
Wege zum Aufbau erfolgreicher Observability-Praktiken

„Wie können wir unsere DevOps-Daten in nützliche DevSecOps-Daten verwandeln? Die Datenmenge ist so riesig! Die Daten können von überall stammen! Sie haben alle möglichen unterschiedliche Formate!“
Diese Aussagen sind zwar alle richtig, es gibt jedoch Ähnlichkeiten in verschiedenen Teilen des DevOps-Lebenszyklus, die genutzt werden können, um all diese Daten zu erschließen und zu vereinheitlichen. Wie bringen wir Ordnung in dieses Datenchaos? Auf die gleiche Weise, wie Wissenschaftler komplexe Phänomene untersuchen – wir erstellen ein konzeptionelles Modell der Daten. Die Modellierung gemeinsamer Konzepte aus den verschiedenen Segmenten des DevOps-Lebenszyklus, von der Planung bis zur Veröffentlichung, erhöht die Observability eurer DevOps-Prozesse und unterstützt DevSecOps-Praktiken.
Für sämtliche Use Cases im DevSecOps-Bereich ist es von entscheidender Bedeutung, dass wir alle unsere DevOps-Daten nutzen können. Die Fähigkeit, Daten von beliebigen Tools oder Anbietern zu verstehen und zu verwerten, ist so wichtig, dass sie schon im ersten Absatz des NSA-Dokuments „Defending Continuous Integration/Continuous Delivery (CI/CD) Environments“ über die Verteidigung von CI/CD-Umgebungen genannt wird. Der Schwerpunkt dieses Dokuments liegt auf der Integration bewährter Sicherheitsverfahren in die DevOps-Prozesse von CI/CD-Umgebungen, ohne dabei die spezifischen, genutzten Tools zu berücksichtigen, die angepasst werden – dies ist ein wichtiger Aspekt bei DevSecOps-Praktiken.
Diese Blog-Reihe zur Modellierung von DevOps-Daten soll dazu beitragen, gemeinsame Konzepte und Verknüpfungen in verschiedenen Phasen des SDLC zu etablieren, die in einem DevOps-Datenmodell genutzt werden können. Dieses Datenmodell kann dann verwendet werden, um DevOps-Daten als Ganzes zu vereinheitlichen und ihre Verwendung mit anderen, eher herkömmlichen sicherheitsorientierten Datenmodellen (z. B. dem Splunk Common Information Model - CIM) zu vereinfachen. Zum Einstieg werden wir jetzt also einige Elemente und Gemeinsamkeiten in verschiedenen Phasen des DevOps-Lebenszyklus aufschlüsseln. Wir beginnen hier mit der Arbeitsplanung und wenden uns in kommenden Blogs dann den Phasen Codieren, Erstellen und Veröffentlichen zu.
Bei der Arbeitsplanung für Software-Projekte geht es in der Regel um Projekte, Epics, Probleme, Tickets und so weiter. Unabhängig vom Tool verwenden alle agilen Arbeitsplanungsplattformen einige gemeinsame Konzepte, die sich aus der Natur agiler Methoden und ihrer Verwendung in Softwareunternehmen ergeben. Epics, Probleme, Aufgaben, Tickets und dergleichen sind die Objekte, die die Grundlage der meisten agilen Workflows darstellen, unabhängig davon, ob es sich um Sprint, Kanban oder etwas dazwischen handelt. Diese Objekte ermöglichen uns, unabhängig von der Datenquelle Gemeinsamkeiten innerhalb der Daten zu finden.
Diese Gemeinsamkeiten gelten für Jira, Github-Projekte, Trello und andere. Datenmodelle für diese Art von Daten können diese Gemeinsamkeiten als Felder nutzen, um Daten aus unterschiedlichen Quellen in einer einheitlicheren und besser nutzbaren Datenquelle zuzuordnen. Wenn der Objektbezeichner beispielsweise in Jira IssueID, in GitHub IssueNumber und in Trello CardNumber lautet, können alle drei Felder im Datenmodell einfach der Bezeichnung issueNumber zugeordnet werden. Jetzt kann die Suche nach Objekten in jedem dieser Tools über dasselbe issueNumber-Feld erfolgen. Wenn man ein einheitliches Repository-Identifikationsfeld wie repository_name hinzufügt, erhält man dadurch die Flexibilität, alle Arbeitsobjekte für ein bestimmtes Repository während eines bestimmten Zeitraums anzuzeigen.
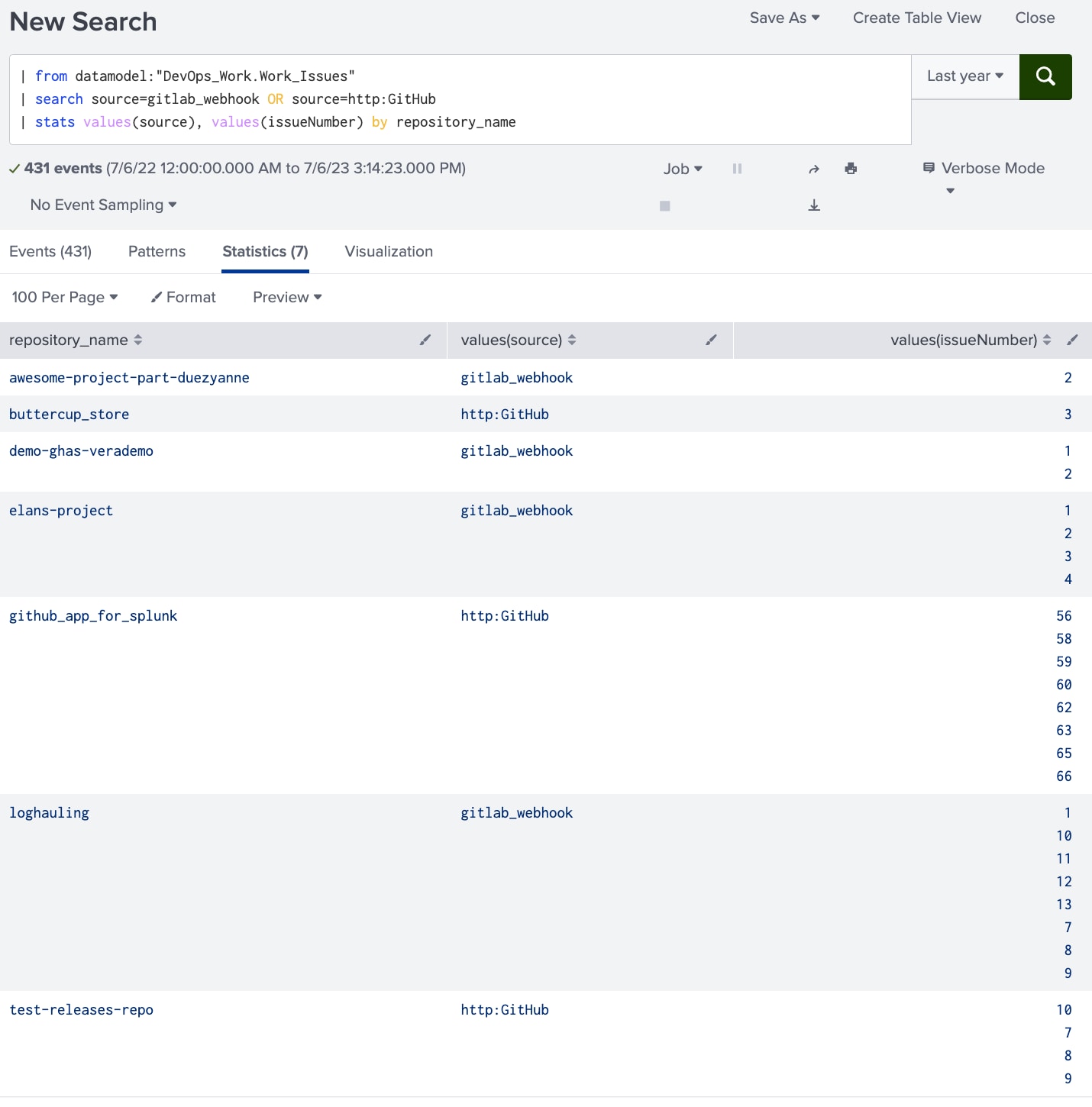
Abbildung 1-1. Eine einfache Splunk-Suche kann die Arbeiten zeigen, die im vergangenen Jahr in verschiedenen Repos und mit verschiedenen Tools durchgeführt wurden. Man könnte die Suche modifizieren, indem man ein einheitliches Feld wie status_current hinzufügt, um nur Tickets zu sehen, die im letzten Jahr geschlossen wurden oder die momentan offen sind.
Dazu kommt, dass es bei der Planung von Arbeiten in Code-Repositorys unheimlich nützlich ist, den Namen des Code-Repositorys bzw. des Branch und andere Details zu euren Planungsobjekten hinzuzufügen! Manche Tools bieten spezielle Lösungen für die Referenzierung von Planungsobjekten. Bei anderen Tools ist das nicht der Fall, diese Daten können jedoch auch auf andere Weise abgeleitet werden, indem man die Nummer des Arbeitsobjekts in einer Code-Commit- oder Pull-Request-Beschreibung referenziert und parst.
Mit diesen Repository-Daten, die Planungsobjekte in Ereignissen auf Code-Ebene wie Commit-Nachrichten und Pull-Requests referenzieren, lässt sich einer Linie von der Arbeit zum Code, von der Aufnahme bis zur Auslieferung und von der Idee bis zur Umsetzung folgen. Darüber hinaus können die Gemeinsamkeiten von Codedaten genutzt werden, um den Lebenszyklus der Softwareentwicklung (SDLC) durch die Erstellung bis hin zur Release zu verfolgen. Repository-Name, Problem-IDs, Commit-Hashes, Branches, Zusammenführungen und andere code-spezifische Daten liefern die nötigen Verknüpfungen, anhand derer man sieht, welcher Code erstellt, veröffentlicht oder gar in eurer Softwareumgebung ausgeführt wird.
Durch die Erstellung dieser Art von Datenmodellzuordnungen nur für die oben aufgeführten Arbeitsplanungsdaten wird die Nachverfolgung des Wer, Was, Wo, Wann und Warum einer Arbeit einfacher und völlig Tool-unabhängig. Es spielt keine Rolle, ob Team A Jira und Team B GitHub verwendet – die Daten sind jetzt einheitlich und nutzbar! Dieser direkte Mehrwert lässt sich schon allein bei Planungsdaten erzielen und ermöglicht die Beantwortung von Fragen wie diesen:
All diese Fragen lassen sich relativ einfach stellen und beantworten, sobald das Instrumentarium eures Unternehmens über diese Art von DevOps-Planungsdaten verfügt.
Wenn ihr Daten aus anderen Phasen der DevOps-Toolkette hinzufügt, erhaltet ihr sogar ein vollständigeres Bild davon, wie eure Softwareorganisation funktioniert. Wenn man die Gemeinsamkeiten der Daten ausnutzt, ermöglicht dies, Metriken aus jeder Phase des Software-Lebenszyklus nachzuverfolgen und abzuleiten, einschließlich Details zum Zeitaufwand für die Überprüfung, dem Zeitaufwand für das Testing und der Gesamtzeit von der Idee bis zum veröffentlichten Code.
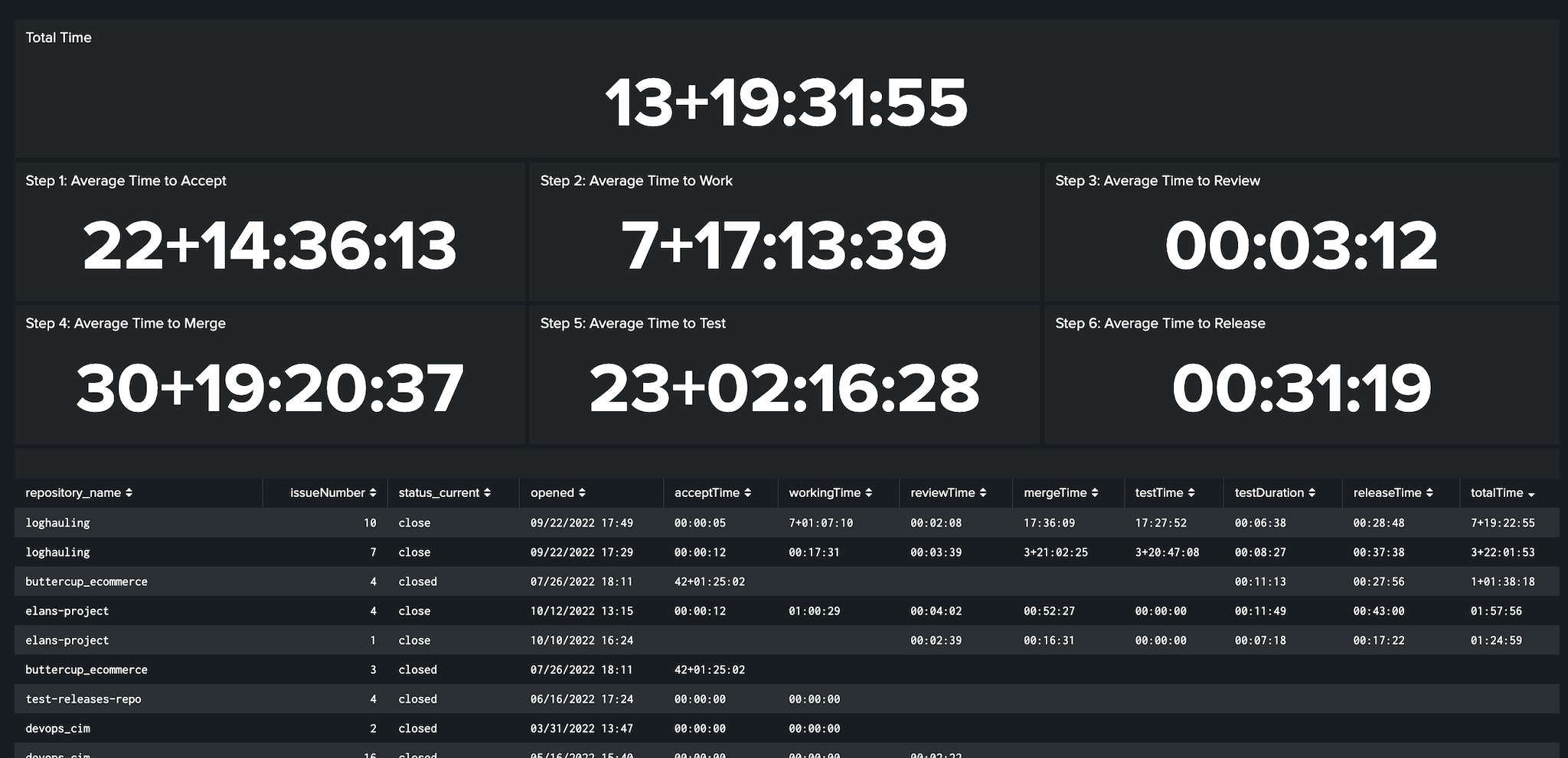
Abbildung 1-2. Ein einheitliches Modell als DevOps-Grundlage eröffnet Möglichkeiten für detaillierte Analysen des Softwareentwicklungslebenszyklus von der Arbeitsplanung bis zum veröffentlichten Code über beliebige Tools oder Plattformen hinweg.
Die Verknüpfung der verschiedenen SDLC-Komponenten (in diesem Fall Planung, Codieren, Testen und Release) ist vielleicht der größte Nutzen eines Datenmodells für DevOps. Wenn man jedoch Gemeinsamkeiten wie IssueNumber, Repository-Name, Branch, Commit-Hash und Merge-Hash als Verknüpfungsfelder über den gesamten Lebenszyklus der Softwareentwicklung von der Arbeitsplanung bis hin zu Betrieb und Monitoring verwendet, sorgt dies für ein tieferes Verständnis der Abläufe in unseren DevOps-Prozessen und unterstützt ganz unmittelbar die DevSecOps-Praktiken, die diese Art von einheitlichen Daten für die erfolgreiche Entwicklung und den Schutz der Unternehmens-Software benötigen.
Neugierig auf mehr? Möchtet ihr wissen, welche Art von Daten GitLab, GitHub, BitBucket und andere codebezogenen Tools bereitstellen und was diese Daten gemeinsam haben? Interessiert ihr euch für DevSecOps und die Mischung aus DevOps-Codedaten und Security? Im nächsten Blog erfahrt ihr mehr über die Gemeinsamkeiten codebezogener DevOps-Daten und darüber, wie die Vereinheitlichung dieser Daten auf agilen Planungsdaten aufbauen kann, um die Resilienz, Sicherheit und Observability eures Unternehmens zu verbessern.
Möchtet ihr wissen, wie Splunk Datenmodelle erstellt? Registriert euch für einen kostenlosen Test der Splunk Cloud Platform und seht es euch noch heute selbst an!
Verfasser dieses Blogbeitrags ist Jeremy Hicks, Staff Observability Field Innovation Solutions Engineer bei Splunk. Ein besonderer Daten geht an: Doug Erkkila, David Connett, Chad Tripod und Todd DeCapua für die Zusammenarbeit, das Brainstorming und die Unterstützung bei der Entwicklung des Konzepts für ein DevOps-Datenmodell.
*Dieser Artikel wurde aus dem Englischen übersetzt und editiert. Den Originalblogpost findet ihr hier.

Die führenden Unternehmen der Welt vertrauen auf Splunk, einem Unternehmen von Cisco, um ihre digitale Resilienz mit der einheitlichen Sicherheits- und Observability-Plattform, unterstützt durch branchenführende KI, kontinuierlich zu stärken.
Unsere Kunden setzen auf die preisgekrönten Sicherheits- und Observability-Lösungen von Splunk, um die Zuverlässigkeit ihrer komplexen digitalen Umgebungen zu sichern und zu optimieren – in jeder Größenordnung.

Die neuesten Artikel von Splunk, direkt im eigenen Posteingang.
© 2005 - 2026 Splunk LLC All rights reserved.
© 2005 - 2026 Splunk LLC All rights reserved.