
AIでセキュリティ分析をレベルアップ
AIが脅威の調査と対応の効果向上にどのように役立つかについてご紹介します。

大企業から政府機関にいたるまで、あらゆる業種の組織で不正、無駄、悪用は重大な問題となっています。利害関係者や一般社会からの監視が厳しさを増す中、問題が組織の財務や評判に及ぼす影響の大きさを考えれば、これらの問題への取り組みは最優先事項と言えるでしょう。
これまで、不正の検出と修正にはさまざまな専門ツールが必要とされてきました。しかし、それらは高機能ではあっても、それを本当に必要としている担当者、つまり技術の専門家ではないビジネスユーザーが使いこなせるものとはとても言えませんでした。
一般に不正調査担当者は、法執行、会計、法務、コンプライアンスなどに関する専門家です。彼らはそれぞれの分野の高度なスキルを持つ専門家ですが、技術の専門家向けに開発された複雑な分析ツールを使用する際には困難に直面することになります。
従来型ツールの複雑さを解消することは、きわめて重要な課題であるにもかかわらず、しばしば見過ごされてきました。
人工知能(AI)と大規模言語モデル(LLM)。この革新的なテクノロジーが登場したことで、技術の専門家ではないユーザーが高度なデータ分析を直感的に利用することが可能になり、これによって、不正の検出、無駄の最小化、悪用の防止に関わる業務全体が大きく生まれ変わろうとしています。
AIが登場したことで、複雑な分析作業を簡素化する新たなチャンスがもたらされました。目標は明確かつ強力です。それは、ビジネスユーザーが各専門分野で使用しているわかりやすい言葉を使って質問すると、実用的な回答が、ビジュアルに訴えるダッシュボード、簡潔なサマリー、インタラクティブな図表などの直感的な形式で提示されるというものです。
今後予定されているSplunkのMachine Learning Toolkit (MLTK) / AI Toolkit (AITK)* version 5.6以降のアップデートでは、サードパーティLLMとの統合など、強力な新機能が導入されます(2025年4月執筆時点)。これらの機能強化によって、「| ai ...」という形式のシンプルなSPLコマンドを使ってローカル、リモートを問わずあらゆるLLMとシームレスに対話できるようになります。以下に例を示します。
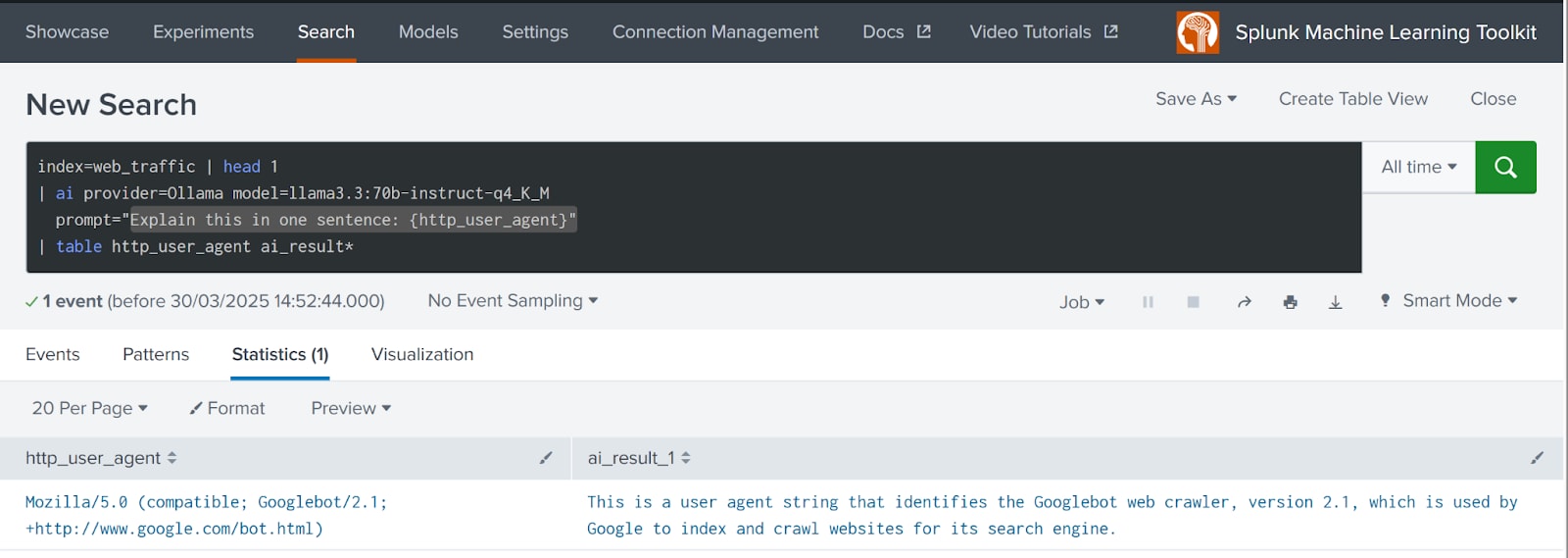
この例では、利用可能な他のデータフィールドから取得した値を使って「prompt」内の変数を展開する構文も示されています。
Splunkは、MLTKおよびAI Toolkit (AI Commander)の機能アップデートに続いて、SplunkとAIの統合によってビジネスユーザー向けの複雑なデータ分析をどのように簡素化できるかを検証する概念実証(POC)を完了させました。
実証しようとしたのは、中規模LLMモデルを使用し、細かい調整を必要としない以下のロジックを実装するという構想でした。
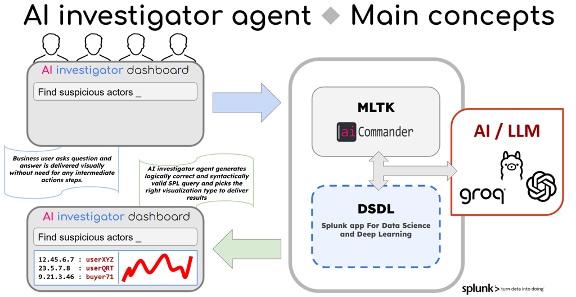
計画はシンプルで、技術の専門家ではないビジネスユーザーが、普段使っているビジネス用語を用いて、不正やサイバーセキュリティの調査を進められるようにするというものでした。
そのようなロジックの初めてのPOCテスト実装が、内で行われました。
インターフェイスはあえて単純なデザインとし、ユーザーの質問を受け付ける入力フィールドを1つ備えるのみです。
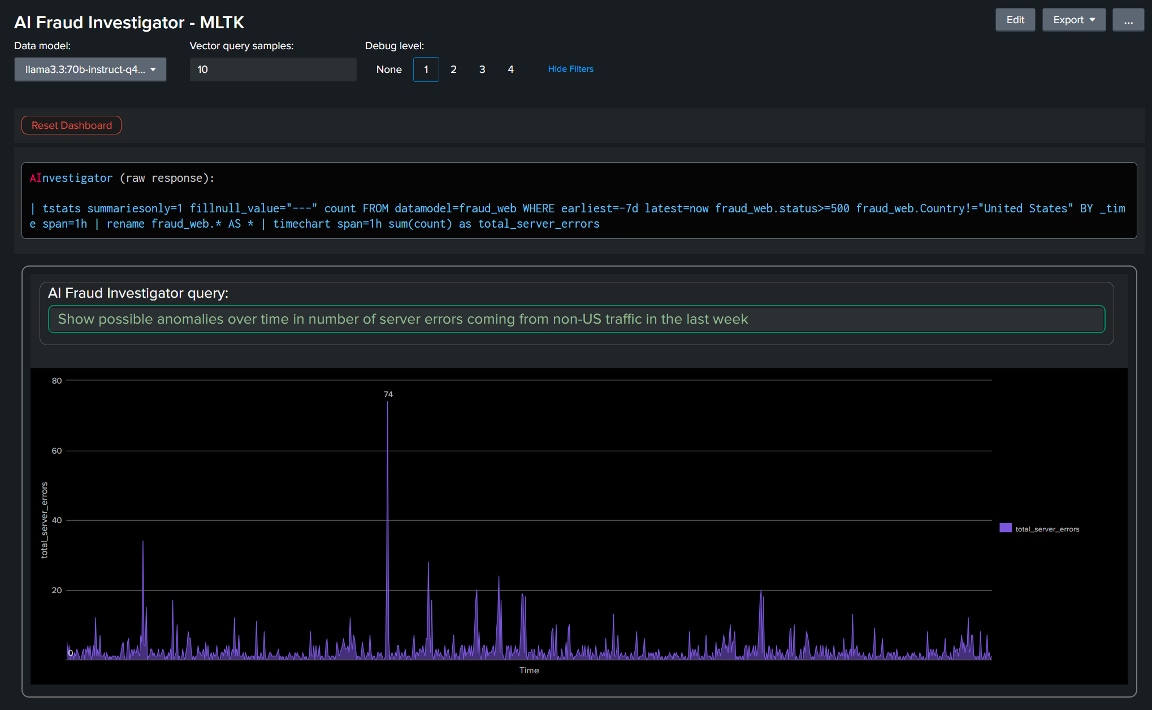
以下の例では、サーバーエラー数の異常を、特に米国以外のトラフィックに絞り込んで時系列で表示するようにユーザーが要求しています。AIエージェントが適切なSPLクエリーを生成し、これに適したタイムチャート表示を選択し、クエリーを検証してからそれを自動で実行し、結果をシームレスに表示しています。
以下からもわかるように、AI調査エージェントの応答内容がそのまま表示されており、ユーザーの質問に対してLLMが生成した実際のSPLクエリーを確認することができます。
次の例では、米国を拠点とするある信用組合のWebサーバーログから、アカウント乗っ取り攻撃にさらされている可能性のあるアカウント(米国以外のIPアドレスからのログインで使用されたアカウント)を特定するようユーザーが要求しています。
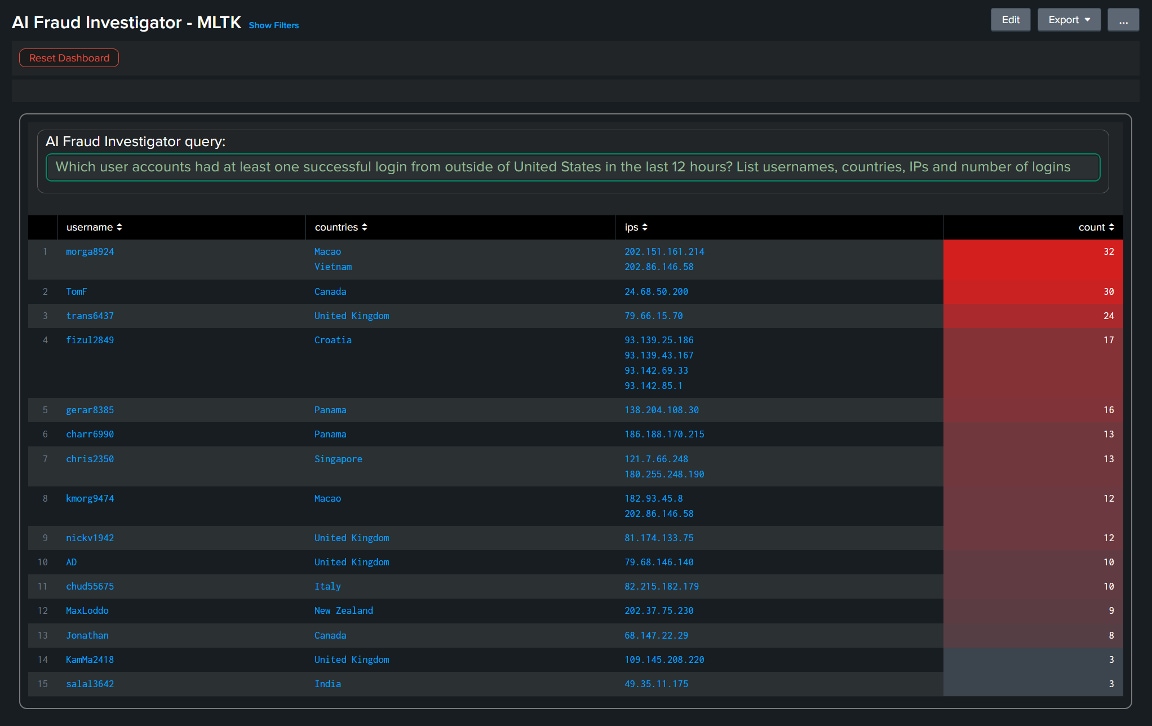
以下が、ユーザーの質問に対してLLMが生成した実際のクエリーです。
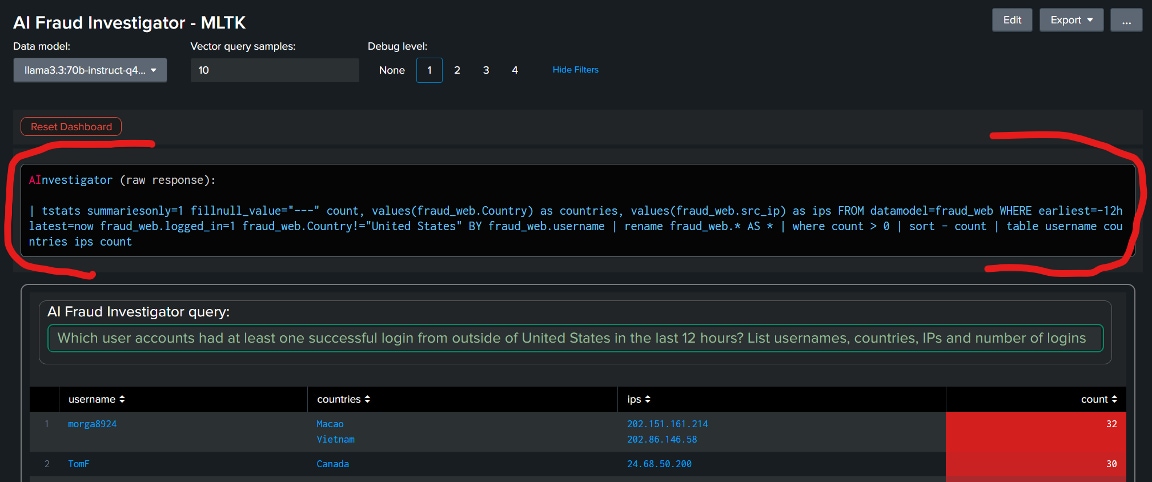
クエリーの構文は正しく、ロジックも有効で、ユーザーが要求したすべてのフィールドを返しています。
以下の例では、ユーザークエリーを日本語に翻訳し、その他は何も変更せずに再度実行しています。表示された結果は本質的には同一の内容です。この例では、SPLクエリーが英語版とわずかに異なっていますが(LLMがユーザーのそれぞれの要求内容を解釈する際の微妙な違いが原因)、十分にユーザーの目的に適った適切な結果が返されています。
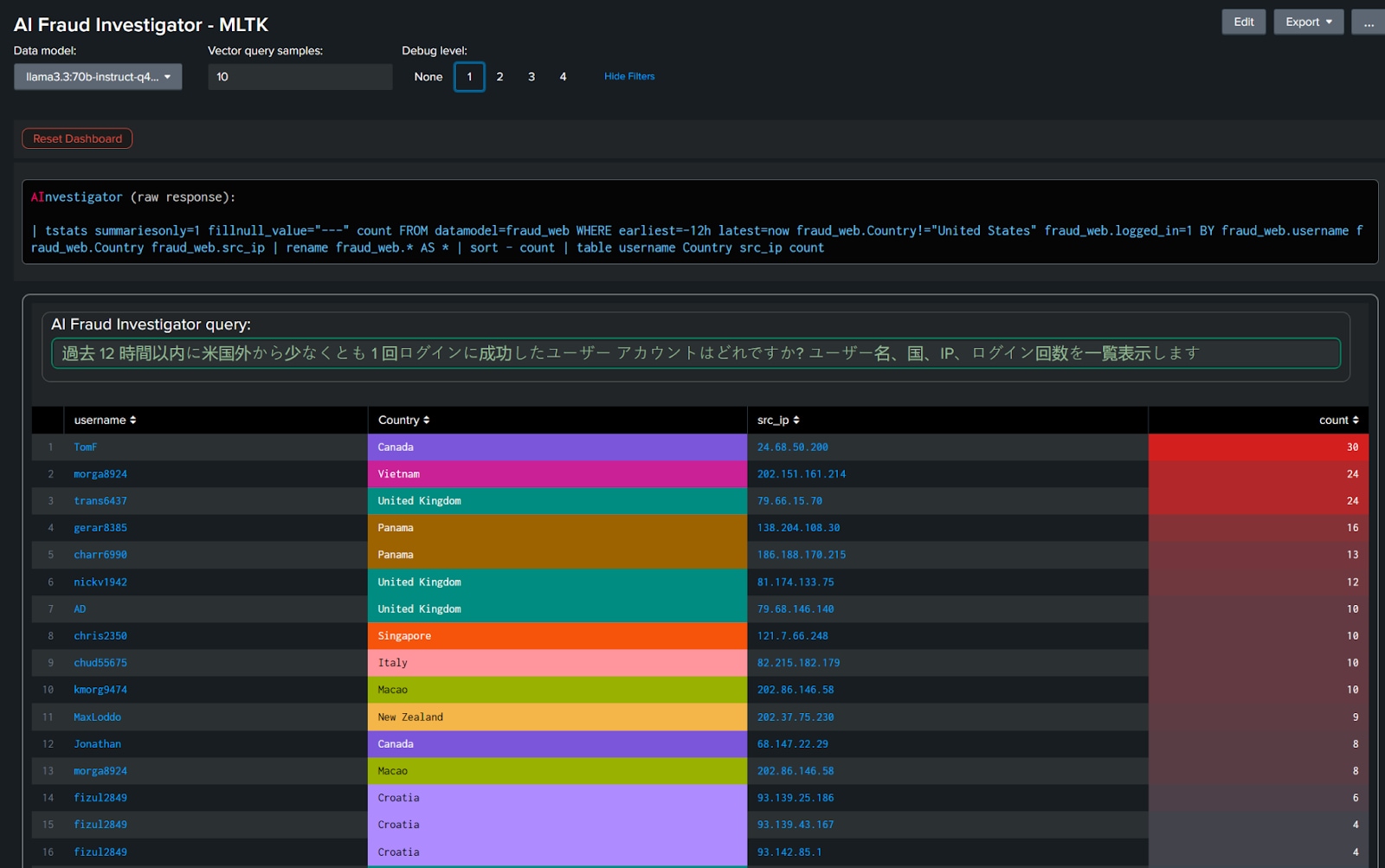
こうした機能はどのように実装されているのでしょうか?
鍵となるのは、適切に構成された例示から学ぶことができるLLMの優れた学習能力を活用することです。最新のMLTKをインストールして設定すれば、Splunkのサーチプロンプトを使ってこの機能を直接体験できます。異なる国々から複数のログインがあったアカウントをリストするというクエリーを考えてみましょう。
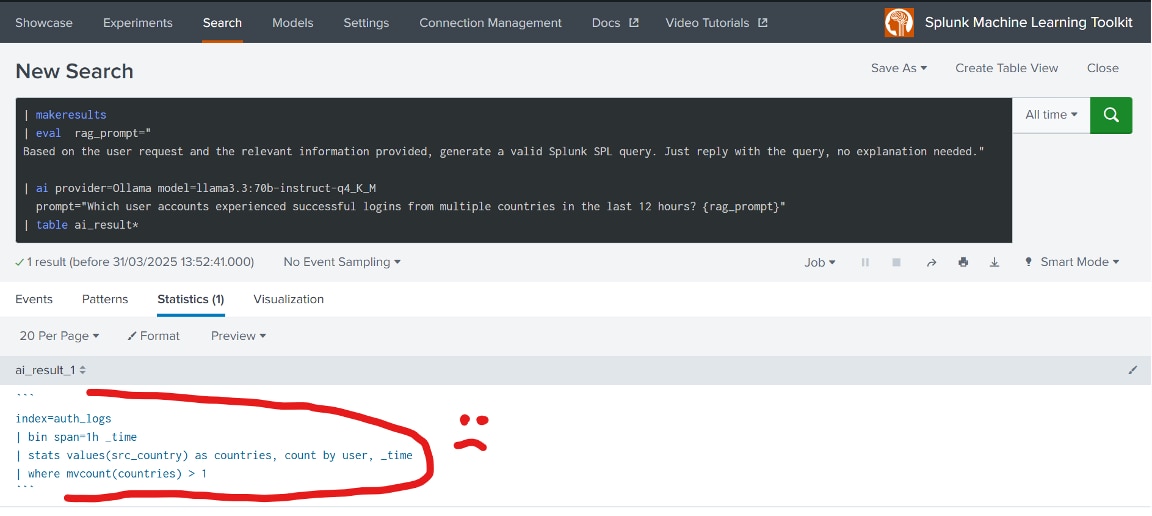
LLMは、データソースやフィールドに関するコンテキストがない状況で、一見有効に見えるクエリーを生成しましたが、これは適切に実行できませんでした。コンテキスト情報が必要であることは明らかです。このままでは、どんなデータソースやフィールドが利用できるのかが、LLMにはまったく分かりません。
では、改善した例を見てみましょう。今度は有効なSPLクエリーが生成されました。
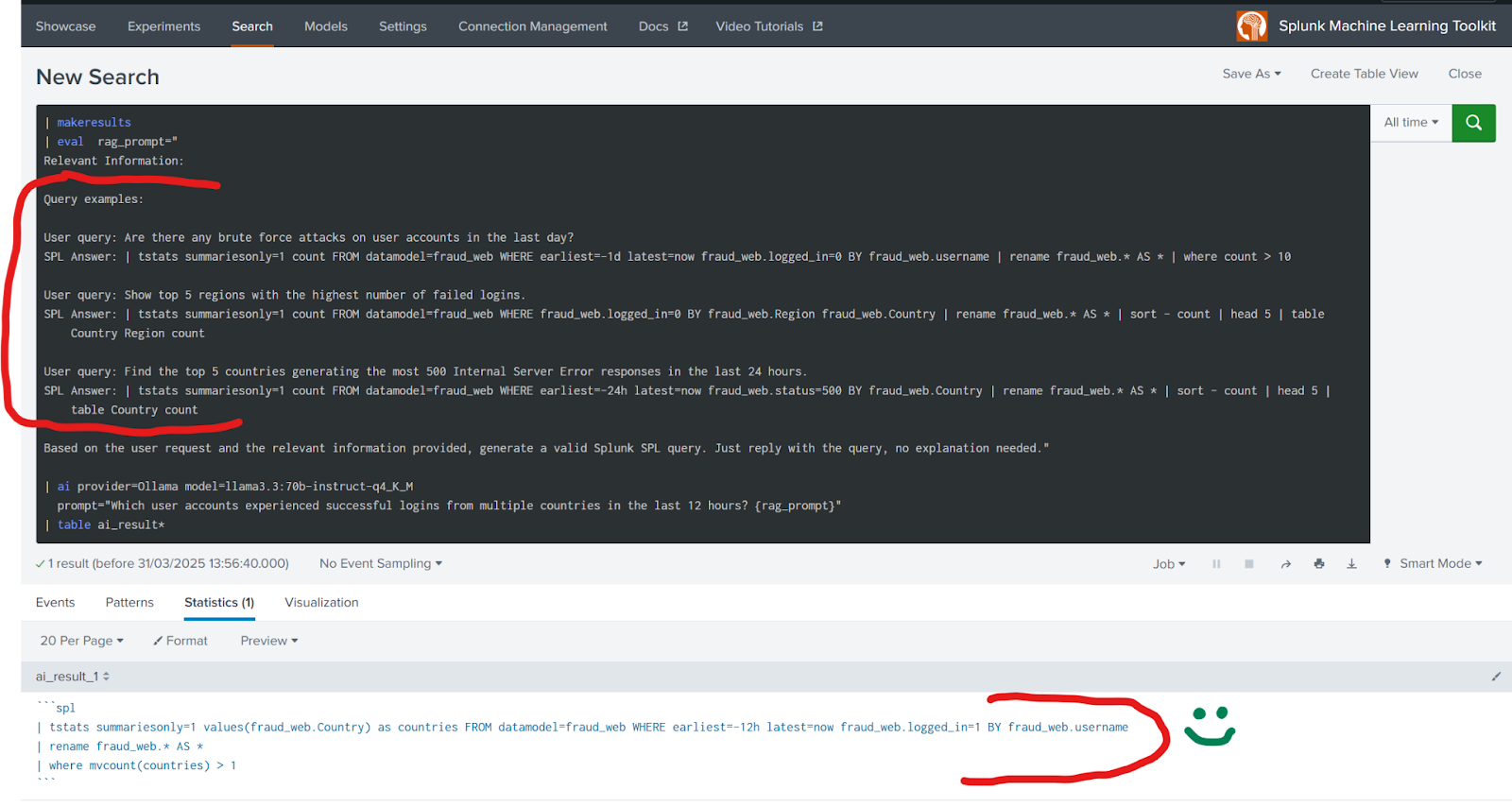
前の例と唯一違っているのは、重要なコンテキスト情報をRAG方式でプロンプト中に埋め込んでいる点です。実際のデータソースと実際のフィールドを使って正しく動作する例を3つ示しただけで、LLMは構文的に正しく、ロジックも有効なSPLクエリーの出力に成功しました。
以下に、AI調査エージェントの実装における、より完成度を高めたアーキテクチャを示します。
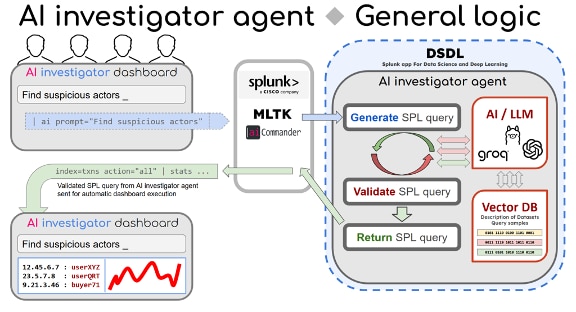
ベクトルDBには、利用できるすべてのデータソースの説明が保存されており、そこには各データソースで利用可能なフィールドの説明も含まれます。
ベクトルDBには、SPLクエリーのサンプルも保存されます(今回実施したPOCでは合計で約50件)。
ユーザーが要求を入力すると、その要求がMLTK/AIコマンダーによってAI調査エージェントに送られます。AIエージェントは、ベクトルDBクエリーを使ってユーザーの要求を最も関連性の高いデータソースと照合し、最も関連性の高いSPLクエリーサンプルを多数抽出します。この結果を使ってユーザーのクエリーが補強され、それがLLMに送られて実行されます。
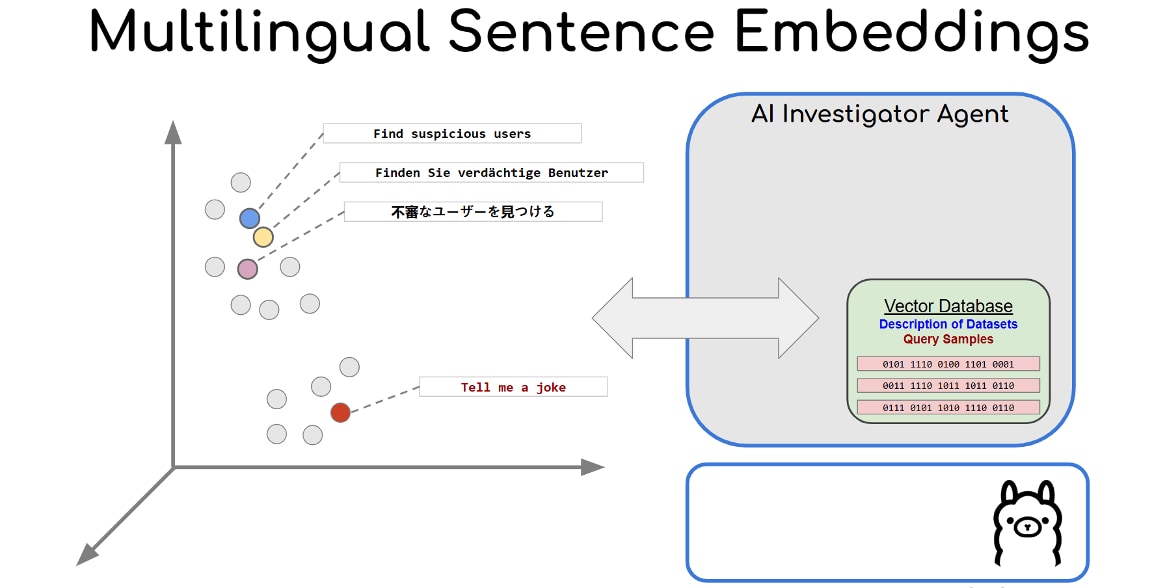
埋め込みモデルとコサイン類似度の仕組みを利用することによって、ユーザーのクエリーはその意味を維持したままさまざまな言語に翻訳可能です。これにより、入力言語を問わず、有効なSPLクエリーの生成が保証されます。
この概念実証(POC)を実施するにあたっては、プロセスの合理化のためにPydantic AIフレームワークが使用されました。また、このフレームワークを利用することで、SPLの自動検証を容易に行い、必要に応じて再試行しながらより有効な出力を得ることが可能になりました。
すべての検証チェックを通過したSPLクエリーは、推奨される可視化方法の情報と併せてダッシュボードに送り返されます。その後、ダッシュボードでクエリーが実行されて結果が表示されます。
技術の専門家ではない不正調査担当者にとって理想的なシナリオははっきりしています。それは、自分の専門分野のビジネス用語を使った自然な言い回しで質問し、直感的に理解しやすい回答を受け取ることです。想定されているのは、LLMドリブンのシステムがこのような質問を解釈し、適切なクエリーを自律的に生成して実行し、その後、情報の可視化や明快で実用的な説明によってインサイトを提示するという流れです。この方法によって、調査担当者にかかる認知および運用面の負荷が大幅に軽減され、調査担当者は本来の役割、つまり結果の解釈と対策の決定にもっと集中できるようになります。
不正、無駄、悪用との戦いに真摯に取り組む企業・組織は、データ分析の簡素化を優先する必要があります。そのようにすれば、調査担当者の技術的スキルを問わず、強力なインサイトを利用できるようになり、それに基づいて対策を講じたり、戦略を立てたりできるようになるからです。このようなAIの戦略的導入は、ますます巧妙化する不正行為に先回りし、民間と公共の両部門における整合性、効率、社会的信頼を保護するための鍵となります。
Splunk AI Toolkit (AITK)*をダウンロードする。
*バージョン5.6.3で、名称が「Splunk Machine Learning Toolkit (MLTK)」から変更となりました
このブログはこちらの英語ブログの翻訳、濵田 菜央によるレビューです。

© 2005 - 2026 Splunk LLC 無断複写・転載を禁じます。
© 2005 - 2026 Splunk LLC 無断複写・転載を禁じます。
