

Digital Resilience Pays Off
Download this e-book to learn about the role of Digital Resilience across enterprises.
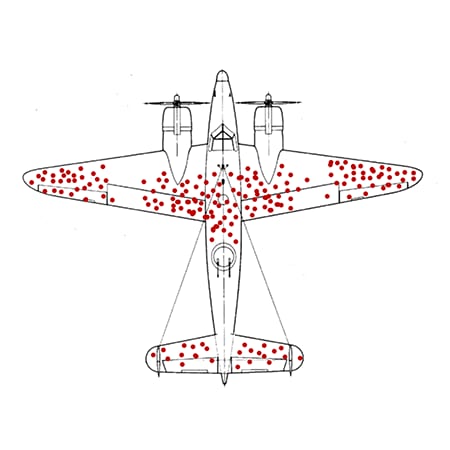
During World War II, a mathematician named Abraham Wald worked on a problem – identifying where to add armor to planes based on the aircraft that returned from missions and their bullet puncture patterns. The obvious and accepted thought was that the bullets represented the problem areas for the planes. Wald pointed out that the problem areas weren’t actually these areas, because these planes survived. He found that the missing planes had unknown data, indicating other problem areas existed. In fact, the pattern for the surviving planes showed the areas that weren’t problematic.
By McGeddon - Own work, CC BY-SA 4.0, https://commons.wikimedia.org/w/index.php?curid=53081927
In the emerging world of observability, we’re often told to do just that; base our choice of response solely on the data that survives. In short, monitoring on just the things you know in your environment will cause you to fall prey to bias. Tools are presenting new views and levels of information that are useful in the world of orchestration, microservices and hybrid clouds. But are they complete enough? Are they giving you the information you really need?
Per Sir Arthur Conan Doyle’s character, Sherlock Holmes, “You see, but you do not observe” (A Scandal in Bohemia). Welcome to survivorship bias, projecting conclusions based on the survivors, not on the population as a whole.
Over the last few years, we’ve seen an accelerating pace of architectural complexity and widening abstractions. Our monolithic applications are becoming cloud-native applications. Our single-threaded, three-tiered environments are becoming massive, elastic and more complex microservices architectures.

This has been driven by changes in the way we embrace technology. We’ve adopted a huge number of abstractions to deal with this evolution.
We live in a world where we can have many hosts. We can be multi-cloud. Our services are written in different programming languages and use different frameworks. We’re ever expanding, elastic in compute and unbounded data needs.
Consider Kubernetes, as just one piece. Kubernetes is the clear leader in container orchestration, heavily used in our complex containerized applications, dominant in the public cloud and constantly expanding its capabilities. But with the simplicity of the abstraction comes some challenges:
Add to these challenges the different structures for Docker containers, your underlying application services, third-party services and communication protocols, and it gets intense. Which in turn means we have challenges with monitoring the end-to-end performance of distributed services. With our complexity, it isn’t usually possible to hand-map our request’s path through the application.
It’s also not unusual to see data volumes for observability telemetry to push the boundaries of hundreds of terabytes a day. Metric aggregation is highly efficient but it still requires the addition of tags, categories and underlying infrastructure information to be useful in rapidly identifying underlying causes, resulting in corresponding high cardinality. Distributed traces can generate dozens of spans, with the average being around 8 per each request. So, imagine a simple e-commerce site generating 500 requests per second. This gives us 4K spans, each with incredibly important data, especially when it comes to outliers and the unique events we didn’t know to expect.
It’s a signal-to-noise problem, where every bit of the noise is an important signal. And that very point is where we start seeing survivorship bias creep into our observability spectrum of choices.
There are ways to reduce the noise, at least in theory. We can filter the telemetry by sampling. We can reduce the transmission aggregate by bandpass methods. We might have to deal with quantization noise in digital signals (but this is highly unlikely).
These all suffer the same issue, an assumption that what you throw away is noise. In a microservices, request-driven application, none of it is noise. So by applying anything that reduces your data, it does just that, reduces your data. And that makes it hard to find the very conditions that we depend on observability techniques to find, the unknown unknowns.
For some distributed tracing tools, the answer is sampling. They look at 5% or 10% of the traces, blindly discarding the others (head-based sampling). Others are more clever, waiting until the trace completes and then analyzing the trace for interesting details, choosing to send you the ones it finds interesting (tail-based sampling). But if the goal of observability is discovering, identifying and resolving the unknown unknowns, looking at what was sent to you is an inherent bias.
You’ll still want to identify the outliers, but now you have all the data, good or bad. You aren’t driving decisions based on just your survivors, you can identify weak spots and improve them. You can set meaningful baselines, identify real anomalies and keep your aircraft flying.
Otherwise, how do you build a meaningful service map for your requests? How do you track historic data trends when you don’t have all the data?
“But wait,” I hear you say. “Don’t my metrics tell me everything anyway?”
The answer gets complicated. If you are doing random sampling before analysis, especially with trace data, your RED (Rate, Errors, Duration) numbers are not valid. You’re again running systems based only on what you see, ignoring your unknown unknowns.
It can get even worse. In the airplane example, the initial response to the pattern of bullet holes was to add more armor to these bullet-ridden spots, making it, in turn, more likely to survive. Yet, that armor would have made the planes slower, likely more cumbersome and thus less likely to survive. The acceptance of the survivorship bias would have resulted in the opposite result.
Now take the plane example to our RED dashboard. In the approach where we’re sampling, we will get the current normal curve distribution for our duration metrics. We’ll miss the outliers, the P95 or P99 outliers. Our dashboards will look great but our customers will be unhappy (at least some of the time).
Even if we have a full aggregation of our metrics, the lack of full underlying data can be problematic. Take the same approach and we’re now able to see the very occasional spike in duration. Our metrics might alert us to the fact that something is wrong. It’s likely an outlier, so now the question is, “Did our sampling approach record that trace?” Or are we, like Bender in Futurama, going off to find the file on Inspector 5, only to discover it isn’t there at all. And even if your intelligent sampling did keep that outlier, how are you going to compare it to the activities around it at the time, or the normal progress of requests for the customer and its related infrastructure?
Really, the answer is quite simple. Depend on instrumentation that will deliver all of the data to you all of the time, in a real-time, efficient manner. This avoids the pitfall of misleading data and incomplete data. That data, via your dashboard of choice, be it RED-based or your own custom concept can then present a complete view of your apps and environment, with the capability to drill into the underlying cause. In short, you get to determine what is important and what you want to know, not simply take the data a tool provider thinks might be important to you.
So, check your Observability technology. Make sure you aren’t just receiving part of the picture of how your systems are working. Be aware that survivorship bias does exist and is incredibly easy to fall into since the data you see can easily support your initial conclusions. Ensure you are getting unbiased Observability data and keep your applications ‘flying’.
Click to find out more about Observability at Splunk.
----------------------------------------------------
Thanks!
Dave McAllister

The Splunk platform removes the barriers between data and action, empowering observability, IT and security teams to ensure their organizations are secure, resilient and innovative.
Founded in 2003, Splunk is a global company — with over 7,500 employees, Splunkers have received over 1,020 patents to date and availability in 21 regions around the world — and offers an open, extensible data platform that supports shared data across any environment so that all teams in an organization can get end-to-end visibility, with context, for every interaction and business process. Build a strong data foundation with Splunk.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2024 Splunk Inc. All rights reserved.
