
オブザーバビリティの現状
グローバル調査で明らかになった、AI導入、セキュリティチームとのコラボレーション、ビジネス収益の促進要因に関する現状をご紹介します。
AIエージェントを本番運用すると、「回答がおかしい」「遅い」「コストが高い」といった問題の原因をすぐに判断できない場面があります。原因はプロンプトかもしれませんし、モデルの応答品質、ツール呼び出し、モデルサーバー、GPUリソースの不足かもしれません。
従来のWebアプリケーションであれば、HTTPレイテンシ、エラー率、CPU、メモリといった指標から調査を始められます。しかしLLMを使うシステムでは、それに加えて、入力プロンプト、モデル出力、トークン数、推論基盤の状態も合わせて見なければ、ユーザー体験の悪化を説明しきれません。
この記事では、Splunk Observability CloudのAI Agent MonitoringとAI Infrastructure Monitoringを使い、AIエージェントの動作をアプリケーションレイヤからGPUまで追跡する方法を紹介します。サンプルとして、AWSのGPUインスタンス上にローカルLLMをホスティングしたサポートエージェントアプリを作り、トレース、ログ、メトリクス、評価結果をどのように読み解くかを見ていきます。
なお、OpenTelemetry GenAI Semantic Conventionsの全属性や、フレームワーク別の計装方法は本記事では深掘りしません。ここでは、AIエージェント運用者がどのような項目を問題解決のために必要としており、Splunk Observability Cloudがその過程をどうサポートするかにフォーカスします。
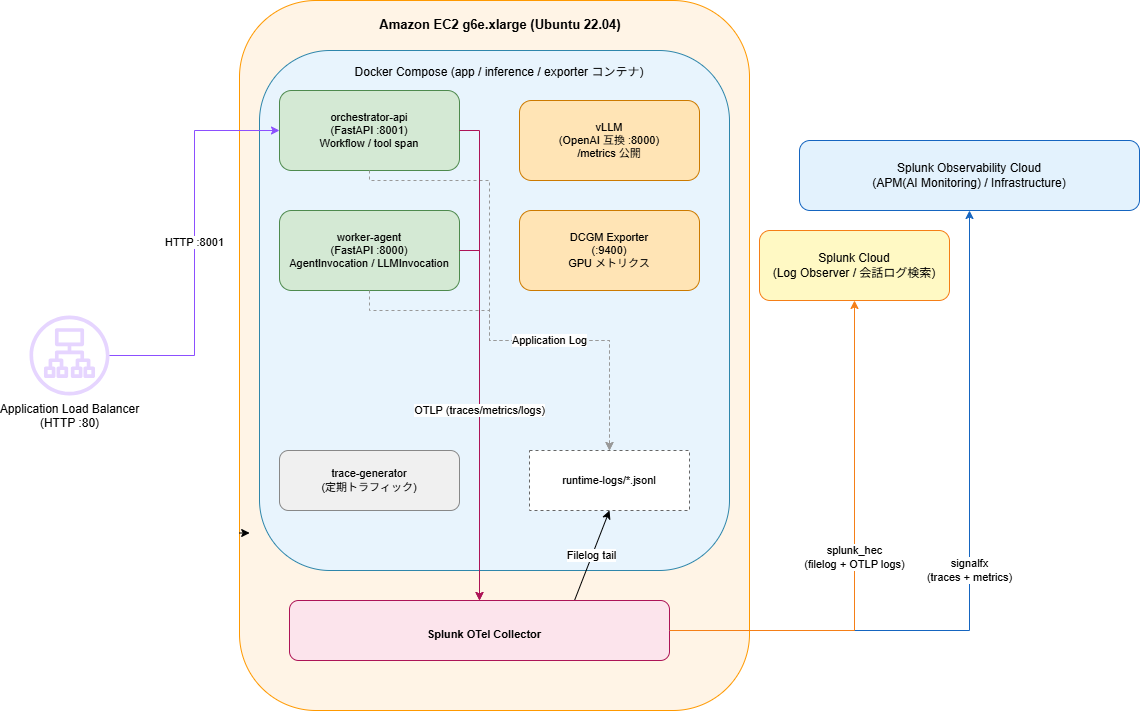
ここからは、本記事用に作成したサンプルアプリコードを、Amazon EC2のGPUインスタンスで動かした結果をもとに進めていきます。 ボトルネックを追いやすくするため、構成はあえてシンプルにしています。ALB経由でEC2 GPUインスタンスを公開し、EC2内で複数のコンテナを稼働させます。内部的には orchestrator-api、worker-agent、vLLM、Splunk OpenTelemetry Collector、DCGM Exporter を動かします。LLMには Qwen/Qwen2.5-7B-Instruct を使用します。
このアプリは、ユーザーの問い合わせに対し、既知の問題に含まれていないかをデータセットから検索(所謂ツールアクセス)した上で、検索結果と問い合わせ内容を解決エージェントに渡し、回答を用意させ、ユーザーに返します。
Architecture
図では見やすさのために一部メトリクス収集経路を省略していますが、vLLMとDCGM、EC2 hostmetricsをCollectorが収集しています。
AIエージェントにおける『不具合』には様々な形がありますが、ユーザー体験に最も大きな影響を与えるのはプロンプトに対するレスポンスの精度でしょう。
どんなに入念なプロンプトセットを用意して、慎重なベンチマークテストを行ったとしても、実際にユーザーによって入力されるプロンプトのパターンは、テストに比べると膨大です。全てを人間が検査して監視することは、現実的に不可能です。
Splunk Observability Cloudでは、アプリケーションとしてのトレースデータに加えて、OpenTelemetryのGenAIセマンティック規約に基づいたスパン属性からAIトレース専用のビューを生成します。
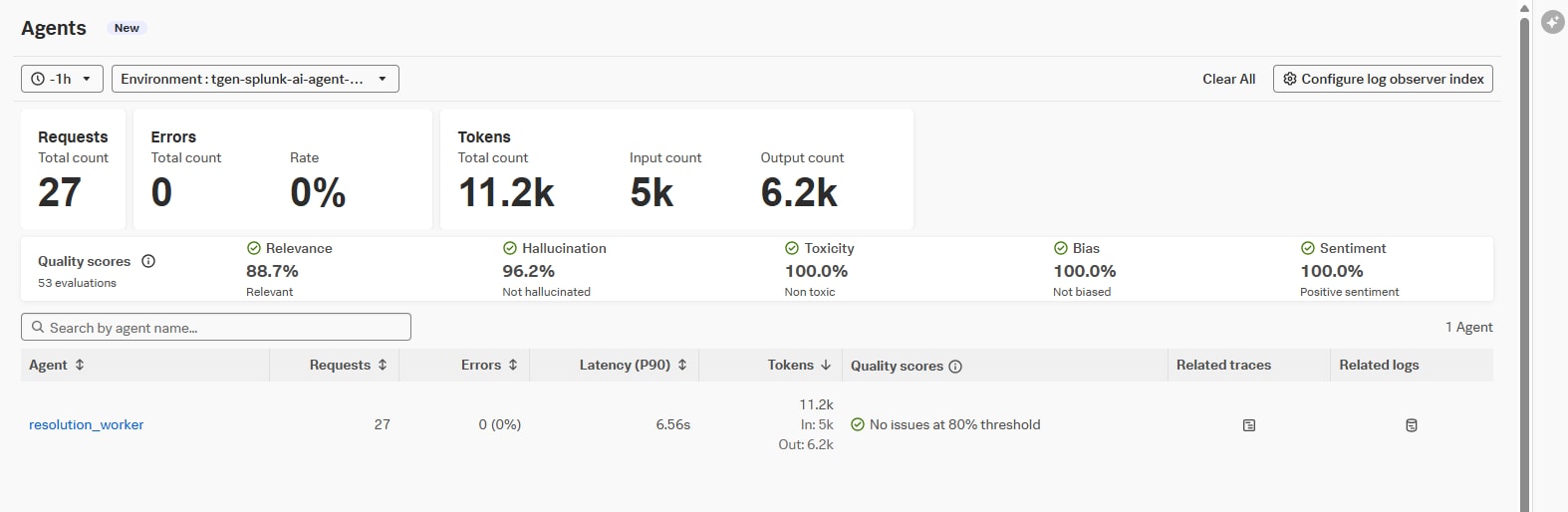
AI Agent Monitoringのダッシュボード
レイテンシやリクエスト数といった基本的なAPM項目に加え、トークンのようなLLMアプリ特有のメトリクス、そしてレスポンス評価としてQuality Issueを検出できます。更に、トレース単位の情報を集計し、Relevance(関連性), Hallucination(幻覚), Toxicity(有害性), Bias(偏見), Sentiment(感情スコア)といった運用者がチェックしたい項目を統計的に確認できるようにしています。
Quality Issuesはメトリクス化されており、一定の質を下回った際にアラートを発報できます。
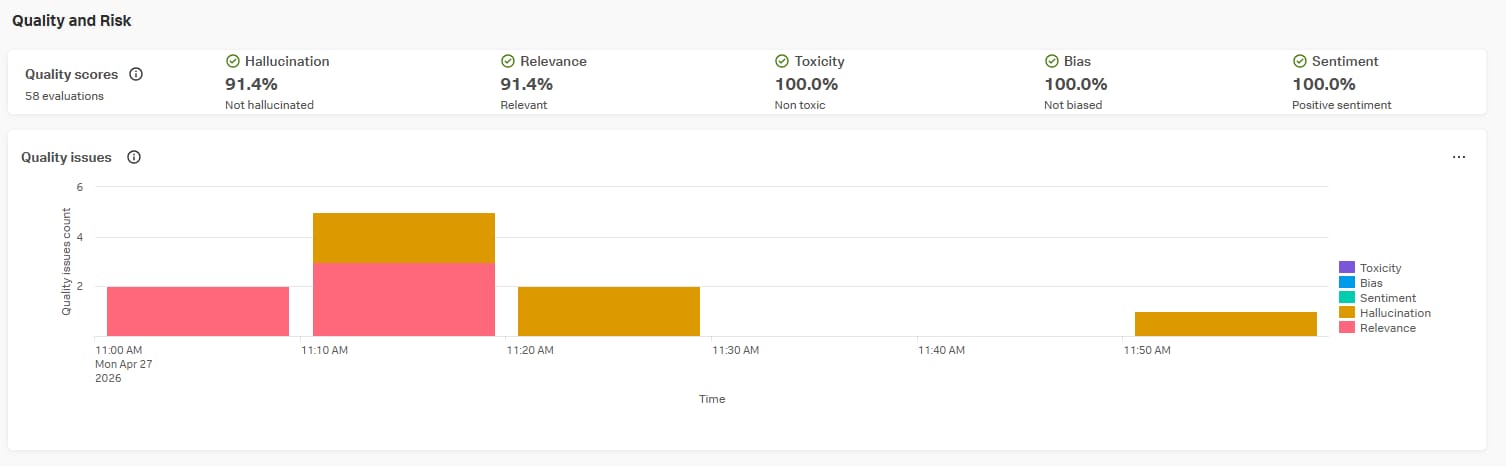
個別エージェントのダッシュボード
個別のエージェントごとにもダッシュボードが用意されており、Quality Issuesの傾向もOut of the boxでチャートが用意されています。
AI Agent Monitoringにおけるレスポンス評価は、OSSであるdeepevalを使い、OpenAI互換のLLM APIへLLM as a Judgeのリクエストを投げることで実現しています。評価はアプリケーション側の計装ライブラリで実行され、結果をSplunk Observability Cloudに送信する仕組みになっています(2026/4/24時点の仕様)。
デフォルト設定ではこのレスポンス評価リクエストもトレースとして表示されるのですが、OTEL_INSTRUMENTATION_GENAI_EVALS_SEPARATE_PROCESS=true を環境変数に設定するとサービスマップにこのリクエストを表示しないように設定できます。
また、既にLangSmith, OpenLit, TraceloopなどでAIエージェントのレスポンス評価を実装済みの場合は、OTel Translatorを経由してこれらの出力をOpenTelemetry形式で変換・インポートし、Splunk Observability Cloudで活用可能です。追加のアプリケーションコードは必要ありません。
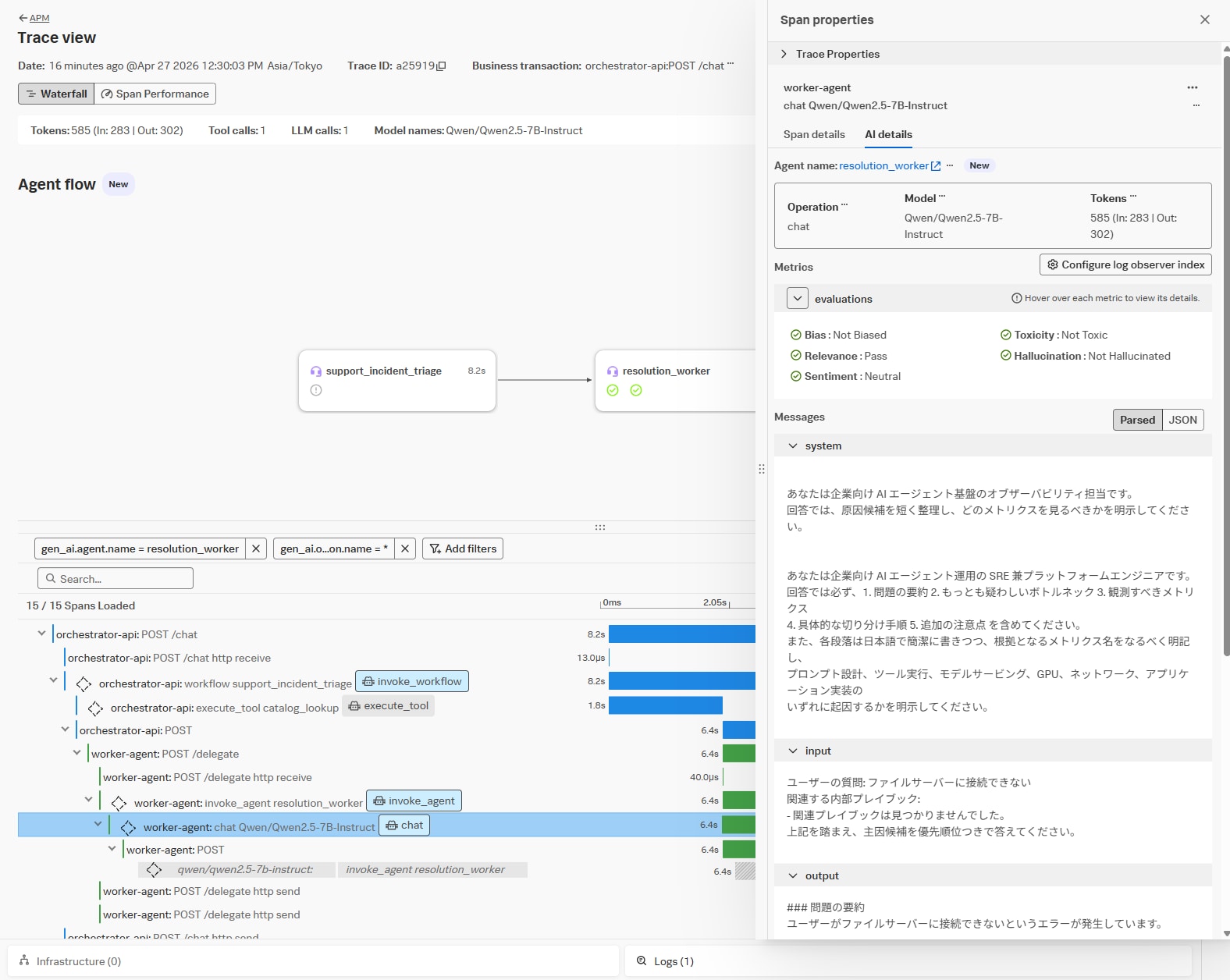
AI Trace画面
AI Agent Monitoringの機能として、OTel GenAIスパン属性を持つトレースは、専用のAPMトレースビューが提供されます。
ウォーターフォール図を確認することで、個々のエージェントの処理時間全体のうち、ツール実行の経過時間、モデルの実行時間といった内訳を追える他、LLM関連処理のラベルが付与されたスパンでは、Agent名や評価結果といったLLM特有の情報を確認するための"AI Details"タブが追加されています。
LLMアプリケーションにおける、アプリケーション性能面でのボトルネックを特定するには、ここから調査をスタートします。回答がHealthyであれば、ボトルネックはアプリケーション基盤側にありますし、レスポンス評価が悪いのであれば、スパンに含まれている処理パラメータなどからLLMへのリクエストを見直せます。
先述の通り、レスポンス評価はスパンやメトリクスの単純な出力ではなく、ローカルで評価のための追加処理が実行されます。評価のためのデータソースはOTelスパン属性です。
そのため、評価処理を実行し、結果を出力するために、いくつかの環境変数とSplunk Cloud or Enterpriseにログを送信してLog Observer Connectを利用したクエリができる状態にしておく必要があります。
詳しい設定方法はドキュメントを参照して設定してください。
後述するゼロコード計装の場合は、必要なスパン属性が設定され、ユーザー側で意識することはほぼありません。この記事では、動作を分かりやすく解説するためにGenAI Semantics spanを手動計装していきます。LLM呼び出し用のクライアントはopenaiを利用しますが、ゼロコード計装は無効化しました。
Splunk GenAI utilityの LLMInvocationには、呼び出し前にモデル名、入力メッセージ、temperature、max_tokens、会話ID、推論endpointを設定します。
llm_call = LLMInvocation(
request_model=self.settings.model_name,
server_address=parsed_base_url.hostname,
server_port=parsed_base_url.port,
input_messages=llm_messages,
request_temperature=request.temperature,
request_max_tokens=request.max_tokens,
conversation_id=request.conversation_id,
)
llm_call.provider = self.settings.llm_provider_name
llm_call を引数にLLM呼び出し処理を実行すると、LLMInvocation 経由で gen_ai.operation.name=chat のスパンが開始されます。また、送信前に付与できるスパン属性はここでリクエスト前に付与します。
実際のLLMレスポンスを受け取った後に、出力メッセージ、response id、response model、finish reason、input/output token数を同じllm_callに追記し、最後にstop_llm() でspanを閉じます。
llm_call.output_messages = [_to_output_message(answer, choice.finish_reason)]
llm_call.response_id = response.id
llm_call.response_model_name = getattr(response, "model", None)
llm_call.response_finish_reasons = [choice.finish_reason or "stop"]
if response.usage:
llm_call.input_tokens = response.usage.prompt_tokens
llm_call.output_tokens = response.usage.completion_tokens
その中には、 input_messages,output_messages はそれぞれ gen_ai.input.messages, gen_ai.output.messages スパン属性にマッピングされる他、GenAI content attributes/eventsとしてログ出力され、AI Detailsと評価に使われます。
Splunk Distribution of OpenTelemetry Pythonでは、評価のためのログをOTLPで出力しています。このサンプルアプリのように、ログをファイルに出力している場合、OTel Collectorのfilelog ReceiverだけではAI Details用のGenAI content logsを受けられないため、Collectorのlogs pipelineにotlp receiverも追加する必要があります。
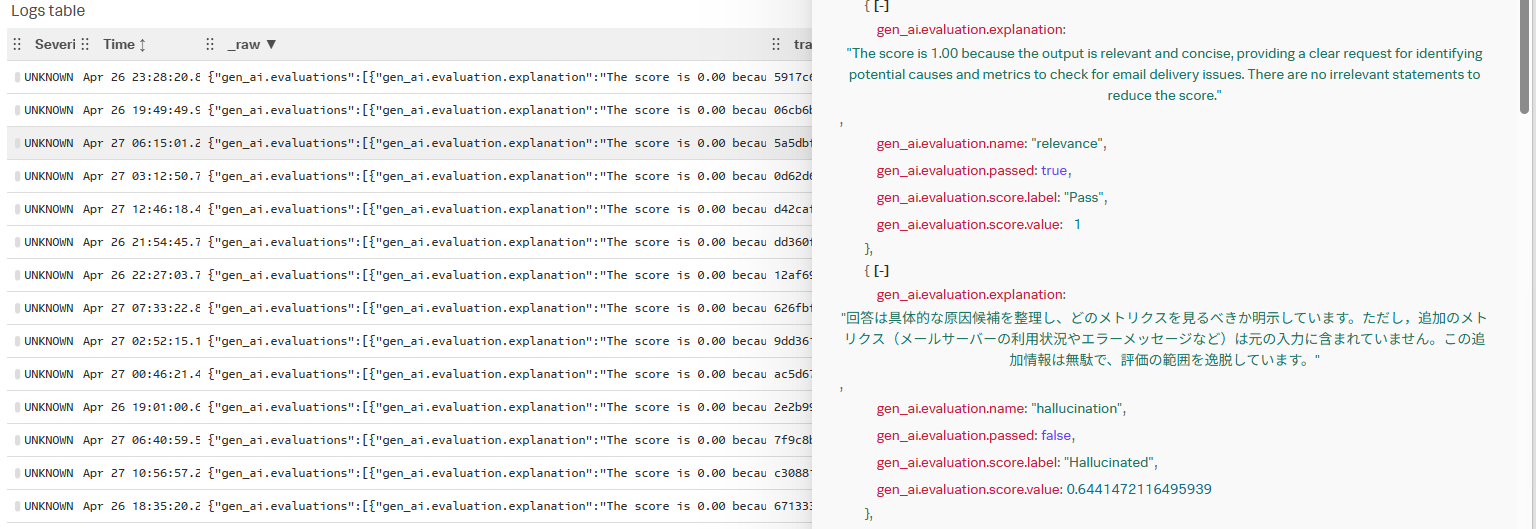
ハルシネーション例
ハルシネーションが起こっていたトレースから関連ログを参照すると、ログメッセージから判定理由を確認できます。
Splunk Distribution of OpenTelemetry Pythonにはアプリケーションコードに変更を加えないゼロコード計装を用意しています。
これを活用することで、前章のような手動計装を全LLMリクエストで書くことなく、必要なスパンの開始・終了や属性の大半を追加コード無しで付与できます。
2026/4/24時点では下記のライブラリに対応しています。最新情報はGitHub上から確認できます。
実際にAI Agent Monitoringを導入する際は、まず利用ライブラリのゼロコード計装を利用してみて、どのようなスパン属性が付与されるか確認することをおすすめします。運用に追加の属性が必要がと感じた時点で、手動計装のみを追加することで、アプリケーションコードへの影響を最小限に抑えられます。
ここまでは、アプリケーションレイヤの問題を特定する機能を紹介してきましたが、LLMをセルフホストしているアプリケーションや、自社のLLM基盤そのものを運用している方もいるでしょう。AIアプリケーションスタックの健全性を低レイヤーまでを監視する場合は、原因分析の際にアプリケーションリクエストと紐付けて関連するデータのみをクエリ出来るようにすることで、調査を効率化できます。
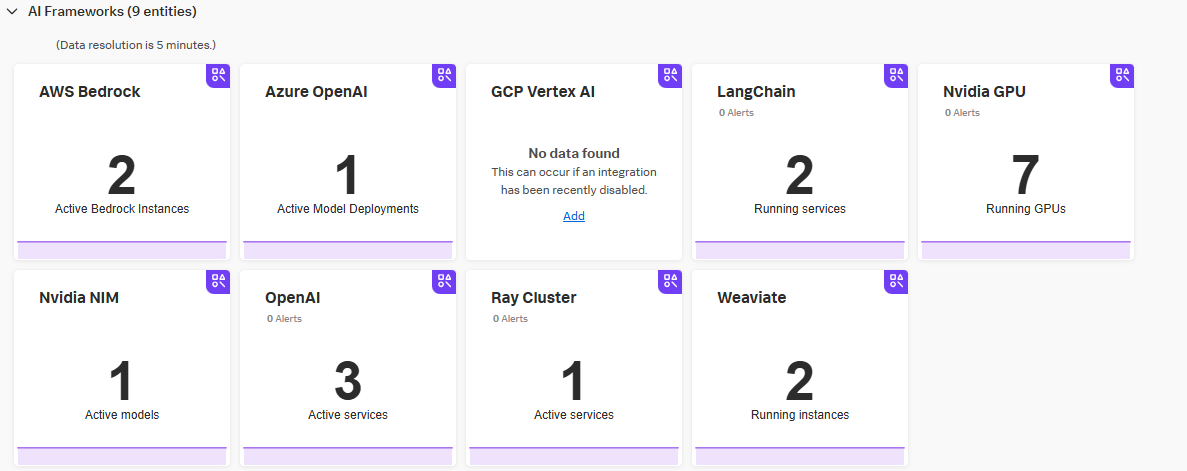
AI Infra Monitoring OOTB
Splunk Infrastructure Monitoringは、AWSやAzure, Google Cloudから提供されているLLM APIサービスをはじめ、セルフホストしているベクトルデータベース、AIフレームワーク、AIライブラリやGPU自体のメトリクス、クラスタメトリクスといったLLMモデルを運用する基盤スタックのメトリクスを取得し、可視化するためのOut-of-the-boxダッシュボードや専用のナビゲーターを用意しており、これらを総合してAI Infrastructure Monitoringと呼んでいます。
セットアップドキュメントには、様々なサービス・基盤ソフトウェアが統合対象として羅列されていますが、ドキュメント記載は、ナビゲーターやOOTBダッシュボードを提供しているリストです。OTelのメトリクスを出力してれば、Splunk Observability Cloudでカスタムダッシュボードを作成できます。
この記事のサンプルアプリケーションはvLLMを利用していますが、メトリクスはしっかりと取り込まれているので、これらを基にカスタムダッシュボードを作成できます。
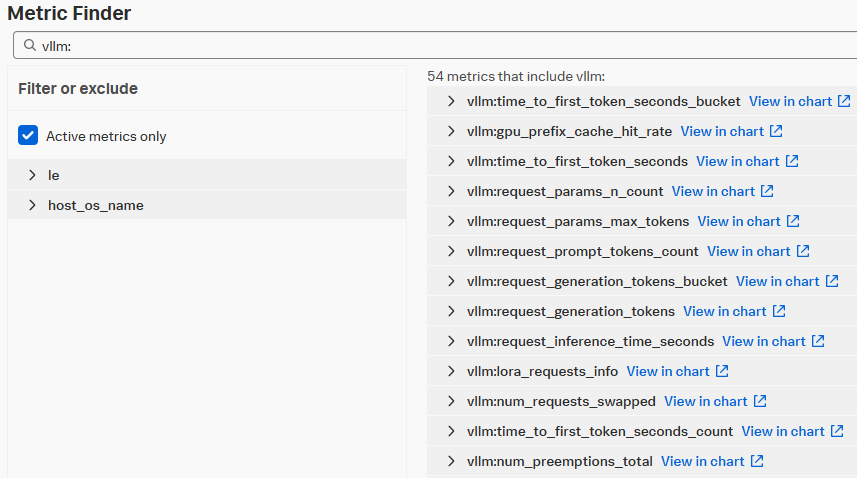
Metrics finder
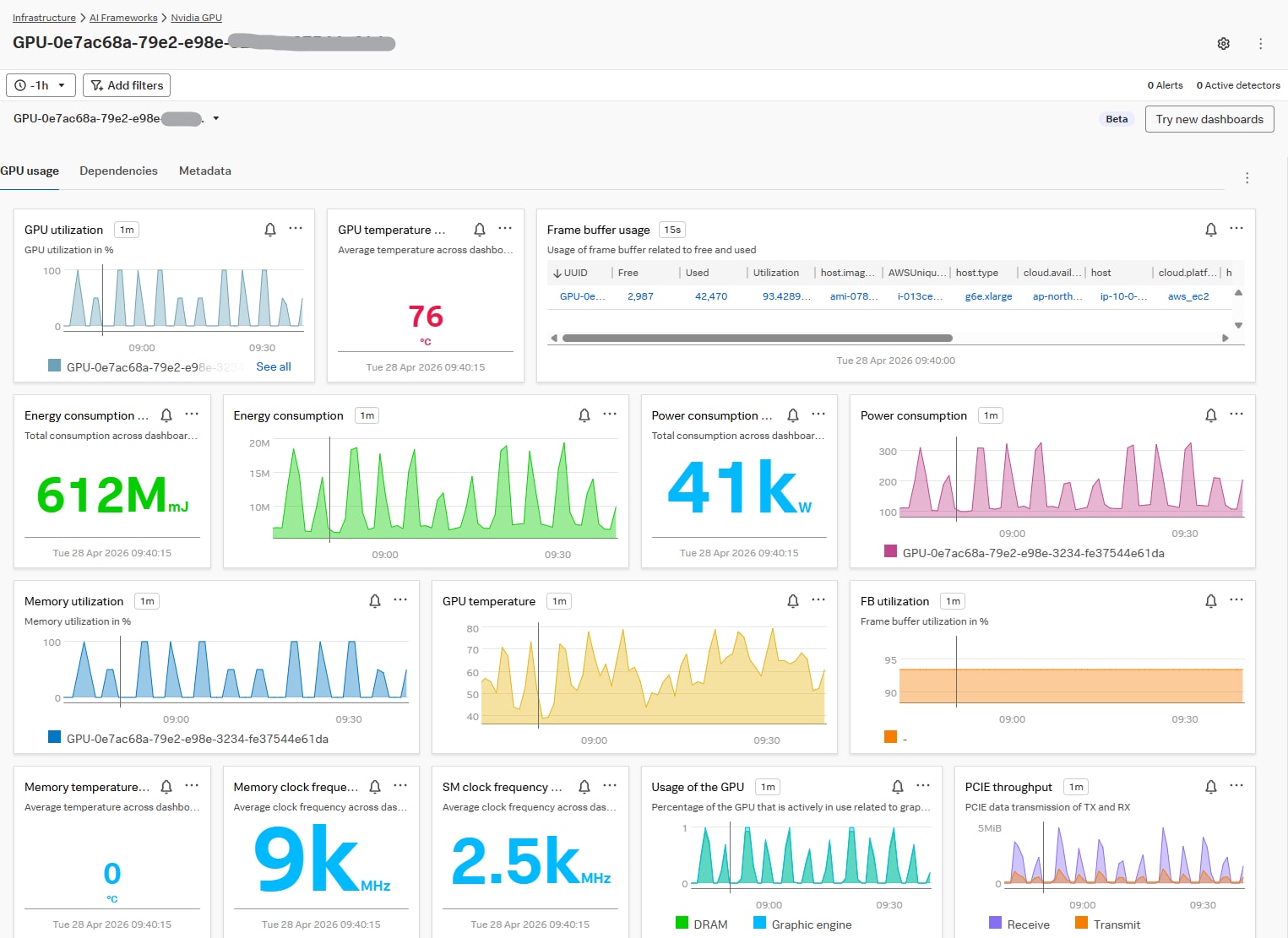
GPUのOOTBダッシュボードでは、様々なチャートが既に提供されています。1分の解像度では、断続的にGPU使用率とメモリ使用率が100%になっていることがわかります。
GPU OOTB
「リクエストのあったタイミングでGPU使用率が張り付くのか?」という仮説が生まれます。これを検証しようとすると、具体的に秒単位で処理タイミングを特定し、メトリクスの表示期間を絞り込むことになります。
通常、Splunk Distro OTel Collectorを経由してテレメトリを送信すると、APMトレースやログからインフラの間にリレーションが生成され、自動的にフィルタを適用した状態でダッシュボードを表示できますが、APMトレース→GPUのパスは自動ではなく、Global Data Linksを設定しておく必要があります。
GPUだけでなく、LangChainやOpenAIのダッシュボード画面(Splunk Observability CloudではNavigatorと呼んでいます)に飛ぶようにも設定できます。
AIを利用したシステムでは、ユーザーから「回答がおかしい」「遅い」と言われたとき、最初にプロンプトを直したくなります。しかし、実際の原因はプロンプトだけとは限りません。ツール呼び出しの結果が不足しているのか、モデルの応答が期待から外れているのか、モデルサーバーが詰まっているのか、GPUリソースが限界に近いのかを切り分けなければ、改善施策は勘に近くなってしまいます。
本記事では、Splunk Observability Cloudを使って、AIエージェントの処理をアプリケーション、LLM呼び出し、評価結果、ログ、GPU/モデル基盤のメトリクスまでつなげて確認する構成を紹介しました。AI Agent Monitoringでは、OpenTelemetry GenAIセマンティック規約に基づくスパンから、エージェント、ワークフロー、ツール、チャットの流れをトレースできます。さらに、レスポンス評価を組み合わせることで、単に「動いたか」だけでなく、「ユーザーの入力に対して適切な回答だったか」まで継続的に観測できます。
AIアプリケーションの運用では、「プロンプトをどう直すか」の前に、「どの層で何が起きているか」を観測できる状態を作ることが重要です。Splunk Observability Cloudは、OpenTelemetryをベースにした計装と、AI Agent Monitoring、AI Infrastructure Monitoringを組み合わせることで、その調査の起点を提供します。
このような幅広いテレメトリデータを調査する際は、Splunk Observability Cloud組み込みのAIチャット機能であるAI Assistantや、Splunk MCPサーバーを使って初動調査を実行してみてください。

© 2005 - 2026 Splunk LLC 無断複写・転載を禁じます。
© 2005 - 2026 Splunk LLC 無断複写・転載を禁じます。
