
AIと機械学習を活用したセキュリティユースケース
SplunkのAIと機械学習機能の効果的な活用方法を、お客様の成功事例とともにご紹介します。
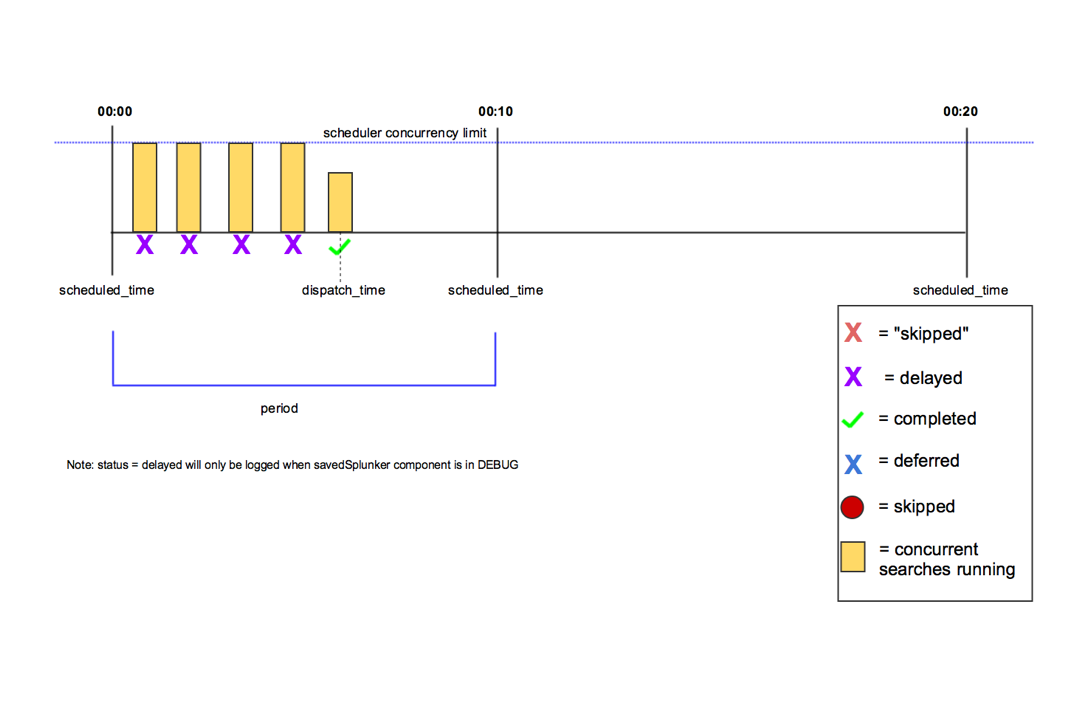
動作の違いはスケジューリングのモード(リアルタイムか連続)に依存します。
skipped (スキップ)
deferred (延期)
savedsearches.conf realtime_schedule = 1
savedsearches.conf realtime_schedule = 0
limits.conf max_continuous_scheduled_search_lookback = <期間>
| 検索タイプ | デフォルトスケジューリングモード | savedsearches.conf | scheduler.logステータス | MC表示ステータス |
|---|---|---|---|---|
| scheduled (定期検索) | リアルタイム | realtime_schedule = 1 | success / skipped | completed / skipped |
| report acceleration | リアルタイム | realtime_schedule = 1 | success / skipped | completed / skipped |
| datamodel acceleration | リアルタイム | realtime_schedule = 1 | success / skipped | completed / skipped |
| Summary index (サマリー) | 連続 | realtime_schedule = 0 | success / continued | completed / deferred |
スケジューラは複数の検索が同時刻に予定されている場合、以下の順序で優先します。
1. 第一優先:アドホックな履歴検索(手動で実行する検索)
ユーザが手動で実行する履歴検索は常に最優先で実行されます。複数のアドホック検索が同時に始まり、定期的なレポートがスケジュールされている場合、一部のレポートは実行枠を譲ってスキップされることがあります。
2. 第二優先:リアルタイムスケジューリングの定期レポートやアラート
手動で設定したレポートやアラートはデフォルトでリアルタイムモードを使用します。
このサーチとレポートカテゴリーでは手動作成のレポートやアラートがスキップされるのを極力避ける為、追加の優先順位決定のルールが適用されます。より詳細な情報については以下のリンクを参照してください。
「How the scheduler prevents skipped report runs」
3. 第三優先:連続スケジューリングの定期レポート
サマリーインデックスを生成する定期レポートなど、データ収集に欠落が許されない検索で使われます。
「Real-time scheduling and continuous scheduling」
4. 最終優先:自動スケジュールされたレポート
レポート加速やデータモデル加速のプロセスで使用され、集計を更新します。
スケジューリングルールにより、スキップされる検索を減らす仕組みがあります。
1. スケジュールされたレポートに優先度スコアを適用
実行時間の平均に基づいてスコアを算出し、短時間で終わるレポートが優先して実行されます。
短時間の検索はスキップされにくくなりますが、長時間かかる検索はスキップされやすくなります(全検索に適用)。
2. リアルタイムを連続より優先
リアルタイムスケジュールの検索は連続スケジュールより優先度が高く設定されます。
リアルタイム同士でのみ競合し、連続モードの検索より先に実行されます(全検索に適用)。連続スケジュールの実行時も同じモードでのみ競合します。
3. スキップされた検索の優先度を引き上げる
スキップが発生した場合、優先度スコアを改善して、今後実行される可能性を高めます。
特に実行頻度が低い検索は、実行頻度がより高い検索が同じ回数スキップした時よりも大きく優先順位があがります(全検索に適用)。
4. スケジュールウィンドウの設定
検索の開始時刻に柔軟性を持たせるため、サーチが時刻どおりにスタートすることが厳格に必要とされない場合は、ウィンドウ期間を設定します。
設定された期間内では優先順位が一時的に下がり、その時点で順位の高いサーチを先に実行します。設定された期間が終わりに近づくにつれて徐々に優先順位が上がり、サーチが実行されます(デフォルトでは無効、必要に応じて設定)。
最大合計検索数 = (max_searches_per_cpu × CPUの数) + base_max_searches
クラスタ全体の総同時実行検索数
(アドホック + スケジュール検索)
( max_searches_per_cpu × CPUの数 + base_max_searches ) × クラスタメンバー数
クラスタ全体の同時実行「スケジュール検索」数
( ( max_searches_per_cpu × CPU数 + base_max_searches ) × max_searches_perc ) × クラスタメンバー数
クラスタ全体の同時実行「自動サマリ化検索」数
( ( ( max_searches_per_cpu × CPU数 + base_max_searches ) × max_searches_perc ) × auto_summary_perc ) × クラスタメンバー数
3ノードSHC、各メンバーが8 CPUコアの場合:
1. 総検索数
(1 × 8 + 6) × 3 = 42
2. スケジュール検索数
( (1 × 8 + 6) × 0.5 ) × 3 = 21
3. 自動サマリ化検索数
( ((1 × 8 + 6) × 0.5) × 0.5 ) = 3.5 → 切り捨てて 3、× 3 = 9
01-31-2019 14:53:21.086 -0500 INFO loader - Detected 8 (virtual) CPUs, 8 CPU cores, and 7822MB RAM
| rest splunk_server=<captain> /services/server/info | table splunk_server numberOfVirtualCores
| rest splunk_server=<captain> "/services/server/status/limits/search-concurrency?cluster_wide_quota=1" | table max*
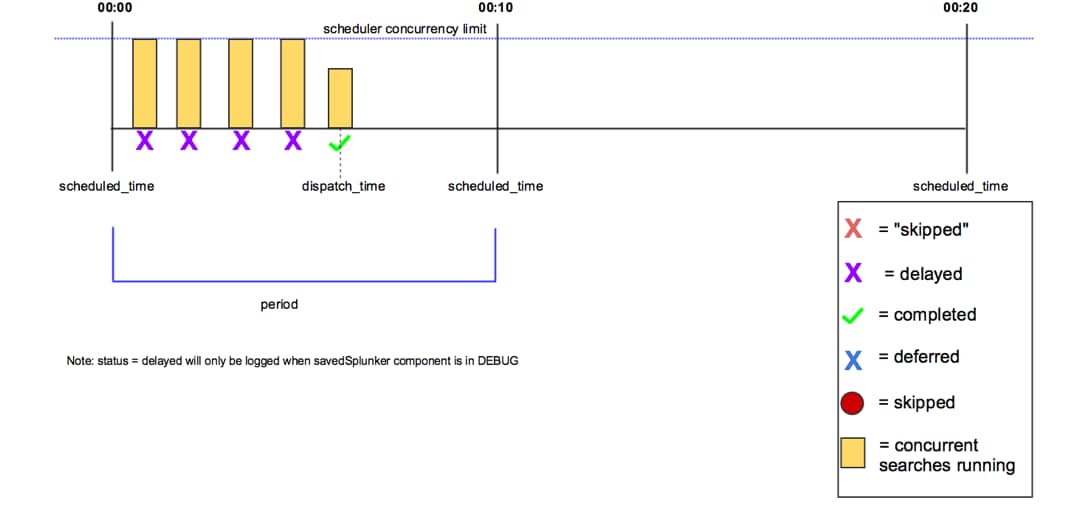
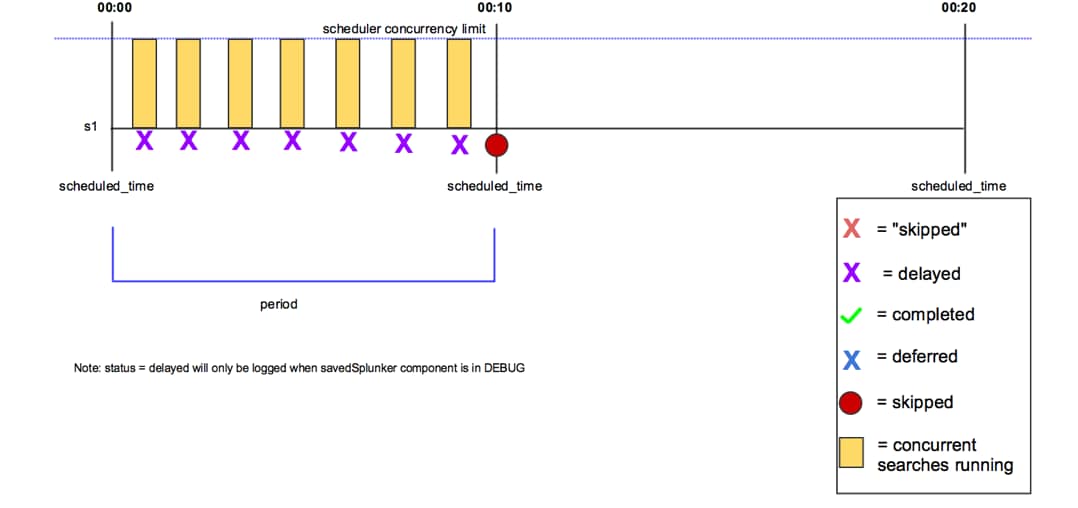
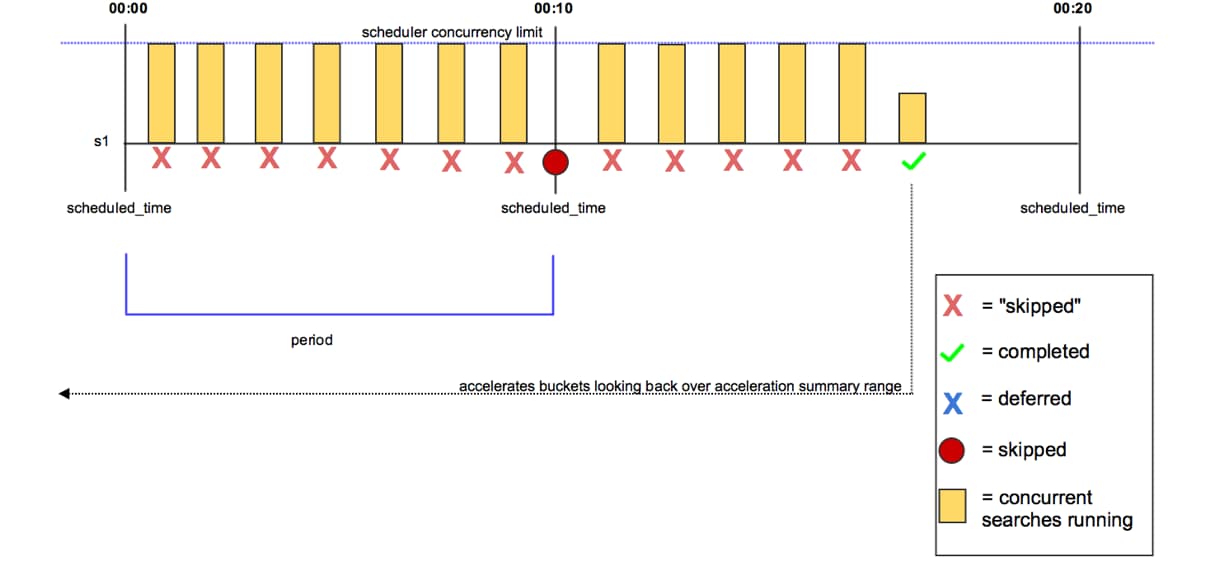
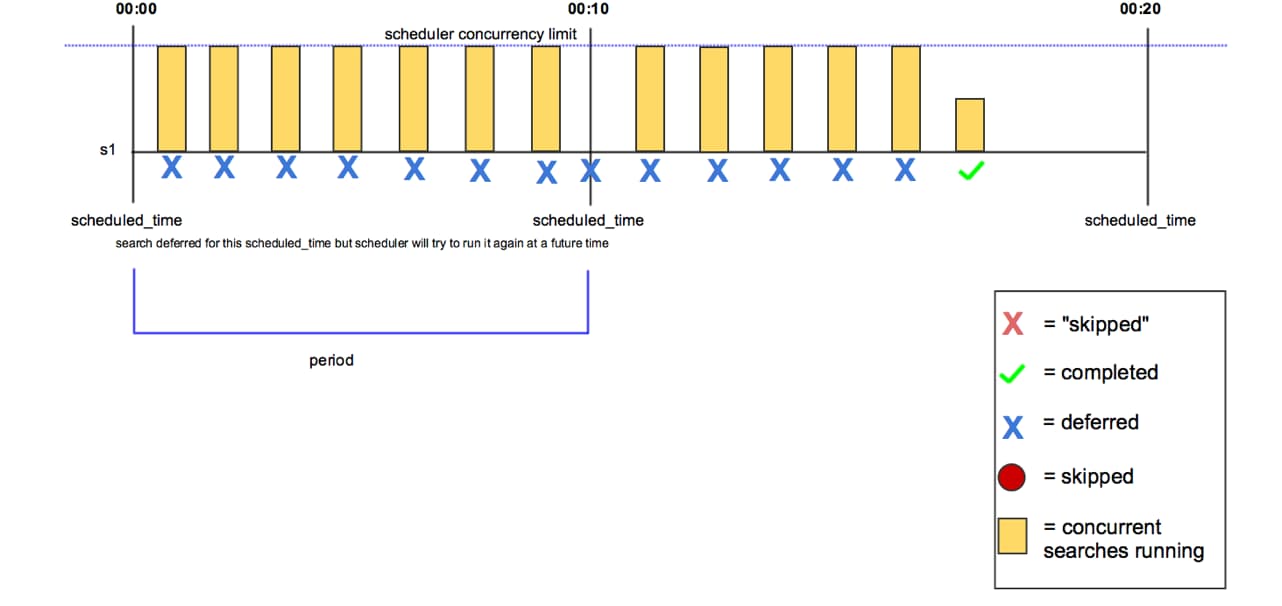
パート2では、検索がスキップまたは延期される場合の主な原因やベストプラクティス、トラブルシューティングを解説します。

© 2005 - 2026 Splunk LLC 無断複写・転載を禁じます。
© 2005 - 2026 Splunk LLC 無断複写・転載を禁じます。
