungen auf den verbleibenden Elementen (den Survivors) und nicht auf der Grundgesamtheit der Elemente (der Population) basieren.
In den letzten Jahren haben Abstraktion und Komplexität der Systemarchitektur mit wachsendem Tempo zugenommen. Unsere monolithischen Anwendungen werden zu Cloud-nativen Anwendungen. Unsere Umgebungen mit einem Thread und drei Ebenen werden zu riesigen, elastischen und immer komplexeren Microservice-Architekturen.

Die Triebfeder hierfür sind Änderungen in unserem Umgang mit Technologie. Wir haben auf immens viele Abstraktionen zurückgegriffen, um mit dieser Entwicklung Schritt zu halten.

In unserer modernen Welt kann man mehrere Hosts nutzen, Multi-Cloud-Systeme sind möglich. Unsere Services werden in unterschiedlichen Programmiersprachen geschrieben und nutzen verschiedene Frameworks. Wir erleben ständiges Wachstum, elastische Computing-Systeme und unbegrenzten Datenbedarf.
Denkt z. B. an Kubernetes, um nur ein Beispiel zu nennen. Kubernetes ist klar führend im Bereich der Container-Orchestrierung, wird in unseren komplexen containerisierten Anwendungen intensiv genutzt, dominiert die Public Cloud und erweitert die verfügbaren Möglichkeiten ständig. Doch die Vereinfachung durch Abstraktionen bringt auch einige Herausforderungen mit sich:
Berücksichtigen wir zusätzlich zu diesen Herausforderungen noch die unterschiedlichen Strukturen für Docker-Container, die zugrunde liegenden Anwendungs-Services, Services von Drittanbietern und Kommunikationsprotokolle, dann wird das Ganze ziemlich komplex. Und das wiederum macht das Monitoring der End-to-End-Performance verteilter Services anspruchsvoll. Aufgrund der vorherrschenden Komplexität ist es meist nicht möglich, den Pfad einer Anforderung durch die Anwendung per Hand zu skizzieren.
Es ist auch nicht mehr ungewöhnlich, wenn die Datenvolumen für Observability-Telemetrie die Grenzwerte von mehreren Hundert Terabyte pro Tag erreichen. Die Metrikaggregation ist zwar sehr effizient, erfordert für eine sinnvolle Ursachenfeststellung aber dennoch, dass Tags, Kategorien und Informationen über die zugrundeliegende Infrastruktur hinzugefügt werden, was die Kardinalität entsprechend erhöht. Distributed Tracing-Daten können Dutzende von Datenbereichen generieren, wobei der Durchschnitt bei etwa acht Bereichen pro Anforderung liegt. Stellen wir uns also einmal eine einfache E-Commerce-Website vor, die 500 Anforderungen pro Sekunde erzeugt. Dies ergibt 4000 Datenbereiche, von denen jeder unglaublich wichtige Daten enthält, besonders im Hinblick auf Ausreißer und die einzigartigen Events, mit denen wir nicht gerechnet haben.
Dies ist ein „Signal-to-Noise-Problem“, bei jedem jedes noch so kleine Rauschen ein wichtiges Signal darstellt. Und genau an diesem Punkt kommt es bei unserem Observability-Auswahlspektrum schleichend zu einer Verzerrung durch den Überlebensirrtum bzw. Survivorship Bias.
Man kann das Rauschen reduzieren – zumindest in der Theorie. Wir können die Telemetriedaten durch Sampling filtern. Wir können das Übertragungsaggregat durch Bandpass-Methoden reduzieren. Eventuell haben wir es mit Quantisierungsrauschen bei digitalen Signalen zu tun (das ist allerdings äußerst unwahrscheinlich).
Alle diese Maßnahmen haben dasselbe Manko, und zwar die Annahme, dass es sich bei den aussortierten Daten um Rauschen handelt. Bei einer anforderungsbasierten Microservices-Anwendung ist aber nichts davon Rauschen. Durch Maßnahmen zur Reduzierung der Daten erreicht man also auch genau das: man reduziert seine Daten. Und das macht es schwer, die Bedingungen zu finden, für deren Erkennung wir Observability-Verfahren anwenden – die „unbekannten Unbekannten“.
Bei manchen Tools für Distributed Tracing ist Sampling die Antwort. Hier werden 5 oder 10% der Tracing-Daten verwertet und der Rest wird unbesehen verworfen (Head-Based Sampling, d.h. Sampling anhand vorab festgelegter Kriterien). Andere Tools gehen intelligenter vor: Sie warten, bis das Tracing abgeschlossen ist, analysieren die Tracing-Daten dann auf interessante Details und schicken euch nur die interessanten Daten (Tail-Based Sampling, d.h. Sampling anhand nachträglich festgelegter Kriterien). Wenn Observability aber zum Ziel hat, die unbekannten Unbekannten zu entdecken, zu identifizieren und zu beheben, entsteht bei der Betrachtung der extrahierten Daten unwillkürlich eine Verzerrung.
Ihr möchtet noch immer die Ausreißer identifizieren, doch dafür stehen euch jetzt alle Daten zur Verfügung, ob sie sinnvoll sind oder nicht. Wenn ihr Entscheidungen nicht nur auf den „überlebenden“ Daten basiert, habt ihr die Möglichkeit, Schwachstellen aufzudecken und zu beheben. Ihr könnt sinnvolle Basiswerte festlegen, echte Anomalien feststellen und dafür sorgen, dass euer Flugzeug in der Luft bleibt.
Wie erstellt ihr sonst eine sinnvolle Service-Map für eure Anforderungen? Wie verfolgt ihr historische Datentrends, wenn ihr nicht über alle Daten verfügt?
„Ja, aber", höre ich euch schon sagen. „Bekomme ich alle nötigen Angaben nicht schon durch meine Metriken?“
Die Antwort ist etwas kompliziert. Wenn ihr die Zufallsauswahl beim Sampling vor der Analyse durchführt, gilt besonders bei Tracing-Daten, dass die RED-Werte (Rate, Errors, Duration) nicht gültig sind. Und wieder basiert der Systembetrieb dann nur auf den sichtbaren Daten und die unbekannten Unbekannten werden ignoriert.
Die Verzerrung kann sich auch schlimmer auswirken. In unserem Flugzeugbeispiel bestand die erste Reaktion auf das Muster der Einschusslöcher darin, die Panzerung an den Einschussstellen zu verstärken, um die Überlebenschancen zu erhöhen. Diese zusätzliche Panzerung hätte die Flugzeuge aber langsamer und wahrscheinlich auch schwerfälliger gemacht und somit die Überlebenschance gesenkt. Die Verzerrung durch Survivorship Bias hätte also den gegenteiligen Effekt gehabt.
Sehen wir uns das Flugzeugbeispiel nun in unserem RED-Dashboard an. Bei der Methode mit Sampling erhalten wir die aktuelle Normalverteilung für unsere Duration-Metriken. Uns entgehen damit die Ausreißer P95 und P99. Unsere Dashboards sehen toll aus, doch unsere Kunden sind unzufrieden (zumindest zeitweise).
Selbst wenn wir eine volle Aggregation unserer Metriken verwenden, kann das Fehlen zugrundeliegender Daten problematisch sein. Bei derselben Methode sehen wir nun sporadische Spitzenwerte bei den Duration-Metriken. Unsere Metriken weisen also möglicherweise auf ein Problem hin. Wahrscheinlich handelt es sich um einen Ausreißer. Die Frage lautet also nun „Wurden diese Tracing-Daten durch unsere Sampling-Methode erfasst?“ Oder geht es uns wie Bender aus der Serie „Futurama“, der nach der Datei zu Inspector 5 sucht, um dann festzustellen, dass es diesen gar nicht gibt? Selbst wenn euer intelligentes Sampling diesen Ausreißer beibehalten hat, wie wollt ihr ihn mit den Aktivitäten zu diesem Zeitpunkt oder den normalen Anforderungsansturm des Kunden und der zugehörigen Infrastruktur vergleichen?
Die Antwort darauf ist ganz leicht. Verlasst euch auf eine Instrumentierung, die euch jederzeit effizient sämtliche Daten in Echtzeit bereitstellt. So entgeht ihr den Fallstricken irreführender bzw. unvollständiger Daten. Diese Daten können dann über das Dashboard eurer Wahl (ob RED-basiert oder auf der Grundlage eures eigenen Konzepts) eine vollständige Sicht auf eure Apps und die Umgebung geben, wobei per Drilldown die zugrundeliegende Ursache angezeigt werden kann. Kurz gesagt, bestimmt ihr selbst, was wichtig und für euch interessant ist, und akzeptiert nicht einfach die Daten, die ein Tool-Anbieter für wichtig hält.
Prüft eure Observability-Technologie. Stellt sicher, dass ihr kein unvollständiges Bild davon bekommt, wie eure Systeme arbeiten. Macht euch bewusst, dass es den Überlebensirrtum/Survivorship Bias gibt und das es unglaublich leicht ist, in diese Falle zu tappen, da die sichtbaren Daten eure anfänglichen Schlussfolgerungen meist plausibel machen. Stellt sicher, dass ihr Observability-Daten ohne Verzerrung bekommt, dann bleiben eure Anwendungen „flugfähig“.
Klickt hier, um mehr über Observability bei und mit Splunk zu erfahren.
*Dieser Artikel wurde aus dem Englischen übersetzt und editiert. Den Originalblogpost findet ihr hier: Survivorship Bias in Observability (18.06.2020).
----------------------------------------------------
Thanks!
Splunk

Die führenden Unternehmen der Welt vertrauen auf Splunk, einem Unternehmen von Cisco, um ihre digitale Resilienz mit der einheitlichen Sicherheits- und Observability-Plattform, unterstützt durch branchenführende KI, kontinuierlich zu stärken.
Unsere Kunden setzen auf die preisgekrönten Sicherheits- und Observability-Lösungen von Splunk, um die Zuverlässigkeit ihrer komplexen digitalen Umgebungen zu sichern und zu optimieren – in jeder Größenordnung.

Die neuesten Artikel von Splunk, direkt im eigenen Posteingang.
© 2005 - 2026 Splunk LLC All rights reserved.
© 2005 - 2026 Splunk LLC All rights reserved.