
Wege zum Aufbau erfolgreicher Observability-Praktiken

Docker erschütterte die Welt von DevOps vor ein paar Jahren in ihren Grundfesten. Container, die für die Cloud-Architektur bereit waren, rückten den Produktionsbetrieb näher an die Entwicklung und trugen dazu bei, Microservices zum Rückgrat eines flexibleren, aggressiveren Gestaltungsansatzes für Softwarearchitektur zu machen. Die Docker-Bewegung gibt Produktteams mehr Freiheit bei der Wahl ihrer Technologien, da sie ihre Anwendungen in der Produktion selbst bereitstellen und verwalten können. Der Einsatz von Docker kann jedoch auch mehr Komplexität, eine Flut an Infrastruktur- und Anwendungsdaten sowie eine größere Notwendigkeit für Monitoring und Benachrichtigungen in der Produktionsumgebung bedeuten.
Splunk Infrastructure Monitoring führt schon seit 2013 Docker-Container in Produktionssystemen aus. Jede einzelne, von uns verwaltete Anwendung wird in einem Docker-Container ausgeführt. Im Laufe der Zeit haben wir gelernt, wie wir unsere Docker-basierte Infrastruktur überwachen und für maximale Transparenz bei unseren Anwendungen sorgen, ganz gleich, wo und wie sie ausgeführt werden.
Dies ist der erste Blog einer Reihe zum Thema Monitoring von Docker-Containern. In diesem Blog werde ich erläutern, was beim Monitoring dockerisierter Umgebungen wichtig ist, wie ihr für euch relevante Container-Metriken erfasst und welche Möglichkeiten zum Erfassen von Anwendungsmetriken es gibt.
IT, Operations und Engineering sind sich zwar über den Wert und die Ziele von Containern einig, doch eine Frage bleibt offen: „Wie überwache ich Docker in meiner Produktionsumgebung?“ Die Verwirrung an diesem Punkt kommt daher, dass wir die falsche Frage stellen. Das Monitoring des Docker-Daemons, des Kubernetes-Masters oder sogar des Mesos-Schedulers ist nicht schwierig. Es ist notwendig, und es gibt Lösungen dafür.
Wenn ihr eure Anwendungen in Docker-Containern ausführt, ändert dies eigentlich nur, wie sie gepackt, geplant und orchestriert werden – nicht jedoch, wie sie ausgeführt werden. Die Frage, die ihr eigentlich stellen solltet, lautet daher: „Wie verändert Docker das Monitoring meiner Anwendungen?“
Die Antwort lautet, wie so oft, „Es kommt darauf an“. Es kommt nämlich darauf an, welche Abhängigkeiten in eurer Umgebung bestehen, und es kommt auch auf eure Use Cases und Ziele an:
Um zu verstehen, welche Veränderungen sich aus einer Microservices-Architektur und einer dockerisierten Umgebung für eure Monitoring-Strategie ergeben können, solltet ihr am besten zunächst die folgenden vier einfachen Fragen beantworten. Eventuell lautet die Antwort bei jeder Anwendung anders, und euer Monitoring-Ansatz sollte diese Unterschiede widerspiegeln.
Wenn ihr Metriken auf Systemebene von euren Containern benötigt, bietet Docker alles Nötige dafür. Der Docker-Daemon stellt sehr detaillierte Metriken über CPU, Arbeitsspeicher, Netzwerk und E/A zur Verfügung, die für jeden laufenden Container über den Endpunkt /stats der Remote-API von Docker verfügbar sind. Ganz gleich, ob ihr Metriken auf Anwendungsebene erfassen möchtet oder nicht, ihr solltet auf jeden Fall zuerst die Container-Metriken abfragen.
Um diese Metriken zu erfassen und an euer Monitoring-System zu übermitteln, verwendet ihr am besten collectd und docker-collectd-plugin. Weitere Informationen dazu findet ihr in unserem Einführungs-Blog über das Monitoring von Docker in großem Maßstab mit Splunk Infrastructure Monitoring.
Die einfachste und zuverlässigste Methode, Metriken von all euren Containern abzurufen, besteht darin, collectd auf jedem Host auszuführen, auf dem sich ein Docker-Daemon befindet. Dazu konfiguriert ihr einfach docker-collectd-plugin so, dass es mit dem lokalen Docker-Daemon auf jedem Host kommuniziert:
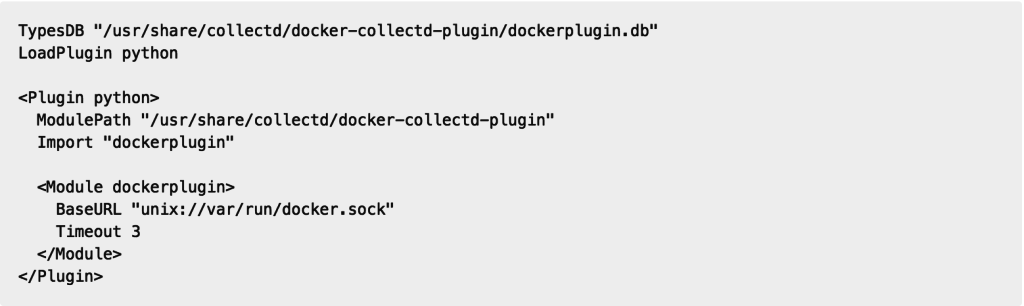
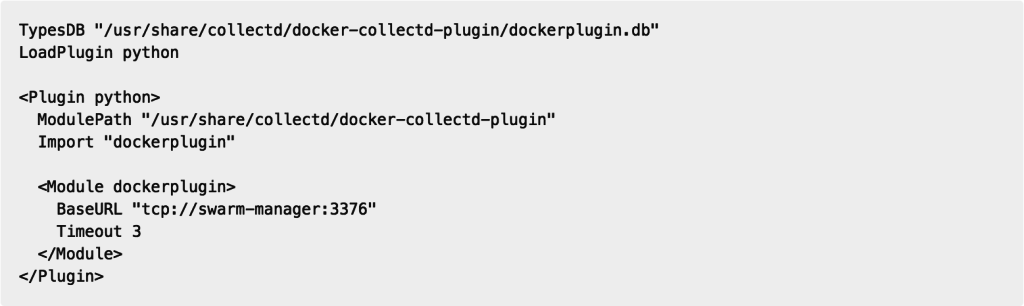
Wenn ihr Docker Swarm verwendet, stellt der Swarm API-Endpunkt die gesamte Remote-API von Docker zur Verfügung, die Daten für alle im Schwarm ausgeführten Container meldet. Das heißt, es muss nur eine collectd-Instanz mit dem docker-collectd-plugin auf den API-Endpunkt des Swarm-Manager verweisen. Es werden dann Container-Metriken von allen laufenden Containern erfasst, die ihr auf euren Swarm-Knoten gestartet habt:
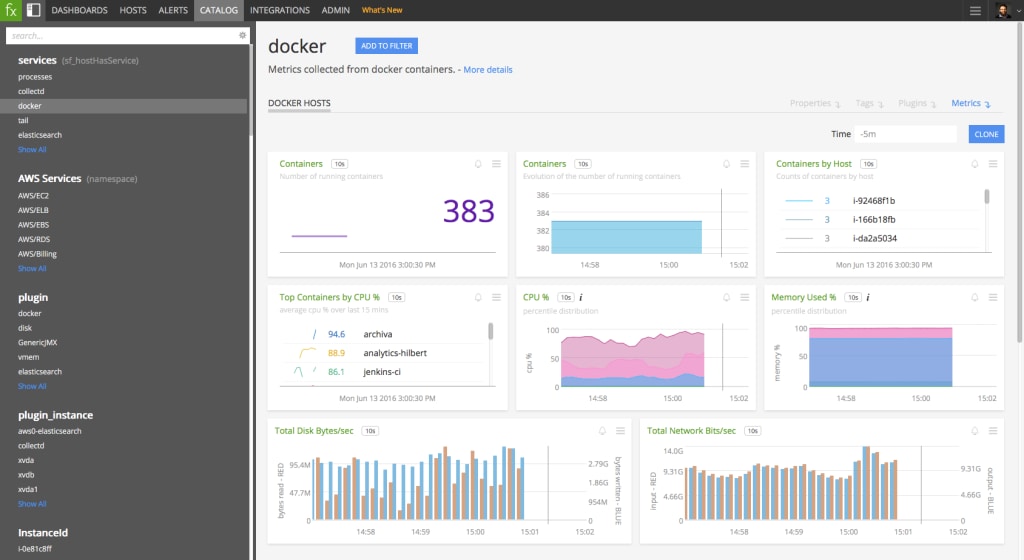
Sobald Metriken für eure Container in euer Monitoring-System übertragen werden, könnt ihr Diagramme und Dashboards erstellen, um die Leistung eurer Container und Infrastruktur zu visualisieren. Hier erfahrt ihr mehr über die Metriken, die docker-collectd-plugin erfasst.
Wenn ihr Splunk Infrastructure Monitoring als Monitoring-System verwendet, erkennen wir diese Metriken automatisch und stellen ausgewählte, integrierte Dashboards zur Verfügung, mit denen ihr eure Docker-Infrastruktur vom Cluster über Hosts bis hinunter zum einzelnen Container darstellen könnt.
Eine der größten Herausforderungen beim Erfassen von Anwendungsmetriken aus dockerisierten Anwendungen ist die Lokalisierung der Datenquelle. Wenn eure Anwendungen Metriken nicht automatisch per Push an einen entfernten Endpunkt übermitteln, müsst ihr wissen, was wo ausgeführt wird, welche Metriken abgefragt werden müssen und wie ihr diese Metriken aus euren Anwendungen abfragt.
Im Fall von Erstanbieter-Software empfiehlt es sich unbedingt, dass ihr eure Anwendung so konzipiert, dass sie ihre Metriken selbständig meldet. Bei den meisten Bibliotheken zur Code-Instrumentierung ist dies bereits so. Alternativ solltet ihr diese Funktionalität problemlos zu eurer Codebasis hinzufügen können. Stellt einfach sicher, dass der entfernte Endpunkt einfach und (wenn möglich) dynamisch konfigurierbar ist.
In Java ist beispielsweise Codahale/Dropwizard Metrics eine beliebige Bibliothek, die man für die Instrumentierung von Java-Programmen empfehlen kann. Um sie so einzurichten, dass sie Metriken an Splunk Infrastructure Monitoring meldet, fügt ihr unsere signalfx-java-Client-Bibliothek und ein paar Codezeilen zu eurer Anwendung hinzu:

Für Python, Go, Ruby und andere gibt es ähnliche Lösungen.
Bei Drittanbieter-Software gestaltet sich die Erfassung von Metriken deutlich komplizierter. In den meisten Fällen ist die zu überwachende Anwendung nicht in der Lage, Metrikdaten an einen externen Endpunkt zu übermitteln. Ihr müsst diese Metriken also direkt aus der Anwendung, aus JMX oder gar aus Logs abrufen. In dockerisierten Umgebungen macht dies das Konfigurieren eures Monitoring-Systems ziemlich anspruchsvoll, je nachdem, ob ihr eine statische Container-Platzierung oder eine dynamische Container-Planung verwendet.
Wenn ihr die Platzierung eurer Anwendungs-Container kennt, entweder aufgrund der Konfiguration oder weil es eine Konvention dafür gibt, macht dies die Erfassung von Metriken aus diesen Anwendungen leichter. Ihr konfiguriert einfach collectd auf jedem Host oder an einem anderen Standort, um den Erfassungsprozess zu starten.
Abhängig von der Anwendung müsst ihr eventuell weitere TCP-Ports verfügbar machen, um den jeweiligen Endpunkt zu erreichen, über den die Anwendung Metriken bereitstellt. In manchen Fällen, wie etwa bei Kafka, müsst ihr JMX aktivieren und bereitstellen. In anderen Fällen, wie Elasticsearch und ZooKeeper, wird ein spezifischer Endpunkt der API direkt verfügbar gemacht.
Wenn ihr einen dynamischen Container-Scheduler wie Kubernetes oder Mesos + Marathon verwendet, könnt ihr wahrscheinlich nicht komplett kontrollieren, wo eure Anwendungen ausgeführt werden. Selbst wenn eure Anwendungen die Service-Erkennung nutzen, kann es sehr schwierig sein, die Lücke zwischen euren Metrikerfassungs- und Monitoring-Systemen zu schließen. Das gleiche Problem besteht bei der Verwendung von serverlosen Infrastrukturen oder reinen Container-Hosting-Anbietern.
Unserer Meinung nach gibt es drei Lösungen für dieses Problem. Keine dieser Lösungen ist perfekt, wenn ihr an schlanken Docker-Images festhalten möchtet, die eine einzelne Anwendungsbinärdatei innerhalb des laufenden Containers ausführen. Sie alle bieten jedoch einen Ausgangspunkt, um die Lücke zwischen den Metrikerfassungs- und Monitoring-Systemen zu schließen.
Das Monitoring von Docker selbst und das Erfassen von Metriken auf Systemebene aus euren Containern sind mit docker-collectd-plugin einfach. Beim Monitoring der Anwendungen, die in euren Docker-Containern ausgeführt werden, wird das Ganze etwas komplexer. Dies ist auch der Grund für die ganze Verwirrung rund um das Thema Docker-Monitoring.
Im zweiten Teil der Blog-Reihe über das Monitoring von Docker-Containern sehen wir uns an, wie Splunk Infrastructure Monitoring seine containerisierte Infrastruktur überwacht, befassen uns mit den Tools für die übergreifende Orchestrierung innerhalb unserer verschiedenen Umgebungen und damit, wie wir für Sichtbarkeit über sämtliche Ebenen der Infrastruktur hinweg sorgen.
Weitere Informationen bietet euch unser Webinar mit Zenefits über das Operationalisieren von Docker und das Orchestrieren von Microservices. In den vergangenen drei Jahren habe ich zudem meine Erfahrungen mit dem groß angelegten Einsatz von Docker weitergegeben. Dabei ging es unter anderem darum, welche Metriken für das Monitoring wichtig sind, wie man Datendimensionen für Troubleshooting-Zwecke zuweist und, welche Strategien für Benachrichtigungen zu Microservices, die in Docker-Containern laufen, ihr verfolgen solltet.
Um mehr über Splunk Infrastructure Monitoring zu erfahren, holt ihr euch am besten eine 14 Tage gültige, kostenlose Testversion!
*Dieser Artikel wurde aus dem Englischen übersetzt und editiert. Den Originalblogpost findet ihr hier.

Die führenden Unternehmen der Welt vertrauen auf Splunk, einem Unternehmen von Cisco, um ihre digitale Resilienz mit der einheitlichen Sicherheits- und Observability-Plattform, unterstützt durch branchenführende KI, kontinuierlich zu stärken.
Unsere Kunden setzen auf die preisgekrönten Sicherheits- und Observability-Lösungen von Splunk, um die Zuverlässigkeit ihrer komplexen digitalen Umgebungen zu sichern und zu optimieren – in jeder Größenordnung.

Die neuesten Artikel von Splunk, direkt im eigenen Posteingang.
© 2005 - 2026 Splunk LLC All rights reserved.
© 2005 - 2026 Splunk LLC All rights reserved.